在机器人学习领域,如何有效地将视觉语言模型(VLM)的强大感知能力与低级动作控制相结合,是实现通用机器人智能的关键挑战。SmolVLA(Small Vision-Language-Action)架构正是在这一背景下应运而生,它通过一种新颖的交错注意力机制,实现了视觉语言特征与机器人动作生成之间的紧密耦合。本文将深入探讨SmolVLA架构中VLM与动作专家(Action Expert)之间的信息交互,特别是其注意力机制中KV和QKV的设计原理,并结合官方代码进行详细解析。
一、SmolVLA架构概览
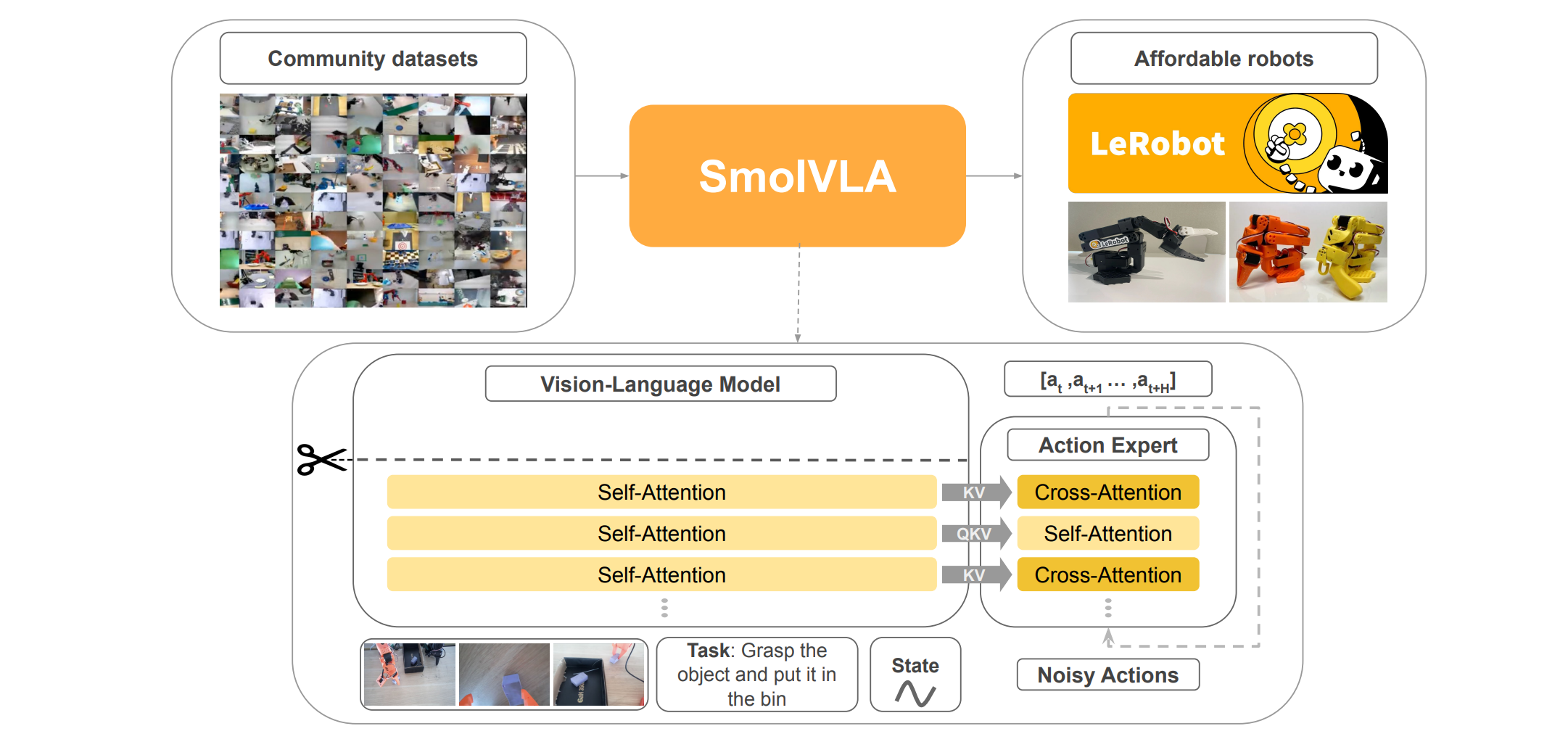
SmolVLA由两大部分组成:一个预训练的视觉语言模型(VLM)和一个动作专家。VLM负责处理多模态输入,包括语言指令、RGB图像和机器人本体感受状态,并提取高级特征。这些特征随后被送入动作专家,由其生成一系列低级动作块(action chunks)。与传统的Transformer架构不同,SmolVLA的动作专家采用了交错式的自注意力(Self-Attention, SA)和交叉注意力(Cross-Attention, CA)层,而非在每个解码器块中同时包含两者。这种设计旨在优化性能并提高推理速度。
二、注意力机制基础回顾
在深入SmolVLA的细节之前,我们先简要回顾一下Transformer中自注意力和交叉注意力的基本概念:
自注意力(Self-Attention):在自注意力机制中,输入序列中的每个元素都会与同一序列中的所有其他元素计算注意力权重。它通过将输入表示转换为查询(Query, Q)、键(Key, K)和值(Value, V)三个向量来实现。Q与K的点积决定了注意力权重,然后这些权重作用于V,得到加权和的输出。自注意力允许模型捕捉序列内部的依赖关系。
交叉注意力(Cross-Attention):交叉注意力通常用于处理两个不同的输入序列。其中一个序列提供查询(Q),而另一个序列提供键(K)和值(V)。例如,在编码器-解码器架构中,解码器的查询来自解码器自身的输出,而键和值则来自编码器的输出。这使得解码器能够“关注”编码器输出中的相关信息。
三、SmolVLA中VLM与动作专家的信息交互
SmolVLA的核心创新之一在于其VLM与动作专家之间独特的信息交互方式。如图1所示,VLM的输出特征(通常是其最后一层或中间层的隐藏状态)被传递给动作专家。这种交互通过注意力机制实现,其中VLM的特征充当了动作专家注意力层的键(K)和值(V)的来源。
3.1 动作专家中的交叉注意力(Cross-Attention)
在SmolVLA的动作专家中,交叉注意力层(图1中金色块)负责将动作令牌(action tokens)与VLM提取的视觉语言特征进行融合。根据论文描述:
In our setup, CA layers cross-attend the VLM’s keys and values, while SA layers allow the action tokens in vθv_θvθ to attend to each other.
这意味着在交叉注意力层中:
- 查询(Q):来自动作专家自身的当前动作令牌的表示。这些令牌代表了模型正在尝试生成的动作序列。
- 键(K)和值(V):来自VLM的输出特征。VLM已经处理了图像、语言指令和机器人状态,并生成了包含这些多模态信息的丰富表示。这些VLM特征作为外部信息源,为动作令牌提供了上下文。
因此,交叉注意力层接收的是VLM的KV以及动作专家自身的Q。这种设计使得动作专家能够根据VLM提供的感知信息来调整和生成动作。例如,如果VLM识别出图像中的特定物体或理解了语言指令中的特定动词,这些信息将通过KV传递给动作专家,指导其生成相应的抓取或移动动作。
让我们看看smolvlm_with_expert.py中的forward_cross_attn_layer函数,它负责处理交叉注意力逻辑。虽然代码中直接计算了expert_query_state、expert_key_states和expert_value_states,但关键在于expert_key_states和expert_value_states的来源。它们是通过expert_layer.self_attn.k_proj和expert_layer.self_attn.v_proj对VLM的key_states和value_states进行投影得到的。这明确体现了VLM作为KV源的机制:
_key_states = key_states.to(dtype=expert_layer.self_attn.k_proj.weight.dtype).view(
*key_states.shape[:2], -1
)
expert_key_states = expert_layer.self_attn.k_proj(_key_states).view(
*_key_states.shape[:-1], -1, expert_layer.self_attn.head_dim
) # k_proj should have same dim as kv
_value_states = value_states.to(dtype=expert_layer.self_attn.v_proj.weight.dtype).view(
*value_states.shape[:2], -1
)
expert_value_states = expert_layer.self_attn.v_proj(_value_states).view(
*_value_states.shape[:-1], -1, expert_layer.self_attn.head_dim
)
expert_query_state = expert_layer.self_attn.q_proj(expert_hidden_states).view(expert_hidden_shape)
这里的key_states和value_states实际上是VLM层在处理其自身输入时生成的KV对。动作专家通过对其进行线性投影,将其适配到自己的维度空间,从而在交叉注意力中作为外部信息源。
3.2 动作专家中的自注意力(Self-Attention)
自注意力层(图1中浅黄色块)在动作专家内部运作,其目的是让动作令牌之间相互关注,捕捉动作序列内部的时间依赖性。根据论文:
SA layers allow the action tokens in vθv_θvθ to attend to each other. We employ a causal attention mask for the SA layers, ensuring that each action token can only attend to past tokens within the chunk, preventing future action dependencies.
这意味着在自注意力层中:
- 查询(Q)、键(K)和值(V):全部来自动作专家自身的当前动作令牌的表示。每个动作令牌都生成自己的Q、K和V,并与其他动作令牌的K和V进行交互。
自注意力层接收QKV的原因是它需要捕捉序列内部的依赖关系。动作专家在生成动作序列时,需要考虑之前生成的动作对当前动作的影响,并确保动作序列的连贯性和流畅性。因果注意力掩码(causal attention mask)的引入,进一步确保了每个动作令牌只能关注其之前的令牌,从而避免了未来信息泄露,这对于序列生成任务至关重要。
在smolvlm_with_expert.py的forward_attn_layer函数中,我们可以看到Q、K、V都是从inputs_embeds(即动作令牌的隐藏状态)中计算出来的:
query_states = []
key_states = []
value_states = []
for i, hidden_states in enumerate(inputs_embeds):
layer = model_layers[i][layer_idx]
if hidden_states is None or layer is None:
continue
hidden_states = layer.input_layernorm(hidden_states)
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, layer.self_attn.head_dim)
hidden_states = hidden_states.to(dtype=layer.self_attn.q_proj.weight.dtype)
query_state = layer.self_attn.q_proj(hidden_states).view(hidden_shape)
key_state = layer.self_attn.k_proj(hidden_states).view(hidden_shape)
value_state = layer.self_attn.v_proj(hidden_states).view(hidden_shape)
query_states.append(query_state)
key_states.append(key_state)
value_states.append(value_state)
query_states = torch.cat(query_states, dim=1)
key_states = torch.cat(key_states, dim=1)
value_states = torch.cat(value_states, dim=1)
这里的inputs_embeds在动作专家内部的自注意力层中,就是动作令牌的嵌入表示。通过对这些嵌入进行Q、K、V投影,模型能够计算动作令牌之间的相互依赖关系。
四、交错注意力机制的优势
SmolVLA采用交错式的交叉注意力和自注意力层,而非在每个解码器块中同时包含两者,这与许多标准VLM架构(如Transformer解码器)有所不同。论文指出:
Empirically, we find that interleaving CA and SA layers provides higher success rates and faster inference time. In particular, we find self-attention to contribute to smoother action chunks A, something particularly evident when evaluating on real robots.
这种设计选择的优势在于:
- 效率提升:通过交错使用,而不是在每个层都同时计算两种注意力,可以减少计算开销,从而实现更快的推理速度。
- 性能优化:实验结果表明,这种交错方式能够带来更高的成功率。自注意力层有助于生成更平滑、更连贯的动作序列,这对于真实机器人控制至关重要。
- 明确职责:交叉注意力层专注于融合外部视觉语言信息,而自注意力层则专注于建模动作序列内部的依赖关系,职责更加明确,可能有助于模型更好地学习各自的特定任务。
五、总结
SmolVLA通过交错注意力机制,在VLM与动作专家之间建立了高效且富有表现力的信息交互通道。交叉注意力层允许动作专家从VLM中获取丰富的感知上下文(KV),从而指导动作的生成;而自注意力层则使动作专家能够捕捉动作序列内部的依赖关系(QKV),确保动作的连贯性和流畅性。这种独特的设计不仅提升了模型的性能和推理速度,也为机器人学习领域提供了一种新的注意力机制范式,使其在复杂任务中展现出卓越的潜力。