目录
背景补充
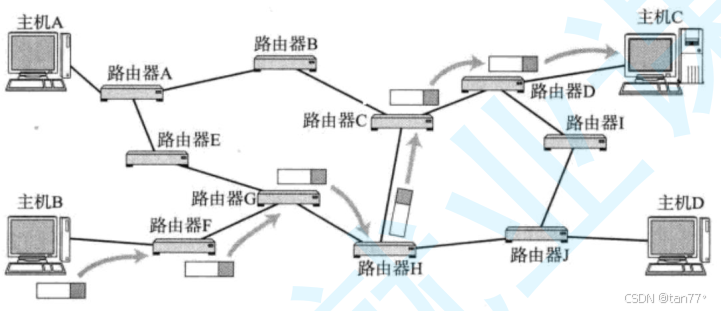
假设现在主机B要给主机C发送消息。在我们前面的学习中,一直都是将数据拷贝到主机B的发送缓冲区,然后通过网络,到达主机C,将报头分离,数据拷贝到接收缓冲区。对于数据在网络中的过程,我们是没有进行介绍的。我们要知道,主机B和主机C并不是直接连接的。中间是会经过非常多的路由器的。对于整个传输过程,此时会有2个问题:
1.路径选择问题。主机B为什么要将报文发送给路由器F呢?路由器F又为什么要将这个报文发送给路由器G呢?...目标决定路径,因为主机B要将报文发送给主机C。所以,这里就需要引入一个概念---IP地址,这里所说的IP地址是在全球范围都具有唯一性的IP地址。现在主机C的IP地址是确定且唯一的,未来主机B就可以根据主机C的IP地址,通过某种策略来进行路径选择。所以,路径选择的一个重要依据就是目标主机的IP地址。
2.主机B怎么将报文交给路由器F?主机B要将报文交给路由器F,则主机B和路由器F一定是处于同一个子网的,因为在同一个子网下是可以直接通信的。所以,主机B与主机C通信时,是通过无数的子网构成的信道通信的。
第一个问题是网络层的问题,第二个问题是局域网通信的问题,也是数据链路层的问题。关于IP协议,有两个协议,IPv4和IPv6,使用较多的是IPv4。IP地址用于标识主机的唯一性。
唐僧取经时,目的是到西天的大雷音寺找如来佛祖,这里如来佛祖就是进程,之前说过了,这里不用管。但是,唐僧来路上问路时,还没到西天时,就会问“西天怎么走?“,只有到了西天后,才会问"大雷音寺怎么走?“。所以,IP地址=目标网络+目标主机。我们将主机、路由器统称为节点。
协议头格式
网络协议栈每一层都解决不同的问题。应用层报头主要解决自身报文完整性、序列与反序列化问题;传输层报头主要支持进行流量控制、拥塞控制、超时重传、连接管理等。网络层在通信时要进行路径选择和报文的转发。
IP协议与TCP协议的关系
IP的核心作用:把报文跨网络转发到目标主机!到达目标主机的IP层后,就会进行解包,将其交给TCP/UDP了,进而通过端口号交付给上层应用。如果在转发过程中,这个报文丢包了呢?IP是不关心丢包问题的,因为TCP会处理丢包问题。所以,IP就是提供了一种能力,把数据从A主机,跨网络,转发给B主机的能力。但是,有能力就一定能做到吗?这是不一定的。所以,TCP提供了重发的功能。通过TCP+IP就能有一种可靠的能力,将数据从A主机跨网络转发给B主机的能力。这个可靠的能力解决的就是主机距离变长的核心问题。TCP协议用于解决转发的策略问题,IP协议用于解决具体转发问题。
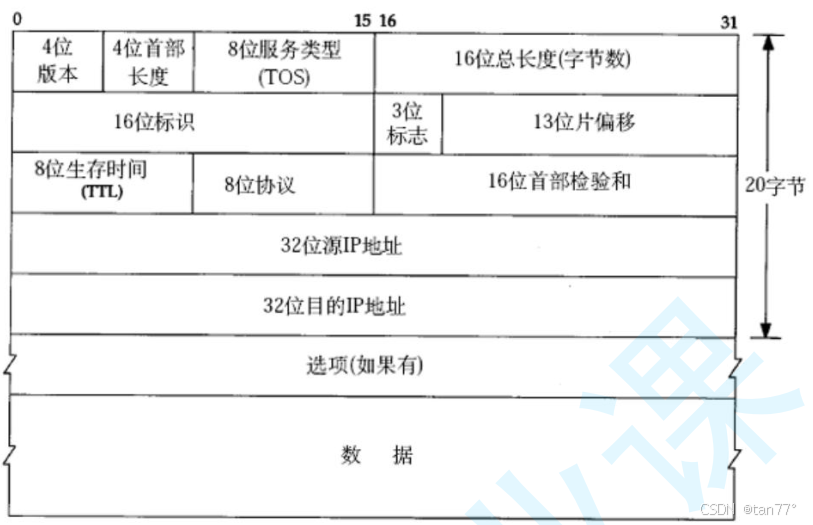
IP报头 = IP标准报头 + 选项。之前我们在学习套接字时,要将端口号、IP地址转为网络序列,就是由TCP报头和IP报头决定的。IP报头中的IP地址是32位的,所以一定不能是点分十进制的。并且接收方能够得到发送方的信息,也是由TCP报头和IP报头决定的。
这里的4位首部长度与TCP是完全相同的,记录的是IP报头的长度。16位总长度记录的是IP报头+有效载荷的长度。有了这两个字段后,就可以进行解包了。
- IP是如何解包的?如何封装的?
因为存在4位首部长度和16位总长度,所以可以进行解包的。封装与TCP也是一样的。 - IP是如何分用的?
IP报头中有8位协议字段,表示的是上层协议的类型。这里面填写的是TCP/UDP的协议号。TCP是6,UDP是17。
4位版本就是标识是IPv4,还是IPv6。IPv4的IP地址是32位的,最多能标识2^32个IP地址,已经不足了,所以就有了IPv6,IPv6使用128个位标识1个IP地址。但是IPv4和IPv6不兼容。并且要推广IPv6,不单单只是IPv6更好的问题,而是生态问题,即现在很多内容都使用的是IPv4,要修改这些现有的东西是很困难的。
8位服务类型:3位优先权字段(已经弃用),4位TOS字段,和1位保留字段(必须置为0)。4位TOS分别表示:最小延时,最大吞吐量,最高可靠性,最小成本.这四者相互冲突,只能选择一个。对于ssh/telnet这样的应用程序,最小延时比较重要;对于ftp这样的程序,最大吞吐量比较重要。举个例子帮助理解,假设唐僧在路过黑风岭时,人们都告诉他这里很危险,还是绕路走吧,唐僧认为从黑风岭过只需要1天,而绕路需要7天,所以还是选择从黑风岭过,在这里,唐僧在做路径选择时,是时间优先的。报文在网络中传输时,有些路径可能传输效率比较高,但是容易丢包;有些则传输效率比较低,如可能路径较长,但是不容易丢包。8位服务类型就是由OS设置报文的转发策略。
第二行的内容我们后面再介绍。网络是人搭建的,所以也是可能出现问题的,如可能出现环路问题,报文在一些路由器之间持续来回转发,这样就浪费了网络资源。所以我们要给网络报文设置一个TTL,这个TTL是一个计数器,每经过一个路由器就让这个计数器--,当TTL减小到0了,路由器就会将这个报文丢弃。16位首部校验用于检测和IP报头完整性,不用管。
IP报文的分片与组装
我们上面对于IP报头的第二行是没有介绍的。现在我们正式进行讲解,要理解第二行,就需要联合TCP进行理解。
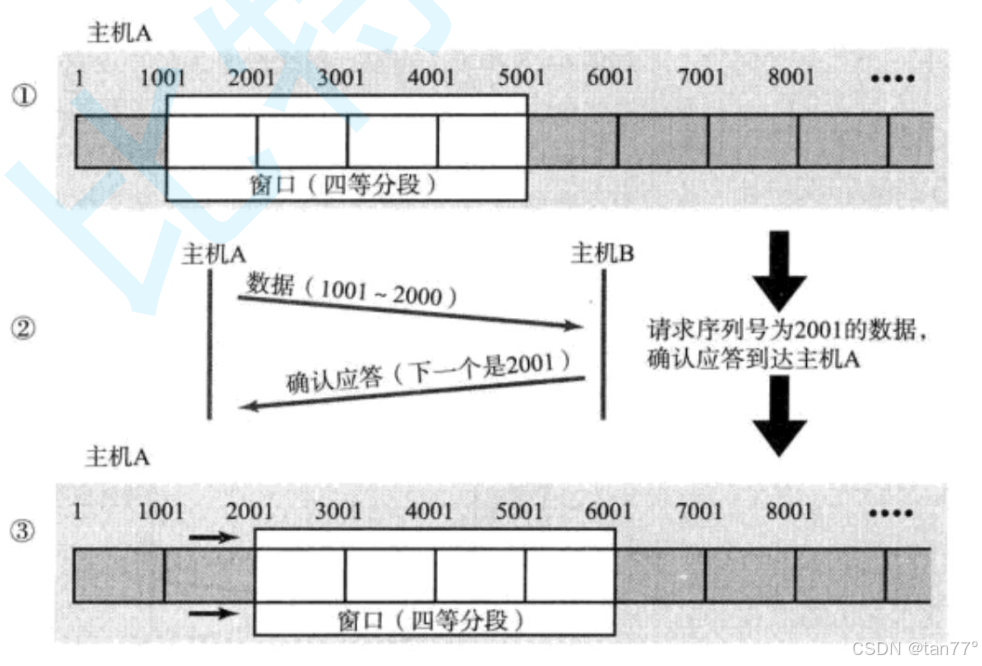
我们知道,TCP协议中存在一个叫做滑动窗口的东西,滑动窗口决定了发送方单次发送的数据总量,大小受拥塞窗口和对方接收缓冲区大小共同决定。为什么不把滑动窗口内的数据打包形成一条报文直接发送呢?而是要弄成多条报文发送呢?
当IP报文太长了,会将IP报文变成小报文,称为IP报文的分片问题。数据链路层规定,单次发送的数据帧的有效载荷长度不能超过MTU(一般是1500字节)。当IP报文太长时,将IP报文交给数据链路层就会被告知,此时就需要进行分片了,分片的工作是由网络层来完成的。对于分片后的报文,未来接收到时是需要进行组装的,由接收方的网络层进行组装。为了能够完成分片和组装的工作,IP协议的报头中就增加了3个字段:16位标识、3位标志、13位片偏移。
分片是好还是不好呢?
1. 其实上层根本就不关心网络层是否进行了分片、组装。对于传输层而言,发送方发送了1万字节,只要接收方能够接收到这1万字节的数据即可。
2. 假设发送方发送了1万字节的报文,现在将其分片成了10个报文进行发送,那么在发送的过程中,任何一个报文丢包了,就是不完整的。在传输层看来,就是丢包了。我们会发现,进行分片之后,丢包的概率增加了。所以,分片注定不能称为网络发送的主流。
如何不分片?
网络层的作用仅仅只是进行路由,真正决定发送多少数据,什么时候发的是传输层。所以,只要传输层不发送太长的报文即可不分片。所以,滑动窗口中的数据不是通过一个报文发送,而是分成多个报文发送,是为了减少分片。
UDP没有滑动窗口,所以UDP很容易造成分片问题,从而导致丢包概率增加。但是既然都使用了UDP,那么说明对于丢包问题并不关心,所以问题并不大。
IP报头中有一个字段是16位首部校验和。说明对于组装,并不会关心有效载荷的组装是否规范,只会检查IP报头的组装是否规范。并且TCP和UDP的报头中有校验和,这里不是首部校验和,用于检测整个报文是否完整。
如何进行组装呢?
IP 分片对传输层是透明的,这意味着传输层无需关心数据是否被分片以及如何重新组装。要知道如何进行分片和组装,需要先知道下面三个问题:
- 接收方如何得知自己收到的报文分片了?
- 接收方如何得知自己收到的分片收全了?
- 接收方如何组装形成完整的报文?
我们先来看一下IP报头中第二行的3个字段,了解了这3个字段就可以知道上面3个问题了:
- 16 位标识(id):唯一的标识主机发送的报文。正常来说每一个报文中都应该不同,但是如果IP报文在数据链路层被分片了,那么每一个片里面的这个id都是相同的。
- 3 位标志字段:第一位保留(保留的意思是现在不用,但是还没想好说不定以后要用到)。第二位置为1表示禁止分片,这时候如果报文长度超过 MTU,IP 模块就会丢弃报文。第三位表示"更多分片",如果分片了的话,最后一个分片置为0,其他是1。类似于一个结束标记。
- 13 位分片偏移:是分片相对于原始 IP 报文开始处的偏移。其实就是在表示当前分片在原报文中处在哪个位置。实际偏移的字节数是这个值除以8得到的。因此,除了最后一个报文之外(之前如果都是8的整数倍,最后一片的偏移量也一定是8的整数倍),其他报文的长度必须是8的整数倍(否则报文就不连续了)。
接收方如何得知自己收到的报文分片了?
我们来看看接收到的报文分片与没分片时,3个字段的数值:
- 没有分片,一个完整报文:16位标识,000,0
- 第一个分片 :16位标识,001,0
- 中间分片 :16位标识,001,!0
- 结尾分片 :16位标识,000,!0
所以,只要3位标志或13位分片便宜有一个不为0,这个报文就分片了。
接收方如何得知自己收到的分片收全了?
首先,根据16位标识,可以将所有分片放在一起,然后按照片偏移进行升序排序。将所有的分片收集到之后,可能会存在一些分片丢包了:
- 第一个分片丢包,排序完成之后第一片的片偏移不是0
- 结尾分片丢包,因为所有分片中只有结尾分片的3位标志字段是0,所以是可以知道的
- 中间分片丢包,下一个分片的偏移量 = 当前分片偏移量 + 当前分片长度,所以可以通过计算得知是否有中间分片丢包
当上面3种情况都没有出现时,就说明所有分片都收全了。
接收方如何组装形成完整的报文?
只需要保证接收到所有的分片,并排序之后,将其进行组装即可。
如果要分片,应该如何分片呢?
注意:分片指的是对IP报文的有效载荷进行分片。所以,所谓片偏移是数据相对于原始IP报文有效载荷的起始的偏移量。总长度是16位的,而片偏移只有13位。所以,片偏移具体的数字,必须是8的整数倍。当数据的偏移量是1480时,报头中的片偏移存的是1480/8=185。分片之后,每一片就是一个IP报文,所以每一个分片都要含有IP报头。
假设我们现在有一个IP报文,长度是3020字节,其中IP报头是20字节,有效载荷是3000字节。因为3020大于1500,所以是需要进行分片的。分片分的是有效载荷,所以对于报头不用管。
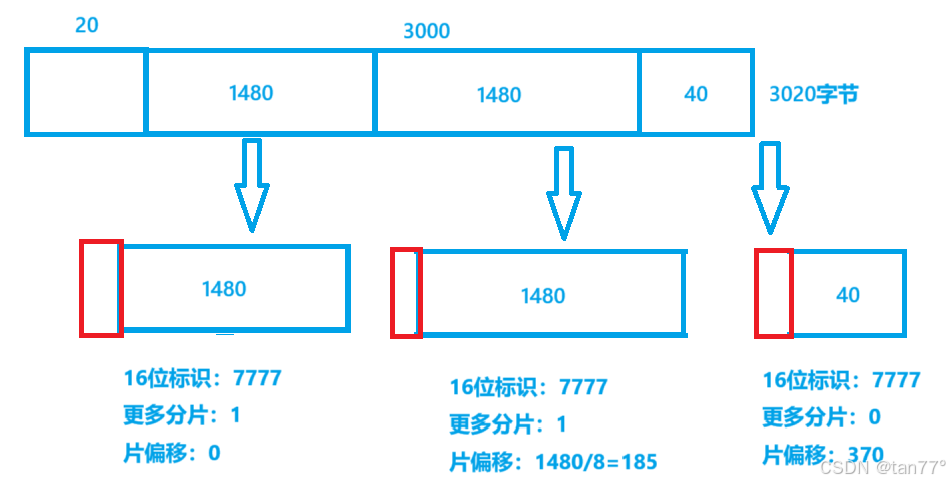
分片后的3个报文的IP报头拷贝自原先的IP报头,第二行的数据会进行修改。分片时最后剩下的一个报文长度不是8的整数倍时,可以进行填充,未来再根据IP报头的总长度将填充的去掉即可。
注意:分片、组装不一定只能在发送方和接收方进行,因为中途经过的一些路由器的MTU可能不是1500。因为有片偏移的存在,所以即使是二次分片了,也是可以组装的。但是这种情况出现的概率是非常低的。
网段划分
网段划分也叫子网划分。
网段划分是什么?为什么要进行网段划分?
唐僧在从东土大唐去往西天的过程中,西天是目标地址,但是如果没有从东土大唐到西天的路的话,是不能前往西天的。也就是说,有了目标地址,但是没路的话是无法到达目标地址的。所以,报文在网络中传输,光有目标IP地址是不够的。而路是被设计过的,所以网络也是被设计过的,也就是说,在报文转发过程中,会经历一个一个的子网,这些子网是被设计过的,使报文能从主机B到达主机C。设计网络的一个设计方案就是子网划分。所以,子网划分就是对网络进行人为的设置,使得未来可以通过物理网络和子网划分将报文发送到目标主机。当然,子网划分是硬件层面的,在转发过程中,还会配合软件层面的路由算法,通过软件+硬件,就可以将网络设施建设好了。这些网络设施是被谁设计的呢?是三大运营商设计的。
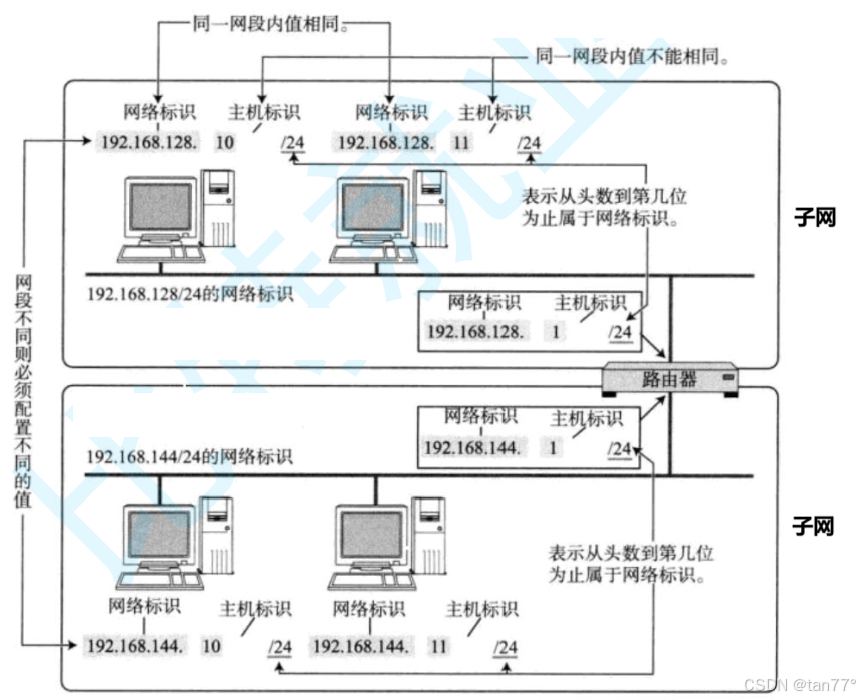
我们会发现,上面的子网内主机的IP地址都以192.168.128开头,下面的子网内主机的IP地址都以192.168.144开头。192.168.128.0叫做上面子网的网络号,192.168.144.0叫做下面子网的网络号。在一个子网内的所有主机的网络号是完全一样的,但主机号一定不一样。所以,IP地址=网络地址+主机地址。这样就能在一个子网内标识一个主机的唯一性。路由器负责的就是将报文从一个子网转发到另一个子网,所以路由器一定要有两个IP地址。
1.子网内的主机的IP地址是从哪里来的?
在一个子网中,路由器是第一个入网的设备。路由器具有构建子网的能力,也就是说,子网内的主机的IP地址是从路由器来的。当一个设备要上网时,就要先连接路由器,连接路由器就是向路由器申请一个IP地址。
2.路由器的IP地址是怎么来的?
路由器的网络标识一般都是固定的,而主机标识永远都是1。当一台主机连接了一个子网,获取到了一个IP地址后,是可以知道这个IP地址哪一部分是网络地址,那一部分是主机地址的。假设现在主机192.168.128.11要发送报文给192.168.144.10。主机192.168.128.11就会分析目标IP地址的网络地址部分与自己的网络地址进行比较,若相同,则就是局域网通信,发现不同,说明目标主机不在自己所在的子网内,但是它也不知道这个目标主机在哪里,此时只能将这个报文交给路由器。所以当子网被划分了,就自然有了转发算法。
- 有一种技术叫做DHCP,能够自动的给子网内新增主机节点分配IP 地址,避免了手动管理IP 的不便;
- 一般的路由器都带有DHCP功能。因此路由器也可以看做一个DHCP服务器。
根据一个IP地址进行报文转发,有两个阶段:
- 根据目标网络,转发报文到目标网络
- 转发到目标网络后,把报文进行内网转发
我们举一个例子帮助理解上面的过程。在大学中,会有非常非常多的学院,而每一个学院内的学生都会有学号,我们可以简单地将学号定义为学号 = 院号 + 编号。假设现在有计算机学院(01)、理学院(02)、文学院(03)、外国语学院(04)、化环学院(05)、医学院(06),对于每一个院,都会有自己的院群。假设现在计算机学院中有一名学生张三,学号是01023,医学院有一名学生李四,学号06077。校方为了方便管理每一个学院,所以会给每一个学院安排一个院学生会主席,这个主席本质上也是学生,所以他也要有学号,假设计算机学院的主席学号是01110,医学院的学生会主席学号是06120,并且这些学生会主席会统一拉入一个校群,以方便相互交流,也就是说,院学生会主席既在自己的院群,又在校群。现在,计算机学院的张三捡到了一个钱包,这个钱包当中有一个学生证,但是已经被损坏的有一些严重了,只能看清楚里面的学号,这个学号是06077。张三虽然不知道这个学号对应的学生是谁,但是他知道这个学生不是和自己一个学院的,在自己这个学院当中,知道这个学号属于哪一个学院的人,一定是院学生会主席。所以,张三会将这个学号06077和自己的电话发送到群聊当中,并@学生会主席,告诉学生会主席自己捡到一个钱包,并且失主一定不是我们院的。院学生会主席可能知道06是那个院,也可能不知道,但这并不重要,因为他在校群当中。计算机学院的学生会主席就会将这条消息转发到校群中,如果他知道06是医学院,他就会@医学院的学生会主席。无论是否@,这条消息最终都会被医学院的学生会主席拿到,医学院的学生会主席就会将这条消息转发到医学院的院群当中。他知道06077是谁就直接@他,不知道也无所谓,这样,06077的这位同学就能够看到这条消息了,消息内有张三的电话,李四就能联系上张三,从而拿回自己的钱包了。
在这个过程中,每一个学院就是一个内/子/局域网,院学生会主席就是路由器,校群是一个极简版的公网,张三发到院群中的数据就是目标IP+有效载荷。这条报文从内网转发到公网,再从公网转发到内网,即可发送到目标IP。张三能够这么高效地将消息发送给李四,是因为学校的结构是被精心设计过的。将不同的学生划分到不同的学院当中,就是子网划分的过程。
为什么要进行子网划分?因为子网划分后报文的传输效率变高了。为什么传输效率会变高呢?
在学校中,如果没有根据学院来划分学生,只是给每一个学生一个编号,那么要找到一个学生只能线性遍历。因为将钱包归还给别人本质上是一种查找,查找的本质是淘汰,所以当医学院的学生会主席拿到张三发出的消息,本质上是淘汰了计算机学院、理学院、文学院、外国语学院、化环学院。线性遍历时,一次淘汰1个人,而子网划分一次可以淘汰很多人。所以,子网划分之所以效率高,是因为淘汰的效率高了,进而导致查找效率高了。所以,之所以要进行子网划分,我因为支持网络建设,提高淘汰的效率。
在进入目标子网之前,张三、计算机学院的院学生会主席是不关心06077中的077这个数字的,只关心06。报文在进行转发的过程中,在到达目标网络之前,路由只看IP中的目标网络部分!!到达目标网络之后,才关心077,根据077做内网转发。IP=目标网络+目标主机,当我们进行路上路由的时候,只关心目标网络!!路由的基本单位是网络!!
怎么进行网段划分?
网段划分的具体做法
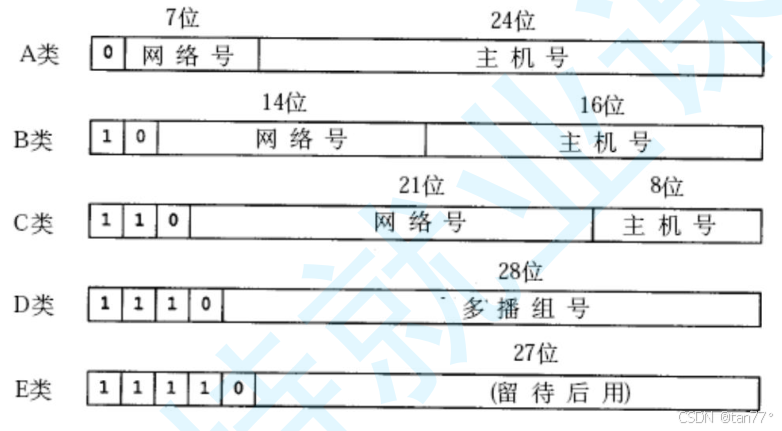
过去曾经提出一种划分网络号和主机号的方案,把所有IP地址分为五类。全球范围内,允许存在2^7个A类网络,每一个A类网络中允许存在的主机数是2~24个。申请网络时,并不是以国家为单位申请的。而是以公司、组织等为单位申请的,申请到网络之后,就可以对网络进行建设了。这种划分方案是有问题的。像A类、B类网络,本身是很多的,容易造成IP地址浪费的问题。针对这种情况提出了新的划分方案,称为CIDR。引入一个额外的子网掩码来区分网络号和主机号,子网掩码也是一个32位的正整数.通常用一串"0"来结尾,将IP地址和子网掩码进行"按位与"操作,得到的结果就是网络号,网络号和主机号的划分与这个IP地址是A类、B类还是C类无关。有了子网掩码后,就可以动态调整网络号和主机号的位数。
我们来看两个划分子网的例子:

虽然这里子网地址范围内有256个IP地址,但是实际上末尾全0或全1是无法使用的,称为特殊IP。末尾全0时,即140.252.20.0是网络号,末尾全1时,即140.252.20.255是广播地址。所以真正只有254个。

68的二进制是01000100,240的二进制是11110000,按位与的结果是01000000,所以按位与完就是140.252.20.64,这是网络号。子网掩码的最后是240,是11110000,说明前28位是网络号,后4位是主机号。主机号就是从0000-1111,所以就是140.252.20.64-140.252.20.79。有15个,但是实际上只有13个可以使用。
一个路由器会有2个子网掩码,分别与两个IP地址对应。
特殊的IP地址
将IP地址中的主机地址全部设为0,就成为了网络号,代表这个局域网;将IP地址中的主机地址全部设为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包;127.*的IP地址用于本机环回,通常是127.0.0.1。
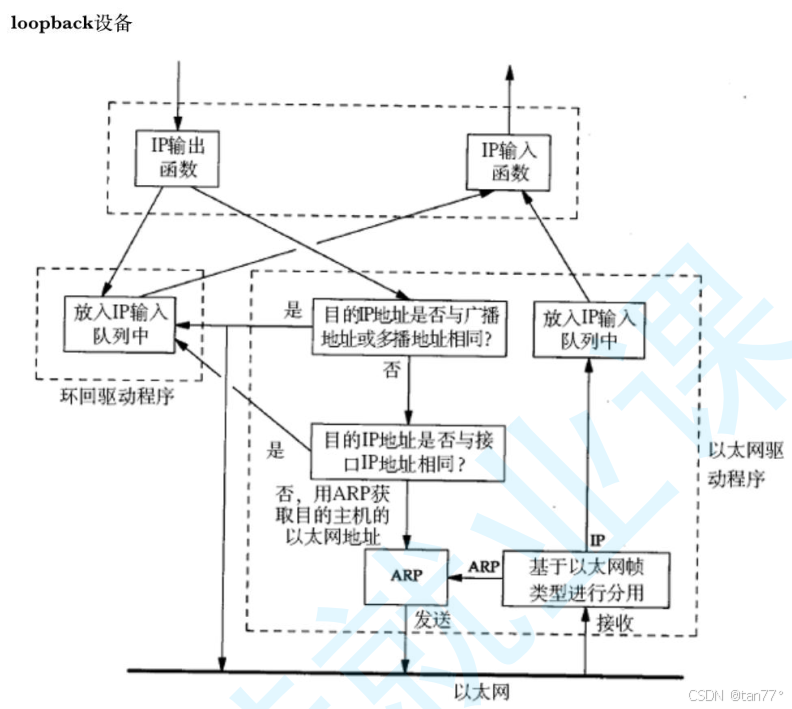
当目标IP地址是127*时,并不会走网络,而是走网络协议栈到IP层,然后判断,若发现是本主机,就将报文放到IP协议的输入队列中,然后就可以被本主机读取了不会到达链路层及下面的区域。
IP地址的数量限制
IP地址是一个32位的整数,所以总共会有2^32个IP地址,大约是43亿。并且由于一些特殊IP的存在,数量远不及43亿。CIDR在一定程度上缓解了IP地址不足的问题,但仍然是不够用的,有3种方法解决这个问题:
- 路由器动态分配IP地址:只给接入网络的设备分配IP地址.因此同一个MAC地址的设备,每次接入互联网中,得到的IP地址不一定是相同的;这是增加IP地址利用率的做法,它不能解决IP地址资源不足的问题;
- NAT技术,解决IP地址资源不足的问题的技术,后面说;
- 升级为IPv6。
私有IP地址和公网IP地址
可以将网络分为局域网和公网。在局域网内使用的IP地址称为私有IP地址。只能使用私有IP地址来组建局域网,不能出现在公网中。也就是说,在所有的IP地址中,切分出来一部分IP地址只能用于搭建局域网,这部分IP地址就称为私有IP。其余的称为公网IP。
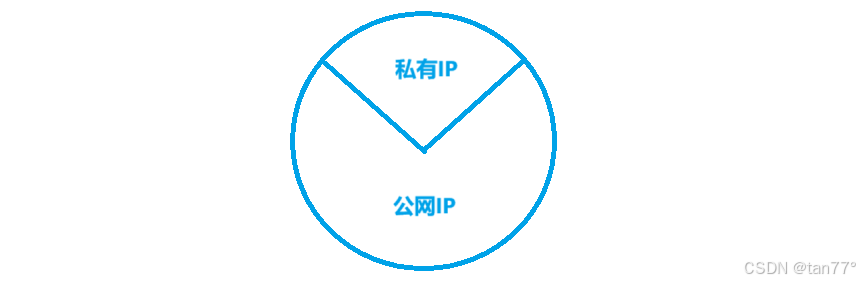
如果一个组织内部组建局域网,IP地址只用于局域网内的通信,而不直接连到Internet上,理论上使用任意的IP地址都可以,但是RFC1918规定了用于组建局域网的私有IP地址:
- 10.*,前8位是网络号,共16,777,216个地址
- 172.16.*到172.31.*,前12位是网络号,共1,048,576个地址
- 192.168.*,前16位是网络号,共65,536个地址
私有IP只在内网进行使用,所以不同的子网中,是可以出现相同的私有IP的,公网IP是不能重复的。可以使用ifconfig查看当前主机的IP地址和子网掩码:

上面3种私有IP地址种,从下往上的主机数是越来越多的,所以做家庭组网一般都是192.168,而在学校等场所可能使用的就是172.16,在大型组织或企业中,可能使用的就是10。所以,不同的组织根据自身规模的大小,会选择不同的私有IP来搭建自己的私有网络。网络建设的时候,在内网,在公网,统一采用各自的子网掩码的方式,进行网络建设!!
当我们在家庭中想构建子网,只需要买一个路由器即可,因为路由器具有构建子网的能力。路由器为什么有构建子网的能力?因为路由器可以给接入的主机分配私有IP地址,而私有IP可以直接被使用。构建子网/局域网,不仅仅我们在做,运营商也在做也就是说,从我们的路由器出去的报文不一定直接就到公网了,可能是先到另一个子网。
运营商
基本的网络情况
无论是申请公网IP,还是网络建设,都是运营商来做的。我们来看看具体的步骤。
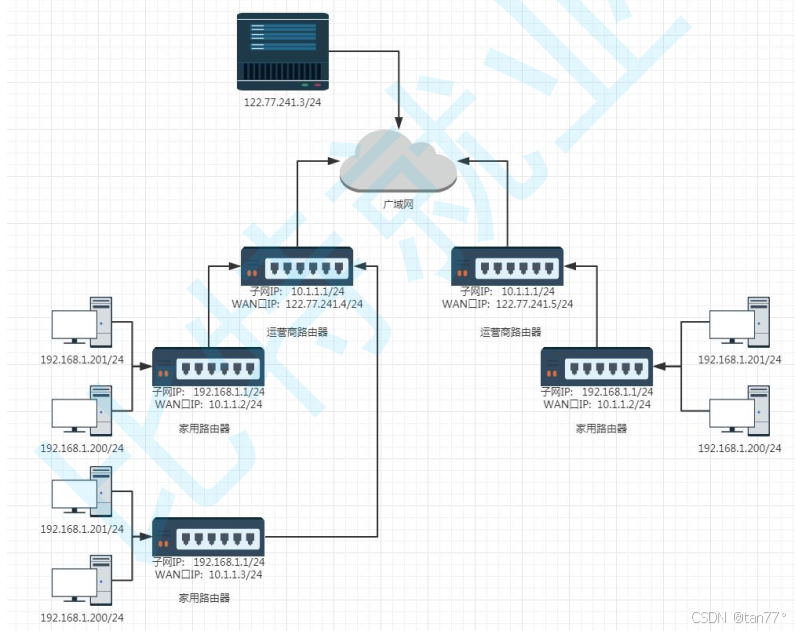
假设在家里想上网,就可以找运营商,运营商就会上门将网口弄好,将网线拉到家里,然后配备上路由器,然后设置好账号和密码,通过账号和密码就可以连接上家里的路由器了,因为路由器具有构建子网的能力,此时就构建好了家里的子网了。家里的IP地址通常是192.168开头的。
家里的路由器是不会直接连接广域网的,而是连接运营商的路由器,这个路由器构建的子网采用更大的私有IP,如172.16开头或10开头的,通常一个镇/区/市等有一个专门的路由器构建。这个子网属于运营商构建的,家里的路由器未来就会将报文转发到运营商构建的子网当中。所以,家里的路由器是横跨两个子网的,一个是家里的子网,由家里的路由器构建,一个是运营商构建的子网,由运营商的路由器构建。路由器分为家用路由器和企业路由器。企业路由器能够构建出更大的子网。
既然家用路由器会集连两个网络,那么它就需要配备有两个IP地址。图中192.168.1.1称为子网IP,也称为LAN口IP,10.1.1.2称为WAN口IP。当家里的路由器插上网线之后,不是立即构建自己的子网,而是先向运营商的路由器申请一个IP地址。所以,从家里路由器出去的报文,并没有到达公网,而是必须先到达运营商构建的一个更大的子网中。家里主机的报文一定能够交给家里的路由器,到达家里路由器的报文也一定能够交给运营商的路由器。
1. 我们在访问各个网页,使用各个应用时,都是需要网络的,为什么不是将钱交给这些网页或应用的开发者,而是将钱交给运营商呢?运营商在配置我们家里的路由器时,是会有账号的,这个账号通常就是手机号,未来没钱了,直接向这个手机号充钱即可。也就是说,路由器在配置时,会有两套账号体系,第一套体系是让运营商识别我们的家用路由器的,当家用路由器连接上运营商的路由器时,就会将账号,也就是手机号推送到运营商的路由器,运营商的路由器就会判断这个手机号是否有话费,若有话费,就允许将这个路由器发送过来的报文转发到公网上,没有则不转发;另一套账号体系是家用路由器构建的子网的名称和密码,供人们进行连接的。所以,我们的报文未来必须经过运营商的路由器做转发,才能到达公网!所以交钱需要交给运营商。
2. 运营商可以因为你欠费不让你如公网,也可以因为你访问的目标IP地址非法而拦截你。当我们要访问谷歌官网时,运营商就会识别出这个域名对应的IP地址是海外IP,是不合法的,就拦截。所以科技上网的本质就是骗过运营商,让运营商识别不出来这个IP地址。
假设我们今天要访问抖音的服务器,抖音的服务器肯定配备了公网IP,比如说是122.77.241.3,而当前主机的IP地址是192.168.1.201。每个主机都会有自己的路由表,其中就有自己的IP地址和子网掩码,将自己的IP地址和子网掩码进行按位与就可以获取到自己的网络号,再将目标主机的IP地址与自己的子网掩码进行按位与即可得到目标主机的网络号。所以它是可以判断出122.77.241.3这个IP地址对应的网络号不是自己当前的网络的。当发现不是,这台主机就会将这个报文发送给当前子网内的路由器,发送到路由器之后,路由器就会将122.77.241.3与自己的子网掩码进行按位与,发现不是运营商路由器构建的子网,就会将这条报文推送给运营商的路由器。上面的图只是一个简化的图,实际上运营商的出口路由器可能会有很多层状结构,从而搭建出一个非常复杂的子网结构,但是不需要管,因为这并不影响报文通过运营商的出口路由器发送到公网当中。当报文被转发到公网之后,就可以转发到目标主机了,具体细节后面说。抖音的服务器肯定也是在某一个内网当中,这个内网的入口路由器就会判断发送过来的报文是否是当前内网的,发现是,就做内网转发即可。
抖音的服务器接收到请求之后,就需要发送回一个应答,怎么发送应答呢? 如果应答的报文中的目标IP地址填入一个192.168.1.201,此时是无法转回来的,因为这是一个私有IP。所以,发送报文时真正的步骤是这样的。从主机发送出去时,源IP地址是192.169.1.201,目标IP地址是122.77.241.3,当报文每转发到1个路由器,就回将这条报文的源IP地址修改成这个路由器的WAN口IP,因为私有IP是不能出现在公网或另一个子网当中的,先修改为10.1.1.2,再修改为122.77.241.4,然后就可以通过公网进行转发了。抖音服务器的应答报文中,源IP地址是122.77.241.3,目标IP地址是122.77.241.4。此时通过公网,就可以将这个应答报文发送给之前发送的出入口路由器处。我们将内网到公网做源IP地址替换的技术称为NAT技术。具体如何将报文从运营商的出入口路由器转到发送报文的主机上,后面再说。为什么NAT技术能缓解IP地址不足的问题?因为它单独切分了一部分IP,只用它来做内网,这样IP地址可以被重复利用了!!!
全球网络
公网本质上是对全球的公网IP进行划分的过程。公网IP是以国家,组织,公司,学校等为单位,进行申请的。我们这里就以国家为例。假设美国申请的IP地址是1.0.0.0/8,俄罗斯是2.0.0.0/8,韩国是3.0.0.0/8,日本是4.0.0.0/8,法国是5.0.0.0/8,中国是6.0.0.0/8,英国是7.0.0.0/8,这里/8的意思是IP地址的前8位表示网络号。每个国家都会有一个国家级别的国际路由器。当然,每一个国家都会有多个IP地址,且有多个国际路由器,这里简便一点,就看1个。这些国际路由器会在同一个网络当中。
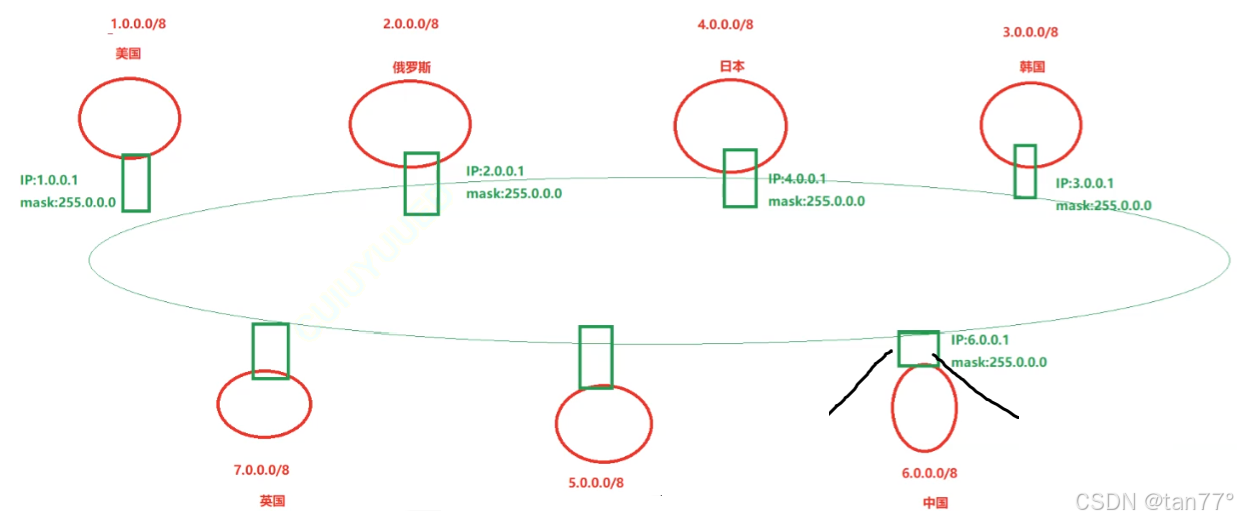
因为这些路由器都是位于同一个子网的,所以,未来每个国家都可以将自己的网络号、子网掩码等通过网络告诉其他国家,所以每一个国家的国际路由器中都可以维护一个路由器表目,我们以美国的路由器为例:
| 目标网络 | 子网掩码 | 地区 | 下一跳 |
| 1.0.0.0 | 255.0.0.0 | 美国 | |
| 2.0.0.0 | 255.0.0.0 | 俄罗斯 | |
| ... | |||
| 6.0.0.0 | 255.0.0.0 | 中国 | 6.0.0.1 |
| ... |
中国划分到的网段就是6.0.0.1/8,所以网段划分的直接体现就是把IP地址的若干位充当子网的入口,将配置信息体现在路由器当中。全球都以这种做法来做,就可以在全球范围内进行网段划分。中国拿到的是6.0.0.1/8,剩下的24个比特位就可以由中国自由支配了。
现在中国的IP地址就是6开头的,然后要怎么再划分呢?因为前8个比特位已经划分过了,所以我们使用接下来的8个比特位进行划分省份,我们这里只列举几个省份。每个省也会有一个省级的路由器。将中国内部的所有省的省路由器和中国的国际路由器放到同一个网络当中。当一个省成功接入网络,就会将自己的省路由器的网络号和子网掩码发送给这个子网当中的所有路由器。同样可以维护一个路由器表目,与上面是一样的。这里是可以继续对公网划分的,比如说再进一步划分到市,但是道理是一样的,这里就到省即可。
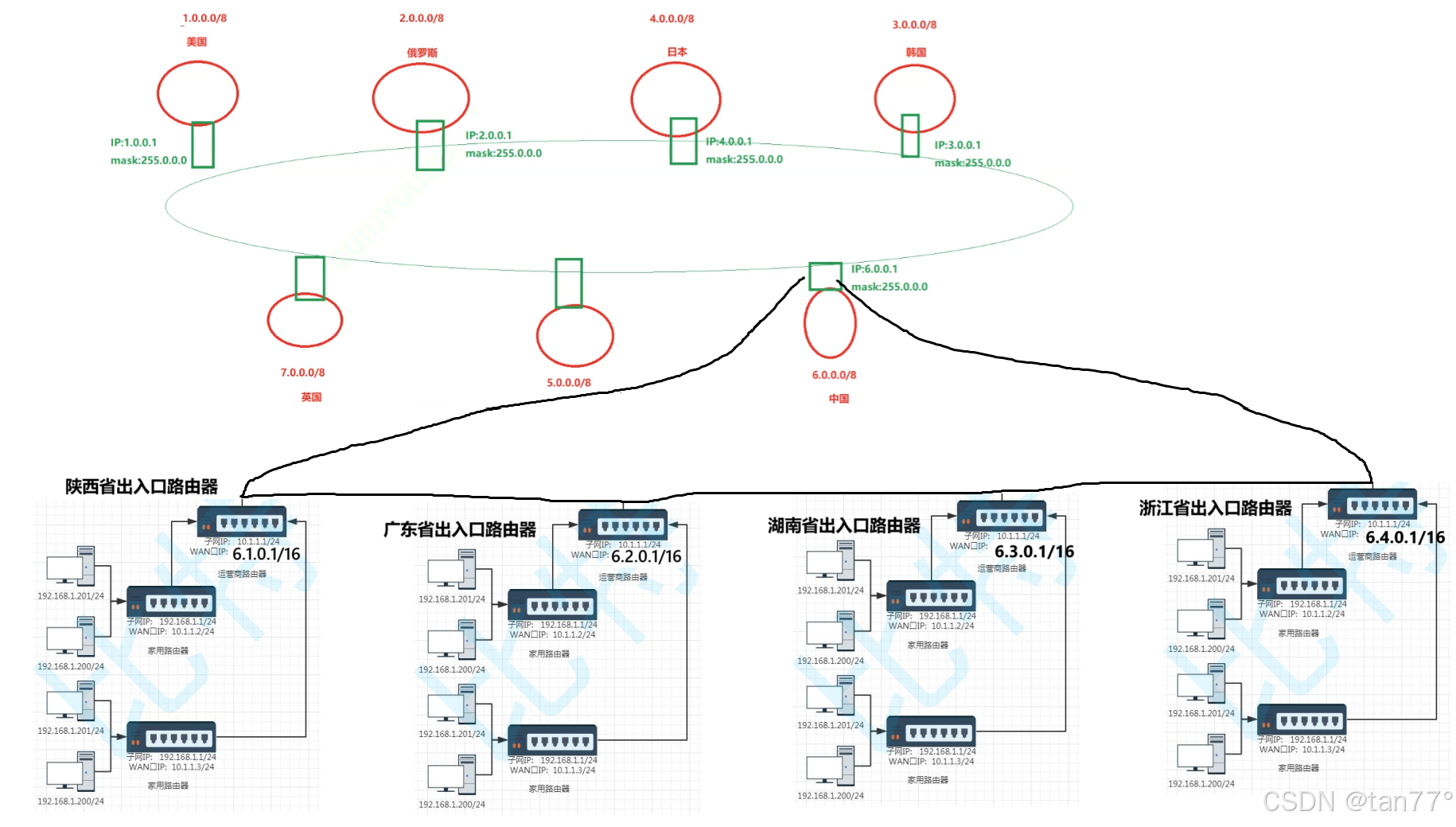
此时国内每一个省的运营商就可以组件省内的局域网了。当然也可以在省内进行市级别的公网IP划分,其实就是扩展子网掩码。但是这里就不做了。每一台路由器都会有一个缺省路由器,当路由器拿到一个不认识的IP地址时,就会将报文交给缺省路由器,家里主机的缺省路由器是家里的路由器,家里路由器的缺省路由器就是运营商的路由器,省级路由器的缺省路由器是国家级路由器。


这里的Destination和默认网关就是缺省路由器的IP地址。
这里需要说明一下,在NAT中,并不是每经过一个路由器就会变换一下源IP地址,而是每经过一个内网才会变换,假如从广东省的一台主机给美国发消息,那么这个消息到美国时,源IP地址是6.2.0.1/16,而不是6.0.0.1/8。当美国内部的主机接收到消息后,会进行应答,报文到达美国的国家级路由器时,就会将6.2.0.1与这个路由器的子网掩码进行按位与,得到6.0.0.0,然后查看这个路由器的路由表目,得到下一跳是6.0.0.1,就可以通过公网发送到中国了。
所以,现在我们已经知道了一个报文从内网 -> 公网 -> 内网的过程了,当然,传输时也不一定每次都会到公网。至于到了目标主机的内网后,怎么将报文转给目标主机,后面说。
路由
当网络的设施建设好了,其实大部分路由问题就已经解决了。路由器一般要尽可能地帮助我们进行路由,所以路由器要配置默认路由,也叫缺省路由。也就是说,当报文到达了某一个路由器,进行路由时,路由器一定不能说不知道,而是一定要告诉报文下一个目的地是哪里。注意:不仅仅是路由器有缺省路由,主机也有缺省路由。
当报文到达某一个路由器进行路由时,无非就是3种情况。当路由器不知道IP地址是谁时,直接将报文交给缺省路由器;当路由器知道IP地址是谁时,直接将报文交给指定的路由器;当前这个路由器就是报文的目标IP地址是入口路由器。在这个过程中,都是根据目的网络进行路由的。当到达了目标IP的入口路由器时,就需要进行内网转发了。
我们现在已经知道了路由的一个宏观过程,那么在报文到达每一个路由器时,是怎么进行路由的呢?所以,主机和路由器在网络层都配备了自己的路由表!可以通过route查看路由表。

Destination是网络号,Genmask表示的是子网掩码,Iface是网络接口,Flags带U时,表示这个条目是有效的,Gateway是下一跳IP地址。当一个报文到达了一个路由器时,路由器就会拿着报文中的目标IP与自己路由表中的子网一个一个按位与,查看按位与后的结果是否与这个子网掩码对应的网络号相同。如果相同,直接通过Iface的网络接口转发到指定的网络;若都不相同,就通过default的Iface进行转发,default就是缺省路由。
上面的图是云服务器的路由表,毕竟不是真的路由器,所以并不是很详细,我们来看一张真实的路由器的路由表:

我们会发现,为什么在进行内网转发时,下一跳的IP地址是*呢?这是因为在进行内网转发时,是数据链路层的工作,更加关注的是MAC地址。后面说。
路由表生成算法
一个路由器是怎么知道他的缺省路由是谁?一个路由器是怎么知道他所在的子网当中其他路由器的信息的?路由表可以由网络管理员手动维护(静态路由),也可以通过一些算法自动生成(动态路
由)。我们可以直接将其理解成路由器上线之后,可以向他所在的子网广播自己的网络信息,然后他再记录下与自己直连的网络即可。