✨ 哈喽,屏幕前的每一位开发者朋友,你们好呀!✨
当你点开这篇文章时,或许正对着 IDE 里闪烁的光标发呆,或许刚解决一个卡了三天的 bug,正端着咖啡松口气 —— 不管此刻的你在经历什么,都想先和你说声:“辛苦了,同行者!” 👋
作为一名摸爬滚打多年的开发工程师,我始终觉得,我们敲出的每一行代码,不仅是业务逻辑的堆叠,更是无数个 “踩坑与爬坑” 的缩影。从第一次上线时的手忙脚乱,到如今能冷静应对突发 bug;从对着文档啃源码的迷茫,到能给新人讲清设计思路 —— 这些藏在键盘敲击声里的成长,太值得被好好梳理和分享了。 📝
所以,这一系列文章里,不会有太多高深的架构理论,也不会罗列晦涩的技术文档。我想聊的,是那些 “教科书里没写” 的实战细节:
比如上线前必做的 3 个自查动作(亲测能减少 80% 的线上问题)🛡️;
比如和产品经理 “友好沟通” 需求的 5 个小技巧(避免反复改需求到崩溃)🤝;
比如如何用最少的时间,快速定位线上性能瓶颈(曾靠这招拯救过一次紧急故障)🚀;
再比如那些看似 “浪费时间” 的重构,其实藏着怎样的长期价值…… ♻️
当然,更想和大家聊聊 “技术之外” 的事:如何平衡加班与生活(毕竟身体是敲代码的本钱)💪,如何在团队中清晰表达自己的想法(别让好方案被沉默埋没)🗣️,甚至是 “35 岁焦虑” 来袭时,我是如何调整心态的…… 🌱
如果你也和我一样,相信 “经验不是用来炫耀的资本,而是能帮同行少走弯路的路灯”,那不妨坐下来喝杯茶,一起在评论区聊聊:你最近遇到的最大挑战是什么?有没有哪个瞬间,让你觉得 “啊,原来我真的成长了”? 💬
毕竟,开发这条路从来不是孤军奋战。我们分享的每一个踩坑故事,都可能成为别人的指路牌;你留下的每一条评论,或许也会给我新的启发。 🌟
那么,准备好了吗?让我们开始这场 “代码背后的成长对话” 吧!接下来的每一篇,都等你来拍砖、补充、共鸣 —— 因为最好的经验,永远在交流里生长。 🌱
目录
一.什么是存储过程?
1.定义
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程思想上很简单,就是数据库SQL语言层面的代码封装与重用。
举例:我们的项目有个业务逻辑,涉及到了3个SQL语句,此时我们就可以将这三个SQL语句封装成一个存储过程。
2.好处
- 封装之后,可复用
- 可以接收参数,也可以返回参数
- 减少网络交互,效率提升
二.基本语法
1.创建存储过程

举例

创建之后,可以查看一下
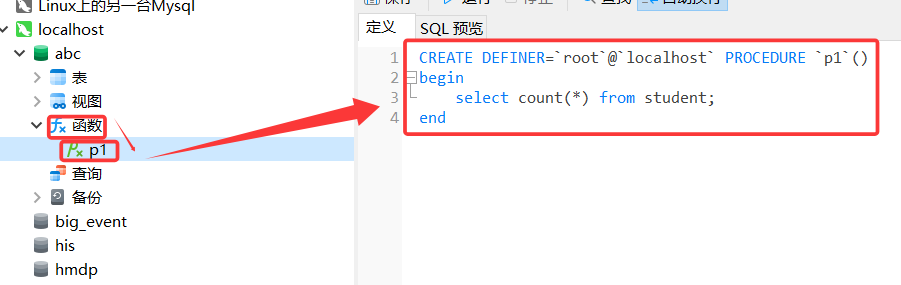
2.调用存储过程

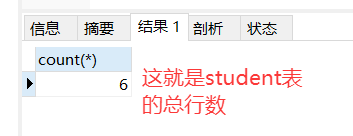
举例

执行结果
3.查看存储过程

方式一 :查询某个数据库中的全部存储过程
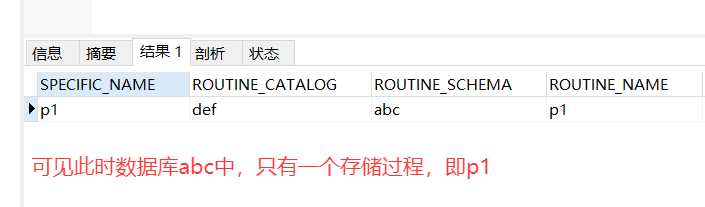
举例:查看某个数据库下的所有存储过程
-- 查看数据库abc中的所有存储过程
select * from information_schema.ROUTINES where ROUTINE_SCHEMA = 'abc'执行结果如下:
方式二:查询某个存储过程创建时的SQL语句
举例: 查看存储过程p1创建时的SQL语句
-- 查看存储过程p1创建时的SQL语句
show create procedure p1;执行结果如下:

4.删除存储过程

举例:删除存储过程p1

执行效果如下:

三.delimiter的使用【重要】
1.不使用delimiter时,存在的问题
以下是创建存储过程p1的SQL语句
-- 创建存储过程p1
create procedure p1()
begin
select count(*) from student;
end; 将其放到linux命令行上执行,结果如下:
可见代码报错了,因为mysql默认以分号作为结束符号,因此执行到第一个分号就会结束代码,根本执行不到end,因此会报错。

2.delimiter的作用
设置一个结束符号,从而解决上述问题
举例:

然后再修改一下原来的存储过程创建SQL语句
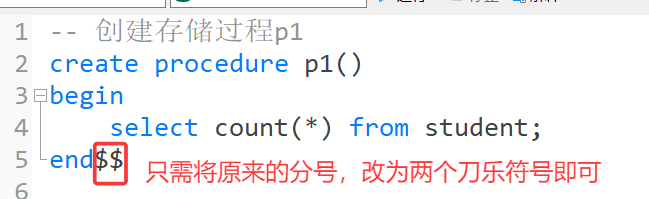
执行结果如下:

3.注意事项
一旦通过delimiter将结束符号设置为$$以后,后续所有执行的SQL语句,都要以$$结尾,不然SQL语句不会结束,光标就会一直等待你输入$$。
当然,当我们操作完了存储过程相关的内容,就可以再次使用delimiter将结束符设置回分号即可
以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~