摘要:前馈式3D建模已成为实现快速且高质量3D重建的一种颇具前景的方法。特别是直接生成显式3D表示(如3D高斯溅射)的方法,因其渲染速度快、质量高且应用广泛而备受关注。然而,许多基于Transformer架构的先进方法存在严重的可扩展性问题,因为它们依赖于跨多个输入视图图像标记的全局注意力机制,导致随着视图数量或图像分辨率的增加,计算成本急剧上升。为了实现可扩展且高效的前馈式3D重建,我们提出了一种迭代式大型3D重建模型(iLRM),该模型通过迭代优化机制生成3D高斯表示,并遵循以下三个核心原则:(1)将场景表示与输入视图的图像解耦,以实现紧凑的3D表示;(2)将全注意力多视图交互分解为两阶段注意力机制,以降低计算成本;(3)在每一层注入高分辨率信息,以实现高保真重建。在广泛使用的数据集(如RE10K和DL3DV)上的实验结果表明,iLRM在重建质量和速度方面均优于现有方法。值得注意的是,iLRM具有出色的可扩展性,通过高效利用更多输入视图,在相当的计算成本下实现了显著更高的重建质量。Huggingface链接:Paper page,论文链接:2507.23277
研究背景和目的
研究背景:
近年来,3D重建技术在计算机视觉和图形学领域取得了显著进展,尤其是在快速且高质量的3D场景重建方面。传统的3D重建方法往往依赖于逐场景的优化,虽然这些方法能够生成高质量的3D模型,但它们的计算成本高且难以实时处理。随着深度学习技术的发展,基于前馈神经网络的3D建模方法逐渐兴起,这些方法通过从大规模数据集中学习先验知识,能够在单次前向传播中实现3D场景的快速重建,从而提供了接近实时的性能。
特别是,3D高斯溅射(3D Gaussian Splatting, 3D-GS)作为一种显式的3D表示方法,因其快速且高质量的渲染能力而备受关注。然而,现有的基于前馈神经网络的3D高斯重建方法在处理多视图输入时,往往依赖于跨图像标记的全局注意力机制,导致随着视图数量或图像分辨率的增加,计算成本急剧上升,严重限制了其可扩展性。因此,开发一种既高效又可扩展的3D重建方法成为当前研究的重要方向。
研究目的:
本研究旨在提出一种迭代式大型3D重建模型(iLRM),通过迭代优化机制生成3D高斯表示,解决现有前馈3D重建方法在可扩展性和计算效率方面的局限性。具体目标包括:
- 解耦场景表示与输入视图图像:实现紧凑的3D表示,减少对高分辨率输入图像的依赖。
- 分解多视图交互:将全注意力多视图交互分解为两阶段注意力机制,降低计算成本。
- 注入高分辨率信息:在每一层迭代过程中注入高分辨率信息,实现高保真重建。
研究方法
模型架构:
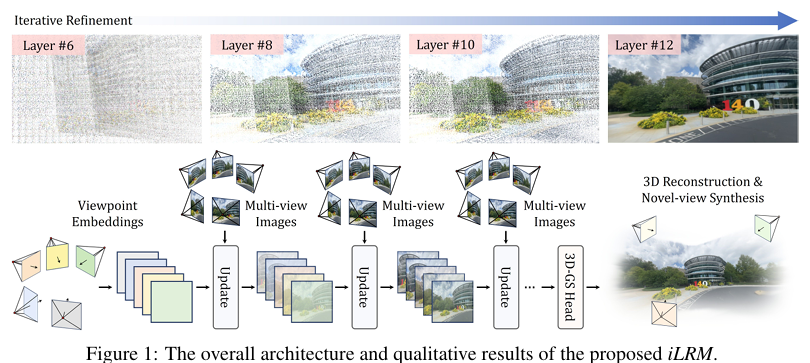
iLRM模型采用了一种端到端的Transformer架构,直接从视点嵌入中回归3D高斯参数。模型通过多个更新层组成,每个更新层包含一个交叉注意力模块和一个自注意力模块。
- 视点标记化:使用Plücker射线嵌入对每个输入视图进行标记化,生成视点标记。
- 多视图图像标记化:将每个输入视图图像分割成不重叠的块,并提取RGB图像块和Plücker射线块,拼接后线性投影生成图像块标记。
- 迭代更新机制:
- 交叉注意力:在每个更新层中,视点标记通过交叉注意力机制与对应的多视图图像特征进行交互,实现基于视觉信息的细化。
- 自注意力:经过交叉注意力细化后的视点标记再通过自注意力机制进行全局依赖捕捉,增强多视图感知能力。
- 标记提升:为了弥补视点标记分辨率低于图像标记分辨率所带来的信息损失,提出标记提升策略,通过线性查询层扩展低分辨率视点标记的特征维度,使其更好地捕捉视觉对应关系。
- 解码为3D高斯:最终层的视点标记通过一个线性层解码为3D高斯参数,包括均值、不透明度、协方差和颜色。
训练目标:
使用均方误差(MSE)损失和感知损失(利用预训练的VGG网络)对渲染图像进行监督,优化模型参数。
研究结果
实验结果:
在广泛使用的数据集(如RE10K和DL3DV)上进行了综合评估,实验结果表明iLRM在重建质量和速度方面均优于现有方法。
- 重建质量:在RE10K数据集上,iLRM相比最先进的方法(如GS-LRM和DepthSplat)在PSNR指标上提高了约3dB,通过利用更多视图(8视图对比2视图)在更少的计算时间内(0.028秒对比0.065秒)实现了更高的重建质量。在DL3DV数据集上,iLRM在相似的计算预算下,利用四倍多的视图(24视图对比6视图)将PSNR指标提高了约4dB。
- 计算效率:iLRM通过解耦表示和输入图像,并采用两阶段注意力机制,显著降低了计算和内存开销,使得模型能够高效利用更多输入视图进行重建。
- 高分辨率实验:在高分辨率设置(512×960)下,iLRM相比DepthSplat在保持相对较小的时间差距的同时,展示了出色的重建质量,这得益于其高效处理高分辨率图像的能力。
研究局限
尽管iLRM在3D重建质量和计算效率方面取得了显著进展,但仍存在以下局限性:
- 自注意力机制的计算瓶颈:尽管通过解耦表示和采用两阶段注意力机制降低了计算成本,但自注意力机制在处理大量输入视图时仍面临计算瓶颈。未来需要开发更高效的自注意力替代方案,如层次化和稀疏注意力机制。
- 相机姿态依赖:iLRM模型需要已知的相机姿态信息,这些信息通常通过运动结构恢复(SfM)方法获得,但在大规模原始视频数据集中,这些姿态信息可能不准确或难以获取。未来工作需要探索无姿态或自姿态估计的3D重建方法。
未来研究方向
基于iLRM的研究成果和局限性,未来研究可以从以下几个方面展开:
- 开发更高效的注意力机制:针对自注意力机制在处理大规模多视图输入时的计算瓶颈,研究层次化、稀疏或其他高效处理策略,以进一步提升模型的计算效率和可扩展性。
- 无姿态或自姿态估计的3D重建:探索在不依赖精确相机姿态信息的情况下实现高质量3D重建的方法,这将极大增强模型在实际应用中的灵活性和实用性。
- 跨数据集和跨域的泛化能力:研究模型在不同数据集和不同场景下的泛化能力,通过迁移学习或领域适应技术,使模型能够适应更广泛的应用场景。
- 动态场景重建:将iLRM模型扩展到动态场景重建中,通过引入时间维度信息,实现视频序列中的动态3D场景重建,这将为虚拟现实、增强现实等领域提供更丰富的应用场景。
- 结合其他3D表示方法:探索将3D高斯表示与其他3D表示方法(如点云、体素、网格等)相结合的可能性,以充分利用不同表示方法的优势,进一步提升3D重建的质量和效率。
通过不断研究和优化,iLRM及其后续研究有望在3D重建领域发挥更大的作用,推动计算机视觉和图形学技术的进一步发展。