使用Python和JS逆向基于webpack的游戏平台
网站分析
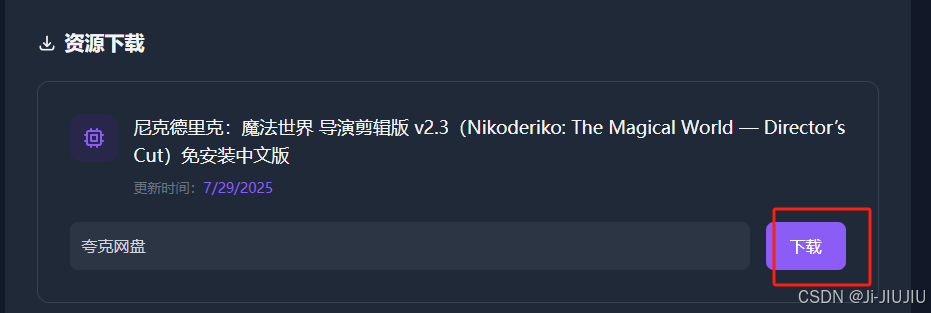
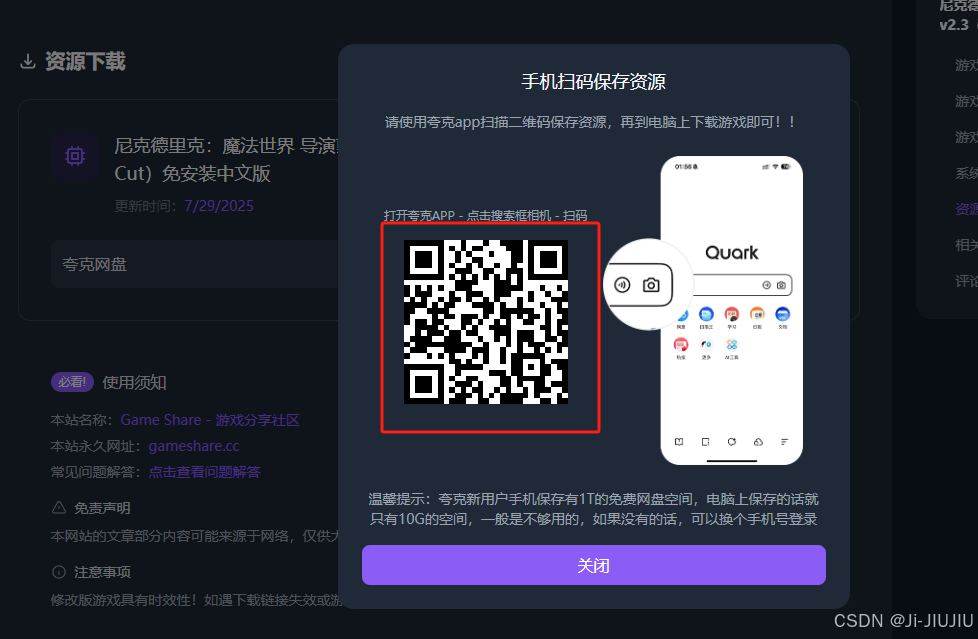
最近在找游戏,发现一个不错的分享平台,资源下载需要点击下载后扫二维码,进行网盘转存,如果想要20个游戏要扫20次,身为程序员怎么可能这样机械式呢.
JS代码分析
开始进行F12之路
先找到button [下载] 触发的函数,全局search 下载
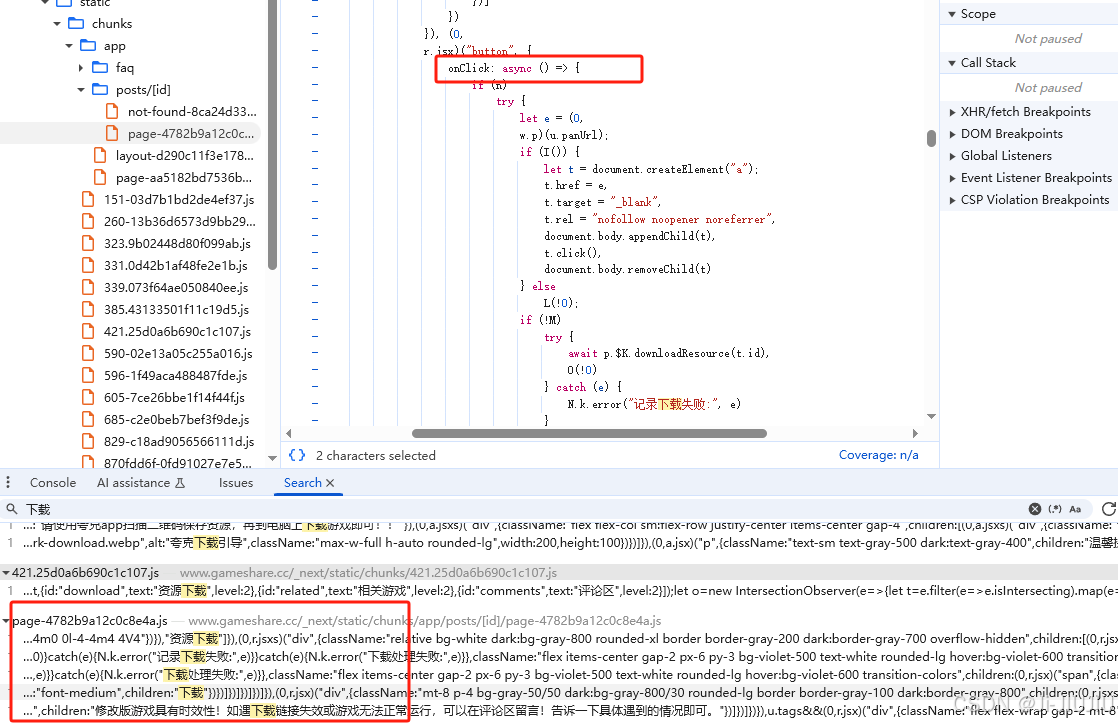
不出意外在这个js文件里面搜索到了
page-4782b9a12c0c8e4a.js
然后开始调试打断点, F5 刷新断住进行跟栈
这里可以看出这地址是加密的
Kcv3H5Y+q+P7BNEPFwrcSlRuRvA1BMnTTTlvTtsCD/7h6HUeY+VtdffUiumxo5MX
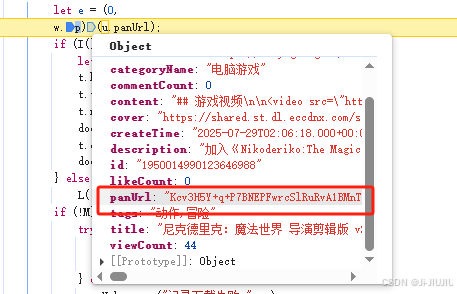
这是解密后的
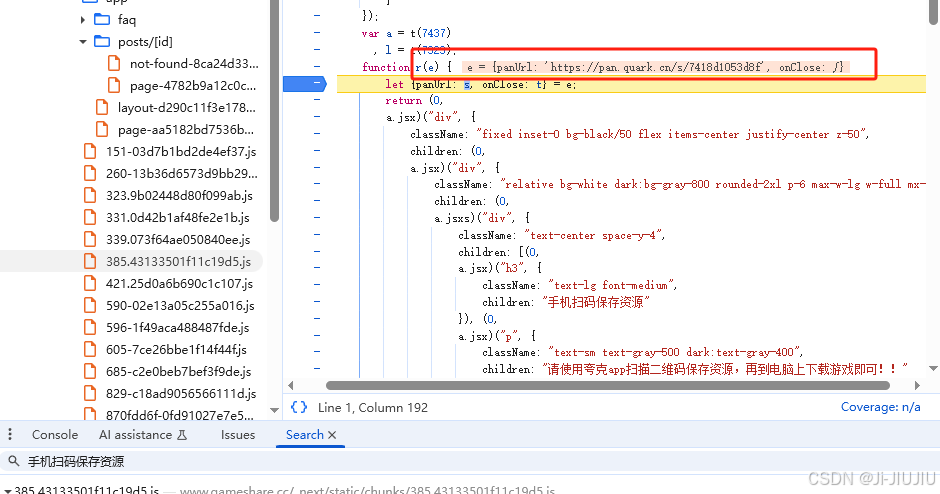
来看下w.p(xx)这个是什么东西,点击看下
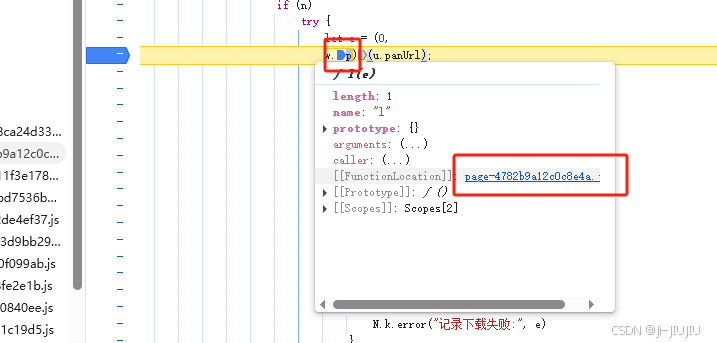
毫不意外的可以看出这里就是解密的方法了… 那就开始扣了…

先把加载器给扣下,然后跟栈,报缺什么方法就补什么方法,这种方式有个缺点…
你永远不知道需要补多少个函数…
我的做法是居然这个函数只有引用到,那我就整个js给扣下来
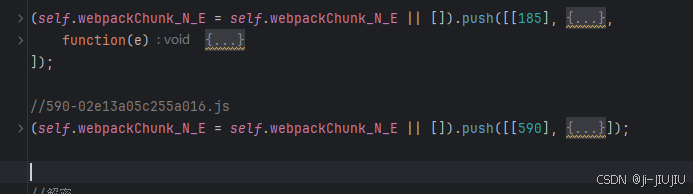
然后关注被调用的函数,然后随机删几个,看会不会被依赖到,如果随便删几个跑不动,就保留整个js吧,不要费时间去调了…
然后开始补环境变量
运行后会提示ReferenceError: self is not defined,这里的self只出现了这一行,只是全局性的变量。添加window = global;,并用window替换self。然后再运行,就不会有报错了。但是要记得待会再补代码的时候如果有self也要同样使用window
接下来提示TypeError: Cannot read property ‘call’ of undefined
其实也有两种方式找函数,一个是全选o()然后点击,或者全选n(xx)然后点击,两种方式都可以找到
这里我是全扣…不想去看上下文了…
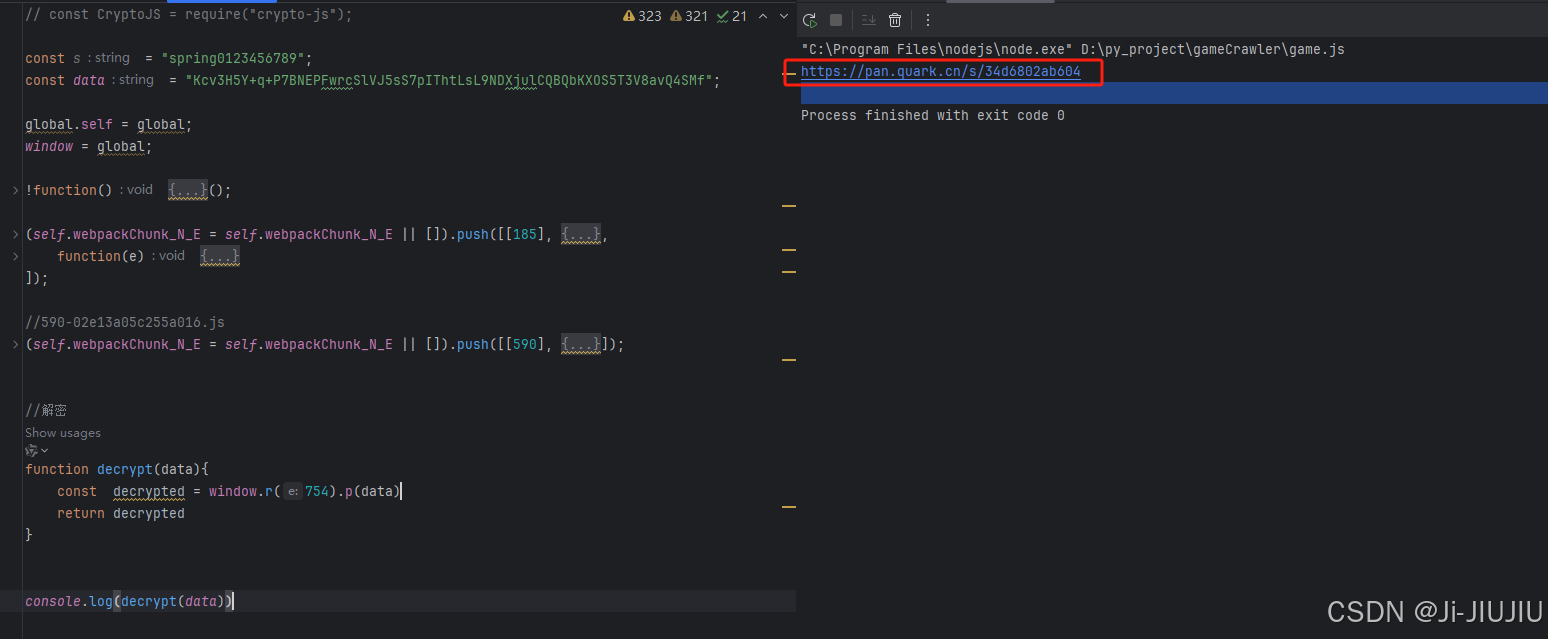
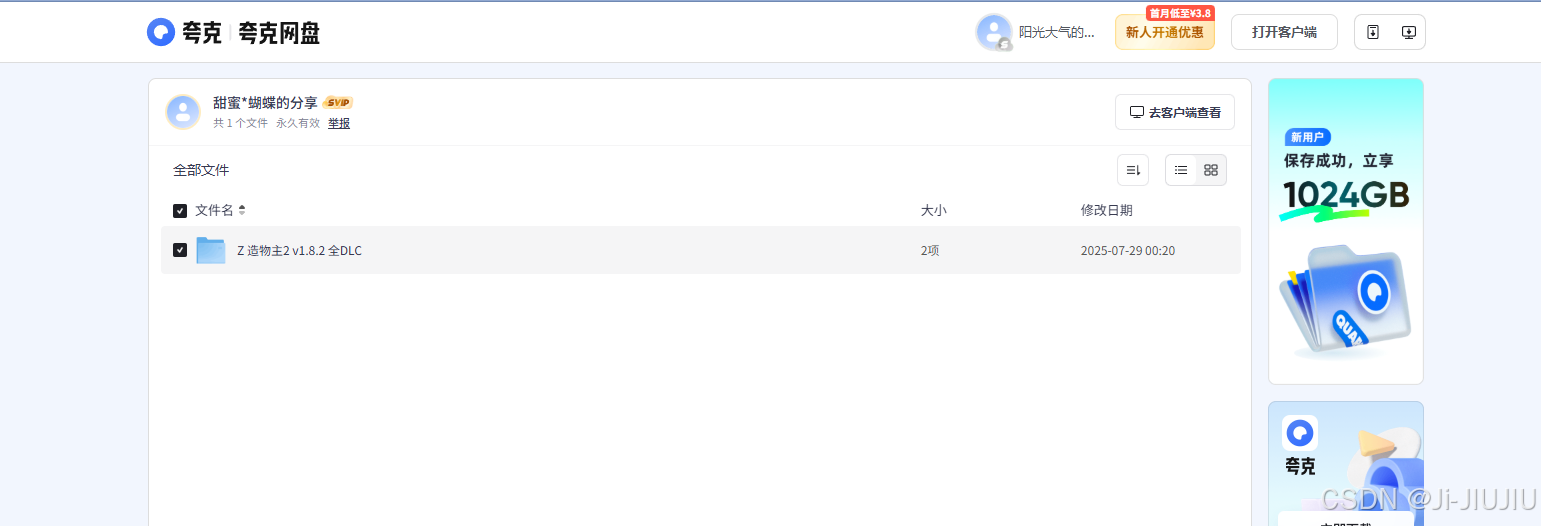
ok 到这里就解密完成了 …
用Python Pyexejs库来动态加载js
import requests
import execjs
with open('game.js', encoding='utf8') as f:
js_code = f.read()
js_compile = execjs.compile(js_code)
code = js_compile.call("decrypt", panUrl)
print(code) # https://pan.quark.cn/s/34d6802ab604
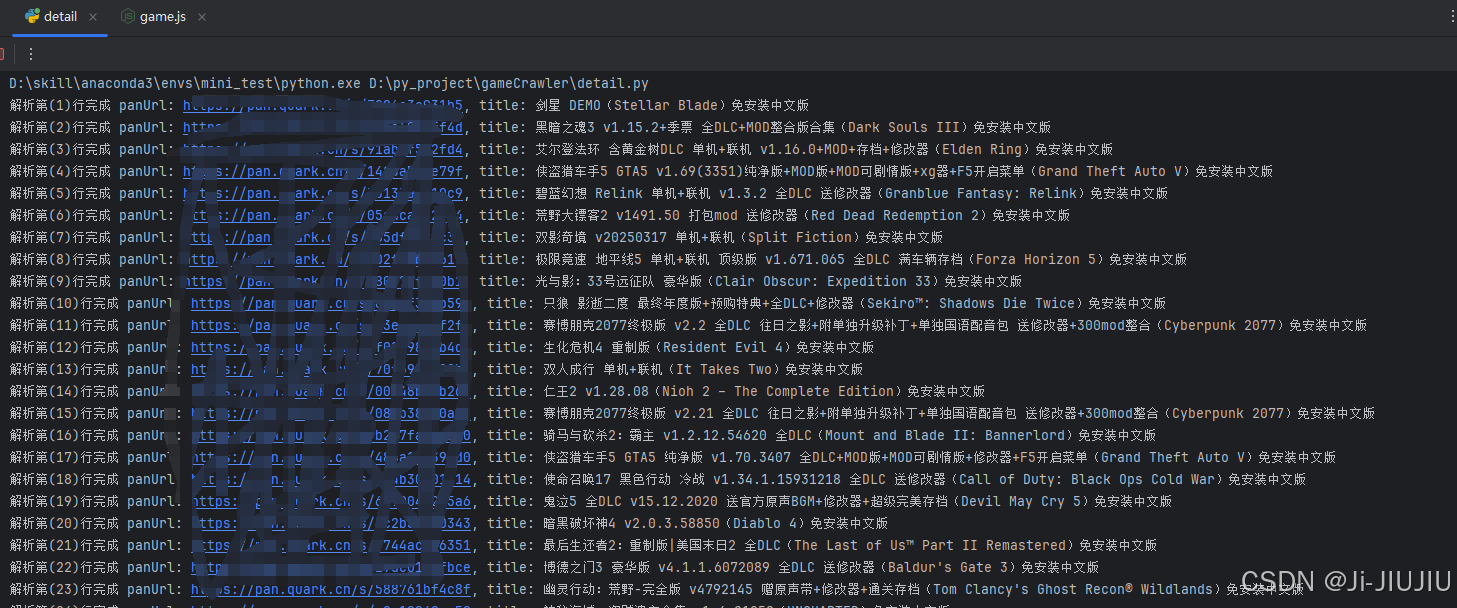
把逻辑完善就是以下的效果了
搜索3A大作的游戏都抓下来, 在用夸克网盘批量转存的工具,保存到自己的云盘就okok
结束撒花~~~~~~~~~
本文主要介绍了对于使用webpack打包技术的这一类网站的逆向方法和思路。当然对于逆向JS有很多种方式,根据webpack的规则来定位函数只是其中一条路,也不是非走不可。
免责声明
教育和研究用途:本文章提供的信息和示例代码仅供教育和研究用途。它们的目的是帮助读者了解爬虫技术的原理和应用。
合法合规性:请注意,网络爬虫可能会侵犯网站的服务条款或法律法规。在实际应用中,你必须确保你的爬虫活动合法、合规,并遵守所有相关法律。
责任限制:作者对于读者使用文章中提供的信息和代码所导致的任何问题或法律纠纷概不负责。读者应自行承担风险并谨慎操作。
合理使用:请在使用网络爬虫时保持谨慎和礼貌。不要对目标网站造成不必要的干扰或侵害他人利益。请在遵守法律的前提下使用爬虫技术。
变动和更新:作者保留随时更改文章内容的权利,以反映新的法规、技术和最佳实践。
资源和参考文献:本文章中的示例代码和信息可能依赖于第三方资源,作者会尽力提供相关参考文献和资源链接。作者不对这些资源的可用性或准确性负责。
协商:如果您有任何关于本文内容或责任声明的疑虑或疑问,请在使用之前与专业法律顾问协商。