文章目录
RAG(Retrieval-Augmented Generation)-- 检索增强生成:
一种结合信息检索(Retrieval)和文本生成(Generation)的技术:通过实时检索相关信息,并将其作为上下文输入到生成模型中,从而提高生成结果的时效性和准确性 (← 优势)
目前感觉最好用的 RAG 产品是 notebookLM,可以先上手体验下 ( BUT 需要外网,不开源)
开源产品可以选择 Qwen-Agent ---- 本文是从头构建 RAG,也可以选择基于 Qwen-Agent 来快速实现 RAG 部署 (见主页博文)
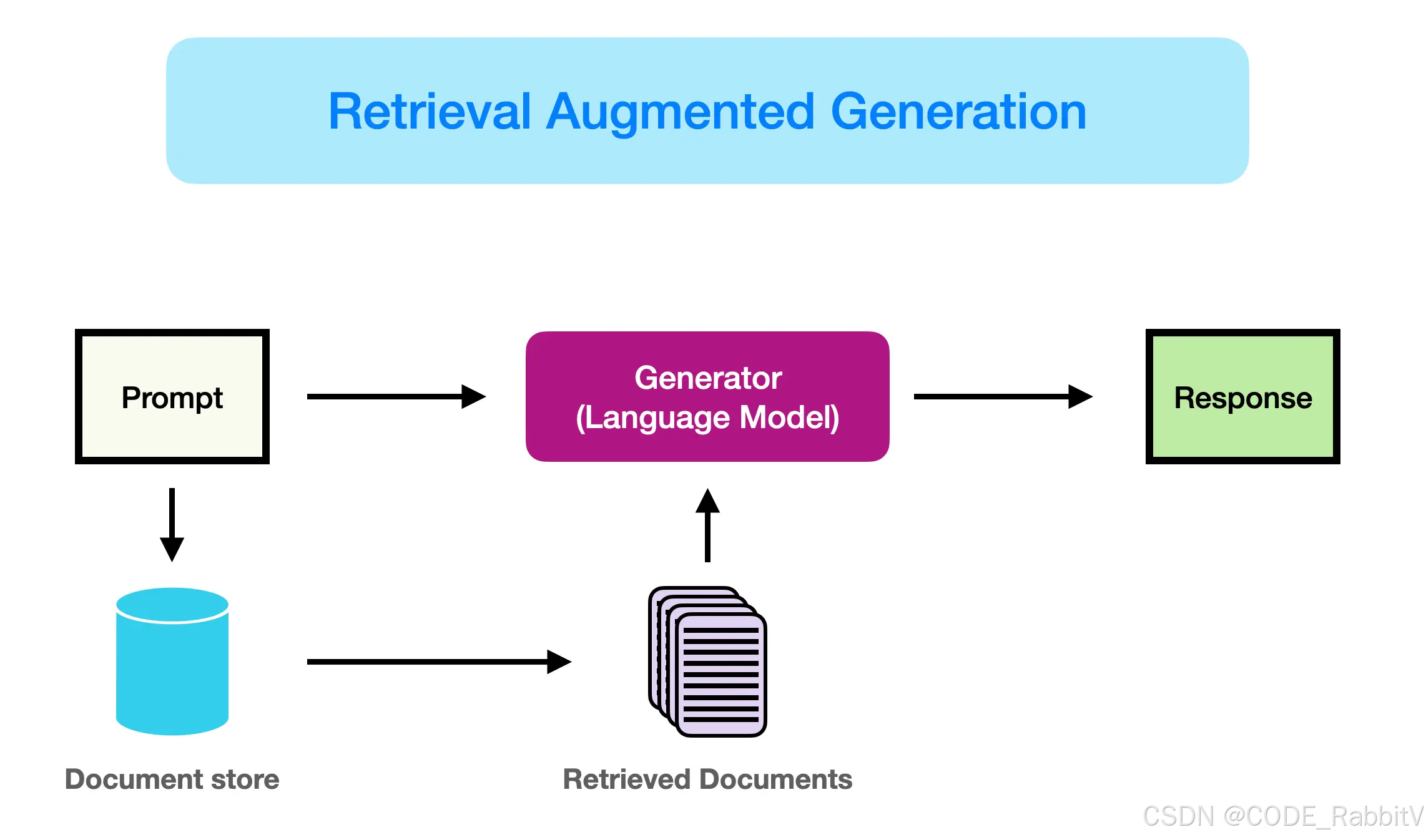
⭐ RAG 的三大步骤:数据预处理、检索和生成 💜 【理论基础】
RAG 第一步:数据预处理
Indexing => 如何更好地把知识存起来
在让 AI 使用外部知识前,需要先把原始资料整理成适合检索的格式,主要包括以下几步:
知识库构建:汇总各种收集到的相关资料,比如文档,建立一个“外部知识库”
文档分块:把长文档按语义切成一小段一小段(叫做 chunk)
- ✏️ 说明:分得太碎可能语义不完整,分太大又不利于检索,要平衡
向量化:使用“嵌入模型”把 chunk 转成“向量”并存进“向量数据库”,方便快速搜索
类型 模型 特点 适用场景 开源状态 通用模型 BGE-M3多语言、长文本、混合检索 高精度 RAG、跨语文档 ✅ 开源 text-embedding-3-large 英文表现强 英文场景 ❌ 闭源(OpenAI) Jina-embeddings-v2 模型小,推理快 实时任务、轻量场景 ✅ 开源 中文模型 xiaobu-embedding-v2 语义理解强 中文分类、检索 ✅ 开源 M3E-Turbo本地部署好 法律、医疗文本 ✅ 开源 stella-mrl-large-zh-v3.5-1792 关系抽取强 NLP分析、高语义需求 ✅ 开源 指令驱动 & 复杂任务 gte-Qwen2-7B-instruct支持代码与跨模态 多任务问答 ✅ 开源(协议限制) E5-mistral-7B Zero-shot强 动态语境 ✅ 开源 企业级 BGE-M3稳定部署、强检索 企业知识库 ✅ 开源 E5-mistral-7B 支持微调 高复杂系统 ✅ 开源 ✏️ 说明:可以在 https//modelscope.cn/ 找到并下载 embedding 模型 (以下示例中部署 BGE-M3,个人级不建议部署,代价大~看下流程即可)
# 安装依赖(只需运行一次) # pip install FlagEmbedding # 1️⃣ 加载模型 from FlagEmbedding import BGEM3FlagModel # 加载 BGE-M3 模型,use_fp16=True 可以加速(需要显卡支持) model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) ## 替换成你存 BGE 模型的路径 # 2️⃣ 编码文本为向量 # 设定两个句子列表,一个作为查询,一个作为候选答案 sentences_query = ["什么是BGE M3?", "BM25的定义"] sentences_docs = [ "BGE M3 是一个支持稠密检索、词匹配和多交互的嵌入模型。", "BM25 是一种用于排名的词袋模型。" ] # 使用模型编码成向量(dense_vecs) emb_query = model.encode(sentences_query, max_length=8192, batch_size=12)['dense_vecs'] emb_docs = model.encode(sentences_docs)['dense_vecs'] # 3️⃣ 计算相似度 # 使用点乘计算 query 和每个文档的相似度(越高越相关) similarity = emb_query @ emb_docs.T # 输出相似度矩阵 print("相似度矩阵:") print(similarity) ## 形状是 [sentences_query 的数量, sentences_docs 的数量]
RAG 第二步:检索 Retrieval
Retrieval => 如何在大量的知识中,找到一小部分有用的,给到模型参考
让 AI 从知识库中找到与你问题相关的资料,主要包括以下几步:
- 查询处理:将你的问题转成向量(即数字表达),然后在向量数据库中搜索,找出最相关的内容片段
- 相关性排序:对初步搜索结果进行相关性排序,挑选最合适的片段,用于下一步生成答案
RAG 第三步:生成 Generation
Generation => 如何结合用户的提问和检索到的知识,让模型生成有用的答案
让大模型结合相关资料,生成最终答案,主要包括以下几步:
- 上下文组装:把上一步找到的片段,与你的问题一起输入大模型,构成“增强版上下文”
- 生成回答:大语言模型根据增强后的上下文,生成准确、有依据的回答
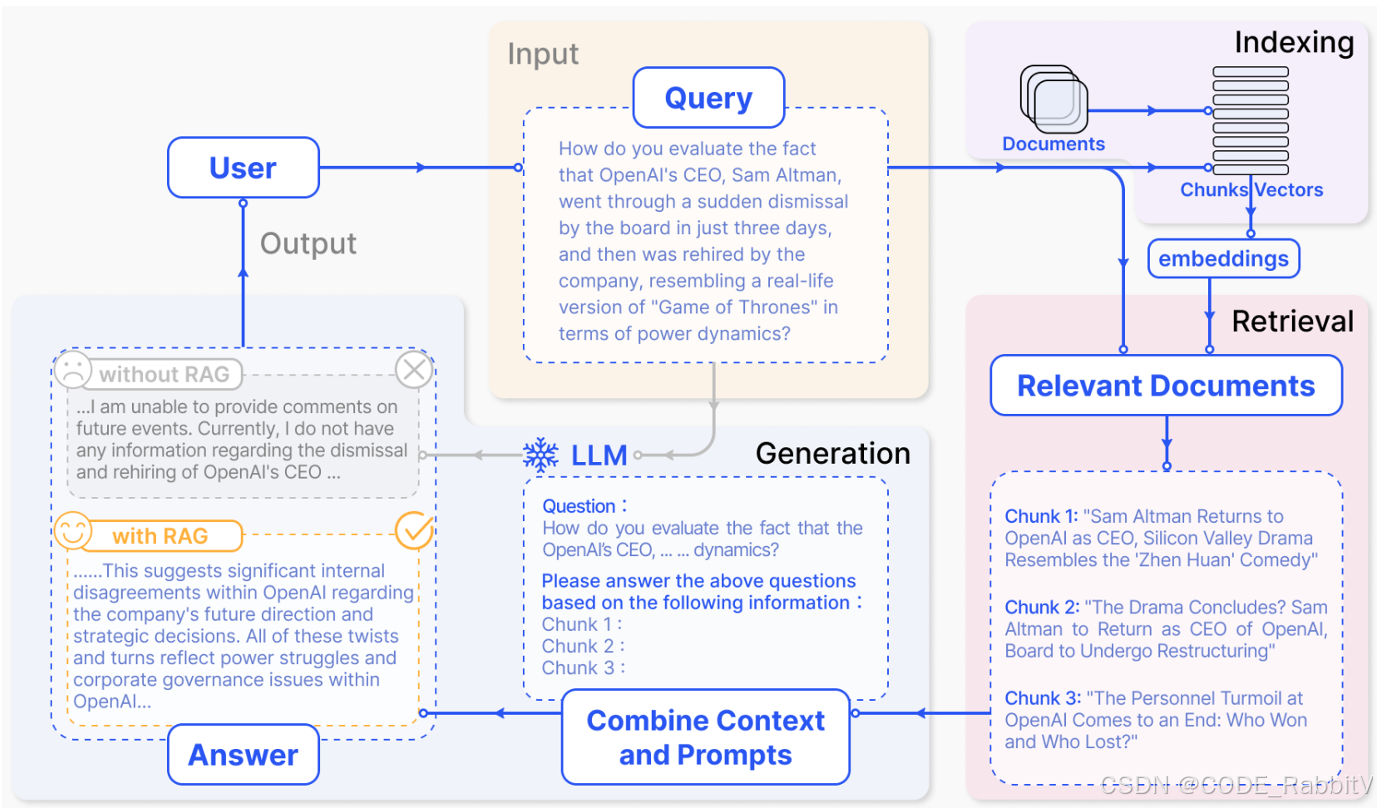
⭐ RAG 部署的三大步骤 :PDF提取、知识库创建和 Q&A💜 【代码实战】
from typing import List, Tuple
DASHSCOPE_API_KEY = '' ## TODO: 填充你的 DASHSCOPE_API_KEY 🔍🔍🔍
1. PDF提取文本和页码信息:text, page_numbers
from PyPDF2 import PdfReader
def extract_text_with_page_numbers(pdf) -> Tuple[str, List[int]]:
"""
从PDF中提取文本并记录每行文本对应的页码
参数:
pdf: PDF文件对象
返回:
text: 提取的文本内容
page_numbers: 每行文本对应的页码列表
"""
text = ""
page_numbers = []
for page_number, page in enumerate(pdf.pages, start=1):
extracted_text = page.extract_text()
if extracted_text:
text += extracted_text
page_numbers.extend([page_number] * len(extracted_text.split("\n")))
return text, page_numbers
pdf_reader = PdfReader('./你准备的 PDF 文档(自行修改 🔍🔍🔍).pdf') # 读取 PDF 文件
text, page_numbers = extract_text_with_page_numbers(pdf_reader) # 提取文本和页码信息
2. 根据文本和页码信息创建知识库 knowledgeBase
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
def process_text_with_splitter(text: str, page_numbers: List[int]) -> FAISS:
"""
处理文本并创建 FAISS 知识库存储
参数:
text: 提取的文本内容
page_numbers: 每行文本对应的页码列表
返回:
knowledgeBase: FAISS 知识库
"""
# 步骤一:准备 chunks
## 1. 创建文本分割器
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=1000, ## 最大长度
chunk_overlap=200, ## 重叠长度
length_function=len,
)
## 2. 分割文本为 chunk
chunks = text_splitter.split_text(text)
# print(f"Text split into {len(chunks)} chunks.")
# 步骤二:准备嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 步骤三:根据准备 chunks 和 嵌入模型,创建 FAISS 知识库
knowledgeBase = FAISS.from_texts(chunks, embeddings)
knowledgeBase.page_info = {chunk: 0 for i, chunk in enumerate(chunks)} # 存储 chunk 对应的页码
# TODO:暂时chunk 对应的页码都标注为了 0,待后续完善
return knowledgeBase
knowledgeBase = process_text_with_splitter(text, page_numbers)
# knowledgeBase.save_local('./faiss-0804') # 保存 (可选)
3. 根据知识库提供的 docs 进行 Q&A
from langchain_community.llms import Tongyi
from langchain.chains.question_answering import load_qa_chain
from langchain_community.callbacks.manager import get_openai_callback
# 加载问答链
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=DASHSCOPE_API_KEY) # qwen-turbo
chain = load_qa_chain(llm, chain_type="stuff")
# 拼接查询问题 query + docs -> input_data
query = "你的提问(自行修改 🔍🔍🔍)"
docs = knowledgeBase.similarity_search(query)
input_data = {"input_documents": docs, "question": query}
# 执行问答链 (同时使用回调函数跟踪 API 调用成本)
with get_openai_callback() as cost:
response = chain.invoke(input=input_data)
print(f"查询已处理。成本: {cost}")
print(response["output_text"])
# 补充 response 回答依据
print("来源:")
unique_pages = set()
for doc in docs: # 获取每个文档块的来源页码,存储至 unique_pages 集合
text_content = getattr(doc, "page_content", "")
source_page = knowledgeBase.page_info.get(
text_content.strip(), "未知"
)
unique_pages.add(source_page)
print(f"文本块页码: {source_page}")
运行会输出类似下面的内容:
根据提供的信息,... 。具体相关内容如下:
......
来源:
文本块页码: ...
✏️ 其中,我们看到核心代码 chain = load_qa_chain(llm, chain_type="stuff")
---- LangChain 问答链的四种 chain_type 类型说明:
| 代码片段 | 功能说明 |
|---|---|
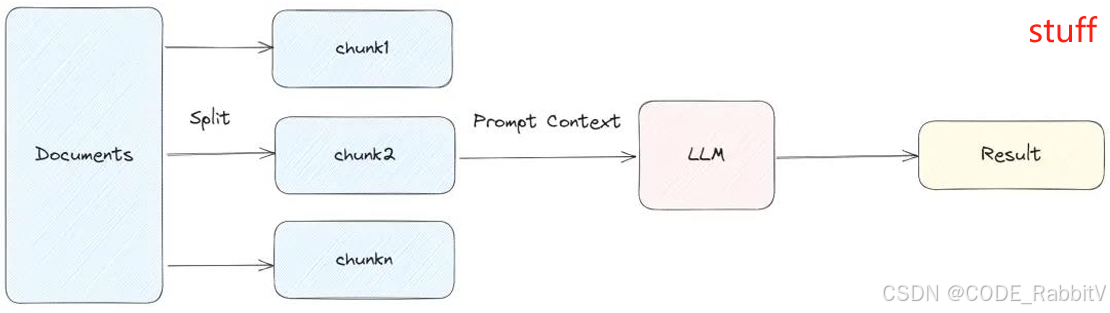
chain = load_qa_chain(llm, chain_type="stuff") |
将所有文档拼接为一个 prompt,一次性输入给 LLM,适用于文档较小的情况 |
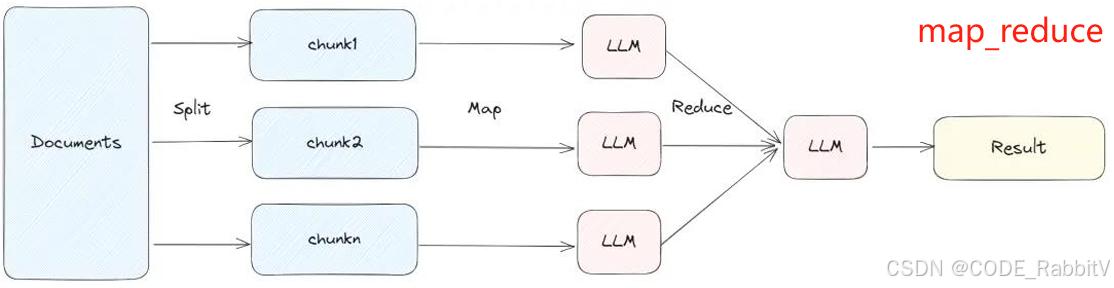
chain = load_qa_chain(llm, chain_type="map_reduce") |
每个 chunk 单独作为 prompt 提问,然后将结果合并做最终回答,适合并行处理 |
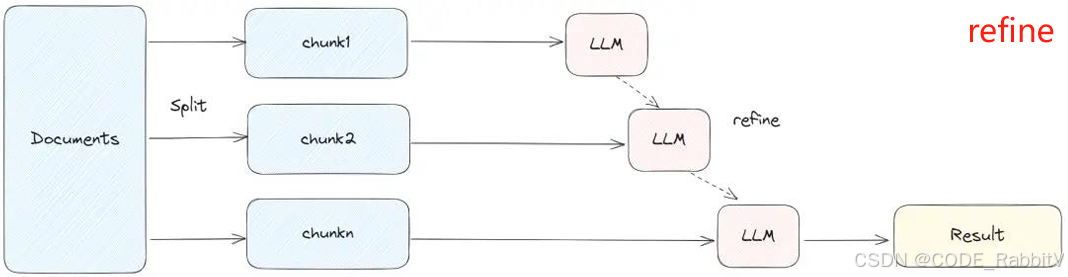
chain = load_qa_chain(llm, chain_type="refine") |
先从一个 chunk 得到初步回答,后续逐步 refine,适合多轮提炼答案 |
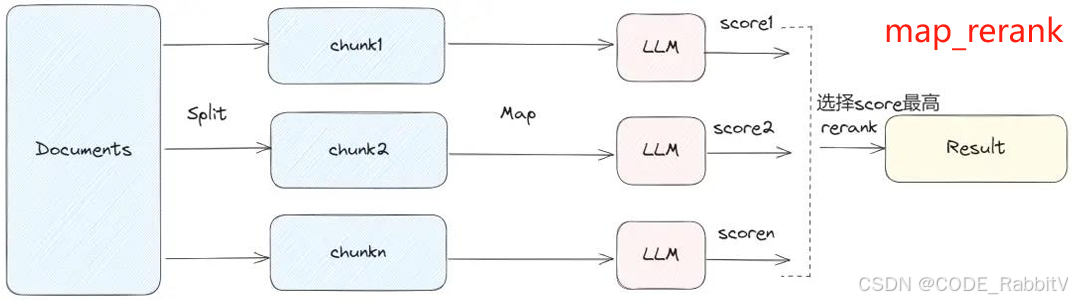
chain = load_qa_chain(llm, chain_type="map_rerank") |
每个 chunk 提问并打分,返回评分最高的那一块的答案,适合精准筛选 |