1. 实现功能
M4-3: 智能后处理 - 停顿感知增强版 (终极版)
本脚本是 M4-3 的重大升级,引入了“停顿感知”能力:
- 利用 Whisper 分段信息: 将 Whisper 的 segments 间的自然停顿作为强信号 ([P]) 提供给 LLM。
- 全新 Prompt: 设计了专门的 Prompt,指导 LLM 理解并利用 [P] 标记,实现更精准、更自然的断句。
- 保留了之前版本的所有优点:详细的耗时统计、清晰的流程、支持多种模型加载方式等。
2.运行效果
conda activate whisper
(base) root@DESKTOP-8IU6393:/home/gpu3090# conda activate whisper
/root/anaconda3/envs/whisper/bin/python /home/gpu3090/vscode/M4-实用技巧/M4-3-大模型接入.py
(whisper) root@DESKTOP-8IU6393:/home/gpu3090# /root/anaconda3/envs/whisper/bin/python /home/gpu3090/vscode/M4-实用技巧/M4-3-大模型接入.py
🚀 开始 Whisper 语音转录与智能后处理流程 (v4.0 - 停顿感知版)
======================================================================
🔧 步骤 1: 正在加载 Whisper 模型 'large-v3' 到 cuda...
🌐 使用在线模型: large-v3
✅ 模型加载完成。耗时: 0:00:27.998095
🎙️ 步骤 2: 正在转录音频文件...
📄 文件路径: /home/gpu3090/vscode/M4-实用技巧/../audio/26.mp3
🌍 语言设置: zh
100%|██████████████████████████| 17888/17888 [00:29<00:00, 608.34frames/s]
✅ 音频转录完成。耗时: 0:00:32.950243
📊 原始文本长度: 508 字符, 分段数: 57
📝 原始转录文本 (无标点拼接):
--------------------------------------------------
作品二十六号我们家的后园有半亩空地母亲说,让她慌着怪可惜的你们那么爱吃花生,就开辟出来种花生吧我们姐弟几个都很高兴埋种、翻地、播种、浇水没过几个月,居然收获了母亲说,今晚我们过一个收获节请你们父亲也来尝尝我们的新花生,好不好我们都说好母亲把花生做成了好几样食品还吩咐就在后园的茅亭里过这个节晚上天色不太好可是父亲也来了实在很难得父亲说,你们爱吃花生吗我们争着答应,爱谁能把花生的好处说出来姐姐说,花生的味儿美哥哥说,花生可以榨油我说,花生的价钱便宜谁都可以买来吃,都喜欢吃这就是它的好处父亲说,花生的好处很多有一样最可贵它的果实埋在地里不像桃子、石榴、苹果那样把鲜红嫩绿的果实高高地挂在枝头上使人一见就生爱慕之心你们看它矮矮地长在地上等到成熟了就会吃了也不能立刻分辨出来它有没有果实必须挖出来才知道我们都说是母亲也点点头父亲接下去说所以你们要像花生它虽然不好看可是很有用不是外表好看而没有实用的东西我说那么人要做有用的人不是外表好看不要做只讲体面而对别人没有好处的人了父亲说对这是我对你们的希望我们谈到夜深才散花生做的食品都吃完了父亲的话却深深地印在我的心上欢迎光临普通话学习网3w.png.compthxx.com
--------------------------------------------------
🔄 步骤 3 & 4: 正在进行热词替换与中英文空格处理 (逐段进行)...
✅ 热词与空格处理完成。耗时: 0:00:00.002897
🤖 步骤 5: 正在调用 LLM 'qwen3:14b' 进行停顿感知智能标点...
🔄 正在发送请求到 Ollama...
✅ Ollama 处理完成。
✅ LLM 标点处理完成。耗时: 0:01:18.138540
📊 最终文本长度: 3054 字符
✨ LLM 处理后最终文本:
==================================================
<think>
好的,我现在需要处理用户提供的这段文本,添加合适的标点。首先,我要仔细阅读用户的要求,确保完全理解任务。用户提到,原始文本由多个语音片段拼接而成,使用了[P]标记表示自然停顿点,这些地方需要优先考虑使用逗号或句号。同时,不能增删或改动原文内容,最终输出要移除所有[P]标记。
首先,我会通读整个文本,识别所有[P]的位置,并考虑每个位置应该使用哪种标点。例如,第一个[P]出现在“作品二十六号”之后,这里可能是一个段落的开始,所以可能需要句号,但根据上下文,可能更适合用逗号,不过需要看后面的内容。不过,根据指导原则,[P]是强烈的断句提示,所以应该优先处理。
接下来,我会逐段处理。例如,“作品二十六号[P]我们家的后园有半亩空地”这里,[P]后面是新的句子,所以应该在“作品二十六号”后面加句号,然后开始新句。不过,可能“作品二十六号”是一个标题,所以可能需要单独处理,但用户没有说明,所以按照普通文本处理。
然后,检查每个[P]的位置,替换为逗号或句号。例如,“母亲说,让她慌着怪可惜的[P]你们那么爱吃花生”这里,[P]后面是新的句子,所以应该在“怪可惜的”后面加句号,然后开始新句。不过原句中的逗号可能已经存在,需要确认是否正确。
另外,要注意句子的长度,如果在没有[P]的片段内部句子过长,可以添加逗号。例如,“埋种、翻地、播种、浇水”这里可能需要逗号分隔动作,但原句中没有,所以可能不需要,但根据指导原则,可以添加。
还需要注意引号的使用,比如“母亲说,让她慌着怪可惜的”中的逗号是否正确,可能需要调整为句号,但用户要求不能改动原文,所以只能在[P]处处理。
最后,处理完所有[P]后,移除这些标记,并检查整个文本的标点是否流畅,是否符合中文的标点习惯,同时确保没有改动原文内容。
现在,我需要逐步处理每个[P]的位置,并确保标点正确。例如:
- 作品二十六号[P] → 作品二十六号。
- 母亲说,让她慌着怪可惜的[P] → 母亲说,让她慌着怪可惜的。
- 你们那么爱吃花生,就开辟出来种花生吧[P] → 你们那么爱吃花生,就开辟出来种花生吧。
- 我们姐弟几个都很高兴[P] → 我们姐弟几个都很高兴。
- 埋种、翻地、播种、浇水[P] → 埋种、翻地、播种、浇水。
- 没过几个月,居然收获了[P] → 没过几个月,居然收获了。
- 母亲说,今晚我们过一个收获节[P] → 母亲说,今晚我们过一个收获节。
- 请你们父亲也来尝尝我们的新花生,好不好[P] → 请你们父亲也来尝尝我们的新花生,好不好。
- 我们都说好[P] → 我们都说好。
- 母亲把花生做成了好几样食品[P] → 母亲把花生做成了好几样食品。
- 还吩咐就在后园的茅亭里过这个节[P] → 还吩咐就在后园的茅亭里过这个节。
- 晚上天色不太好[P] → 晚上天色不太好。
- 可是父亲也来了[P] → 可是父亲也来了。
- 实在很难得[P] → 实在很难得。
- 父亲说,你们爱吃花生吗[P] → 父亲说,你们爱吃花生吗。
- 我们争着答应,爱[P] → 我们争着答应,爱。
- 谁能把花生的好处说出来[P] → 谁能把花生的好处说出来。
- 姐姐说,花生的味儿美[P] → 姐姐说,花生的味儿美。
- 哥哥说,花生可以榨油[P] → 哥哥说,花生可以榨油。
- 我说,花生的价钱便宜[P] → 我说,花生的价钱便宜。
- 谁都可以买来吃,都喜欢吃[P] → 谁都可以买来吃,都喜欢吃。
- 这就是它的好处[P] → 这就是它的好处。
- 父亲说,花生的好处很多[P] → 父亲说,花生的好处很多。
- 有一样最可贵[P] → 有一样最可贵。
- 它的果实埋在地里[P] → 它的果实埋在地里。
- 不像桃子、石榴、苹果那样[P] → 不像桃子、石榴、苹果那样。
- 把鲜红嫩绿的果实高高地挂在枝头上[P] → 把鲜红嫩绿的果实高高地挂在枝头上。
- 使人一见就生爱慕之心[P] → 使人一见就生爱慕之心。
- 你们看它矮矮地长在地上[P] → 你们看它矮矮地长在地上。
- 等到成熟了[P] → 等到成熟了。
- 就会吃了[P] → 就会吃了。
- 也不能立刻分辨出来[P] → 也不能立刻分辨出来。
- 它有没有果实[P] → 它有没有果实。
- 必须挖出来才知道[P] → 必须挖出来才知道。
- 我们都说是[P] → 我们都说是。
- 母亲也点点头[P] → 母亲也点点头。
- 父亲接下去说[P] → 父亲接下去说。
- 所以你们要像花生[P] → 所以你们要像花生。
- 它虽然不好看[P] → 它虽然不好看。
- 可是很有用[P] → 可是很有用。
- 不是外表好看[P] → 不是外表好看。
- 而没有实用的东西[P] → 而没有实用的东西。
- 我说[P] → 我说。
- 那么人要做有用的人[P] → 那么人要做有用的人。
- 不是外表好看[P] → 不是外表好看。
- 不要做只讲体面[P] → 不要做只讲体面。
- 而对别人没有好处的人了[P] → 而对别人没有好处的人了。
- 父亲说[P] → 父亲说。
- 对[P] → 对。
- 这是我对你们的希望[P] → 这是我对你们的希望。
- 我们谈到夜深才散[P] → 我们谈到夜深才散。
- 花生做的食品都吃完了[P] → 花生做的食品都吃完了。
- 父亲的话却深深地印在我的心上[P] → 父亲的话却深深地印在我的心上。
- 欢迎光临普通话学习网[P] → 欢迎光临普通话学习网。
- 3w.png.com[P] → 3w.png.com。
- pthxx.com → pthxx.com。
处理完所有[P]后,需要检查是否有遗漏,确保所有[P]都被替换,并且标点正确。同时,检查句子的连贯性和标点是否符合中文习惯,比如逗号和句号的使用是否恰当,引号内的标点是否正确等。
最后,确保没有改动原文的任何汉字或英文单词,只添加了标点,并移除了所有[P]标记。
</think>
作品二十六号。我们家的后园有半亩空地。母亲说,让她慌着怪可惜的。你们那么爱吃花生,就开辟出来种花生吧。我们姐弟几个都很高兴。埋种、翻地、播种、浇水。没过几个月,居然收获了。母亲说,今晚我们过一个收获节。请你们父亲也来尝尝我们的新花生,好不好?我们都说好。母亲把花生做成了好几样食品。还吩咐就在后园的茅亭里过这个节。晚上天色不太好。可是父亲也来了。实在很难得。父亲说,你们爱吃花生吗?我们争着答应,爱。谁能把花生的好处说出来?姐姐说,花生的味儿美。哥哥说,花生可以榨油。我说,花生的价钱便宜。谁都可以买来吃,都喜欢吃。这就是它的好处。父亲说,花生的好处很多。有一样最可贵。它的果实埋在地里。不像桃子、石榴、苹果那样。把鲜红嫩绿的果实高高地挂在枝头上。使人一见就生爱慕之心。你们看它矮矮地长在地上。等到成熟了,就会吃了。也不能立刻分辨出来。它有没有果实?必须挖出来才知道。我们都说是。母亲也点点头。父亲接下去说。所以你们要像花生。它虽然不好看。可是很有用。不是外表好看,而没有实用的东西。我说,那么人要做有用的人。不是外表好看,不要做只讲体面,而对别人没有好处的人了。父亲说,对。这是我对你们的希望。我们谈到夜深才散。花生做的食品都吃完了。父亲的话却深深地印在我的心上。欢迎光临普通话学习网。3w.png.com。pthxx.com
==================================================
💾 步骤 6: 正在保存最终文本...
📁 文件已保存: /home/gpu3090/26_whisper_final.txt
📁 文件已保存: /home/gpu3090/26_whisper_original.txt
📁 原始文本已保存: /home/gpu3090/26_whisper_original.txt
✅ 文件保存完成。耗时: 0:00:00.000570
🎉 全部流程完成!
======================================================================
⏱️ 各步骤耗时统计:
步骤1 (模型加载): 0:00:27.998095
步骤2 (音频转录): 0:00:32.950243
步骤3&4 (预处理): 0:00:00.002897
步骤5 (LLM标点): 0:01:18.138540
步骤6 (文件保存): 0:00:00.000570
⏰ 总计耗时: 0:02:19.314213
📁 输出文件:
📄 最终文本: ./26_whisper_final.txt
📄 原始文本: ./26_whisper_original.txt
======================================================================
3.实现过程
(base) root@DESKTOP-8IU6393:/home/gpu3090# conda activate whisper
/root/anaconda3/envs/whisper/bin/python /home/gpu3090/vscode/M4-实用技巧/M4-3-大模型接入.py
3.1 报错处理
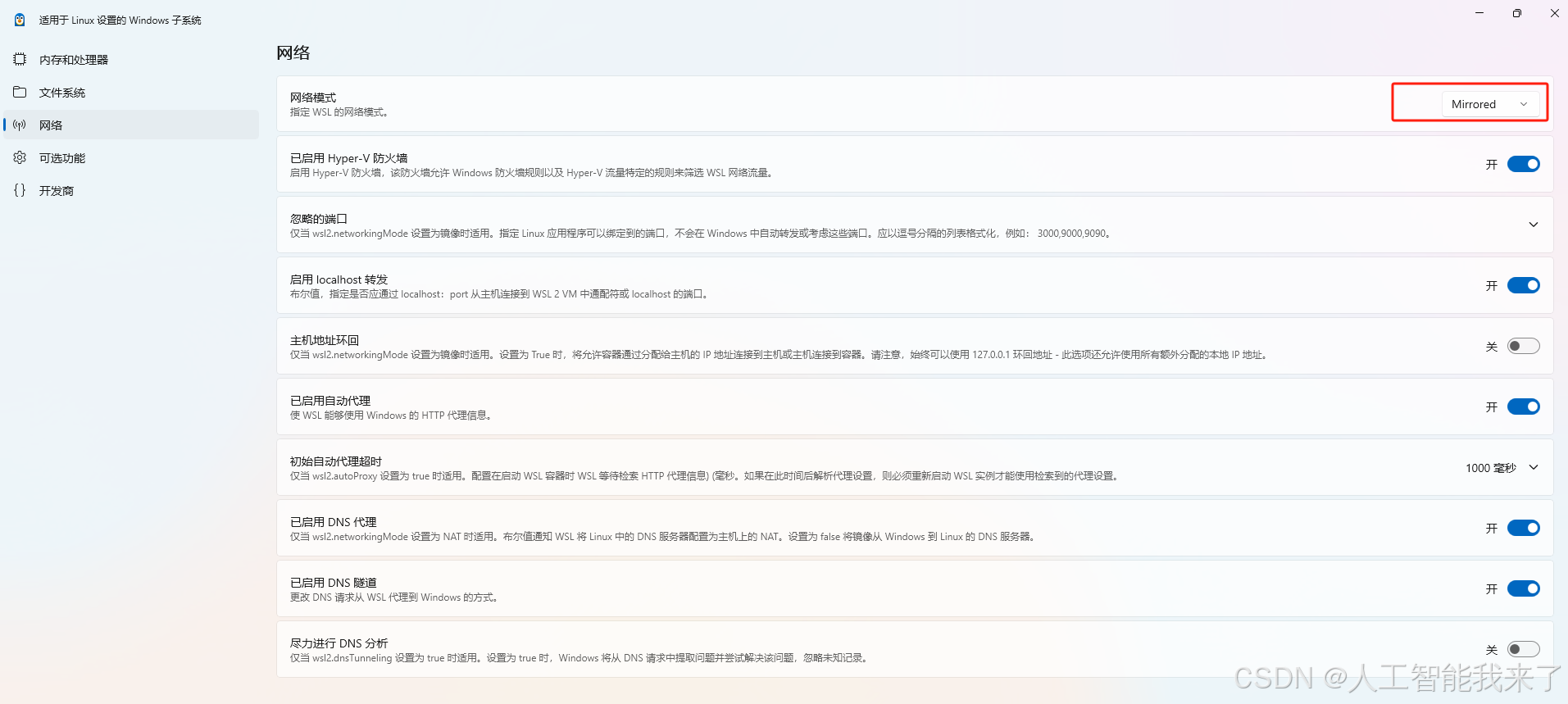
当遇到ollama连接失败的时候,配置网络模式为镜像,重启wsl即可

C:\Users\Administrator>wsl -- shutdown
wsl: 检测到 localhost 代理配置,但未镜像到 WSL。NAT 模式下的 WSL 不支持 localhost 代理。
Shutdown scheduled for Sun 2025-08-10 12:30:30 CST, use 'shutdown -c' to cancel.
C:\Users\Administrator>wsl -u root
wsl: 检测到 localhost 代理配置,但未镜像到 WSL。NAT 模式下的 WSL 不支持 localhost 代理。
(base) root@DESKTOP-8IU6393:/mnt/c/Users/Administrator# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 198.18.0.1 netmask 255.255.255.252 broadcast 198.18.0.3
inet6 fdfe:dcba:9876::1 prefixlen 126 scopeid 0x0<global>
ether 00:15:5d:b2:6a:b2 txqueuelen 1000 (Ethernet)
RX packets 10 bytes 628 (628.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1376 (1.3 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1492
inet 192.168.1.8 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 2409:8a5c:326:cf70:7d68:89e6:88c5:f000 prefixlen 128 scopeid 0x0<global>
inet6 fe80::e56e:68b6:c226:6373 prefixlen 64 scopeid 0x20<link>
inet6 2409:8a5c:326:cf70:1720:1956:e512:56ac prefixlen 64 scopeid 0x0<global>
ether f0:2f:74:1a:39:e7 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1900 (1.9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 12 bytes 972 (972.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 12 bytes 972 (972.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
loopback0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
ether 00:15:5d:81:e5:df txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
(base) root@DESKTOP-8IU6393:/mnt/c/Users/Administrator#
3.2 代码
import os
import whisper
import datetime
import torch
import re
import ollama
# --- 1. 文本处理函数 ---
def apply_replacements(text, replacement_map):
"""对单个文本片段应用热词替换规则。"""
for old_word, new_word in replacement_map.items():
text = text.replace(old_word, new_word)
return text
def add_spaces_around_english(text):
"""为中英文混排文本自动添加空格。"""
pattern1 = re.compile(r'([\u4e00-\u9fa5])([a-zA-Z0-9]+)')
pattern2 = re.compile(r'([a-zA-Z0-9]+)([\u4e00-\u9fa5])')
text = pattern1.sub(r'\1 \2', text)
text = pattern2.sub(r'\1 \2', text)
return text
# <--- 重点修改:此函数现在接收 segments,并使用带 [P] 的 Prompt ---
def enhance_punctuation_with_llm(segments, llm_model_name):
"""
使用 LLM 为文本智能添加标点,利用 Whisper 的分段作为停顿信号。
"""
# 1. 在 segment 之间插入 [P] 标记作为停顿提示
# ["你好", "今天天气不错"] -> "你好[P]今天天气不错"
text_with_pauses = "[P]".join([s['text'].strip() for s in segments if s['text'].strip()])
if not text_with_pauses.strip():
print("⚠️ 文本内容为空,跳过 LLM 处理。")
return "" # 返回空字符串
# 2. 构建新的、更智能的 Prompt
prompt = f"""# 角色
你是一位顶级的中文文案编辑,能深刻理解语音节奏和书面表达的转换。
# 任务
为下面的原始文本添加标点。这段文本由多个语音片段拼接而成,我使用了特殊标记 `[P]` 来表示原始语音中的自然停顿点。
# 指导原则
1. **关键指令**: `[P]` 标记处是强烈的断句提示。你应该在这些位置优先考虑使用逗号(,)或句号(。)。
2. **句内微调**: 即使在没有 `[P]` 标记的片段内部,如果句子过长,你也可以根据逻辑添加逗号。
3. **忠实内容**: 绝对不允许增删或改动原文的任何汉字或英文单词。
4. **最终输出**: 在最终结果中,必须移除所有的 `[P]` 标记。
# 待处理文本
---
{text_with_pauses}
---
# 输出要求
直接输出经过你精细编辑和标点优化后的最终文本,确保不含 `[P]` 标记。"""
# 3. 调用 Ollama API
try:
print(" 🔄 正在发送请求到 Ollama...")
response = ollama.chat(
model=llm_model_name,
messages=[{'role': 'user', 'content': prompt}],
options={'temperature': 0.2} # 较低的温度让输出更稳定
)
punctuated_text = response['message']['content'].strip()
print(" ✅ Ollama 处理完成。")
return punctuated_text
except Exception as e:
print(f"❌ 调用 Ollama API 时出错: {e}")
# 出错时,返回一个不带标点的、拼接好的文本作为后备
fallback_text = " ".join([s['text'].strip() for s in segments])
print(" ⚠️ 将使用未处理的原始拼接文本继续。")
return fallback_text
def save_text_file(text, output_path):
"""将文本保存为 TXT 文件。"""
with open(output_path, 'w', encoding='utf-8') as txt_file:
txt_file.write(text)
print(f"📁 文件已保存: {os.path.abspath(output_path)}")
# --- 2. 主流程函数 ---
def run_transcription_pipeline(model_name, media_path, language, replacement_map, llm_model_name):
"""执行完整的转录和后处理流程,每一步都有详细的耗时统计。"""
print("🚀 开始 Whisper 语音转录与智能后处理流程 (v4.0 - 停顿感知版)")
print("=" * 70)
total_start_time = datetime.datetime.now()
script_dir = os.path.dirname(os.path.abspath(__file__)) if '__file__' in locals() else '.'
output_dir = script_dir
device = "cuda" if torch.cuda.is_available() else "cpu"
# --- 步骤 1: 加载模型 (代码不变) ---
# ... (与您提供的代码完全相同)
step1_start = datetime.datetime.now()
print(f"🔧 步骤 1: 正在加载 Whisper 模型 '{model_name}' 到 {device}...")
if os.path.exists(model_name) or '/' in model_name or model_name.endswith('.pt'):
model = whisper.load_model(model_name, device=device)
print(f" 📂 使用本地模型文件: {model_name}")
else:
model = whisper.load_model(model_name, device=device)
print(f" 🌐 使用在线模型: {model_name}")
step1_end = datetime.datetime.now()
step1_duration = step1_end - step1_start
print(f"✅ 模型加载完成。耗时: {step1_duration}\n")
# --- 步骤 2: 转录音频 (代码不变) ---
step2_start = datetime.datetime.now()
print(f"🎙️ 步骤 2: 正在转录音频文件...")
print(f" 📄 文件路径: {media_path}")
print(f" 🌍 语言设置: {language}")
result = model.transcribe(media_path, language=language, verbose=False)
# <--- 修改:现在我们保留 segments,原始文本仅用于展示 ---
original_segments = result['segments']
original_text_display = result['text'].strip()
step2_end = datetime.datetime.now()
step2_duration = step2_end - step2_start
print(f"✅ 音频转录完成。耗时: {step2_duration}")
print(f"📊 原始文本长度: {len(original_text_display)} 字符, 分段数: {len(original_segments)}")
print("\n📝 原始转录文本 (无标点拼接):")
print("-" * 50)
print(original_text_display)
print("-" * 50 + "\n")
# <--- 修改:后续处理现在基于 segments ---
# --- 步骤 3 & 4: 逐段进行热词替换和空格处理 ---
step3_4_start = datetime.datetime.now()
print("🔄 步骤 3 & 4: 正在进行热词替换与中英文空格处理 (逐段进行)...")
processed_segments = []
for segment in original_segments:
# 复制 segment 以免修改原始数据
new_segment = segment.copy()
# 步骤 3: 热词替换
text = apply_replacements(new_segment['text'], replacement_map)
# 步骤 4: 中英文空格
text = add_spaces_around_english(text)
new_segment['text'] = text
processed_segments.append(new_segment)
step3_4_end = datetime.datetime.now()
step3_4_duration = step3_4_end - step3_4_start
print(f"✅ 热词与空格处理完成。耗时: {step3_4_duration}\n")
# --- 步骤 5: LLM 智能标点 (利用停顿信号) ---
step5_start = datetime.datetime.now()
print(f"🤖 步骤 5: 正在调用 LLM '{llm_model_name}' 进行停顿感知智能标点...")
# <--- 修改:将处理过的 segments 传递给 LLM 函数 ---
final_text = enhance_punctuation_with_llm(processed_segments, llm_model_name)
step5_end = datetime.datetime.now()
step5_duration = step5_end - step5_start
print(f"✅ LLM 标点处理完成。耗时: {step5_duration}")
print(f"📊 最终文本长度: {len(final_text)} 字符\n")
print("✨ LLM 处理后最终文本:")
print("=" * 50)
print(final_text)
print("=" * 50 + "\n")
# --- 步骤 6: 保存文件 (逻辑简化) ---
step6_start = datetime.datetime.now()
print("💾 步骤 6: 正在保存最终文本...")
base_name = os.path.splitext(os.path.basename(media_path))[0]
txt_path = os.path.join(output_dir, f"{base_name}_whisper_final.txt")
save_text_file(final_text, txt_path)
original_txt_path = os.path.join(output_dir, f"{base_name}_whisper_original.txt")
save_text_file(original_text_display, original_txt_path)
print(f"📁 原始文本已保存: {os.path.abspath(original_txt_path)}")
step6_end = datetime.datetime.now()
step6_duration = step6_end - step6_start
print(f"✅ 文件保存完成。耗时: {step6_duration}\n")
# --- 总结统计 ---
total_end_time = datetime.datetime.now()
total_duration = total_end_time - total_start_time
print("🎉 全部流程完成!")
print("=" * 70)
print("⏱️ 各步骤耗时统计:")
print(f" 步骤1 (模型加载): {step1_duration}")
print(f" 步骤2 (音频转录): {step2_duration}")
print(f" 步骤3&4 (预处理): {step3_4_duration}")
print(f" 步骤5 (LLM标点): {step5_duration}")
print(f" 步骤6 (文件保存): {step6_duration}")
print(f" ⏰ 总计耗时: {total_duration}")
print("\n📁 输出文件:")
print(f" 📄 最终文本: {txt_path}")
print(f" 📄 原始文本: {original_txt_path}")
print("=" * 70)
# --- 3. 配置与执行 (代码不变) ---
if __name__ == "__main__":
# ... (您的配置部分完全不变)
REPLACEMENT_MAP = {
"乌班图": "Ubuntu", "吉特哈布": "GitHub", "Moddy Talk": "MultiTalk",
"马克道": "Markdown", "VS 扣德": "VS Code", "派森": "Python",
"甲瓦": "Java", "JavaScript": "JavaScript",
}
WHISPER_MODEL_NAME = "large-v3"
MEDIA_FILE = "../audio/26.mp3"
LANGUAGE = "zh"
LLM_MODEL_NAME = "qwen3:14b"
script_dir = os.path.dirname(os.path.abspath(__file__)) if '__file__' in locals() else '.'
media_path_full = os.path.join(script_dir, MEDIA_FILE)
if not os.path.exists(media_path_full):
print(f"❌ 错误: 音频文件不存在 -> {media_path_full}")
print("请检查 MEDIA_FILE 路径设置。")
else:
run_transcription_pipeline(
model_name=WHISPER_MODEL_NAME,
media_path=media_path_full,
language=LANGUAGE,
replacement_map=REPLACEMENT_MAP,
llm_model_name=LLM_MODEL_NAME
)