目录
在网络爬虫中,当需要处理大量请求时,传统的同步爬虫往往因等待网络响应而效率低下。异步爬虫通过非阻塞的方式并发处理多个请求,能显著提升爬取效率,尤其适合高并发、多任务的场景。本文将从协程的基本原理讲起,逐步介绍异步 HTTP 库aiohttp的使用,并通过实战案例展示异步爬取的完整流程。
1、协程的基本原理:异步编程的核心
1.1 什么是协程?
协程(Coroutine)是一种轻量级的用户态线程,它不由操作系统调度,而是由程序自身控制(通过async/await关键字)。与多线程 / 多进程相比,协程的切换成本极低(无需操作系统介入),因此能在单线程内实现高并发。
1.2 同步与异步的区别
- 同步(阻塞):一个任务执行时,必须等待前一个任务完成才能开始(如传统
requests爬虫,等待响应时会阻塞整个程序)。 - 异步(非阻塞):多个任务可以交替执行,当一个任务等待 IO(如网络响应)时,程序会切换到其他任务,避免空闲等待(核心优势)。
1.3 协程的工作流程(类比生活场景)
- 同步:一个服务员(线程)服务一桌客人(任务),点单后必须等待厨房做菜(IO 等待),期间什么都不做。
- 异步:一个服务员同时服务多桌客人,点单后(发起请求),在等菜时(IO 等待)去服务其他客人,菜做好了再回来上菜(处理响应)。
1.4 Python 协程的核心语法
async def:定义一个协程函数(不能直接调用,需通过事件循环运行)。await:暂停协程执行,等待另一个协程完成(通常用于 IO 操作)。- 事件循环(Event Loop):协程的 “调度中心”,负责管理所有协程的执行顺序。
"""
文件名: 1
作者: 墨尘
日期: 2025/8/8
项目名: pythonProject
备注:
"""
import asyncio
# 定义协程函数
async def task(name, delay):
print(f"任务 {name} 开始")
await asyncio.sleep(delay) # 模拟IO等待(非阻塞)
print(f"任务 {name} 完成(耗时{delay}秒)")
# 运行协程
async def main():
# 并发执行两个任务
await asyncio.gather(
task("A", 2),
task("B", 1)
)
# 启动事件循环
asyncio.run(main())
输出结果(体现非阻塞特性):
任务 A 开始
任务 B 开始
任务 B 完成(耗时1秒)
任务 A 完成(耗时2秒)
2、aiohttp:异步 HTTP 请求的利器
aiohttp是 Python 中最常用的异步 HTTP 客户端 / 服务器库,支持异步发送 HTTP 请求,完美适配协程语法,是异步爬虫的核心工具。
2.1 安装 aiohttp
pip install aiohttp
2.2 aiohttp 的核心用法
2.2.1 发送异步 GET 请求
"""
文件名: 2
作者: 墨尘
日期: 2025/8/8
项目名: pythonProject
备注:
"""
import aiohttp
import asyncio
async def fetch_url(url):
# 创建异步会话(类似requests的Session)
async with aiohttp.ClientSession() as session:
# 发送GET请求(await等待响应)
async with session.get(url) as response:
# 获取响应状态码和文本内容
return {
"status": response.status,
"content": await response.text() # 异步获取文本
}
async def main():
url = "https://httpbin.org/get"
result = await fetch_url(url)
print(f"状态码:{result['status']}")
print(f"内容预览:{result['content'][:200]}")
asyncio.run(main())
结果

2.2.2 发送带参数的请求
"""
文件名: 3
作者: 墨尘
日期: 2025/8/8
项目名: pythonProject
备注:
"""
import aiohttp
import asyncio
async def fetch_with_params():
async with aiohttp.ClientSession() as session:
params = {"name": "异步爬虫", "page": 1}
async with session.get("https://httpbin.org/get", params=params) as response:
data = await response.json() # 异步解析JSON
print("带参数的响应:", data)
asyncio.run(fetch_with_params())
结果
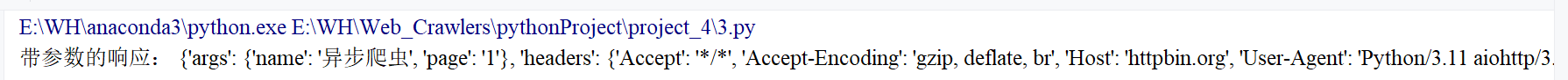
2.2.3 处理异常(网络错误、超时等)
"""
文件名: 4
作者: 墨尘
日期: 2025/8/8
项目名: pythonProject
备注:
"""
import aiohttp
import asyncio
async def fetch_with_error_handling(url):
try:
async with aiohttp.ClientSession() as session:
# 设置超时(5秒)
timeout = aiohttp.ClientTimeout(total=5)
async with session.get(url, timeout=timeout) as response:
return await response.text()
except aiohttp.ClientError as e:
print(f"请求错误:{e}")
except asyncio.TimeoutError:
print("请求超时")
asyncio.run(fetch_with_error_handling("https://httpbin.org/delay/10")) # 模拟超时
结果

3、aiohttp 异步爬取实战:批量爬取电影数据
以测试站点https://spa1.scrape.center/api/movie为例,演示如何用aiohttp异步爬取多页电影数据,对比同步与异步的效率差异。
3.1 目标与分析
- 目标:爬取前 5 页电影列表(每页 10 条数据)。
- 接口:
https://spa1.scrape.center/api/movie?limit=10&offset={offset}(offset为偏移量,第 1 页 = 0,第 2 页 = 10...)。 - 对比:同步爬虫(
requests)与异步爬虫(aiohttp)的耗时。
3.2 同步爬虫实现(作为对比)
"""
文件名: 5
作者: 墨尘
日期: 2025/8/8
项目名: pythonProject
备注: 同步爬虫
"""
# 导入所需库
import requests # 用于发送同步HTTP请求
import time # 用于计算程序运行时间
import warnings # 用于过滤警告信息
from urllib3.exceptions import InsecureRequestWarning # 导入特定警告类
# 过滤SSL证书验证警告(因目标网站证书问题,测试场景临时关闭)
# 作用:消除控制台中"Unverified HTTPS request"的警告信息,使输出更整洁
warnings.filterwarnings("ignore", category=InsecureRequestWarning)
def sync_fetch(url):
"""
同步获取指定URL的JSON数据
:param url: 目标请求URL
:return: 解析后的JSON数据(字典/列表),失败则返回None
"""
try:
# 发送GET请求
# verify=False:跳过SSL证书验证(解决网站证书过期/无效问题)
# timeout=10:设置超时时间(10秒内无响应则放弃,避免无限等待)
response = requests.get(url, verify=False, timeout=10)
# 解析响应内容为JSON格式(接口返回数据为JSON)
return response.json()
# 捕获所有可能的异常(网络错误、超时、JSON解析失败等)
except Exception as e:
print(f"同步请求失败:{e}") # 打印错误信息
return None # 失败时返回None
def sync_main():
"""同步爬虫主函数:协调爬取流程并计算耗时"""
# 记录程序开始时间(用于计算总耗时)
start_time = time.time()
# 生成需要爬取的URL列表(前5页电影数据)
# 接口规律:offset=0(第1页)、offset=10(第2页)... offset=40(第5页)
urls = [
f"https://spa1.scrape.center/api/movie?limit=10&offset={i * 10}"
for i in range(5) # i=0到4,共5页
]
# 遍历URL列表,同步爬取每一页数据
for url in urls:
# 调用同步请求函数获取数据
data = sync_fetch(url)
# 若数据获取成功,则打印爬取信息
if data:
# 从返回数据中提取电影数量(接口返回格式为{"count":总数, "results":列表})
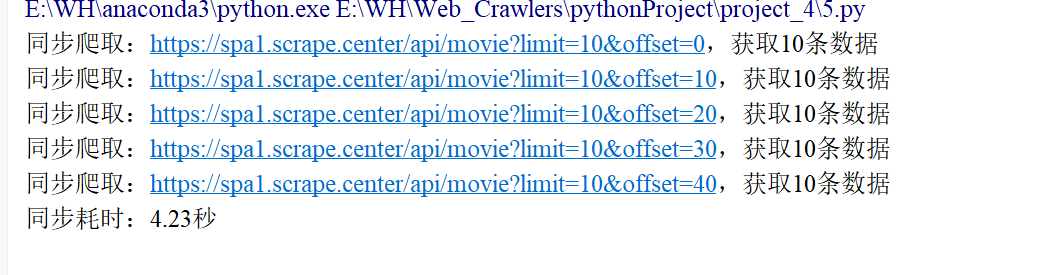
print(f"同步爬取:{url},获取{len(data['results'])}条数据")
# 计算并打印总耗时(当前时间 - 开始时间)
# 保留2位小数,直观展示同步爬取效率
print(f"同步耗时:{time.time() - start_time:.2f}秒")
# 程序入口(当脚本直接运行时执行)
if __name__ == "__main__":
# 调用主函数启动同步爬取
sync_main()结果
3.3 异步爬虫实现(aiohttp)
"""
文件名: 6
作者: 墨尘
日期: 2025/8/8
项目名: pythonProject
备注:
"""
# 导入所需库
import aiohttp # 用于发送异步HTTP请求
import asyncio # 用于实现异步编程(协程、事件循环等)
import time # 用于计算程序运行时间
import warnings # 用于过滤警告信息
from urllib3.exceptions import InsecureRequestWarning # 导入特定警告类
# 过滤SSL证书验证警告(与同步版作用相同,消除控制台冗余输出)
warnings.filterwarnings("ignore", category=InsecureRequestWarning)
async def async_fetch(session, url):
"""
异步获取指定URL的JSON数据
:param session: aiohttp的ClientSession对象(用于复用连接)
:param url: 目标请求URL
:return: 解析后的JSON数据(字典/列表),失败则返回None
"""
try:
# 发送异步GET请求(async with语法自动管理请求生命周期)
# verify_ssl=False:aiohttp中跳过SSL验证的参数(与requests的verify=False作用相同)
# timeout=10:设置超时时间(避免请求无响应)
async with session.get(url, verify_ssl=False, timeout=10) as response:
# 异步解析响应内容为JSON(await等待IO操作完成)
# 注意:aiohttp中必须用await调用异步方法
return await response.json()
# 捕获所有可能的异常(网络错误、超时、JSON解析失败等)
except Exception as e:
print(f"异步请求失败:{e}") # 打印错误信息
return None # 失败时返回None
async def async_main():
"""异步爬虫主函数:协调并发爬取流程并计算耗时"""
# 记录程序开始时间
start_time = time.time()
# 生成需要爬取的URL列表(与同步版相同,前5页电影数据)
urls = [
f"https://spa1.scrape.center/api/movie?limit=10&offset={i * 10}"
for i in range(5)
]
# 创建异步会话(ClientSession是aiohttp的核心对象,类似requests的Session)
# async with语法自动管理会话生命周期(无需手动关闭)
async with aiohttp.ClientSession() as session:
# 生成所有异步任务(将每个URL的请求封装为一个协程任务)
# 注意:此时任务未执行,仅创建任务列表
tasks = [async_fetch(session, url) for url in urls]
# 并发执行所有任务(gather函数等待所有任务完成并返回结果列表)
# *tasks:解包任务列表,作为gather的参数
results = await asyncio.gather(*tasks)
# 遍历结果列表,打印每一页的爬取信息
# zip(urls, results):将URL与对应的结果关联起来
for url, data in zip(urls, results):
if data: # 若数据不为空(爬取成功)
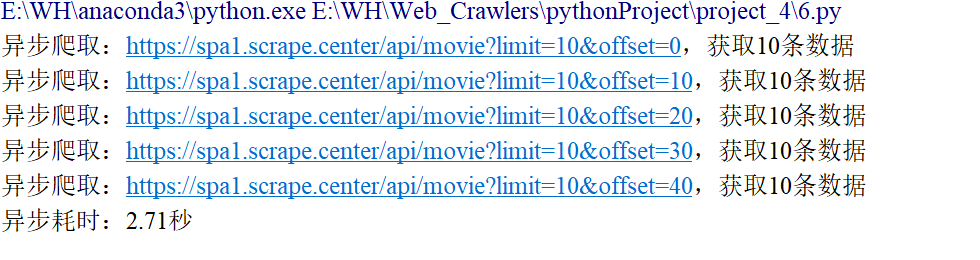
print(f"异步爬取:{url},获取{len(data['results'])}条数据")
# 计算并打印总耗时(异步效率优势在此处体现)
print(f"异步耗时:{time.time() - start_time:.2f}秒")
# 程序入口(当脚本直接运行时执行)
if __name__ == "__main__":
# 启动异步事件循环,运行异步主函数
# asyncio.run()是Python 3.7+的简化写法,自动管理事件循环
asyncio.run(async_main())结果
3.4 运行结果对比
- 同步爬虫:耗时约 4.23秒(依次等待每个请求响应)。
- 异步爬虫:耗时约 2.71 秒(并发请求,同时等待所有响应)。
结论:异步爬虫在多任务场景下效率提升显著,请求越多,优势越明显。
3.5 实战优化:控制并发数量
为避免给服务器造成过大压力,可通过信号量(Semaphore) 限制并发数(如同时最多 5 个请求)
async def async_fetch_with_limit(session, url, semaphore):
async with semaphore: # 控制并发
return await async_fetch(session, url)
async def async_main_with_limit():
semaphore = asyncio.Semaphore(5) # 最多5个并发请求
async with aiohttp.ClientSession() as session:
tasks = [
async_fetch_with_limit(session, url, semaphore)
for url in urls
]
await asyncio.gather(*tasks)
4、总结与进阶
4.1 异步爬虫的适用场景
- 需发送大量 HTTP 请求(如批量爬取列表、分页数据)。
- 网络 IO 等待时间长(如目标网站响应慢)。
- 对爬取效率要求高的场景。
4.2 注意事项
- 控制并发数:避免因请求过于密集被封 IP 或触发反爬。
- 异常处理:异步代码中异常容易被忽略,需完善
try/except。 - 遵守 robots 协议:异步效率高,更应尊重网站爬取规则。