1、项目的基本结构参考这一篇文章
创作中心-CSDNhttps://mp.csdn.net/mp_blog/creation/editor/149960212
2、项目结构参考
3、.env配置文件
DEEPSEEK_API_KEY=sk-ce9b77XXXXb5ac72XXX
DASHSCOPE_API_KEY=sk-aa9bdba79XXXX
TAVILY_API_KEY=tvly-dev-oUxgzHXXXXX
OPENWEATHER_API_KEY=602fee17a7XXXXX
HOST=localhost
USER=root
MYSQL_PASSWORD=XXXXX
DB_NAME=paymXXXXemo
PORT=33064、requirements安装包
langgraph
langchain-core
langchain-deepseek
langchain-tavily
python-dotenv
langsmith
pydantic
matplotlib
seaborn
pandas
pymysql
scikit-learn5、核心代码graph.py
import os, sys
import json
from dotenv import load_dotenv
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
from langchain_deepseek import ChatDeepSeek
from langgraph.prebuilt import create_react_agent
import pymysql
import pandas as pd
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
from pydantic import BaseModel, Field
from langgraph.types import interrupt
sys.stdout.reconfigure(encoding="utf-8")
# 加载环境变量
load_dotenv(override=True)
TAVILY_API_KEY = os.getenv("TAVILY_API_KEY")
# 内网搜索工具
search_tool = TavilySearchResults(
api_key=TAVILY_API_KEY, max_results=5, topic="general"
)
# 设置人在闭环
def human_assistance(query: str) -> str:
"""Request human assistance for a given query.
Args:
query (str): _description_
Returns:
str: _description_
"""
human_response = interrupt({"query": query})
return human_response["data"]
description = """
当用户需要进行数据库查询工作时,请调用该函数。
该函数用于指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,
并且当前函数是使用pymysql链接MySQL数据库。
本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另外一个extract_data函数。
"""
# 定义结构化参数模型
class SQLQuerySchema(BaseModel):
sql_query: str = Field(description=description)
# 封装为Langchain工具
@tool(args_schema=SQLQuerySchema)
def sql_inter(sql_query: str) -> str:
"""
当用户需要进行数据库查询工作时,请调用该函数。
该函数用于在指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,
并且当前函数是使用pymysql链接MySQL数据库。
本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另外一个extract_data函数。
Args:
sql_query (str): 字符串形式的SQL查询语句,用于执行对MYSQL中XXX_DB数据库中各张表进行查询,并获得相关信息。
Returns:
str: sql_query在MySQL中运行结果
"""
# 加载环境变量
host = os.getenv("HOST")
user = os.getenv("USER")
pwd = os.getenv("MYSQL_PASSWORD")
db = os.getenv("DB_NAME")
port = os.getenv("PORT")
# 创建链接
connection = pymysql.connect(
host=host, user=user, password=pwd, db=db, port=int(port), charset="utf8mb4"
)
try:
with connection.cursor() as cursor:
cursor.execute(sql_query)
result = cursor.fetchall()
return result
finally:
connection.close()
# 将结果以JSON字符串形式返回
return json.dumps(result, ensure_ascii=False)
class ExtractQuerySchema(BaseModel):
sql_query: str = Field(description="用于从MySQL提取数据的SQL查询语句")
df_name: str = Field(description="指定用于保存结果的 pandas 变量名称(字符串形式)")
@tool(args_schema=ExtractQuerySchema)
def extract_data(sql_query: str, df_name: str) -> str:
"""
用于在MySQL数据库中提取一张表到当前python环境中,注意,本函数只负责数据表的提取,
并不负责数据查询。若需要在MySQL中进行数据查询,则使用sql_inter函数。
同时需要注意,编写外部函数的参数消息时,必须满足json格式的字符串。
Args:
sql_query (str): 字符串形式的SQL查询语句,用于提取MySQL数据库中的某张表
df_name (str): 将MySQL数据库中提取的表格进行本地保存时的变量名,一字符串形式表示。
Returns:
str: 表格读取和保存结果
"""
print("正在调用 extract_data 工具运行 SQL查询...")
# 加载环境变量
host = os.getenv("HOST")
user = os.getenv("USER")
pwd = os.getenv("MYSQL_PASSWORD")
db = os.getenv("DB_NAME")
port = os.getenv("PORT")
# 创建链接
connection = pymysql.connect(
host=host, user=user, password=pwd, db=db, port=int(port), charset="utf8mb4"
)
try:
# 执行sql并保存为全局变量
df = pd.read_sql(sql_query, connection)
globals()[df_name] = df
return f"✅成功创建pandas对象`{df_name}`,包含从MySQL提取的数据。"
except Exception as e:
return f"❌执行失败:{e}"
finally:
connection.close()
class PythonCodeInput(BaseModel):
py_code: str = Field(description="一段合法的Python代码字符串,例如'2+2'")
@tool(args_schema=PythonCodeInput)
def python_inter(py_code):
"""
当用户需要编写python程序并执行时,请调用该函数
该函数可以执行一段Python代码,并返回执行结果。
需要注意,本函数只能执行非绘图类的代码。若是绘图相关代码,则调用fig_inter函数
"""
g = globals()
try:
# 尝试如果是表达式,则返回表达式运行结果
return str(eval(py_code, g))
# 如果出错,就先测试是否对相同的变量重复赋值
except Exception as e:
global_vars_before = set(g.keys)
try:
exec(py_code, g)
except Exception as e:
return f"代码执行时报错`{e}`"
global_vars_after = set(g.keys)
new_vars = global_vars_after - global_vars_before
# 若存在新变量
if new_vars:
result = {var: g[var] for var in new_vars}
return str(result)
else:
return "已经顺利执行代码"
class FigCodeInput(BaseModel):
py_code: str = Field(
description="要执行Python绘图代码,必须使用maplotlib/seaborn创建图片"
)
fname: str = Field(
description="图像对象的变量名,例如'fig',用于从代码中提取并保存为图片"
)
@tool(args_schema=FigCodeInput)
def fig_inter(py_code: str, fname: str) -> str:
"""
当用户需要使用Python进行绘图任务时,请调用该函数
注意:
1、所有绘图代码必须创建一个图像对象,并将其赋值为指定的变量名(例如'fig')。
2、必须使用`fig = plt.figure()`或`fig = plt.subplots()`创建图像对象。
3、不要用`plt.show()`显示图像,因为这个函数会阻塞程序运行。
4、请确保代码最后调用`fig.tight_layout()`
5、所有绘图代码中,坐标轴标签(xlabel,ylabel)、标题(title)、图例(legend)等文本内容,必须使用英文字母
示例代码:
fig = plt.figure(figsize=(8,6))
plt.plot([1,2,3],[4,5,6])
fig.tight_layout()
"""
current_backend = matplotlib.get_backend()
matplotlib.use("Agg")
local_vars = {"plt": plt, "pd": pd, "sns": sns}
# 设置图像保存路径
base_dir = r"D:\PythonProject\langgraph\data-agent-ui\agent-chat-ui-main\public"
images_dir = os.path.join(base_dir, "images")
os.makedirs(images_dir, exist_ok=True)
try:
g = globals()
exec(py_code, g, local_vars)
g.update(local_vars)
fig = local_vars.get(fname, None)
if fig:
image_filename = f"{fname}.png"
abs_path = os.path.join(images_dir, image_filename)
rel_path = os.path.join("images", image_filename)
fig.savefig(abs_path, bbox_inches="tight")
return f"✅图片已经保存,路径为:{rel_path}"
else:
return "图像对象没有找到,请确认变量名正确并为matplotlib图对象"
except Exception as e:
return f"❌执行失败:{e}"
finally:
plt.close("all")
matplotlib.use(current_backend)
# 创建提示词模版
prompt = """
你是一名经验丰富的智能数据分析助手,擅长帮助用户高效完成以下任务:
1. 数据库查询
当用户需要获取数据库中某些数据或者进行sql查询时,请调用`sql_inter`工具`,该工具已经内置了pymysql连接MySQL.
你需要准确根据用户请求生成SQL语句,例如`SELECT * FROM table_name `或者包含条件的查询。
2. 数据表提取
当用户虚妄将数据库中的表格导入python环境进行后续分析,请调用`extract_data`工具`.
你需要根据用户提供的表名或查询条件生成SQL查询语句,并将数据保存到指定的pandas变量中。
3. 非绘图类任务的Python代码执行
当用户需要执行Python脚本进行数据处理、统计计算时,请调用`python_inter`工具`.
仅限执行非绘图类代码,例如变量定义、数据分析等。
4. 绘图类Python代码执行
当用户需要进行可视化展示时,请调用`fig_inter`工具`.
你可以直接读取数据并进行绘图,不需要借助`python_inter`工具读取图片
你应根据用户需求编写绘图代码,并正确指定绘图对象变量名,如 fig。
当你生成Python绘图代码时,需要指明图像的名称,如fig = plt.figure()或fig= plt.subplot()创建图像对象。
不要调用plt.show(),否则图像将无法保存。
5. 网络搜索
当用户提出与数据分析无关的问题(如最新新闻、实时信息),请调用`search_tool`工具
工具使用优先级:
如需数据库数据,请先使用`sql_inter`或`extract_data`获取,再执行Python分析或绘图。
如需绘图,请先确保数据已加载pandas对象。
回答要求:
所有回答均使用"简体中文",清晰、礼貌、简介。
如果调用工具返回结构化JSON数据,你应提取其中关键信息简要说明,并展示主要结果。
若需要用户提供更多嘻嘻,请主动提出明确的问题。
如果有生成的图片文件,请务必在回答中使用Markdown格式插入图片,如
不要仅输出图片路径文字
风格:
专业、简介、以数据驱动。
不要编造不存在的工具或数据
请根据以上原则为用户提供精准、高效的协助。
"""
tools = [
search_tool,
python_inter,
fig_inter,
sql_inter,
extract_data,
human_assistance,
]
model = ChatDeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"))
graph = create_react_agent(model=model, tools=tools, prompt=prompt)
6、langgraph.json配置内容
{
"dependencies": [
"./"
],
"graphs": {
"data_agent": "./graph.py:graph"
},
"env": ".env"
}7、安装依赖
pip install -r requirement.txt
8、启动后端
langgraph dev --host 0.0.0.0 --port 8080
9、前端启动
9.1 下载前端代码
百度网盘,链接: https://pan.baidu.com/s/1DeDIpAyEG_qj3SQVZhbo5Q?pwd=5t3t 提取码: 5t3t
9.2 前端代码增加.env配置文件
NEXT_PUBLIC_API_URL=http://localhost:8080
NEXT_PUBLIC_ASSISTANT_ID=data_agent
9.3 启动项目
yarn dev
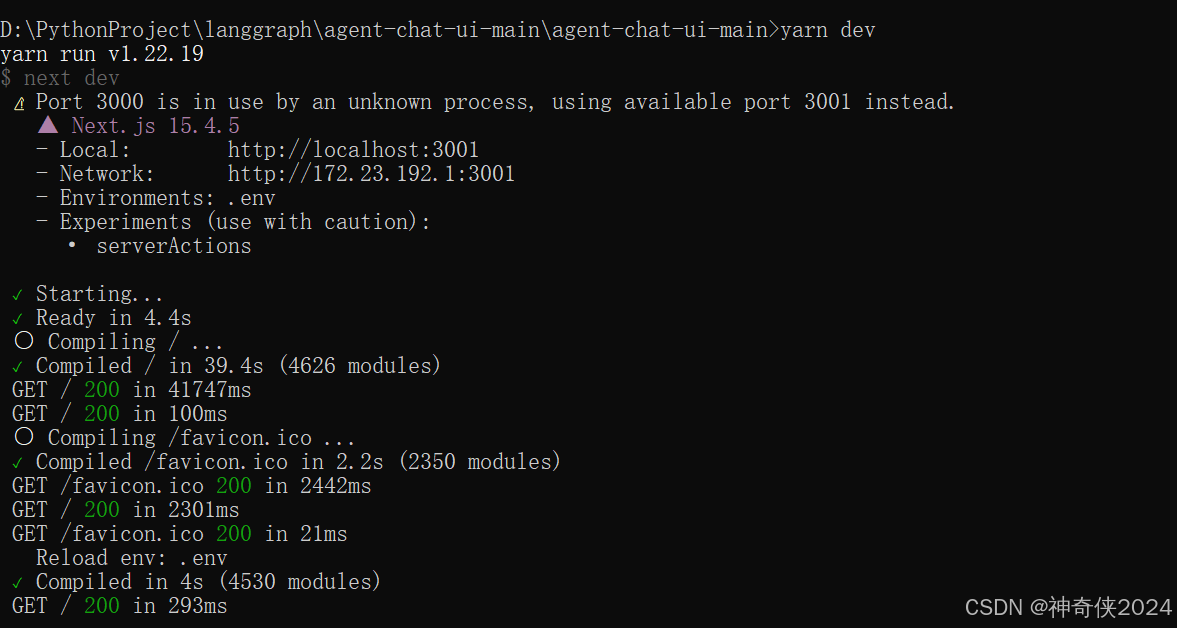
10、演示
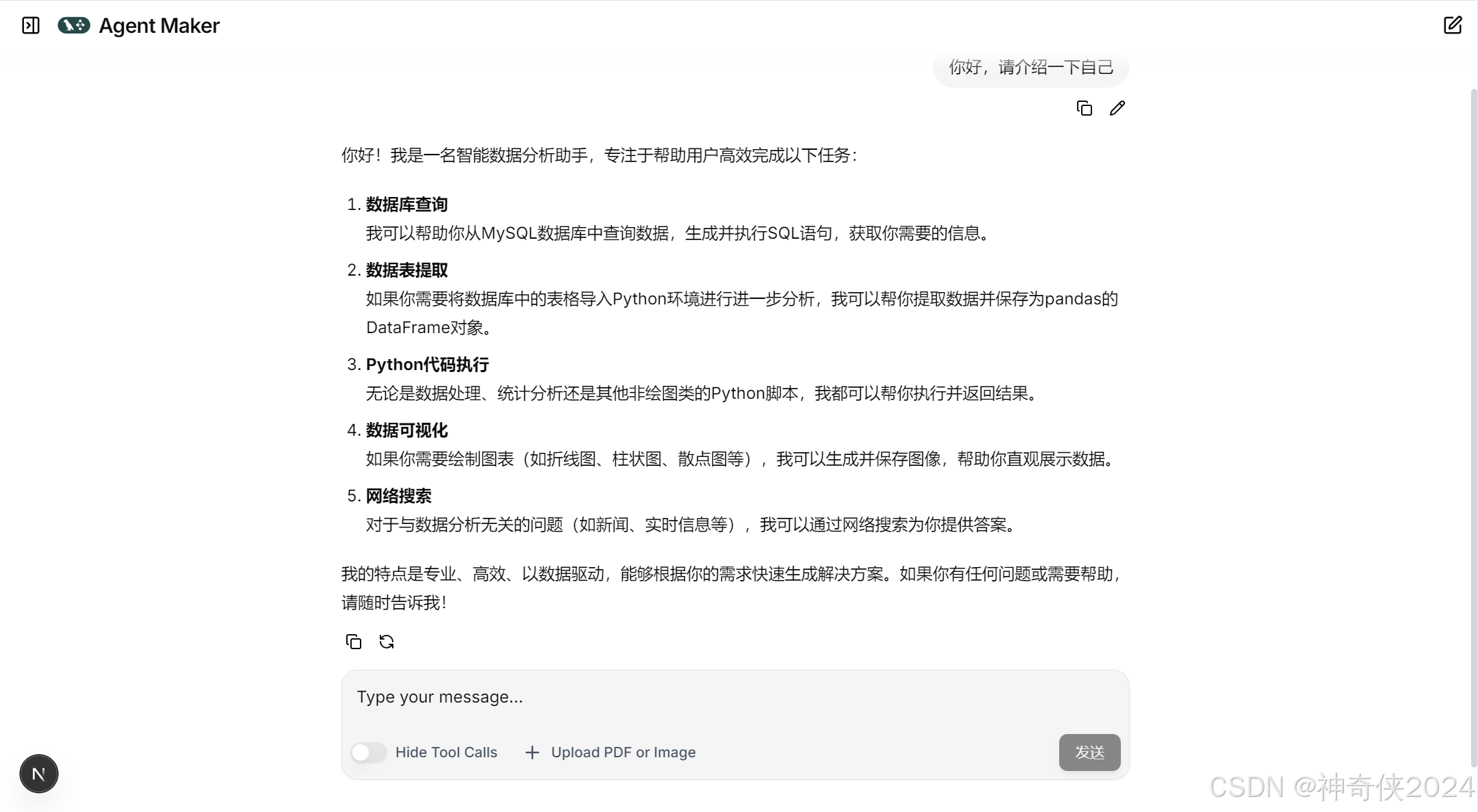
10.1 你好,请介绍一下自己
10.2 你好,当前我的数据库中,总共有几张表

10.3、请问该数据库中这些表分别有多少数据

14、请在该数据库中查询订单支付记录

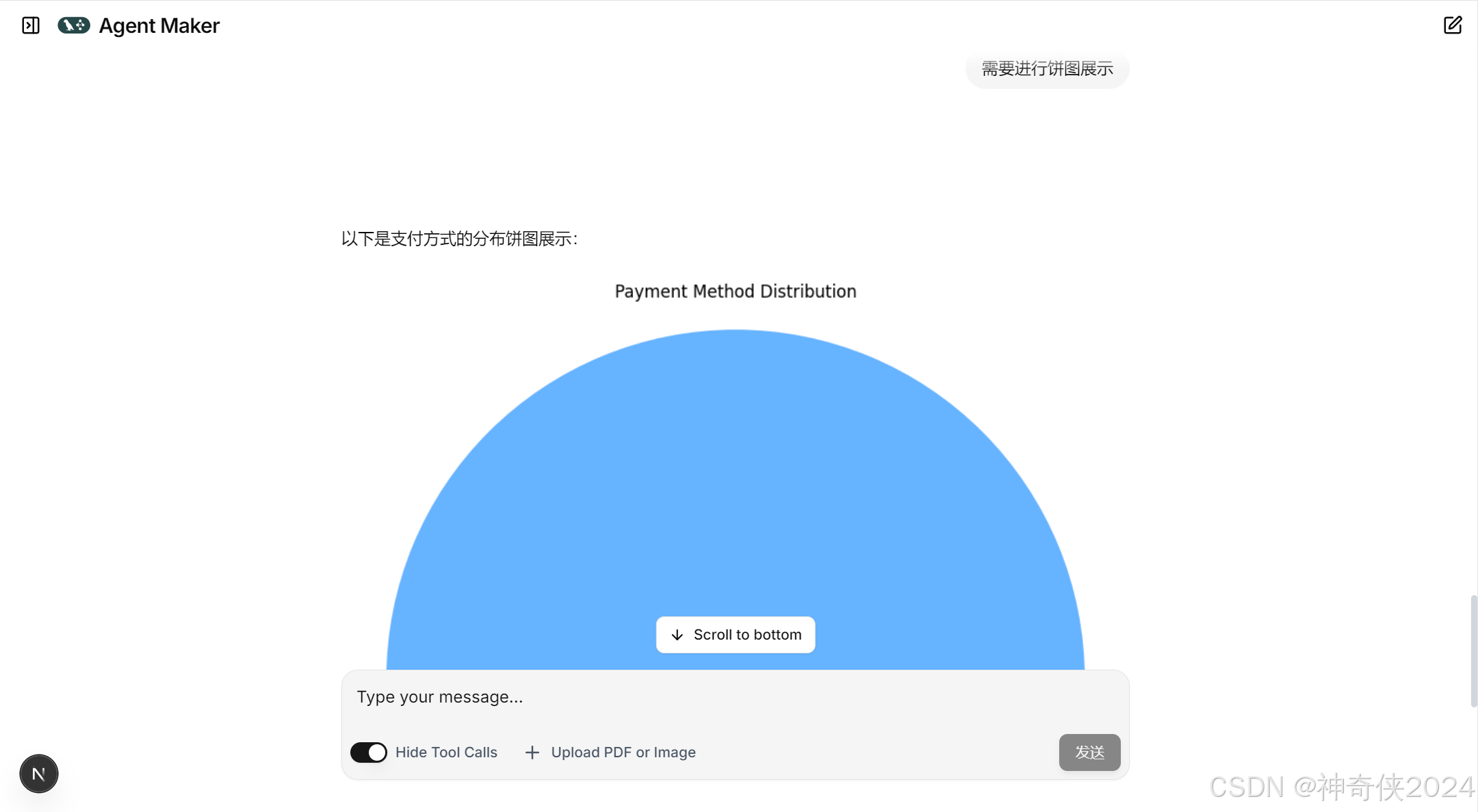
15、请分析以上数据,并通过饼图展示
11、以上是初步入门记录,希望有助于大家学习参考