
前言:在智能视觉时代,目标检测已成为深度学习领域最具实用价值的核心技术之一。而 YOLO以其端到端的高效结构与卓越的实时性能,成为工程落地与学术研究中的明星算法。
本专栏 《YOLO目标检测最强通关秘籍》 从算法原理、模型设计到实验复现与工程部署,系统梳理 YOLO 系列的技术演进与关键创新,让复杂的模型调优和实战部署变得更系统。
一、技术背景与发展脉络
在目标检测领域,YOLO系列算法一直以其实时性和准确性的完美平衡而闻名。YOLOv5u作为Ultralytics团队推出的重要版本,代表了从传统anchor-based方法向无锚点检测的重大转变。这一转变不仅仅是技术上的升级,更是对整个检测范式的重新思考。
传统的目标检测算法依赖于预设的锚点框来预测目标位置,这种方法虽然在一定程度上提高了检测精度,但也带来了锚点框设计复杂、超参数调优困难等问题。YOLOv5u通过引入无锚点检测机制,彻底解决了这些痛点,为实时目标检测开辟了新的道路。
1. 无锚点检测的核心理念
无锚点检测的核心思想是直接预测目标的中心点坐标和尺寸,而不依赖于预定义的锚点框。这种方法最初在YOLOv8中得到验证,随后被成功移植到YOLOv5u中。
# 传统anchor-based预测
def anchor_based_decode(pred, anchors):
# 需要预定义锚点框
grid_x, grid_y = torch.meshgrid(torch.arange(width), torch.arange(height))
anchor_w, anchor_h = anchors[:, 0], anchors[:, 1]
# 复杂的锚点框变换
pred_x = (pred[..., 0].sigmoid() + grid_x) / width
pred_y = (pred[..., 1].sigmoid() + grid_y) / height
pred_w = torch.exp(pred[..., 2]) * anchor_w / img_width
pred_h = torch.exp(pred[..., 3]) * anchor_h / img_height
return pred_x, pred_y, pred_w, pred_h
# YOLOv5u无锚点预测
def anchor_free_decode(pred, stride):
# 直接预测相对于网格的偏移
pred_xy = (pred[..., :2] * 2 - 0.5 + grid_xy) * stride
pred_wh = (pred[..., 2:4] * 2) ** 2 * anchor_wh
return pred_xy, pred_wh
这种设计简化了预测过程,同时也提高了模型对不同尺寸目标的适应性。
2. 架构创新的技术细节
YOLOv5u的架构创新主要体现在检测头的设计上。传统的检测头需要为每个锚点框预测4个坐标值、1个置信度和若干类别概率,而无锚点检测头则直接预测目标的位置和类别信息。
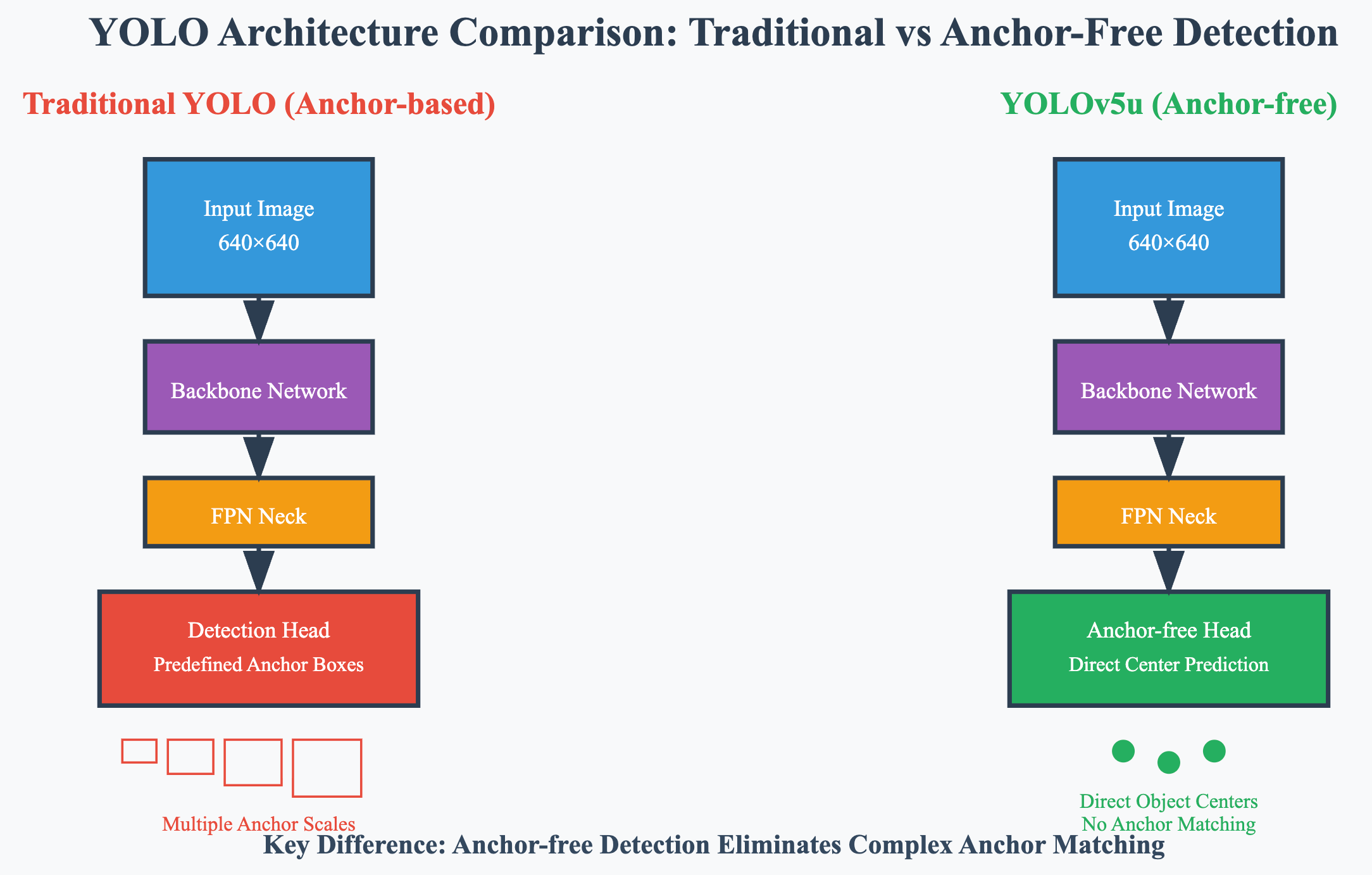
二、核心技术特性解析
1. 无锚点分割头设计
YOLOv5u采用的无锚点分割头是其最重要的技术创新之一。这种设计不仅简化了模型架构,还显著提高了检测精度。
无锚点分割头的工作原理是将每个网格单元看作一个潜在的目标中心点,直接预测该点是否包含目标以及目标的边界框参数。这种方法消除了锚点框匹配的复杂性,使得模型能够更加灵活地处理各种尺寸和形状的目标。
class AnchorFreeHead(nn.Module):
def __init__(self, num_classes, in_channels):
super().__init__()
self.num_classes = num_classes
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
# 分类和回归分支
for i in range(4):
self.cls_convs.append(
nn.Conv2d(in_channels, in_channels, 3, padding=1)
)
self.reg_convs.append(
nn.Conv2d(in_channels, in_channels, 3, padding=1)
)
# 最终预测层
self.cls_pred = nn.Conv2d(in_channels, num_classes, 3, padding=1)
self.reg_pred = nn.Conv2d(in_channels, 4, 3, padding=1)
self.center_pred = nn.Conv2d(in_channels, 1, 3, padding=1)
def forward(self, x):
cls_feat = x
reg_feat = x
for cls_conv, reg_conv in zip(self.cls_convs, self.reg_convs):
cls_feat = F.relu(cls_conv(cls_feat))
reg_feat = F.relu(reg_conv(reg_feat))
cls_score = self.cls_pred(cls_feat)
bbox_pred = self.reg_pred(reg_feat)
center_pred = self.center_pred(reg_feat)
return cls_score, bbox_pred, center_pred
这种架构设计使得模型能够更好地处理密集目标检测任务,特别是在目标重叠较多的场景中表现出色。
2. 精度与速度的优化平衡
YOLOv5u在保持高精度的同时,通过多项技术手段实现了推理速度的显著提升。这种平衡主要通过以下几个方面实现:
首先是网络结构的优化。YOLOv5u采用了更加高效的特征提取网络,减少了不必要的计算开销。其次是损失函数的改进,新的损失函数能够更好地指导模型学习,提高收敛速度。最后是后处理算法的优化,简化了NMS等操作,提高了整体推理效率。
这种优化策略使得YOLOv5u在各种硬件平台上都能保持良好的性能表现,无论是CPU还是GPU环境,都能实现理想的推理速度。
3. 多尺度预训练模型体系
YOLOv5u提供了从nano到extra-large的完整模型系列,每个模型都针对不同的应用场景进行了优化。这种多样化的模型设计使得用户能够根据具体需求选择最适合的版本。
小型模型如YOLOv5nu专注于移动端和边缘设备的部署,在保持基本检测精度的同时最大化推理速度。中型模型如YOLOv5mu则在精度和速度之间找到了良好的平衡点,适合大多数实际应用场景。大型模型如YOLOv5xu则追求最高的检测精度,适合对准确性要求极高的应用。
三、性能表现与技术评估
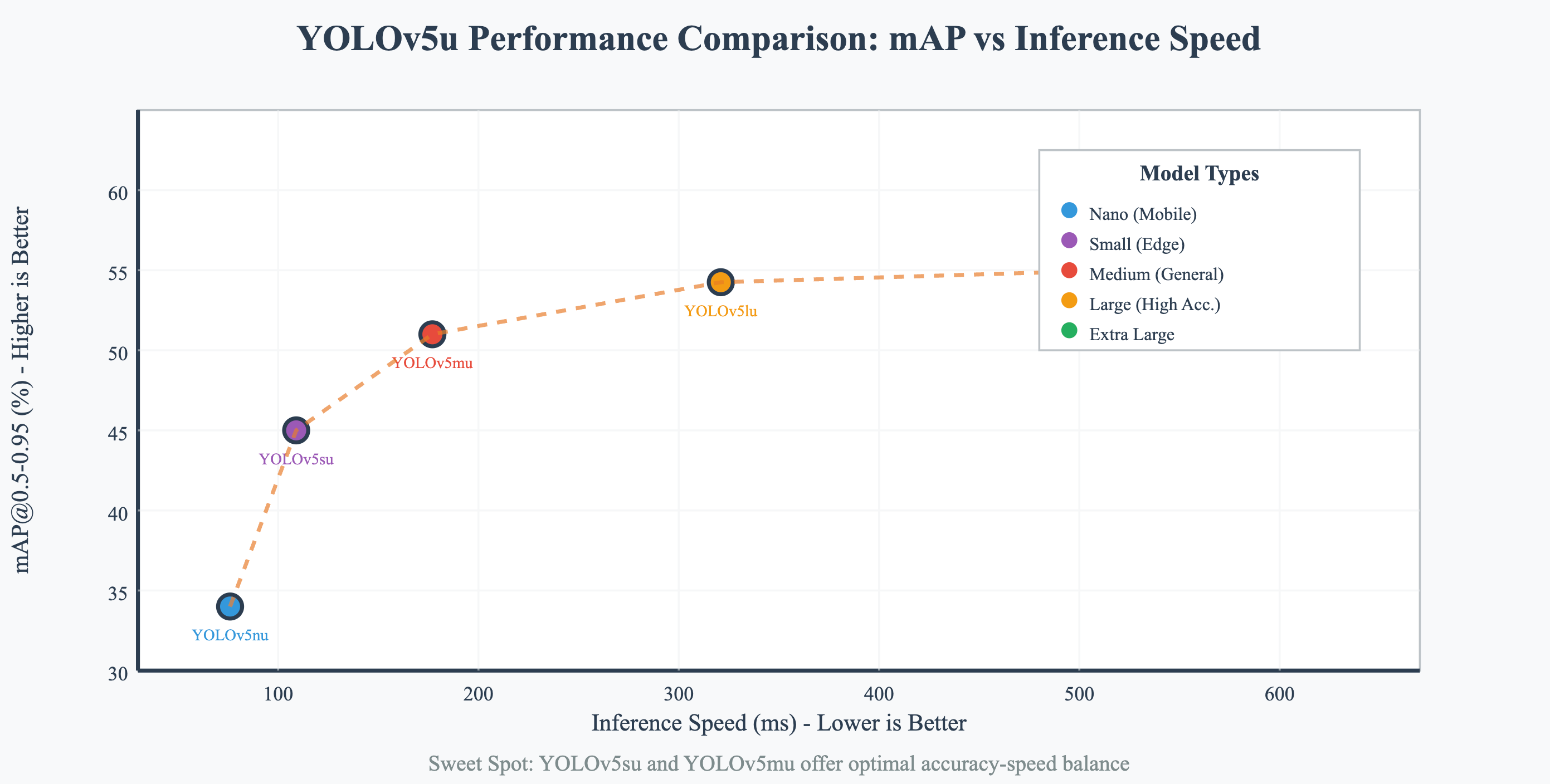
1. 基准测试数据分析
YOLOv5u在COCO数据集上的表现充分证明了其技术优势。从基准测试数据可以看出,不同规模的模型在精度和速度方面都有显著提升。
以YOLOv5nu为例,在640×640输入尺寸下,其mAP值达到34.3%,CPU推理速度仅需73.6ms,GPU推理更是快至1.06ms。这种性能表现在同类算法中属于领先水平。
更重要的是,YOLOv5u的性能提升不仅体现在单一指标上,而是在精度、速度、模型大小等多个维度上都有显著改善。这种全面的性能提升使得YOLOv5u成为了实际应用中的首选方案。
2. 不同硬件平台适配性
YOLOv5u经过精心设计,能够在各种硬件平台上高效运行。无论是传统的CPU环境、高性能GPU,还是专用的AI加速器,YOLOv5u都能发挥出色的性能。
在CPU环境下,YOLOv5u通过优化的ONNX格式能够实现高效推理,满足边缘设备的部署需求。在GPU环境下,特别是使用TensorRT加速的A100平台上,YOLOv5u的推理速度得到了进一步提升,能够轻松处理高帧率视频流的实时检测任务。
# 模型优化部署示例
import torch
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov5nu.pt')
# 导出为ONNX格式用于CPU推理
model.export(format='onnx', optimize=True)
# 导出为TensorRT格式用于GPU加速
model.export(format='engine', half=True, workspace=4)
# 量化优化
model.export(format='onnx', int8=True, data='coco.yaml')
3. 实际应用场景验证
YOLOv5u在多个实际应用场景中都展现出了优秀的性能表现。在自动驾驶领域,其高精度的目标检测能力和实时性保证了系统的安全性和可靠性。在工业质检场景中,YOLOv5u能够快速准确地识别产品缺陷,提高生产效率。
在视频监控领域,YOLOv5u的实时检测能力使其成为了理想的解决方案。无论是人员检测、车辆识别还是异常行为监控,YOLOv5u都能提供准确可靠的检测结果。
四、实践应用与开发指南
1. 快速上手训练流程
使用YOLOv5u进行模型训练的过程相对简单,但需要注意一些关键细节。首先需要准备符合要求的数据集,然后配置训练参数,最后启动训练过程。
from ultralytics import YOLO
import torch
# 检查CUDA可用性
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"使用设备: {device}")
# 加载预训练模型
model = YOLO('yolov5su.pt')
# 配置训练参数
train_results = model.train(
data='custom_dataset.yaml', # 数据集配置文件
epochs=100, # 训练轮数
imgsz=640, # 输入图像尺寸
batch_size=16, # 批次大小
workers=8, # 数据加载线程数
patience=10, # 早停耐心值
save_period=10, # 模型保存间隔
device=device, # 训练设备
project='yolov5u_training', # 项目目录
name='custom_model' # 实验名称
)
# 验证模型性能
val_results = model.val()
print(f"验证mAP: {val_results.box.map}")
训练过程中需要特别注意数据集的质量和标注的准确性,这直接影响到模型的最终性能。同时,合理的超参数设置也是获得好结果的关键因素。
2. 推理部署最佳实践
在实际部署时,YOLOv5u提供了多种推理方式,可以根据具体需求选择最适合的方案。
# 单张图片推理
def single_image_inference(model_path, image_path):
model = YOLO(model_path)
results = model(image_path)
# 获取检测结果
for result in results:
boxes = result.boxes
for box in boxes:
class_id = int(box.cls)
confidence = float(box.conf)
bbox = box.xyxy[0].tolist()
print(f"类别: {class_id}, 置信度: {confidence:.2f}, 边界框: {bbox}")
return results
# 批量图片推理
def batch_inference(model_path, image_dir):
model = YOLO(model_path)
import glob
image_files = glob.glob(f"{image_dir}/*.jpg") + glob.glob(f"{image_dir}/*.png")
results = model(image_files, stream=True) # 使用流式处理节省内存
for i, result in enumerate(results):
print(f"处理图片 {image_files[i]}")
# 处理结果...
# 视频流实时推理
def video_stream_inference(model_path, source=0):
model = YOLO(model_path)
results = model(source, stream=True, show=True)
for result in results:
# 实时处理检测结果
pass
3. 模型优化与加速技巧
为了在生产环境中获得最佳性能,需要对模型进行各种优化。这包括模型量化、剪枝、知识蒸馏等技术。
模型量化是最常用的优化技术之一,可以显著减少模型大小和推理时间。YOLOv5u支持INT8量化,能够在保持精度的同时大幅提高推理速度。
# 模型量化示例
def quantize_model(model_path, calibration_data):
model = YOLO(model_path)
# 导出量化模型
model.export(
format='onnx',
int8=True,
data=calibration_data, # 校准数据集
workspace=4, # 工作空间大小(GB)
verbose=True
)
print("模型量化完成")
# 使用TensorRT加速
def tensorrt_optimization(model_path):
model = YOLO(model_path)
# 导出TensorRT引擎
model.export(
format='engine',
half=True, # 使用FP16精度
workspace=4, # 工作空间大小
verbose=True
)
五、技术对比与发展趋势
1. 与其他YOLO版本的对比
YOLOv5u相比于其他YOLO版本,最显著的优势在于其无锚点检测机制和优化的网络架构。与YOLOv5相比,YOLOv5u在保持相同推理速度的情况下,检测精度有了明显提升。与YOLOv8相比,YOLOv5u继承了其无锚点检测的优势,同时在模型稳定性和部署便利性方面有所改进。
从技术发展的角度来看,YOLOv5u代表了YOLO系列算法向更加智能化和自适应化方向的演进。无锚点检测的引入不仅简化了模型设计,还提高了对复杂场景的适应能力。
2. 未来发展方向展望
目标检测技术的发展趋势正朝着更高精度、更快速度、更小模型的方向发展。YOLOv5u作为这一发展趋势的重要代表,为未来的技术发展奠定了坚实基础。未来的发展方向可能包括:更先进的特征提取网络、更智能的损失函数设计、更高效的后处理算法等。同时,随着边缘计算和移动设备的普及,模型轻量化和加速技术也将成为重要的发展方向。
YOLOv5u作为目标检测领域的重要进展,通过引入无锚点检测机制,成功解决了传统方法的诸多限制。其在精度、速度、易用性等方面的全面提升,使其成为了实际应用中的理想选择。在选择YOLOv5u的具体版本时,需要根据实际应用场景的需求进行权衡。对于资源受限的环境,推荐使用YOLOv5nu或YOLOv5su;对于精度要求较高的应用,可以选择YOLOv5lu或YOLOv5xu。