GROUP BY 的基本用法
GROUP BY 子句用于将结果集按照一个或多个列进行分组,通常与聚合函数(如 COUNT, SUM, AVG 等)一起使用。
实例:
按照部分分组统计员工数量:
select department,count(*) as employee_count
from employees
group by department;按产品和年份分组统计销售额:
select product_id,YEAR(order_date) as order_year,SUM(amount) as total_sales
from orders
group by product_id,YEAR(order_date);HAVING 的基本用法
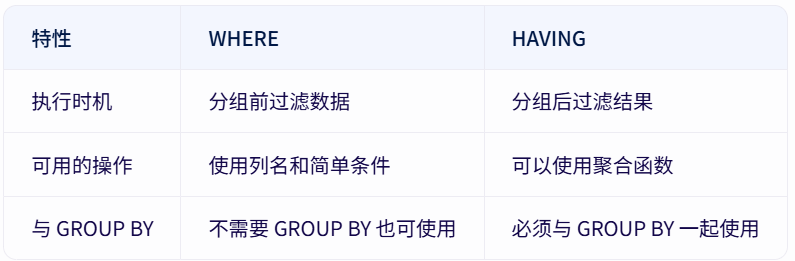
HAVING 子句用于对 GROUP BY 分组后的结果进行过滤,类似于 WHERE 子句,但 WHERE 在分组前过滤,而 HAVING 在分组后过滤。
//筛选员工数超过5人的部门
select department,count(*) as employee_count
from employees
group by department
having count(*)>5//筛选出销售总额超过10000的产品和年份组成
select product_id,year(order_date) as order_year,sum(amount) astotal_sales
from orders
group by product_id,year(order_date)
having sum(amount)>10000;关键区别总结:
常见使用模式
1. 基本分组统计
SELECT category, AVG(price) as avg_priceFROM productsGROUP BY category;2. 分组后过滤
SELECT customer_id, COUNT(*) as order_countFROM ordersGROUP BY customer_idHAVING COUNT(*) >= 3;3. 多列分组
SELECT department, job_title, COUNT(*) as countFROM employeesGROUP BY department, job_titleHAVING COUNT(*) > 2;4. 结合 WHERE 和 HAVING
-- 先过滤2023年的订单,再按客户分组,最后筛选总金额大于5000的客户SELECT customer_id, SUM(amount) as total_spentFROM ordersWHERE order_date BETWEEN '2023-01-01' AND '2023-12-31'GROUP BY customer_idHAVING SUM(amount) > 5000;
注意事项
SELECT 中的非聚合列:在 GROUP BY 查询中,SELECT 子句中的非聚合列必须出现在 GROUP BY 子句中。
性能考虑:GROUP BY 操作可能会消耗较多资源,特别是在大数据集上。
HAVING 中的聚合函数:HAVING 子句中可以使用聚合函数,这是它与 WHERE 的主要区别之一。
NULL 值处理:GROUP BY 会将所有 NULL 值视为相同的分组。
实际案例
案例1:销售分析
按地区和产品类别分组,计算销售总额,并筛选出销售额超过10000的组合
select
region,
product_category,
sum(sales_acount) as total_sales,
count(*) as transaction_count
from sales
group by region,prodect_category
having sun(sales_amount) >10000
order by total_sales desc;案例2:学生成绩分析
按班级和科目分组,计算平均分,并筛选出平均分低于60的科目
select
calss,
subject,
avg(score) as avg_score,
count(*) as student_count
from exam_results
group by class,subject
having avg(score) < 60
order by class,avg_score;