目录
java1.7 -- java1.8 HashMap 做了哪些优化:
1.Java 1.7 ConcurrentHashMap架构:
2.Java 1.8 ConcurrentHashMap架构:
一.HashMap
1.基本概念
HashMap是基于哈希表实现的Map接口,用于存储键值对(K-V)格式,其核心作用就是通过哈希函数为了更快查询到某个元素,时间复杂度O(1);
2.底层数据结构:
在java(1.7)之前 底层是采用“数组 + 链表” 的形式存储
但在java(1.8) 之后,变成了“数组 + 链表 + 红黑树 ”形式存储
我们主要了解java1.8之后的内容;
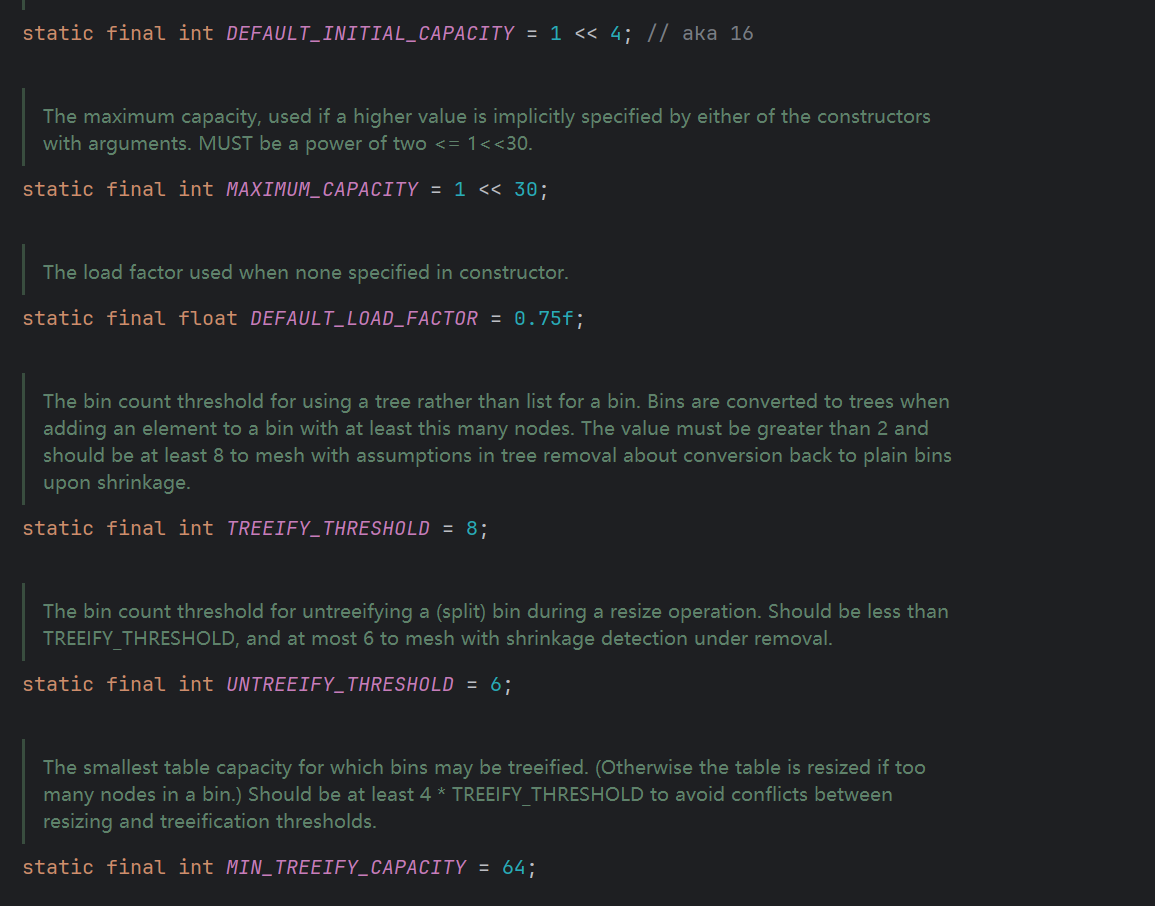
从源码上查看
数组的初始容量为16,负载因子为0.75,所以当超过这个阈值 16 * 0.75 = 12
设计初始容量为16核心原因是2 的幂次方更适合哈希计算,能减少哈希冲突,但8又太频繁扩容,新增性能开销,而32空间又会太大,则浪费空间~
负载因子也是同理,太小,会频繁扩容,虽然查询快了,但是数组太稀疏,浪费空间,而太大,就会扩容少,空间利用率高,但查询会变慢~
当插入第13个元素的时候,已经超过阈值,为了避免哈希冲突,会进行扩容~
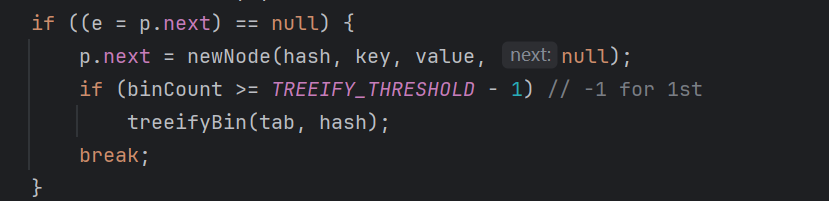
然后这边当数组大小超过64时候,链表大小超过8的时候,会从链表进化成红黑树,但当元素个数少于6个时,会退回链表~
链表长度≥8
基于泊松分布,当负载因子为 0.75 时,链表长度自然增长到 8 的概率极低(约千万分之一),此时说明哈希冲突异常频繁,需要转为红黑树优化。数组容量≥64
若数组容量小于 64(如 32),即使链表长度≥8,也会先触发扩容(而非转红黑树)。原因是:数组容量小时,扩容成本低,通过扩容可分散元素,减少冲突;而红黑树的维护成本(插入 / 删除时的旋转操作)高于扩容,此时扩容更高效。
3.HashCode和equals方法
HashMap中的键一定会实现这俩个方法,hashCode用于计算存储的位置,而equals用于判断来个键是否相同,在put方法的时候,如果俩个哈希值相同,会判断是否是同一个值,如果不是就会放在同一个桶中的不同位置,如果相同就是一个东西~
为什么重写HashCode方法?
如果不重写,这个时候,就会导致俩个相同的key,会被计算出俩个不同的哈希值,导致他们存在在不同的桶中,到时候查询的时候到底是查哪个?
为什么重新equals方法?
equals方法是为了当出现哈希冲突的时候,俩个key的哈希值相同,放在同一桶中,但没有比较它们的对象,可能会误判会导致俩个key存储在不同位置,所以没有覆盖之前的值,就会错误~
class Person {
String name;
int age;
@Override
public int hashCode() { // 重写hashCode,保证逻辑相等的对象哈希值相同
return Objects.hash(name, age);
}
// 未重写equals()
}
public static void main(String[] args) {
HashMap<Person, String> map = new HashMap<>();
Person p1 = new Person("张三", 20);
Person p2 = new Person("张三", 20);
map.put(p1, "学生");
map.put(p2, "工人"); // 哈希值相同,进入同一个桶,但equals判断为不同key
System.out.println(map.size()); // 仍输出2,而非预期的1
}hashCode()和equals()必须配套重写,且满足以下规则:
- 一致性:如果两个对象通过
equals()判断为相等,则它们的hashCode()必须返回相同的值; - 对称性:如果
a.equals(b)为true,则b.equals(a)也必须为true; - 非空性:
a.equals(null)必须返回false。
4.put操作
1.初始化和数组检查

首先判断 HashMap 是否未初始化(table 数组为 null 或长度为 0),若是则触发 初始化(resize):
2.计算索引并检查桶是否为空

如果该位置为空,直接创建新节点插入
3.桶不为null,处理哈希冲突
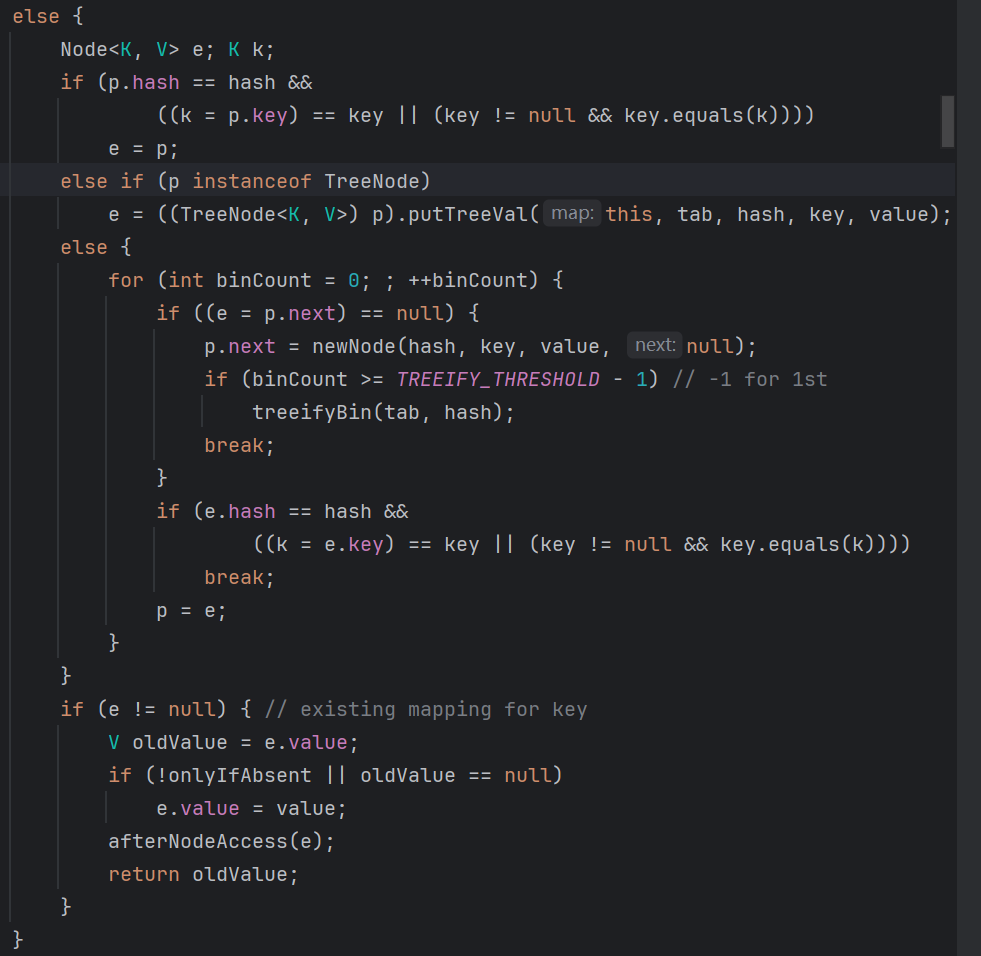
- 检查首节点:若首节点的 key 与传入 key equals 相等(且哈希值相同),则视为 “重复 key”,记录该节点(后续替换其 value)。
- 遍历后续节点:
- 若桶是单链表(
Node):遍历链表,若找到 key 相等的节点,记录该节点;若遍历到链表尾部仍未找到,则在链尾插入新节点(Node)。 - 若桶是红黑树(
TreeNode):调用红黑树的插入方法(putTreeVal),若找到重复 key 则记录节点,否则插入新树节点。
- 若桶是单链表(
- 处理重复 key:若步骤 1 或 2 中找到重复 key 的节点,用新 value 替换其旧 value,流程结束。
4.判断链表是否转化红黑树
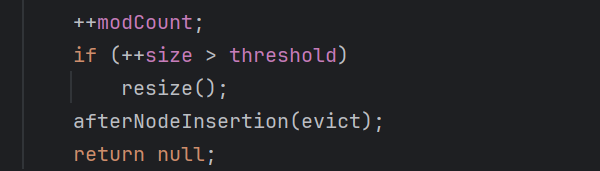
5.以及数组大小是否超过阈值进行扩容
5.get操作
同理get 方法的核心逻辑是:
哈希计算→定位桶→根据桶结构(链表 / 红黑树)查找匹配节点
java1.7 -- java1.8 HashMap 做了哪些优化:
哈希值计算:
1.7版本:对 key 的原始哈希值(hashCode() 结果)进行 4 次扰动(多次移位和异或运算)

1.8版本:简化为 1 次扰动,仅通过一次 “高 16 位与低 16 位异或” 实现混合

减少计算开销:一次异或运算即可达到近似的混合效果,相比 1.7 的 4 次运算,计算效率更高。
实际效果:在大多数场景下,1 次扰动已能保证哈希值的均匀分布,同时降低了 CPU 运算成本。
链表插入方式:
由头插变成尾插,核心是为了解决多线程扩容时的链表环化问题,同时让链表操作逻辑更合理。
多线程扩容时可能导致链表环化(死循环)。
扩容过程中,节点会从旧数组迁移到新数组,头插法在迁移时会反转链表顺序(例如旧链表 A→B,迁移后新链表变为 B→A)。若此时有多个线程同时操作,可能出现节点引用相互指向的情况(如 A.next = B 且 B.next = A),形成环形链表。后续查询时,线程会陷入无限循环,导致 CPU 占用飙升。
二.ConcurrentHashMap
ConcurrentHashMap 是 Java 中用于并发场景的哈希表实现,专为高并发环境设计;
1.Java 1.7 ConcurrentHashMap架构:
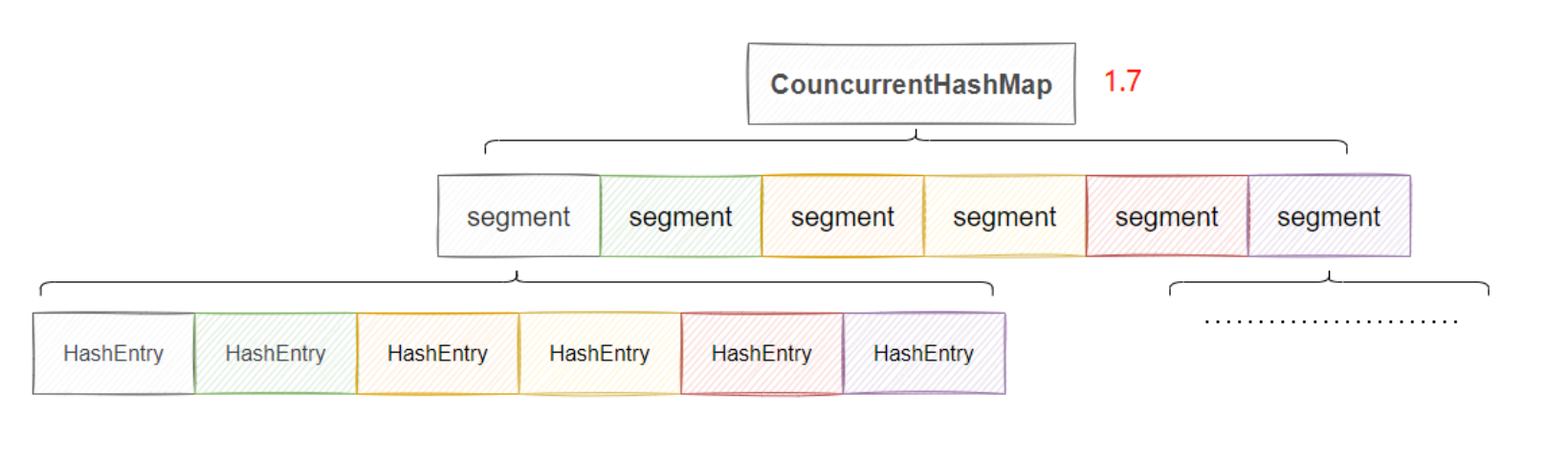
在java1.8之前 ConcurrentHashMap 采用的是 分段数组(Segment)+ 哈希表 , 默认为16个segment,同时支持16个并发~
- 整体结构:
ConcurrentHashMap -> Segment[] -> HashEntry[] -> 链表。
- 写操作(put/remove 等):
- 计算 key 的哈希值,定位到对应的
Segment; - 获取该
Segment的锁(若被占用则阻塞); - 在
Segment内部的哈希表中执行插入 / 删除(类似 HashMap 的逻辑,链表头插法); - 释放锁。
- 计算 key 的哈希值,定位到对应的
- 优点:通过分段锁实现了多线程并发写,效率比全表锁(如 Hashtable)高得多。
- 缺点:
- 锁粒度仍较大(以
Segment为单位),若多个线程操作同一Segment,仍会阻塞; - 结构复杂,维护成本高;
- 扩容仅针对单个
Segment,但整体性能受限于Segment数量。
- 锁粒度仍较大(以
2.Java 1.8 ConcurrentHashMap架构:
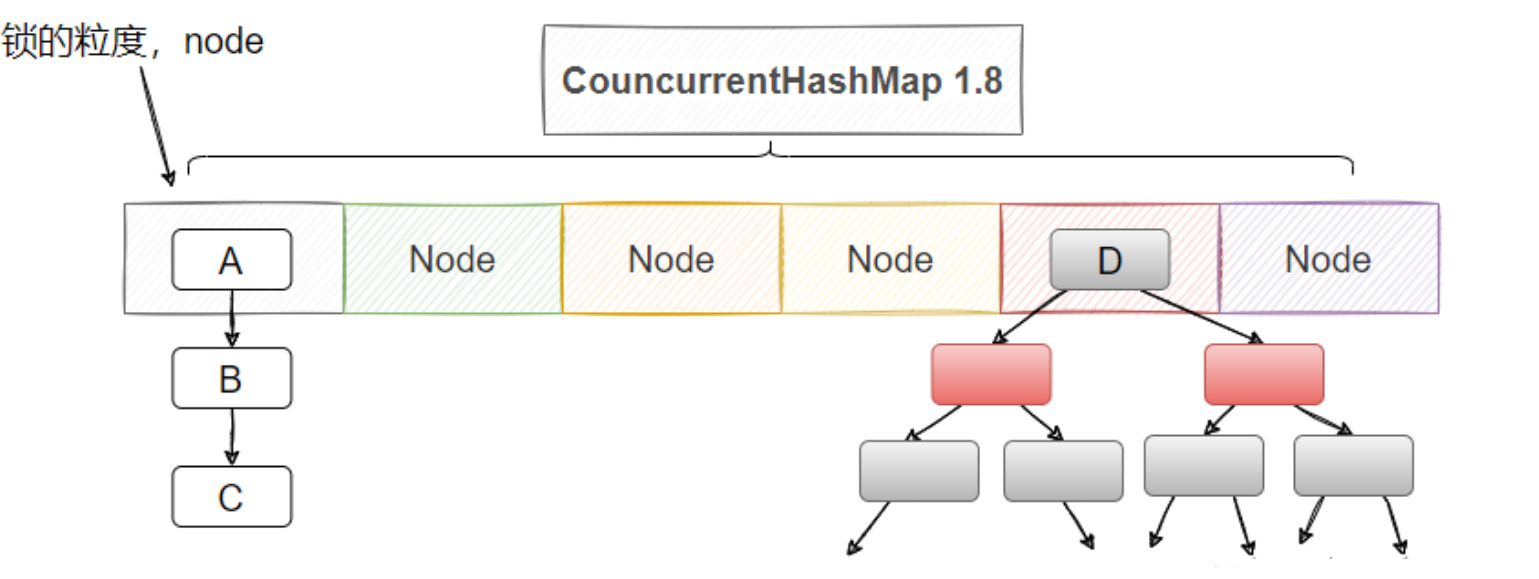
摒弃了 Segment 分段结构,底层直接使用 数组 + 链表 + 红黑树(与 JDK 1.8 HashMap 结构类似)
锁的粒度更小,锁的是桶的头节点,并且采取了CAS + synchronized 机制,仅当多个线程操作同一链表 / 红黑树时才会竞争锁,锁冲突概率远低于 1.7 的 Segment 级锁。
CAS+synchronized的使用场景:
- 无冲突场景(空桶插入、初始化、低并发计数):用 CAS 实现高效无锁操作。
- 有冲突场景(非空桶操作、复杂结构修改):用 synchronized 加锁保证原子性。
| 版本 | 底层架构 | 哈希表数量 | 锁粒度 |
|---|---|---|---|
| JDK 1.7 及之前 | 两层结构:Segment [] 数组 + 每个 Segment 包含一个 HashEntry [] 数组 | 多个(默认 16 个,与 Segment 数量一致) | Segment 级(锁整个子哈希表) |
| JDK 1.8 及之后 | 单层结构:Node [] 数组(链表 / 红黑树解决冲突) | 1 个(整个 ConcurrentHashMap 共用一个底层数组) | 节点级(锁链表头节点或红黑树根节点) |
扩容区别:
| 特性 | JDK 1.7 扩容 | JDK 1.8 扩容 |
|---|---|---|
| 扩容范围 | 单个 Segment 独立扩容 | 整个数组全表扩容 |
| 并发能力 | 单线程扩容(当前操作 Segment 的线程) | 多线程协同扩容(所有线程可协助迁移) |
| 锁影响范围 | 仅锁定当前 Segment,其他 Segment 可用 | 无全局锁,仅锁定迁移中的桶节点 |
| 迁移效率 | 单个 Segment 迁移,效率较低 | 多线程分片迁移,效率更高 |
| 节点迁移方式 | 头插法(可能反转链表) | 尾插法(保持链表顺序,无环化风险) |
| 与读写的兼容性 | 扩容时该 Segment 读写阻塞 | 扩容与读写可并行(读无锁,写锁单个桶) |
size()区别:
在JDK 1.7 中,ConcurrentHashMap 由多个 Segment 组成,每个 Segment 独立维护自己的元素数量(count),因此计算总 size 时需要累加所有 Segment 的 count。
- 为减少误差,JDK 1.7 采用 “重试机制”:如果两次连续累加的结果一致,则认为是准确值;若不一致(说明期间有并发修改),最多重试 3 次,若仍不一致则直接返回当前累加值(接受一定误差)。
而在JDK 1.8中,计算 size 依赖于 baseCount 原子变量和 counterCells 辅助数组,通过无锁累加实现,返回两者的总和作为最终的 size。
当插入元素成功后,需要将总数 +1,流程如下:
优先尝试更新
baseCount:
线程通过 CAS 操作直接更新baseCount(baseCount + 1)。- 若 CAS 成功:计数完成,无需其他操作。
- 若 CAS 失败:说明存在并发竞争(多个线程同时更新
baseCount),进入下一步。
竞争激烈时,使用
counterCells分散计数:- 若
counterCells未初始化,先通过 CAS 初始化(创建一个CounterCell数组)。 - 线程通过哈希算法(基于线程 ID 或随机数)随机选择
counterCells中的一个CounterCell。 - 尝试用 CAS 更新该
CounterCell的value(value + 1):- 若成功:计数完成。
- 若失败:重试或选择其他
CounterCell(避免死锁)。
- 若
| 特性 | JDK 1.7 计数方式 | JDK 1.8 计数方式 |
|---|---|---|
| 底层依赖 | 各 Segment 的 count 累加 |
baseCount + counterCells 累加 |
| 并发处理 | 重试机制减少误差,返回近似值 | CAS 原子操作,返回接近精确值 |
| 性能 | 低并发时高效,依赖 Segment 数量 | 高低并发均高效,通过分散竞争优化 |
| 实现复杂度 | 简单(遍历 + 重试) | 复杂(原子变量 + 辅助数组 + 竞争分散) |
| 适用场景 | 分段锁架构下的近似计数 | 全局数组架构下的高效精确计数 |