文章目录
1 引言
小伙伴们,三个月没见,都还好嘛?说实话,我这段时间的小日子有些跌跌撞撞的。
工作方面,我曾经从零开始搭建的项目,因为团队分工的问题,不得不暂时搁置,只好调整心态,转而投入到其他项目中。身体方面,我原以为自己怎么吃都不会胖,没想到体重从刚毕业时的105斤一路飙升到现在的138斤,这也迫使我把健身计划调整为以减体重为主。生活习惯上,原本设定的连续健身60天的小目标却在第59天意外中断,每日阅读的习惯也在坚持了350多天后,倒在了一年这一重要节点前。这些消极的事情积少成多,对我来说,委实变成了一个大打击。
不过,我始终是那种即使身处低谷,也会努力向光而行的人。虽然工作中有一段时间很迷茫,但最近被安排负责的在线优化问题,让我重新燃起了兴趣。减肥方面,不仅在体重秤上看到了积极的变化,还带动了老婆一起健身,现在她的成果甚至比我还要显著。至于生活习惯,重启永远不晚:新的连续运动天数已经达到了76天,正在向100天的目标迈进;新的连续阅读也坚持了49天,小目标依然是一整年。
解决了这些问题后,我又回来继续学习了。之前涉猎了很多方向(因果推断、不确定性优化、大模型),但都没有形成系统的理解,感觉有些零散。今年下半年,我打算将重心放在因果推断上,争取在年底前形成一次系统性的总结。
本篇文章的主题是因果推断中的元学习方法。此前我曾跳过这部分内容,直接学习了双重机器学习方法(DML),主要是因为DML在业界应用更为广泛。但最近发现,元学习方法在一些团队的特定项目中依然有实际价值。此外,从知识体系的完整性和基础性角度来看,理解元学习方法的原理与实践仍然十分重要。
正文如下。
2 元学习方法
2.1 基本概念
在介绍元学习方法之前,首先需要明确相关概念。机器学习中的元学习(Meta-learning)与因果推断领域常用的元学习器(Meta-learner)虽名称相似,但侧重点略有不同。目前,关于二者关系的讨论还不多。根据主流大模型的解释,机器学习中的 Meta-learning 更强调方法论,即“如何高效学习”;而因果推断中的 Meta-learner,则是这种思想在因果推断任务中的具体实现方式。
因此,要理解因果推断中的元学习方法,首先需要掌握机器学习领域的 Meta-learning 概念。其核心思想是“学习如何学习”,即让算法能够通过不断积累经验,提升自身的学习能力。例如,如果目标是提高考试成绩,元学习关注的是掌握高效的学习方法,从而全面提升各科成绩;而传统机器学习则可能只关注某一科目的成绩提升,较少考虑方法的迁移和泛化能力。
在因果推断领域,元学习方法的应用体现在:模型先在不同干预条件下学习结果分布,再基于这些学习结果评估因果效应。具体实现包括 S-learner、T-learner、X-learner 和 R-learner 等多种算法。
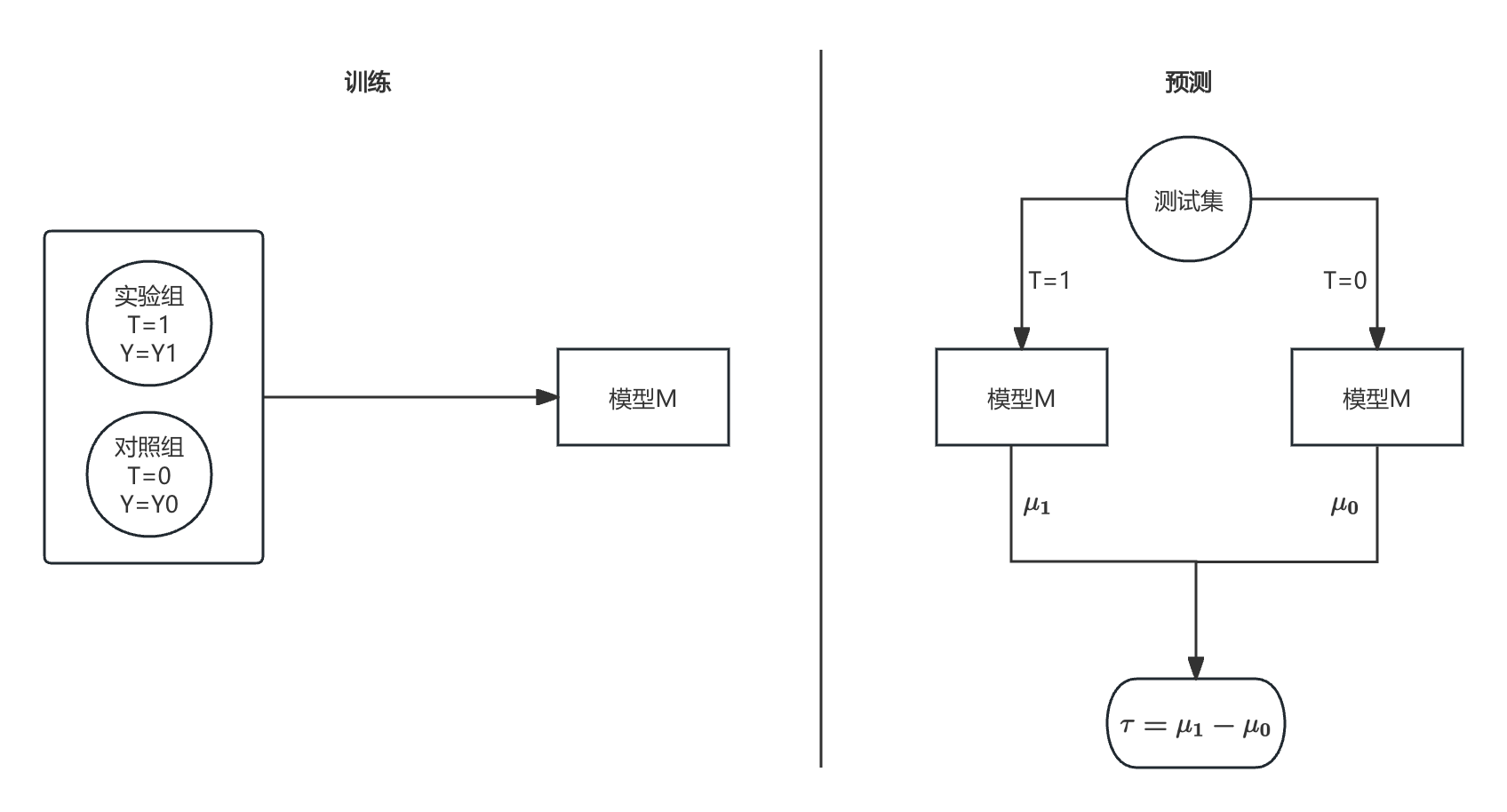
2.2 S-learner
S 代表 Single,即单一模型。S-learner 使用一个模型同时对实验组和对照组的数据进行建模,将处理变量(treatment)作为特征输入。此时,条件平均处理效应(CATE)的表达式为:
τ ( x ) = E [ Y ∣ X = x , T = 1 ] − E [ Y ∣ X = x , T = 0 ] = μ 1 − μ 0 \tau(x) = E[Y|X=x, T=1] - E[Y|X=x, T=0] = \mu_1 - \mu_0 τ(x)=E[Y∣X=x,T=1]−E[Y∣X=x,T=0]=μ1−μ0
下图中, M ( Y ∼ ( X , T ) ) M(Y \sim (X, T)) M(Y∼(X,T)) 表示以 ( X , T ) (X, T) (X,T) 为特征、 Y Y Y 为标签的任意机器学习模型(如线性回归、XGBoost 等)。
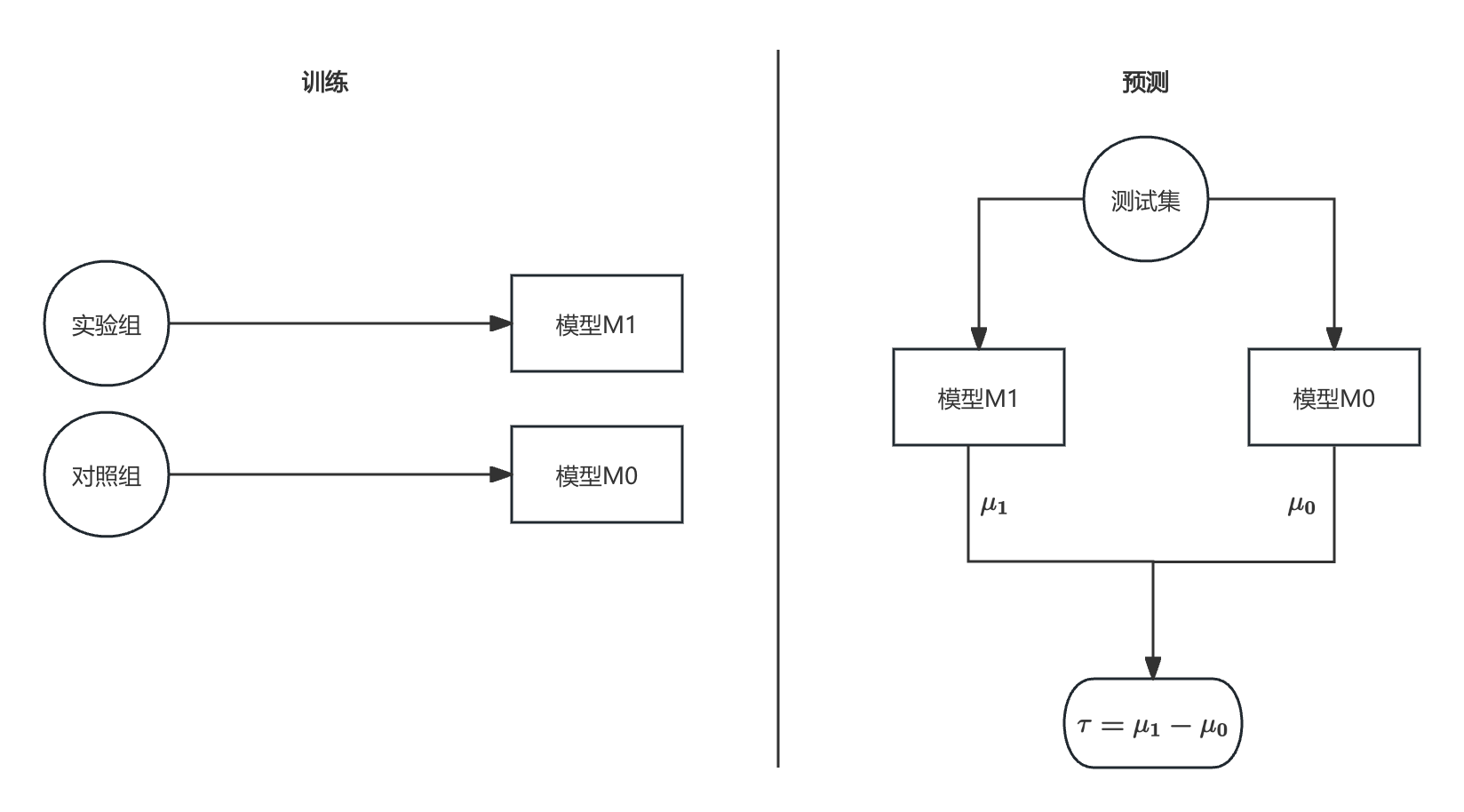
2.3 T-learner
T 代表 Two,即两个模型。T-learner 分别针对实验组和对照组,各自训练一个模型以预测响应值。此时,CATE 的表达式为:
τ ( x ) = E [ Y ( 1 ) − Y ( 0 ) ∣ X = x ] = E [ Y ( 1 ) ∣ X = x ] − E [ Y ( 0 ) ∣ X = x ] = μ 1 − μ 0 \tau(x) = E[Y(1) - Y(0)|X=x] = E[Y(1)|X=x] - E[Y(0)|X=x] = \mu_1 - \mu_0 τ(x)=E[Y(1)−Y(0)∣X=x]=E[Y(1)∣X=x]−E[Y(0)∣X=x]=μ1−μ0
下图中, M 0 ( Y 0 ∼ X 0 ) M_0(Y^0 \sim X^0) M0(Y0∼X0) 和 M 1 ( Y 1 ∼ X 1 ) M_1(Y^1 \sim X^1) M1(Y1∼X1) 分别是对照组和实验组的响应预测模型,模型类型可灵活选择。
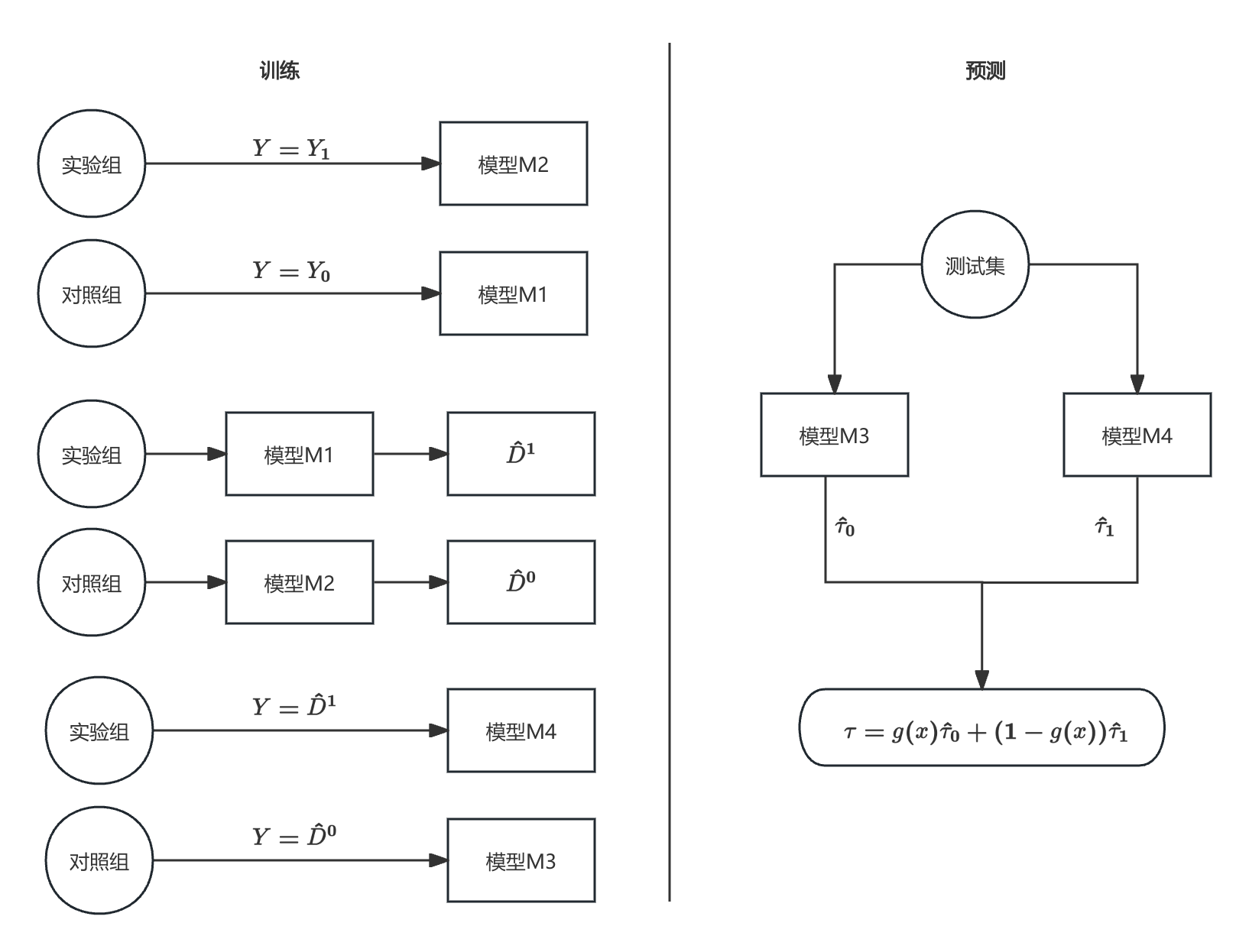
2.4 X-learner
X 代表 Cross,强调交叉估计。X-learner 通过分别估计实验组的平均处理效应(CATT)和对照组的平均处理效应(CATC),再加权平均得到最终的 CATE 估计。
- 第一步:与 T-learner 类似,分别用 M 1 M_1 M1 和 M 2 M_2 M2 针对对照组和实验组拟合响应。
M 1 ( Y 0 ∼ X 0 ) , M 2 ( Y 1 ∼ X 1 ) M_1(Y^0 \sim X^0), \quad M_2(Y^1 \sim X^1) M1(Y0∼X0),M2(Y1∼X1) - 第二步:用对照组模型预测实验组的个体处理效应(ITE),用实验组模型预测对照组的 ITE。
D ^ 1 = Y 1 − M 1 ( X 1 ) , D ^ 0 = M 2 ( X 0 ) − Y 0 \hat D^1 = Y^1 - M_1(X^1), \quad \hat D^0 = M_2(X^0) - Y^0 D^1=Y1−M1(X1),D^0=M2(X0)−Y0 - 第三步:以 X X X 为特征,第二步得到的 ITE 为标签,分别在对照组和实验组上训练模型 M 3 M_3 M3 和 M 4 M_4 M4,最终以加权平均作为 CATE 的估计。权重可采用倾向得分等方法。
τ ^ 0 = M 3 ( D ^ 0 ∼ X 0 ) , τ ^ 1 = M 4 ( D ^ 1 ∼ X 1 ) \hat \tau_0 = M_3(\hat D^0 \sim X^0), \quad \hat \tau_1 = M_4(\hat D^1 \sim X^1) τ^0=M3(D^0∼X0),τ^1=M4(D^1∼X1)
τ ( x ) = g ( x ) τ ^ 0 + ( 1 − g ( x ) ) τ ^ 1 \tau(x) = g(x)\hat \tau_0 + (1 - g(x))\hat \tau_1 τ(x)=g(x)τ^0+(1−g(x))τ^1
2.5 R-learner
R-learner 与双重机器学习(DML)方法类似。回顾 DML 的基本表达式,其通过对残差进行线性回归,估计平均因果效应 τ \tau τ:
Y − Y ^ = τ ⋅ ( T − T ^ ) Y - \hat Y = \tau \cdot (T - \hat T) Y−Y^=τ⋅(T−T^)
R-learner 是 DML 思想的拓展,目标是寻找一个函数 τ ( x ) \tau(x) τ(x),使得以下损失最小化:
[ Y − Y ^ − τ ( x ) ⋅ ( T − T ^ ) ] 2 [Y - \hat Y - \tau(x) \cdot (T - \hat T)]^2 [Y−Y^−τ(x)⋅(T−T^)]2
由于 R-learner 在实际应用中较为少见,本文不再展开介绍。
3 代码实现
本节将进入代码实操环节,分为两个部分:第一部分手动实现一种元学习方法,以加深理解;第二部分通过实例对比不同元学习方法在因果推断中的表现。
3.1 S-learner 原理实现
以 S-learner 为例,分别采用两种方式实现:第一种是直接调用 causalml 工具包中的 BaseSRegressor 模块;第二种是手动编写机器学习模型实现。
import numpy as np
from sklearn.linear_model import LinearRegression
from xgboost import XGBRegressor
from causalml.inference.meta import BaseSRegressor
from causalml.dataset import synthetic_data
def calc_by_package(X, treatment, y):
# 使用线性回归模型
learner_s = BaseSRegressor(learner=LinearRegression())
learner_s.fit(X=X, treatment=treatment, y=y)
ate_s = learner_s.predict(X)
# 使用 XGB 回归模型
learner_t = BaseSRegressor(learner=XGBRegressor())
learner_t.fit(X=X, treatment=treatment, y=y)
ate_t = learner_t.predict(X)
print('s-learner, by package, LR: {:.04f}, XGB: {:.04f}'.format(np.mean(ate_s), np.mean(ate_t)))
def calc_by_self(X, treatment, y):
# 构造训练数据
X_train = np.hstack((X, treatment.reshape((len(treatment), 1))))
X_1 = np.hstack((X, np.ones((X.shape[0], 1))))
X_0 = np.hstack((X, np.zeros((X.shape[0], 1))))
# 线性回归模型
lr = LinearRegression()
lr.fit(X_train, y)
y_1_lr = lr.predict(X_1)
y_0_lr = lr.predict(X_0)
predict_y_lr = y_1_lr - y_0_lr
# XGB 回归模型
xgb = XGBRegressor()
xgb.fit(X_train, y)
y_1_xgb = xgb.predict(X_1)
y_0_xgb = xgb.predict(X_0)
predict_y_xgb = y_1_xgb - y_0_xgb
print('s-learner, by self, LR: {:.04f}, XGB: {:.04f}'.format(np.mean(predict_y_lr), np.mean(predict_y_xgb)))
if __name__ == '__main__':
np.random.seed(20)
# y-观测结果;X-样本特征;treatment-处理变量;tau-个体处理效应
y, X, treatment, tau, b, e = synthetic_data(mode=1, n=10000, p=8, sigma=1.0)
calc_by_package(X, treatment, y)
calc_by_self(X, treatment, y)
从输出结果可以看出,手写实现与工具包实现的结果完全一致:
true causal effect: 0.5002480680349228
estimated causal effect, by package, LR: 0.6801, XGB: 0.5382
estimated causal effect, by self, LR: 0.6801, XGB: 0.5382
3.2 不同元学习器效果对比
下面的代码对比了 S-learner、T-learner、X-learner 和 DML 在同一数据集上的表现,主要评估指标为 ATE 和 AUUC。
import numpy as np
import pandas as pd
from xgboost import XGBRegressor
from causalml.inference.meta import BaseSRegressor, BaseXRegressor, BaseTRegressor
from causalml.dataset import synthetic_data
from econml.dml import CausalForestDML
from causalml.metrics import auuc_score, plot_gain
import matplotlib.pyplot as plt
def plot_sorted_tau_and_preds(df):
# 真实 tau 与四个模型预测结果
tau = df['tau_true'].values
preds = {
'S-learner': df['s-learner'].values,
'T-learner': df['t-learner'].values,
'X-learner': df['x-learner'].values,
'DML': df['DML'].values
}
idx = np.argsort(tau)
tau_sorted = tau[idx]
preds_sorted = {k: v[idx] for k, v in preds.items()}
x = np.arange(len(tau))
y_all = [tau_sorted] + [preds_sorted[k] for k in preds]
ymin = min([arr.min() for arr in y_all])
ymax = max([arr.max() for arr in y_all])
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
model_names = list(preds.keys())
for i, ax in enumerate(axes.flatten()):
ax.scatter(x, tau_sorted, label='True tau', color='black', s=10, alpha=0.7)
ax.scatter(x, preds_sorted[model_names[i]], label=model_names[i], color='tab:blue', s=10, alpha=0.7)
ax.set_title(f'{model_names[i]}')
ax.set_xlabel('Sample (sorted by tau)')
ax.set_ylabel('CATE')
ax.set_ylim(ymin, ymax)
ax.legend()
plt.tight_layout()
plt.show()
def calc_by_package(X, treatment, y, tau):
# S-learner
learner_s = BaseSRegressor(learner=XGBRegressor())
ate_s = learner_s.fit_predict(X=X, treatment=treatment, y=y)
print('estimated causal effect, by S-learner: {:.04f}'.format(np.mean(ate_s)))
# T-learner
learner_t = BaseTRegressor(learner=XGBRegressor())
ate_t = learner_t.fit_predict(X=X, treatment=treatment, y=y)
print('estimated causal effect, by T-learner: {:.04f}'.format(np.mean(ate_t)))
# X-learner
learner_x = BaseXRegressor(learner=XGBRegressor())
ate_x = learner_x.fit_predict(X=X, treatment=treatment, y=y)
print('estimated causal effect, by X-learner: {:.04f}'.format(np.mean(ate_x)))
# DML
cf_dml = CausalForestDML(model_t=XGBRegressor(), model_y=XGBRegressor())
cf_dml.fit(y, treatment, X=X)
ate_dml = cf_dml.effect(X)
print('estimated causal effect, by DML: {:.04f}'.format(np.mean(ate_dml)))
# 合并结果
df = pd.DataFrame({
'y': y,
'treat': treatment,
's-learner': np.ravel(ate_s),
't-learner': np.ravel(ate_t),
'x-learner': np.ravel(ate_x),
'DML': np.ravel(ate_dml)
})
df['tau_true'] = tau
print('true causal effect: {}'.format(np.mean(tau)))
# AUUC
auuc = auuc_score(df, outcome_col='y', treatment_col='treat', normalize=True, tmle=False)
print(auuc)
return df
if __name__ == '__main__':
np.random.seed(0)
y, X, treatment, tau, b, e = synthetic_data(mode=1, p=25)
result_df = calc_by_package(X, treatment, y, tau)
plot_sorted_tau_and_preds(result_df)
# 绘制 AUUC 曲线
plot_gain(
result_df,
outcome_col='y',
treatment_col='treat',
normalize=True,
random_seed=10,
n=100,
figsize=(8, 8)
)
plt.show()
结果解读:
- ATE 结果:X-learner 的预测最接近真实值,DML 和 S-learner 次之(前者整体偏低,后者整体偏高),T-learner 偏差最大。
estimated causal effect, by S-learner: 0.6588 estimated causal effect, by T-learner: 0.7255 estimated causal effect, by X-learner: 0.5699 estimated causal effect, by DML: 0.3762 true causal effect: 0.5116507638464373 - ITE 区分度:DML 的预测区分度最低,S-learner 和 X-learner 中等,T-learner 区分度最高。
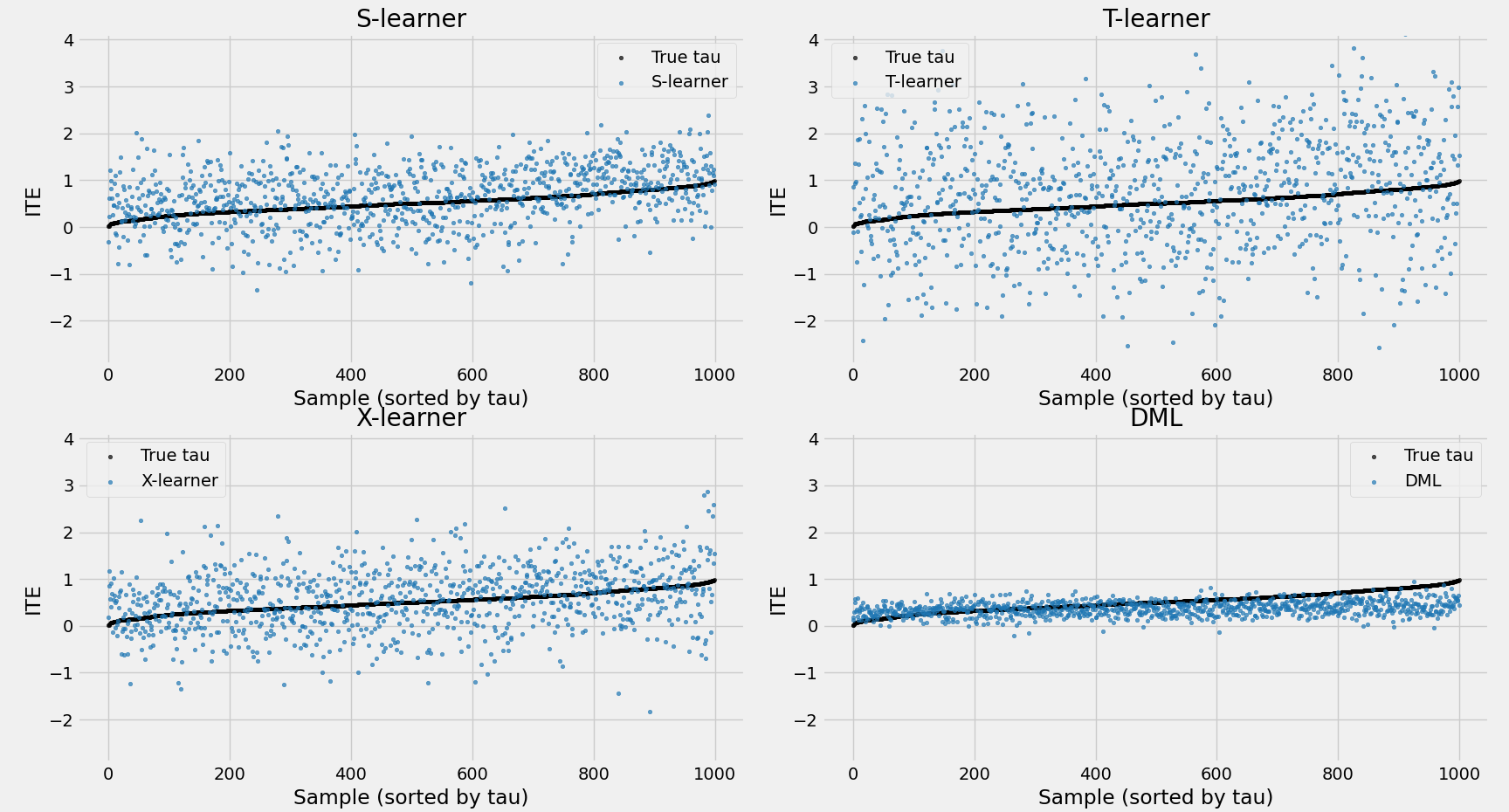
- AUUC 指标:排序能力从高到低依次为排序能力从高到低依次为 T-learner > S-learner > X-learner > DML。
s-learner 0.898929
t-learner 1.049052
x-learner 0.811587
DML 0.727232
tau_true 0.461501
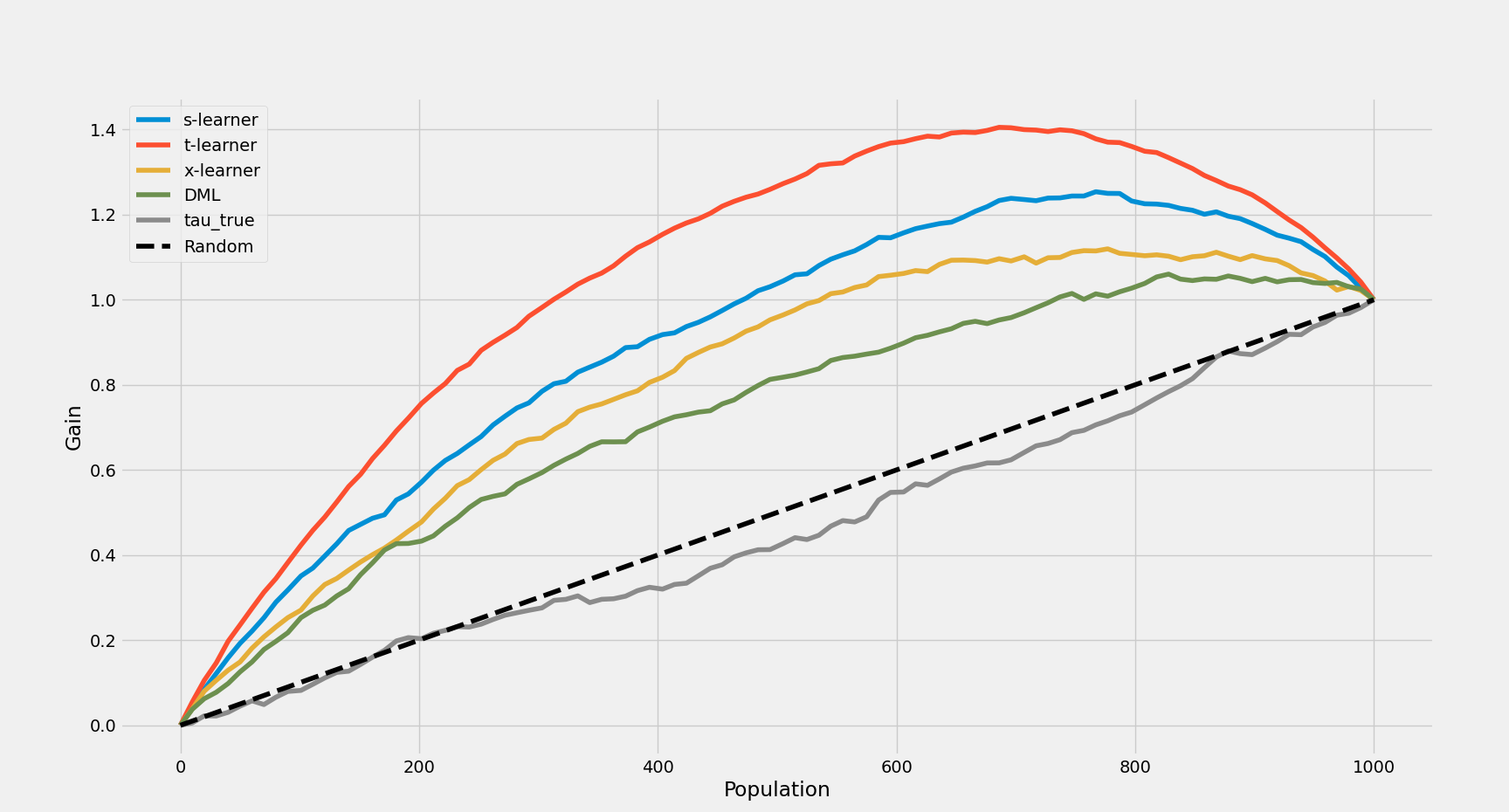
基于以上案例的模型评估结果,有两个值得进一步讨论的点:
ATE 和 AUUC 指标有时结论不一致
ATE 关注平均因果效应的准确性,而 AUUC 关注模型对个体排序的能力。举例来说,假设有 5 个个体,真实 ITE 分别为 [2, 1, 0, -1, -2],真实 ATE=0。如果一个模型预测 ITE 为 [0, 0, 0, 0, 0],则 ATE=0(与真实值一致),但排序能力极差(AUUC 很低);另一个模型预测为 [2, 1.5, 1, 0.5, 0],ATE 不为 0,但排序能力很好(AUUC 高)。实际场景中,指标选择要结合业务目标,比如广告投放更关注排序能力,此时 AUUC 更具参考价值。真实 ITE 的 AUUC 值未必最高
理论上,用真实 ITE 排序后计算 AUUC 应该最优,但实际由于我们无法观测到所有个体的潜在结果,AUUC 的计算通常基于观测数据的分桶均值差,具体逻辑可参考因果推断 | 潜在结果框架的基础知识。
4 总结
正文到此结束,核心内容总结如下:
元学习器在因果推断中的三种常见模型包括:S-learner、T-learner 和 X-learner,各自具有不同的建模思路和适用场景。
在模型评估方面,AUUC 和 ATE 两项指标关注的重点不同,可能导致评估结论不一致。ATE关注整体平均因果效应的准确性,而AUUC更强调模型对个体排序能力的优劣,实际选择应结合具体业务需求。
5 相关阅读
X-learner: https://arxiv.org/pdf/1706.03461
基于元学习的因果效应估计方法:https://zhuanlan.zhihu.com/p/644413135
causalml-meta learn:https://causalml.readthedocs.io/en/latest/examples/meta_learners_with_synthetic_data.html
因果推断 | 潜在结果框架的基础知识:https://mp.weixin.qq.com/s/8YrNm99g2BaGJusQKd_U7A