0.参考
论文有三版:
v1:https://arxiv.org/pdf/2211.10581
v2:https://arxiv.org/pdf/2305.14018
v3:https://arxiv.org/pdf/2311.11722
代码v1/v2:https://github.com/linxuewu/Sparse4D
代码v1/v2/v3:https://github.com/HorizonRobotics/Sparse4D
想看跟踪的看Sparse4Dv3以及对应的代码
1.摘要
(1)做了什么
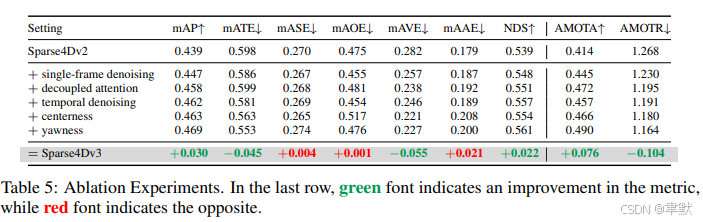
①提升检测性能:引入两个辅助训练任务(时间实例去噪和质量估计),并提出解耦注意力以进行结构改进,显著地提升了检测性能。
②将检测任务扩展到跟踪任务,在推理过程中直接分配实例ID,进一步验证了transformer这种基于query查询的方法的优势。
(2)达到什么样的性能?
在nuScenes数据集上,resnet50的backbone模型,mAP, NDS, and AMOTA, achieving 46.9%, 56.1%, and 49.0%;最好的模型,71.9% NDS and 67.7% AMOTA。
2.介绍
提供的三点贡献:
(1) 我们提出了 Sparse4D-v3,一个强大的 3D 感知框架,包含三项有效策略:时序实例去噪、质量估计和解耦注意力。
(2) 我们将 Sparse4D 扩展为一个端到端的追踪模型。
(3) 我们在 nuScenes 数据集上验证了我们改进的有效性,在检测和追踪任务上均达到了最先进的性能。
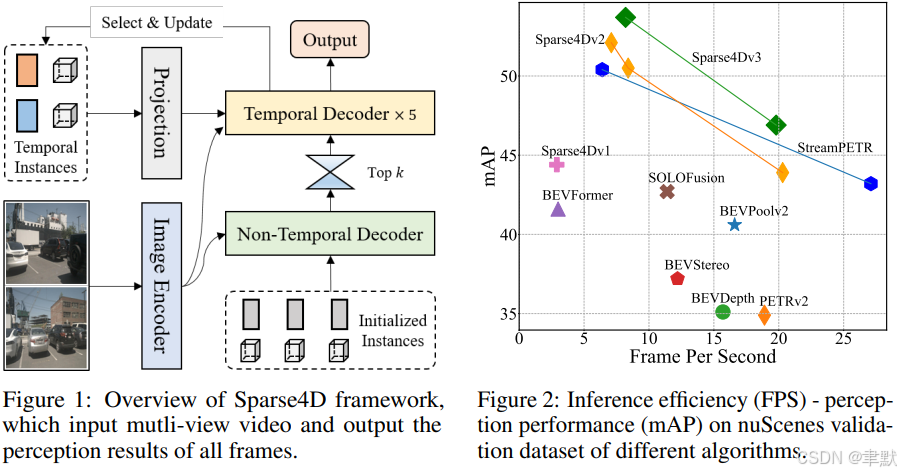
3.方法
(1)时序实例去噪(3D)
插图:时序实例去噪 (Illustration of Temporal Instance Denoising)
(a) 在训练阶段,实例(instances)包含两个组成部分:可学习的 (learnable) 和 带噪声的 (noisy)。噪声实例包含时序 (temporal) 和非时序 (non-temporal) 元素。对于噪声实例,我们采用预匹配 (pre-matching) 方法来分配正负样本——将锚点(anchors)与真实标签(ground truth)进行匹配;而可学习实例则与预测结果 (predictions) 和真实标签 (ground truth) 进行匹配。在测试阶段,仅保留图中的绿色块。
(b) 注意力掩码 (Attention mask) 被用于阻止不同组(groups)之间的特征传播,其中灰色区域表示查询(queries)和键(keys)之间禁止注意力,绿色区域则表示允许注意力。
怎么做的?
在 Sparse4D 框架内,实例(称为查询/queries)被解耦为隐含的实例特征 (implicit instance features) 和显式的锚点 (explicit anchors)。在训练过程中,我们初始化两组锚点:
一组由均匀分布在检测空间中的锚点构成,使用 k-means 方法初始化,这些锚点作为可学习参数。
另一组锚点则通过对真实标签 (Ground Truth, GT) 添加噪声生成,如公式 (1,2) 所示,该公式专为3D检测任务定制:
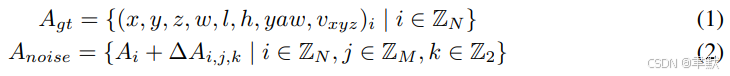
采用二分图匹配 (bipartite graph matching) 方法,对每一组 Anoise 和 Agt 进行匹配,以明确确定正负样本。
通过时序传播 (temporal propagation) 将上述单帧噪声实例进行扩展。在每一帧的训练中,我们从噪声实例中随机选择 M' 组,将其投影到下一帧。该时序传播策略与非噪声实例的策略保持一致:
锚点会经历自车位姿 (ego pose) 和速度补偿 (velocity compensation)。
实例特征则直接作为下一帧特征的初始化。
(2)质量估计 (Quality Estimation)
classification confidence只能评估正样本的的分类置信度,不能确定检测框质量情况,定义了两种质量指标:中心度 (centerness) 和偏航角相似度 (yawness)。
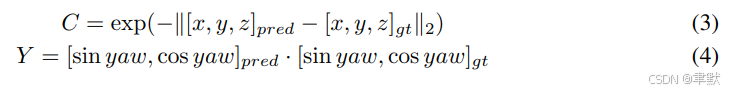
损失函数定义为交叉熵损失 (cross-entropy loss) 和焦点损失 (focal loss):
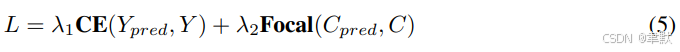
(3)解耦注意力 (Decoupled Attention)
对 Sparse4Dv2 中的锚点编码器 (anchor encoder)、自注意力 (self-attention) 和时序交叉注意力 (temporal cross-attention) 进行了简单而有效的改进。其架构如图 5 所示。
设计原则是:以拼接 (concatenated) 的方式组合来自不同模态的特征,而非采用相加 (additive) 的方式。这与 Conditional DETR [33] 存在一些差异:
首先,我们的改进集中在查询 (queries) 之间的注意力上,而非 Conditional DETR 关注的查询与图像特征之间的交叉注意力;交叉注意力部分我们仍然沿用 Sparse4D 的可变形聚合 (deformable aggregation)。
其次,我们不是在单头注意力 (single-head attention) 层级上将位置嵌入 (position embedding) 和查询特征 (query feature) 拼接,而是在多头注意力 (multi-head attention) 层级外部进行修改,这为神经网络提供了更大的灵活性。
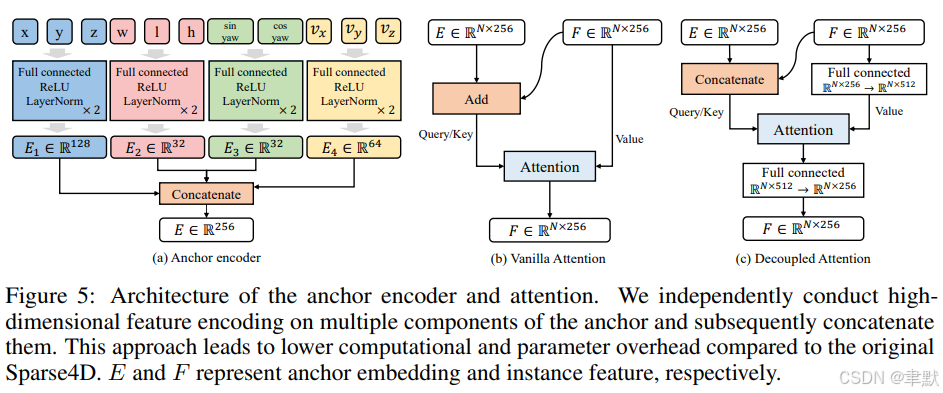
我们对锚点 (anchor) 的多个组成部分进行独立的高维特征编码 (independently conduct high-dimensional feature encoding),随后将它们拼接 (concatenate) 起来。与原始 Sparse4D 相比,这种方法带来了更低的计算量和参数开销 (lower computational and parameter overhead)。其中,E 和 F 分别代表锚点嵌入 (anchor embedding) 和实例特征 (instance feature)。
(4)扩展到追踪 (Extend to Tracking)
从一个检测边界框 (detection bounding box) 扩展为一条轨迹 (trajectory)。一条轨迹包含一个 ID 以及每一帧的边界框信息。
由于设计了大量冗余实例 (large number of redundant instances),许多实例可能并未关联到精确的目标,因此不会被分配明确的 ID。
尽管如此,它们仍然可以被传播 (propagated) 到下一帧。
一旦某个实例的检测置信度 (detection confidence) 超过阈值
T,它就被视为锁定 (locked onto) 了一个目标,并被分配一个 ID。该 ID 在后续的时序传播 (temporal propagation) 过程中保持不变。

4.实验
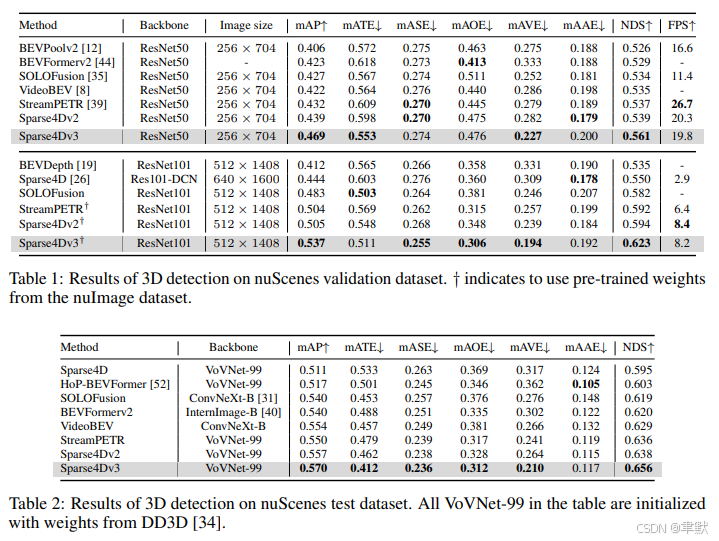
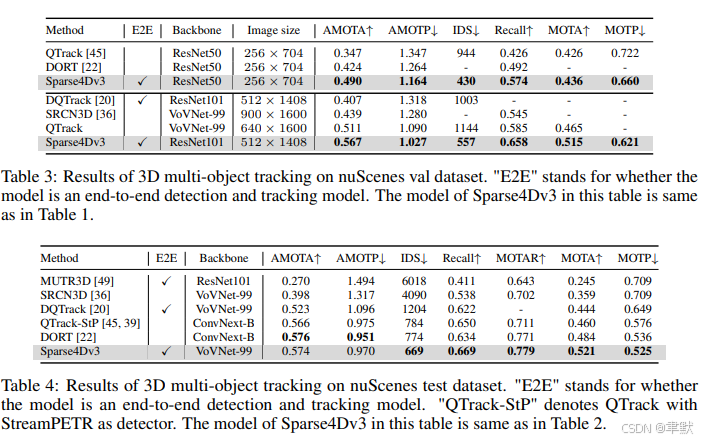
5.结论
未来研究方向 (Future Research Directions):
基于 Sparse4D 框架,存在相当大的潜力 (considerable potential) 进行进一步研究:
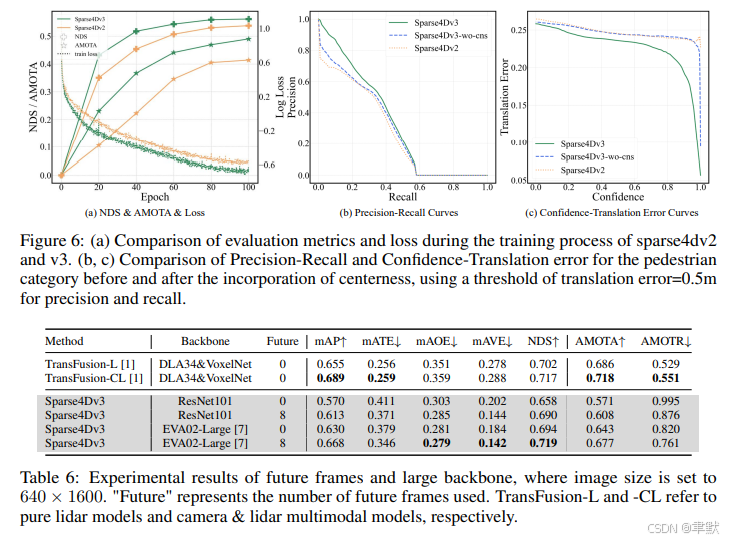
(1) 我们的追踪尝试是初步的 (preliminary),追踪性能还有很大的提升空间 (large room for improvement)。
(2) 将 Sparse4D 扩展为纯激光雷达 (lidar-only) 或多模态模型 (multi-modal model) 是一个有前景的方向 (promising direction)。
(3) 在端到端追踪 (end-to-end tracking) 的基础上,通过引入额外的下游任务 (additional downstream tasks),如预测 (prediction) 和规划 (planning) [10],可以取得进一步的进展。
(4) 集成 (Integrating) 更多的感知任务,例如在线建图 (online mapping) [23] 和 2D 标志与交通灯检测 (2D sign & traffic light detection)。