►前言
在人工智能蓬勃发展的今天,大型语言模型(LLM, Large Language Model)正迅速改变我们与信息互动的方式。无论是进行自然语言处理、生成文字内容,还是作为智能助手的核心引擎,LLM 都展现了强大的语言理解与生成能力。
随着开源模型与工具链的日益成熟,越来越多的开发者开始关注模型的本地部署与定制化微调。Unsloth 作为一款高性能的大模型微调工具,能够协助开发者在本地以更快速且低资源的方式进行 LLM 的微调工作,并支持如 LoRA、QLoRA 等主流技术,大幅降低微调的门槛。
本文将介绍 Unsloth 进行模型微调,打造更符合应用需求的大语言模型系统。
►Unsloth介绍
Unsloth 是一个开源项目,专为加速大型语言模型(LLMs)的微调和推理而设计。它基于 PyTorch 和 Hugging Face Transformers 框架,并且通过使用 OpenAI 的 Triton 语言重写底层核心,实现了显著的性能提升和内存优化。
Unsloth 的主要特点包括:
- 加速微调与推理:Unsloth 声称能够比 Hugging Face 框架快 2-5 倍地微调 Llama 3、Mistral 和 Gemma 等模型,同时减少 80% 的内存消耗。
- Triton 核心加速:通过使用Triton语言重写底层核心,并手动实现反向传播引擎,Unsloth显著提升了模型训练速度和内存利用率。
- 无精度损失:Unsloth 的重写不引入近似计算,确保模型训练的精度不受影响。
- 支持 4-bit 和 16-bit QLoRA/LoRA 微调:基于bitsandbytes,支持低精度微调,进一步降低显存需求。

►操作流程
安装Unsloth套件,并加入预训练量化工具。

预训练模型已加载,使用DeepSeek 8B。


微调前测试 DeepSeek 8B,模型推理代码部分。

数据集已加载,并打印确认加载成功。

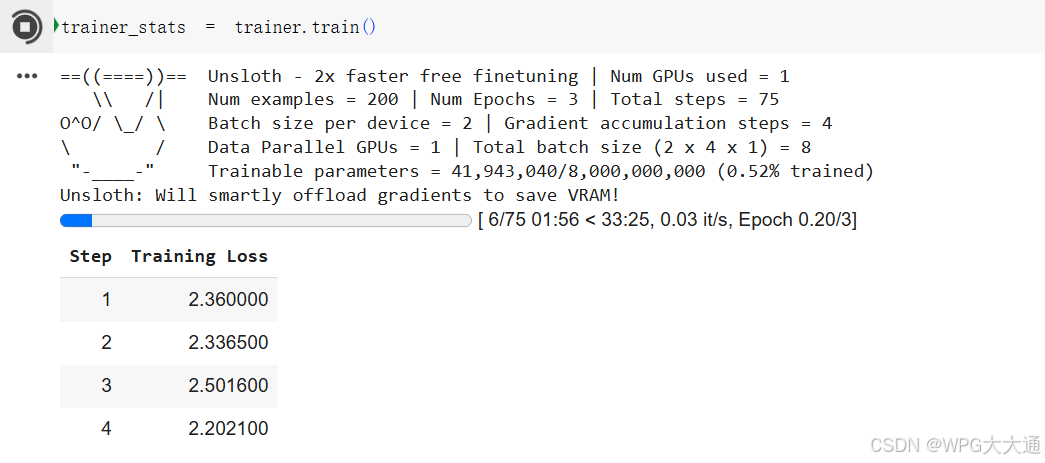
开始微调训练:
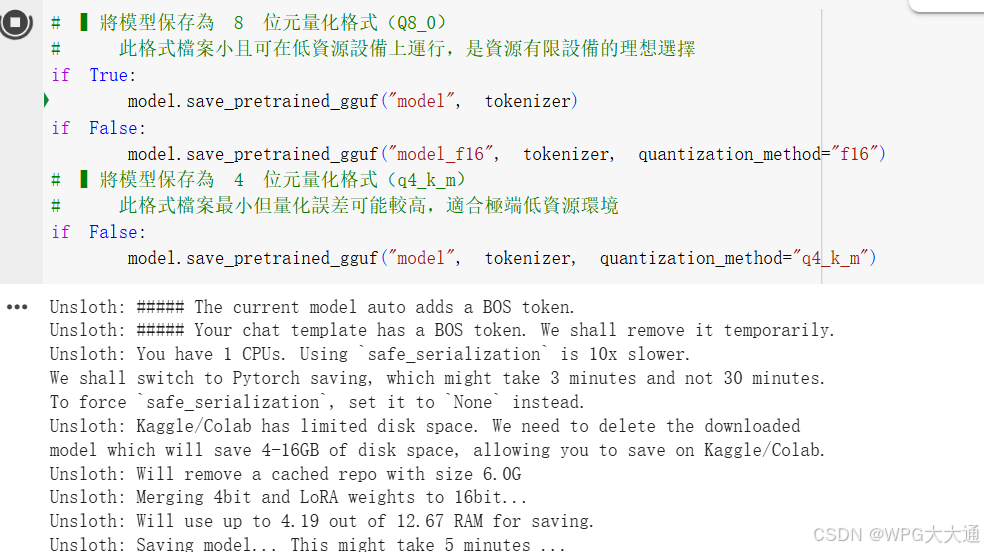
保存为GGUF格式后,即可供Ollama进行调用
►小结
通过以上讲解,结合代码进行示例讲解,相信大家对于Unsloth 微调能够有更深刻的理解,期待下一篇博文吧!
►问与答
问题一:Unsloth 和 Hugging Face 的 Trainer 有什么区别?我该用哪一个?
Unsloth 是专为轻量、快速、高效率微调而设计的套件,特别针对 LoRA 与 QLoRA 微调进行优化。
相比于 Hugging Face 的 Trainer,Unsloth 提供更快的训练速度,支持更简单的 LoRA 集成与权重合并。
问题二:可以在 GPU 上使用 Unsloth 吗?内存需求高吗?
Unsloth 专为低内存环境设计,支持 4bit QLoRA 微调,最低只需 8GB 显存,内置支持 bnb_config(bitsandbytes)与梯度检查点(Gradient Checkpointing)。
问题三:Unsloth 支持哪些模型?能用在中文模型或自定义模型吗?
LLaMA 2 / 3
密史托 / 密克斯托
Qwen / Phi / TinyLLaMA / Gemma
问题四:可以在 Windows 中使用 Unsloth 吗?它有 API 吗?
开发者可以自行创建符合需求的环境,调用 GPU,即可进行微调操作。
问题五:使用 Unsloth 微调后,如何导出模型并部署到其他平台?
使用 merge_lora_weights() 将 LoRA 权重合并为单一模型,或者导出为 Hugging Face 格式的 .bin 和 config.json,进一步转换为 GGUF 或 ONNX 格式。