前言
这是一个新的栏目,针对与已经学习了C语言的读者,这个栏目的前期(数据结构入门)只会只用C语言的语法进行数据结构的实现,在数据结构进阶的阶段会使用C++的STL来进行实现更高阶的数据结构,数据结构和算法是程序员的基础中的基础,所以打好基础很重要,如果你学的很吃力,那么就是练的不够多,见得不够多,人与人之间的差距并不在智力上,而在于勤奋与坚持,当你怀疑自己是不是不够聪明的时候,倒不如更加努力,与君共勉!
目录
1.时间复杂度
本质上就是从数学的角度衡量算法的优劣。
时间复杂度的概念:在计算机科学中,算法的时间复杂度是一个函数(数学意义上),定量描述了该算法的运行时间;但是一个算法的执行所耗费的时间是不能算出来的,只有将程序进行运行才能知道这个算法在这台机器上所用的时间是多少,那么每一个算法都需要上机运行吗?所以会有时间复杂度这个分析方式,一个算法所花费的时间与其中语句的执行次数成正比,所以算法的基本操作的执行次数,为算法的时间复杂度。
1.1 时间复杂度的计算
判断下面的代码基本语句执行的次数:

双层循环执行了n^2次;
单层循环执行了2n次;
单层循环执行了10次;
可以使用以下公式表示:
如果要表示一个算法的时间复杂度一般使用大O的渐进表示法 :
当N越大,函数的其余表达式可以忽略不计,只需要关注对结果影响最大的项数(一般是次方最高的那一项),如果次方数最高的那一项带系数,那么系数可以忽略不计,如果整个表达式都是常数我们可以使用:
来表示时间复杂度。
实例1:时间复杂度为O(N)

实例2:时间复杂度为O(M+N)
题目中没有明确M远大于N,或相反,那么在数量级不清楚的情况下,那么就将数量级相加。

实例3:时间复杂度是O(1)
影响代码效率的只有常数。

实例4:在一个数组中查找一个数
分为三种情况:
最好情况:1次找到;
平均情况:N/2次找到;
最坏情况:N次找到;
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索时间复杂度为O(N)。
实例5:冒泡排序的时间复杂度?

准确的时间复杂度函数为:
我们思考一下冒泡排序的流程:如果是一个降序数组(最坏情况),需要进行升序排序,首先最大的数需要进行交换N-1次,次大需要交换 N-2次,次最小的数只需要交换一次就够了,看着公式,我们知道这是一个等差数列,套入公式:(首项 + 尾项) * 项数 / 2 为:
忽略系数,那么最坏的时间复杂度就是O(N²);
那么最好的时间复杂度 ,如果已经是一个升序数组,我们只需要遍历一次数组即可,所以最好的时间复杂度是O(N)。
实例6:二分查找的时间复杂度

有的读者可能会认为二分查找的时间复杂度是O(N),那么如果按照顺序查找,时间复杂度依然也是 O(N),那么二分查找就失去了它的意义;
先说答案,二分查找的时间复杂度为:
先回顾一下二分查找的算法:每次只需要查找当前数组区域的一半;可以这么理解:如果这个数组的长度为N,第一次查找只需要查找的数组长度为,知道最后一次查找(最坏情况),此时查找的数组长度是1,此时只需要查找1次。
每次只需要对当前区域除以2,N÷2÷2÷2÷2÷2÷2÷2÷2÷2....÷2÷2÷2 = 1,每一次÷2就是一次二分查找,我们只需要知道除了多少个2,就知道进行二分查找了多少次,此时做一个简单的数学运算:
N = 2×2×2×2×2×2×2....×2×2×2
即:其中x是2的个数,或者查找的次数
经过数学运算:
有些同学对这个复杂度的大小和N的复杂度之间的差距并不是很理解,那么我们举一个简单的例子:在中国使用人口普查,如果使用遍历的算法,需要大概14亿次,那么使用二分查找法只需要31次就够了,如果在全世界找一个人(80亿以内),也只需要33次。所以这个算法的时间复杂度是优于遍历查找的复杂度N的。
但是二分查找也是一个非常挫的算法,在使用二分查找算法的时候,需要保证一个大前提就是数组是有序的,那么这个工作量就非常大了;
实例7:阶乘递归的时间复杂度

F(N)->F(N-1) .....F(N),一共需要递归N次
递归算法计算时间复杂度公式:
递归次数 * 每次递归函数中的时间复杂度
例如上面的递归函数,一共需要递归N次,每一个递归函数中就只有一条语句,那么可以认为时间复杂度是O(1),N * 1 = N;
如果在递归函数中写了一个循环,循环了10次,此时时间复杂度:N * 10 = 10N,10作为系数可以省略,这里还是O(N);若循环次数是N,那么此时递归的时间复杂度为O(N²);
实例8:斐波那契递归的时间复杂度

首先看递归函数内部的时间复杂度是O(1);
那么递归了调用了多少次呢?纯靠想象很难想象出来,这里需要画图分析:
斐波那契的函数天生就是一个递归:

①斐波那契调用到1为止,所以这里一共有n层;
②如果从第0层开始,那么最后一层是第n-1层,最后一层就有个元素(递归调用)。
③那么只需要将每一层的元素相加就是一共递归调用了多少次:
利用等比数列求和公式可以算出结果。
注意观察上面图片的右侧部分会先调用到fib(1),所以这就会导致右侧部分缺失,这里并不是满的“二叉树”,但是这一部分对于整体而言无伤大雅,所以还是使用O()来作为斐波那契的递归时间复杂度。
O()的时间复杂度已经非常非常慢了,这里不建议使用这类代码。
那么我们可以直接进行优化,定义第一个、第二个斐波那契数,剩下的斐波那契数直接通过第一个、第二个斐波那契数进行递推即可,这样处理的时间复杂度是O(N);
如果要求第30个斐波那契数,那么只需要运算30次即可,如果使用递归,那就是10亿次。
使用空间换取时间的做法,是非常明智的,以下是优化后的代码:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<malloc.h>
// 求出第整个斐波那契数列
long long* fib(size_t N)
{
// 这里N+1,即使N为0,arr也不会是野指针
long long* arr = malloc(sizeof(long long) * (N + 1));
arr[0] = 0;
arr[1] = 1;
if (N == 0)
{
return arr;
}
// 本质上有N+1个元素
for (int i = 2; i <= N; i++)
{
arr[i] = arr[i - 1] + arr[i - 2];
}
return arr;
}
int main()
{
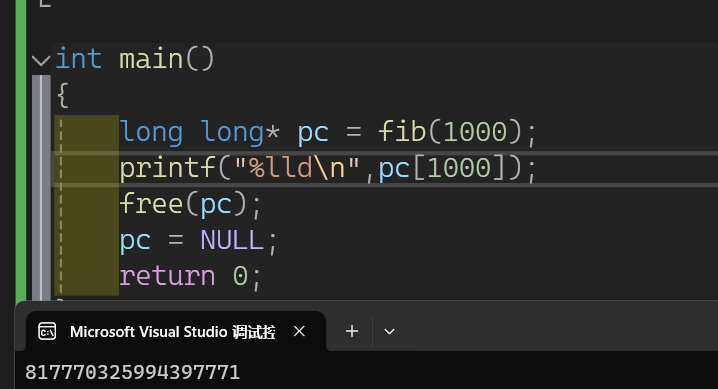
long long* pc = fib(50);
printf("%lld\n",pc[50]);
free(pc);
pc = NULL;
return 0;
}即使是第50个斐波那契数,也只需要计算50次,1000次、10000次瞬间就可以完成计算,注意这里是需要算出整个斐波那契数列,如果要求第N个斐波那契数,就不需要定义数组了,直接可以在三个变量之间进行迭代。
2. 空间复杂度
之前我们介绍了时间复杂度的计算,时间复杂度的计算不计算时间,只计算大概运算的次数;
同理空间复杂度不计算空间,只计算大概定义的变量的个数。对于不同的数据类型,我们一致认为变量和变量之间没有区别,都当做一个普通变量,只需要统计变量的个数即可。
实例1:空间复杂度O(1)

冒泡排序中一共存在5个变量(形参、临时变量),就是O(1)的复杂度。
实例2:空间复杂度O(N)

这里定义了一个长度为N的数组。
实例3:递归空间复杂度O(N)

每一次调用自己的时候,会开辟一个函数栈帧,每一个函数栈帧中有常数个变量,其空间复杂度可以视为O(1) ,那么需要调用自己N次,就需要在内存中开辟N个函数栈帧,所以空间复杂度是O(N)。
思考:斐波那契递归的空间复杂度是多少?
很多读者可能会认为是,因为这个函数被调用了
次,但是实际上是
,这和函数栈帧有关,简单地说,当函数被调用返回值之后,栈空间就会被释放,如果计算f(5),累计调用的次数确实是
,但是基于之前说的,我们需要判断的是峰值空间占用,而不是累计空间占用,也就是说按照某一时刻最多占用空间的数量(栈深度)就是空间复杂度。
面试题1:消失的数字
数组nums包含从0到n的所有整数,但其中缺了一个。请编写代码找出那个缺失的整数。你有办法在O(n)时间内完成吗?
注意:本题相对书上原题稍作改动
示例 1:
输入:[3,0,1] 输出:2
示例 2:
输入:[9,6,4,2,3,5,7,0,1] 输出:8
分析:
本题在时间复杂度上做了要求,需要O(N)的时间复杂度完成,这个题的思路跟博主之前写的C语言综合题目的最后两道oj题类似,我们想象一下,有两个数组,一个数组是完整的数组从0-n,11个数;
另外一个数组是残缺的,有10个数,有且仅缺了1个数字,那么我们将这两个数组内的所有数字放在一起,都是两两成对的,除了那个缺失的数字只有单独一个,所以我们可以使用异或的方式,把所有数字全部异或,相同的数字异或之后会得到0,所以最后得到的数字就是缺失的数字。
int missingNumber(int* nums, int numsSize) {
int ret = 0;
// 遍历残缺数组
for(int i = 0;i < numsSize;i++)
{
ret ^= nums[i];
}
// 遍历完整数组
for(int i = 0;i <= numsSize;i++)
{
ret ^= i;
}
return ret;
}面试题2:只出现一次的数字
这道题在博主之前写过的C语言综合题目博客中已经详细讲解了,但是由于这是一个全新的模块,那么博主依旧进行讲解。
给你一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返回答案。
你必须设计并实现线性时间复杂度(O(N))的算法且仅使用常量额外空间(O(1))来解决此问题。
示例 1:
输入:nums = [1,2,1,3,2,5] 输出:[3,5] 解释:[5, 3] 也是有效的答案。
示例 2:
输入:nums = [-1,0] 输出:[-1,0]
示例 3:
输入:nums = [0,1] 输出:[1,0]
分析:
这道题和上面那道题基本思路一致,都是需要使用异或来解决问题,不同的是,上面的题目只有一个单独的数字,本道题有2个单独的数字,如果我们稍作处理把情况简化之后直接可以按照上一题的做法来进行处理即可。
我们知道有一个单独的数字如何处理,那么两个单独的数字怎么办呢?
①分组:将这两个单独的数字分成两组。
②组内:这两组内进行分别异或,相当于就是上一题的做法,这里会分别得到两个数字就是那单独的两个数字。
那么现在的问题是,如何分组才能将这两个单独的数字分成两组呢?
我们可以将所有数字异或,其实就是这两个出现一次的数的异或,那么我们假设这两个出现了一次的数分别是3和8:

此时我们找一下异或后的值中,任意一位是1,如果某一位是1,那么就说明在这一位上,这两个单独的数字是不同的,那么我们就能将这两个数字区分开,一旦区分开之后,我们就可以按照上一题的思路分别对这两个组进行组内异或,最终会得到这单独的两个数。
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* singleNumber(int* nums, int numsSize, int* returnSize)
{
/*
1.先分组,把这两个单独的数字分成两组
2.组内异或
注意:直接将所有的数字进行异或,然后得到的结果随便找一个1,就能区分这两个单独的数字了
*/
// 1.所有数字异或找1
int ret = 0;
for(int i = 0;i < numsSize;i++)
{
ret ^= nums[i];
}
// 2.根据结果找到最低位的1
int pos = 0;
for(int i = 0;i < 32;i++)
{
if((ret >> i)&1 == 1)
{
pos = i; // 记录此时为1的位置
}
}
// 3.根据pos的位置进行分组
int group1 = 0;
int group2 = 0;
for(int i = 0;i < numsSize;i++)
{
if((nums[i] >> pos)&1 == 1)
{
group1 ^= nums[i];
}else
{
group2 ^= nums[i];
}
}
*returnSize = 2;
int* returnArr = malloc((*returnSize)*sizeof(int));
returnArr[0] = group1;
returnArr[1] = group2;
return returnArr;
}