本文记录了自己在阅读《动手学深度学习》时的一些思考,仅用来作为作者本人的学习笔记,不存在商业用途。
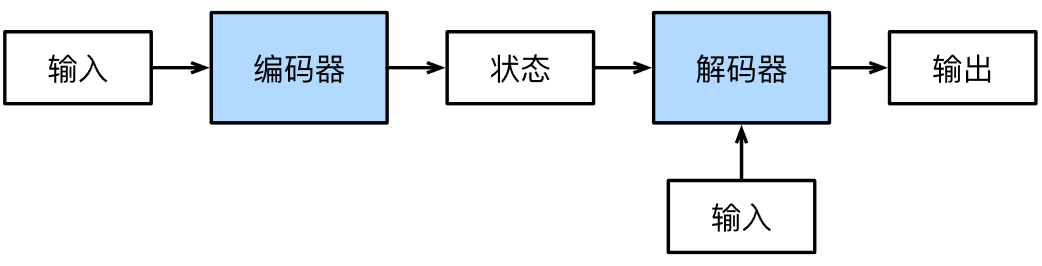
正如我们在9.5机器翻译中所讨论的,机器翻译是序列转换模型的一个核心问题,其输入和输出都是长度可变的序列。为了处理这种类型的输入和输出,我们可以设计一个包含两个主要组件的架构:第一个组件是一个编码器(encoder):它接受一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。第二个组件是解码器(decoder):它将固定形状的编码状态映射到长度可变的序列。这被称为编码器-解码器(encoder-decoder)架构,如:fig_encoder_decoder 所示。
 🏷
🏷fig_encoder_decoder
我们以英语到法语的机器翻译为例:给定一个英文的输入序列:“They”“are”“watching”“.”。首先,这种“编码器-解码器”架构将长度可变的输入序列编码成一个“状态”,然后对该状态进行解码,一个词元接着一个词元地生成翻译后的序列作为输出:“Ils”“regordent”“.”。由于“编码器-解码器”架构是形成后续章节中不同序列转换模型的基础,因此本节将把这个架构转换为接口方便后面的代码实现。
9.6.1 编码器
在编码器接口中,我们只指定长度可变的序列作为编码器的输入X。任何继承这个Encoder基类的模型将完成代码实现。
from torch import nn
#@save
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
# 利用接受任意关键字参数**kwargs(参数都是键值对)初始化实例
def __init__(self, **kwargs):
# 调用父类nn.Module的构造函数, 确保Pytorch能正确初始化模块
super(Encoder, self).__init__(**kwargs)
# 前向传播逻辑需要输入数据X和位置参数*args
def forward(self, X, *args):
# 强制子类必须重写此方法, 否则调用时会报错
raise NotImplementedError
🏷python中的*args和**kargs的用法
https://blog.csdn.net/GODSuner/article/details/117961990`
🏷python中的raise NotImplementedError
https://blog.csdn.net/qq_40666620/article/details/105026716`
9.6.2 解码器
在解码器接口中,我们新增一个init_state函数,用于将编码器的输出(enc_outputs)转换为编码后的状态。注意,此步骤可能需要额外的输入,例如:输入序列的有效长度,这在 9.5.4节中进行了解释。为了逐个地生成长度可变的词元序列,解码器在每个时间步都会将输入(例如:在前一时间步生成的词元)和编码后的状态 映射成当前时间步的输出词元。
#@save
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
# 利用接受任意关键字参数**kwargs(参数都是键值对)初始化实例
def __init__(self, **kwargs):
# 调用父类nn.Module的构造函数, 确保Pytorch能正确初始化模块
super(Decoder, self).__init__(**kwargs)
# 接受编码器的出书enc_outputs和位置参数*args初始化解码器的状态
def init_state(self, enc_outputs, *args):
# 强制子类必须重写此方法, 否则调用时会报错
raise NotImplementedError
# 前向传播逻辑需要输入数据X和编码后的状态state
def forward(self, X, state):
# 强制子类必须重写此方法, 否则调用时会报错
raise NotImplementedError
9.6.3 合并编码器和解码器
“编码器-解码器”架构包含了一个编码器和一个解码器, 并且还拥有可选的额外的参数。 在前向传播中,编码器的输出用于生成编码状态, 这个状态又被解码器作为其输入的一部分。
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
# 前向传播需要编码器输入enc_X和解码器输入dec_X以及位置参数*args(比如语句长度)
def forward(self, enc_X, dec_X, *args):
# 根据编码器输入enc_X(语句中的词元用词表索引编码)和语句长度*args得到编码器输出enc_outputs
enc_outputs = self.encoder(enc_X, *args)
# 根据编码器输出enc_outputs和语句长度*args得到编码后的状态dec_state
dec_state = self.decoder.init_state(enc_outputs, *args)
# 根据解码器输入dec_X和状态dec_state得到解码输出
return self.decoder(dec_X, dec_state)
“编码器-解码器”体系架构中的术语状态 会启发人们使用具有状态的神经网络来实现该架构。 在下一节中,我们将学习如何应用循环神经网络, 来设计基于“编码器-解码器”架构的序列转换模型。
9.6.4 小结
- “编码器-解码器”架构可以将长度可变的序列作为输入和输出,因此适用于机器翻译等序列转换问题。
- 编码器将长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。
- 解码器将具有固定形状的编码状态映射为长度可变的序列。