文章目录
一、网页解析技术介绍
网页解析技术是爬虫获取数据的核心环节,指从网页的HTML/XML等源代码中提取目标信息(如文本、链接、图片、表格数据等)的过程。
二、Beautiful Soup库
1. Beautiful Soup库介绍
Beautiful Soup 是 Python 中一款功能强大的 HTML/XML 解析库,它能够将复杂的网页源代码转换为结构化的树形文档(Parse Tree),并提供简单直观的 API 供开发者遍历、搜索和提取其中的元素与数据。
其核心优势在于:
- 强大的容错能力:能够处理不规范的 HTML 代码(如标签未闭合、属性缺失、嵌套混乱等),自动修复语法错误,生成可解析的结构,非常适合爬取实际场景中格式混乱的网页。
- 直观的操作方式:支持通过标签名、类名(
class)、ID、属性等多种方式定位元素,语法贴近自然语言,即使是非前端开发背景的开发者也能快速上手。 - 灵活的解析支持:可搭配不同的解析器(如 Python 标准库的
html.parser、lxml、html5lib等),兼顾解析速度、兼容性和功能需求。 - 丰富的功能扩展:提供遍历文档树、搜索文档树、修改文档结构等功能,不仅能提取数据,还能对网页内容进行二次处理。
Beautiful Soup 广泛应用于网络爬虫、数据挖掘、网页内容分析等场景,是 Python 爬虫生态中处理网页解析的核心工具之一。
2. Beautiful Soup库几种解析器比较
Beautiful Soup 本身不直接解析网页,而是依赖第三方解析器完成 HTML/XML 的解析工作。不同解析器在速度、容错性和功能上存在差异,选择合适的解析器能提升解析效率和兼容性。
以下是常用解析器的对比:
| 解析器 | 依赖库 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| html.parser | Python 标准库(内置) | 轻量场景、对解析速度要求不高的情况 | 无需额外安装,兼容性好(支持 Python 2.7+ 和 3.2+) | 解析速度较慢,对复杂不规范 HTML 的容错性一般 |
| lxml (HTML) | lxml 库 |
追求解析速度和容错性的常规 HTML 解析场景 | 解析速度极快,对不规范 HTML 的修复能力强 | 需要额外安装 lxml 库(C 语言编写,安装可能依赖系统环境) |
| lxml (XML) | lxml 库 |
XML 文档解析或需要严格 XML 语法支持的场景 | 支持 XML 特有语法,解析速度快,容错性强 | 需安装 lxml 库,仅适用于 XML 格式文档 |
| html5lib | html5lib 库 |
需完全模拟浏览器解析行为的场景 | 对不规范 HTML 的容错性最强(完全遵循 HTML5 标准) | 解析速度最慢,需要额外安装 html5lib 库 |
3. 安装Beautiful Soup库
Beautiful Soup 库的安装过程简单,支持通过 Python 包管理工具 pip 快速安装,同时需根据需求安装对应的解析器。
3.1 安装 Beautiful Soup 4
Beautiful Soup 目前最新稳定版本为 Beautiful Soup 4(简称 bs4),安装命令如下:
pip install beautifulsoup4 -i https://mirrors.aliyun.com/pypi/simple/
3.2 安装解析器
根据前文的解析器对比,推荐安装 lxml 解析器(兼顾速度和容错性):
pip install lxml -i https://mirrors.aliyun.com/pypi/simple/
若需要 html5lib 解析器(用于极端不规范网页),安装命令如下:
pip install html5lib -i https://mirrors.aliyun.com/pypi/simple/
4. Beautiful Soup使用步骤
使用 Beautiful Soup 解析网页的核心流程为:创建Beautiful Soup对象 --> 获取标签 --> 提取数据。
4.1 创建Beautiful Soup对象
创建Beautiful Soup对象是使用该库解析网页的第一步,通过将网页内容(HTML/XML)和解析器传入BeautifulSoup类,生成一个可操作的树形文档对象。这个对象封装了网页的所有元素和结构,提供了丰富的方法用于遍历、搜索和提取数据。
基本语法:
from bs4 import BeautifulSoup
# 创建Beautiful Soup对象
soup = BeautifulSoup(markup, features, **kwargs)
Beautiful Soup类构造方法的参数说明:
| 参数名 | 类型 | 作用描述 | 必选 | 示例值 |
|---|---|---|---|---|
markup |
字符串/文件对象 | 待解析的HTML/XML内容,可来源于网络响应文本或本地文件内容 | 是 | response.text(网络响应文本)、open("page.html")(本地文件对象) |
features |
字符串 | 指定解析器类型,决定使用哪种解析器处理markup内容 |
是 | "lxml"、"html.parser"、"html5lib" |
builder |
解析器构建器 | 自定义解析器构建器(高级用法,通常无需设置) | 否 | lxml.html.HTMLParser() |
parse_only |
解析过滤器 | 限制只解析指定标签(提升效率),需配合SoupStrainer使用 |
否 | SoupStrainer("div", class_="content")(只解析class为content的div) |
from_encoding |
字符串 | 指定markup的编码格式(自动检测失败时手动指定) |
否 | "utf-8"、"gbk" |
exclude_encodings |
列表 | 排除可能的编码格式(用于优化编码检测) | 否 | ["ISO-8859-1", "windows-1252"] |
element_classes |
字典 | 自定义标签类(高级用法,用于扩展标签功能) | 否 | {"div": MyDivClass, "a": MyATagClass} |
示例:创建Beautiful Soup对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
4.2 获取标签
4.2.1 通过标签名获取
直接通过标签名称(如 title、div、a 等)访问网页中的第一个匹配标签,适用于获取页面中唯一或首个出现的标签。
语法:
tag = soup.标签名 # 获取第一个匹配的标签
示例: 获取title标签
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
title_tag = soup.title
print(title_tag)
打印结果如下图所示:

4.2.2 通过find()方法获取
find() 方法用于在文档树中查找第一个符合条件的标签,支持通过标签名、属性、文本内容等多条件筛选,灵活性远高于直接通过标签名获取。
语法:
tag = soup.find(name, attrs, recursive, string, **kwargs)
参数说明:
| 参数名 | 类型 | 作用描述 | 示例值 |
|---|---|---|---|
name |
字符串/列表 | 指定标签名称,可传入单个标签名或多个标签名的列表(匹配任一标签)。 | name="a"(查找<a>标签)、name=["div", "p"](查找<div>或<p>) |
attrs |
字典 | 通过标签属性筛选,键为属性名,值为属性值(支持正则匹配)。 | attrs={"class": "info"}(查找class为info的标签) |
recursive |
布尔值 | 是否递归查找所有子节点,True(默认)表示搜索所有后代节点,False仅搜索直接子节点。 |
recursive=False(仅查找直接子节点) |
string |
字符串/正则 | 按标签内的文本内容筛选,支持字符串完全匹配或正则表达式匹配。 | string="科幻小说"、string=re.compile(r"小说") |
** kwargs |
关键字参数 | 直接传入属性名作为参数(简化写法,等价于attrs),如class_、id等。 |
class_="rating_nums"(查找class为rating_nums的标签) |
示例: 获取第一个出版社所在的标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
tag = soup.find(name='div', attrs={"class": "pub"})
print(tag)
打印结果如下图所示:

4.2.3 通过find_all()方法获取
find_all() 方法用于在文档树中查找所有符合条件的标签,返回一个包含所有匹配结果的列表,是批量提取数据的核心方法。
语法:
tag_list = soup.find_all(name, attrs, recursive, string, limit, **kwargs)
参数说明:
| 参数名 | 类型 | 作用描述 | 示例值 |
|---|---|---|---|
name |
字符串/列表 | 同 find(),指定标签名称或标签名列表。 |
name="a"(获取所有<a>标签) |
attrs |
字典 | 同 find(),通过属性筛选标签。 |
attrs={"id": "content"}(获取id为content的所有标签) |
recursive |
布尔值 | 同 find(),是否递归查找所有子节点。 |
recursive=True(默认,搜索所有后代节点) |
string |
字符串/正则 | 同 find(),按文本内容筛选,返回包含匹配文本的节点列表。 |
string=re.compile(r"评分")(获取所有含“评分”文本的节点) |
limit |
整数 | 限制返回结果的数量,仅返回前 limit 个匹配标签。 |
limit=5(仅返回前5个匹配结果) |
** kwargs |
关键字参数 | 同 find(),直接传入属性名作为参数(如 class_、id)。 |
class_="title"(获取所有class为title的标签) |
示例: 获取前5个出版社所在的标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
tag = soup.find_all(name='div', attrs={"class": "pub"}, limit=5)
print(tag)
打印结果如下图所示:

4.2.4 CSS选择器介绍
CSS选择器是一种通过标签名、类名、ID、属性等规则定位HTML元素的语法,广泛应用于前端开发和网页解析。Beautiful Soup的select()和select_one()方法支持CSS选择器语法,以下是常用选择器规则:
| 选择器类型 | 语法示例 | 描述说明 |
|---|---|---|
| 标签选择器 | div |
匹配所有<div>标签 |
| 类选择器 | .info |
匹配所有class="info"的标签 |
| ID选择器 | #content |
匹配id="content"的标签(ID唯一) |
| 属性选择器 | a[href] |
匹配所有包含href属性的<a>标签 |
| 属性值选择器 | a[href="https://example.com"] |
匹配href属性值为指定URL的<a>标签 |
| 属性包含选择器 | a[href*="book"] |
匹配href属性值包含"book"的<a>标签 |
| 层级选择器 | div.info h2 |
匹配class="info"的<div>下的所有<h2>标签 |
| 直接子元素选择器 | div > p |
匹配<div>的直接子元素<p>(不包含嵌套子元素) |
| 相邻兄弟选择器 | h2 + p |
匹配<h2>后面紧邻的第一个<p>标签 |
| 伪类选择器 | li:nth-child(2) |
匹配父元素中第2个<li>子元素 |
4.2.5 通过select_one()方法获取
select_one()方法通过CSS选择器语法查找第一个符合条件的标签,返回单个标签对象(而非列表),适用于获取唯一或首个匹配的元素。
语法:
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
tag = soup.select_one(selector='div .info > .pub')
print(tag)
参数说明:
| 参数名 | 类型 | 作用描述 | 示例值 |
|---|---|---|---|
selector |
字符串 | CSS选择器规则,支持上述所有选择器语法。 | div.info h2 a(匹配class为info的div下的h2内的a标签) |
namespaces |
字典 | 命名空间映射(用于XML文档解析,HTML解析中通常无需设置)。 | {"html": "http://www.w3.org/1999/xhtml"} |
** kwargs |
关键字参数 | 传递给解析器的额外参数(高级用法,一般无需设置)。 | - |
示例: 获取第一个出版社所在的标签。
tag = soup.find(name='div', attrs={"class": "pub"})
print(tag)
打印结果如下图所示:
4.2.6 通过select()方法获取
select()方法通过CSS选择器语法查找所有符合条件的标签,返回包含所有匹配结果的列表,是批量提取数据的常用方法。
语法:
tag_list = soup.select(selector, namespaces=None, limit=None,** kwargs)
参数说明:
| 参数名 | 类型 | 作用描述 | 示例值 |
|---|---|---|---|
selector |
字符串 | 同select_one(),CSS选择器规则。 |
span.rating_nums(匹配class为rating_nums的span标签) |
namespaces |
字典 | 同select_one(),命名空间映射(HTML解析中通常无需设置)。 |
- |
limit |
整数 | 限制返回结果数量,仅返回前limit个匹配标签(默认返回所有)。 |
limit=3(仅返回前3个匹配结果) |
**kwargs |
关键字参数 | 传递给解析器的额外参数(一般无需设置)。 | - |
示例: 获取前5个出版社所在的标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
tag = soup.select(selector='div .info > .pub', limit=5)
print(tag)
打印结果如下图所示:
4.3 提取数据
获取标签后,下一步是从标签中提取所需数据,主要包括标签间的文本内容和标签的属性值(如链接、图片地址等)。
4.3.1 获取标签间的内容
标签间的内容通常是网页中显示的文本(如标题、描述、评分等),Beautiful Soup 提供了多种属性用于获取不同格式的文本内容,适用于不同场景:
| 属性名 | 描述说明 | 示例代码 | 示例结果(假设标签为<p>hello <b>world</b></p>) |
|---|---|---|---|
text |
返回标签内所有文本的拼接字符串,自动忽略标签嵌套结构,仅保留文本内容。 | tag.text |
hello world |
string |
仅当标签内只有纯文本(无嵌套标签)时返回文本,否则返回None。 |
tag.string |
None(因存在<b>嵌套标签) |
strings |
返回一个生成器,包含标签内所有文本片段(包括嵌套标签中的文本),保留分隔符。 | list(tag.strings) |
['hello ', 'world'] |
stripped_strings |
类似strings,但会自动去除每个文本片段的首尾空白字符,并过滤空字符串。 |
list(tag.stripped_strings) |
['hello', 'world'] |
示例:提取标签中的内容
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
# 使用 CSS 选择器查找第一个 class="subject-item" 的标签(通常是一个 <li> 或 <div>)
# soup.select_one() 返回匹配的第一个 Tag 对象,如果没有匹配则返回 None
li_tag = soup.select_one('.subject-item')
# 打印该标签及其所有子标签中的**全部文本内容**
# .text 属性会递归获取标签内所有字符串,并自动用空格连接
# 注意:可能包含多个空格、换行或制表符等空白字符
print(li_tag.text)
# 遍历 li_tag 下的所有**直接和嵌套的字符串内容**(包括空白字符)
# .strings 是一个生成器,返回所有文本节点(包含空白、换行等)
# 输出时会看到原始的缩进、换行等格式
for string in li_tag.strings:
print(string)
# 遍历 li_tag 下的所有**去除了首尾空白的非空字符串**
# .stripped_strings 是一个生成器,功能类似 .strings
# 但会对每个字符串调用 .strip(),去除两端空白,并跳过空字符串
# 更适合提取“干净”的文本内容
for string in li_tag.stripped_strings:
print(string)
# 使用更精确的 CSS 选择器查找书籍出版信息
# 选择路径:div 下 class="info" 的元素 > 其直接子元素 class="pub"
# 通常用于匹配图书的“作者 / 出版社 / 出版年份”等信息
tag = soup.select_one(selector='div .info > .pub')
# 获取该标签的**直接文本内容**(不包括子标签的文本)
# .string 表示标签的直接内容(如果标签只有一个子字符串)
# .strip() 去除字符串首尾的空白、换行等字符
# 最终得到干净的出版信息文本
print(tag.string.strip())
4.3.2 获取标签属性的值
HTML标签通常包含属性(如<a href="url">中的href、<img src="path">中的src),这些属性值是提取链接、图片地址、类名等信息的关键。
直接通过属性名访问
语法:tag["属性名"]
适用场景:获取已知存在的属性(如href、src、class等)。
示例:获取小说名称的链接
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
a_tag = soup.select_one(".subject-item .info a")
link = a_tag["href"]
print( link)
使用get()方法
语法:tag.get(属性名, 默认值)
适用场景:属性可能不存在时,避免报错(不存在则返回None或指定的默认值)。
示例:获取小说名称的链接
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
a_tag = soup.select_one(".subject-item .info a")
link = a_tag.get('href')
print( link)
打印结果如下所示:
https://book.douban.com/subject/36104107/
获取所有属性
语法:tag.attrs
适用场景:获取标签的所有属性及值(返回字典)。
示例:获取小说名称所在a标签的所有属性
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup=open(file='./豆瓣读书/小说/0.html', mode='r', encoding='utf-8'), features='lxml')
a_tag = soup.select_one(".subject-item .info a")
attrs = a_tag.attrs
print(attrs)
{'href': 'https://book.douban.com/subject/36104107/', 'title': '长安的荔枝', 'onclick': "moreurl(this,{i:'0',query:'',subject_id:'36104107',from:'book_subject_search'})"}
三、实战:解析豆瓣读书中小说的网页
1. 提取网页数据
代码如下所示:
# 导入 BeautifulSoup 用于解析 HTML 内容
from bs4 import BeautifulSoup
# 导入 Path 用于跨平台安全地操作文件和目录路径
from pathlib import Path
# 定义 HTML 文件所在的根目录
file_dir = Path('./豆瓣读书')
# 使用 rglob 递归查找目录中所有以 .html 结尾的文件(包括子目录)
# 例如:./豆瓣读书/page1.html, ./豆瓣读书/2023/page2.html 等
html_files = file_dir.rglob('*.html')
# 遍历每一个找到的 HTML 文件路径
for file_path in html_files:
# 确保当前路径是一个文件(而非目录)
if file_path.is_file():
# 使用 open() 打开文件,指定编码为 utf-8(防止中文乱码)
# 将文件内容传递给 BeautifulSoup,使用 'lxml' 作为解析器(速度快、容错性好)
soup = BeautifulSoup(
markup=open(file=file_path, mode='r', encoding='utf-8'),
features='lxml'
)
# 使用 CSS 选择器查找页面中所有 class="subject-item" 的元素
# 每个 subject-item 通常代表一本书的信息(如书名、作者、评分等)
subject_items = soup.select('.subject-item')
# 遍历每一本书的信息条目
for subject_item in subject_items:
# 获取书籍链接:查找 .info 下的第一个 <a> 标签,提取其 href 属性
href = subject_item.select_one('.info a').get('href')
# 获取书籍标题:同上,提取 <a> 标签的 title 属性(鼠标悬停时显示的完整书名)
title = subject_item.select_one('.info a').get('title')
# 获取出版信息:查找 .info 下 class="pub" 的元素,获取其文本内容并去除首尾空白
pub = subject_item.select_one('.info .pub').string.strip()
# 获取评分:查找 class="rating_nums" 的元素(可能是评分 8.5、9.0 等)
rating = subject_item.select_one('.info .rating_nums')
# 安全提取评分文本:如果元素存在且有字符串内容,则去空白;否则设为空字符串
rating = rating.string.strip() if rating and rating.string else ''
# 获取评分人数:查找 class="pl" 的元素(如 "(2048人评价)")
rating_num = subject_item.select_one('.info .pl').string.strip()
# 获取书籍简介(摘要):查找 .info 的直接子元素 <p>(通常为书籍简介)
plot = subject_item.select_one('.info > p')
# 安全提取简介文本
plot = plot.string.strip() if plot and plot.string else ''
# 查找纸质书购买链接:在 .info 下 class="buy-info" 中的 <a> 标签
paper_tag = subject_item.select_one('.info .buy-info > a')
# 判断是否找到购买链接标签
if paper_tag:
# 提取购买链接的 href(跳转地址)
buylinks = paper_tag.get('href')
# 提取链接上的文字(通常是价格,如 "¥39.5")
paper_price = paper_tag.string.strip()
else:
# 如果没有找到购买信息,则设为空
buylinks = ''
paper_price = ''
# 输出提取的关键信息(可根据需要保存到 CSV/数据库等)
print(href, title, pub, rating_num, paper_price, buylinks)
部分打印结果如下图所示:

2. 保存数据到csv文件
代码如下所示:
# 导入 BeautifulSoup 用于解析 HTML 内容
# 导入 Path 用于跨平台安全地操作文件和目录路径
from pathlib import Path
import pandas as pd
from bs4 import BeautifulSoup
# 定义 HTML 文件所在的根目录
file_dir = Path('./豆瓣读书')
# 使用 rglob 递归查找目录中所有以 .html 结尾的文件(包括子目录)
# 例如:./豆瓣读书/page1.html, ./豆瓣读书/2023/page2.html 等
html_files = file_dir.rglob('*.html')
# 用于存储所有书籍信息的列表(每本书是一个字典)
books = []
# 遍历每一个找到的 HTML 文件路径
for file_path in html_files:
# 确保当前路径是一个文件(而非目录)
if file_path.is_file():
# 使用 open() 打开文件,指定编码为 utf-8(防止中文乱码)
# 将文件内容传递给 BeautifulSoup,使用 'lxml' 作为解析器(速度快、容错性好)
soup = BeautifulSoup(
markup=open(file=file_path, mode='r', encoding='utf-8'),
features='lxml'
)
# 使用 CSS 选择器查找页面中所有 class="subject-item" 的元素
# 每个 subject-item 通常代表一本书的信息(如书名、作者、评分等)
subject_items = soup.select('.subject-item')
# 遍历每一本书的信息条目
for subject_item in subject_items:
# 获取书籍链接:查找 .info 下的第一个 <a> 标签,提取其 href 属性
href = subject_item.select_one('.info a').get('href')
# 获取书籍标题:同上,提取 <a> 标签的 title 属性(鼠标悬停时显示的完整书名)
title = subject_item.select_one('.info a').get('title')
# 获取出版信息:查找 .info 下 class="pub" 的元素,获取其文本内容并去除首尾空白
pub = subject_item.select_one('.info .pub').string.strip()
# 获取评分:查找 class="rating_nums" 的元素(可能是评分 8.5、9.0 等)
rating = subject_item.select_one('.info .rating_nums')
# 安全提取评分文本:如果元素存在且有字符串内容,则去空白;否则设为空字符串
rating = rating.string.strip() if rating and rating.string else ''
# 获取评分人数:查找 class="pl" 的元素(如 "(2048人评价)")
rating_num = subject_item.select_one('.info .pl').string.strip()
# 获取书籍简介(摘要):查找 .info 的直接子元素 <p>(通常为书籍简介)
plot = subject_item.select_one('.info > p')
# 安全提取简介文本
plot = plot.string.strip() if plot and plot.string else ''
# 查找纸质书购买链接:在 .info 下 class="buy-info" 中的 <a> 标签
paper_tag = subject_item.select_one('.info .buy-info > a')
# 判断是否找到购买链接标签
if paper_tag:
# 提取购买链接的 href(跳转地址)
buylinks = paper_tag.get('href')
# 提取链接上的文字(通常是价格,如 "¥39.5")
paper_price = paper_tag.string.strip()
else:
# 如果没有找到购买信息,则设为空
buylinks = ''
paper_price = ''
# 输出提取的关键信息(可根据需要保存到 CSV/数据库等)
# print(href, title, pub, rating_num, paper_price, buylinks)
# 将这本书的信息存为字典,加入列表
books.append({
'href': href,
'title': title,
'pub': pub,
'rating': rating,
'rating_num': rating_num,
'plot': plot,
'buylinks': buylinks,
'paper_price': paper_price
})
# 转换为 DataFrame
books_df = pd.DataFrame(books)
# 创建保存目录(如果不存在)
Path('./data').mkdir(parents=True, exist_ok=True)
# 保存为 CSV 文件
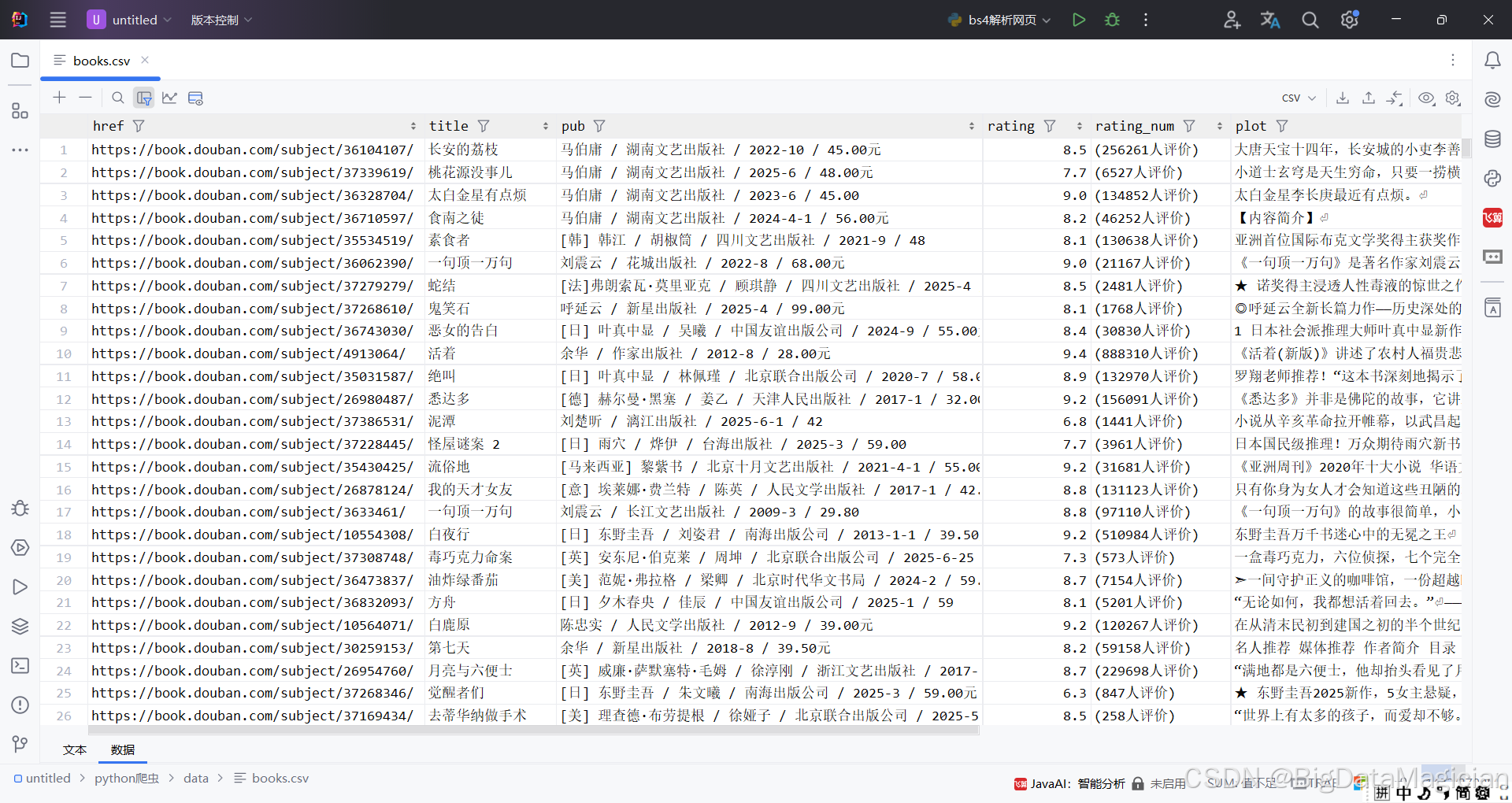
books_df.to_csv('./data/books.csv', index=False, encoding='utf-8-sig')
print(f"图书数据已保存到:'./data/books.csv'")
保存后的部分数据如下图所示: