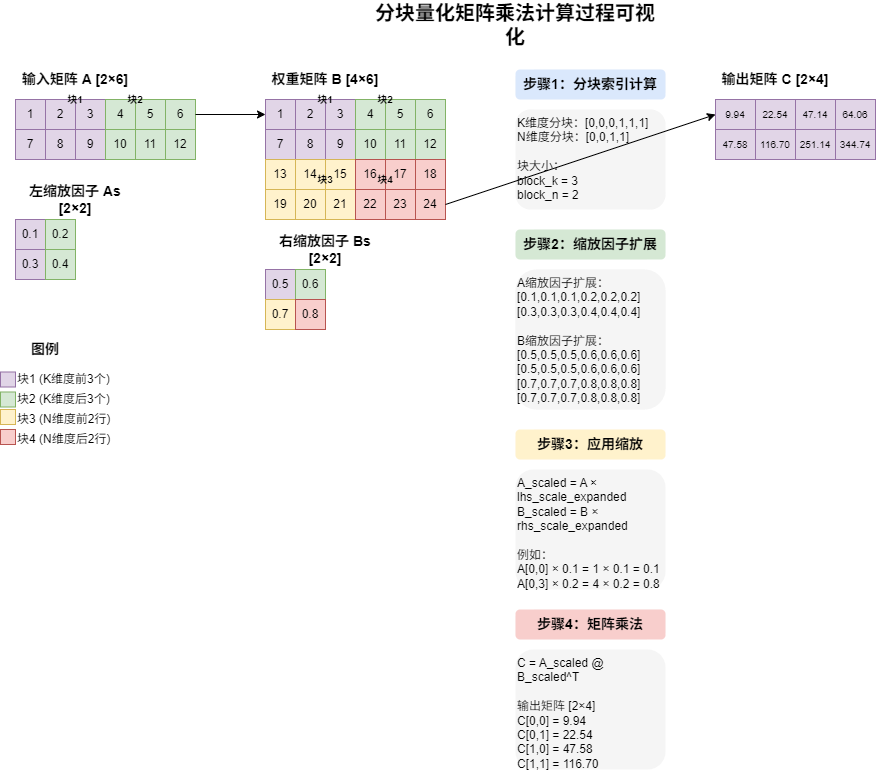
from vllm.triton_utils import tl, triton
from vllm.platforms import current_platform
from vllm.logger import init_logger
import torch
import os
import functools
from typing import Any, Callable, Optional, Union
logger = init_logger(__name__)@functools.lru_cachedefget_w8a8_block_fp8_configs(N:int, K:int, block_n:int,
block_k:int)-> Optional[dict[int, Any]]:"""
Return optimized configurations for the w8a8 block fp8 kernel.
The return value will be a dictionary that maps an irregular grid of
batch sizes to configurations of the w8a8 block fp8 kernel. To evaluate the
kernel on a given batch size bs, the closest batch size in the grid should
be picked and the associated configuration chosen to invoke the kernel.
"""# First look up if an optimized configuration is available in the configs# directory
device_name = current_platform.get_device_name().replace(" ","_")
json_file_name =f"N={N},K={K},device_name={device_name},dtype=fp8_w8a8,block_shape=[{block_n},{block_k}].json"# noqa: E501
config_file_path = os.path.join(
os.path.dirname(os.path.realpath(__file__)),"configs", json_file_name)if os.path.exists(config_file_path):withopen(config_file_path)as f:
logger.info("Using configuration from %s for W8A8 Block FP8 kernel.",
config_file_path,)# If a configuration has been found, return itreturn{int(key): val for key, val in json.load(f).items()}# If no optimized configuration is available, we will use the default# configuration
logger.warning("Using default W8A8 Block FP8 kernel config. Performance might ""be sub-optimal! Config file not found at %s",
config_file_path,)returnNonedefw8a8_block_fp8_matmul(
A: torch.Tensor,
B: torch.Tensor,
As: torch.Tensor,
Bs: torch.Tensor,
dot_dtype =None,
block_size:list[int]=[128,128],
output_dtype: torch.dtype = torch.bfloat16,)-> torch.Tensor:"""This function performs matrix multiplication with block-wise
quantization.
It takes two input tensors `A` and `B` with scales `As` and `Bs`.
The output is returned in the specified `output_dtype`.
Args:
A: The input tensor, e.g., activation.
B: The input tensor, e.g., weight.
As: The per-token-group quantization scale for `A`.
Bs: The per-block quantization scale for `B`.
block_size: The block size for per-block quantization. It should
be 2-dim, e.g., [128, 128].
output_dytpe: The dtype of the returned tensor.
Returns:
torch.Tensor: The result of matmul.
"""ifisinstance(dot_dtype,int)and dot_dtype ==1:
dot_dtype = tl.bfloat16
assertlen(block_size)==2
block_n, block_k = block_size[0], block_size[1]assert A.shape[-1]== B.shape[-1]assert A.shape[:-1]== As.shape[:-1]and A.is_contiguous()assert triton.cdiv(A.shape[-1], block_k)== As.shape[-1]
M = A.numel()// A.shape[-1]assert B.ndim ==2and Bs.ndim ==2
N, K = B.shape
assert triton.cdiv(N, block_n)== Bs.shape[0]assert triton.cdiv(K, block_k)== Bs.shape[1]
C_shape = A.shape[:-1]+(N,)
C = A.new_empty(C_shape, dtype=output_dtype)
configs = get_w8a8_block_fp8_configs(N, K, block_size[0], block_size[1])if configs:# Get the optimal config if there is one
config = configs[min(configs.keys(), key=lambda x:abs(x - M))]else:# Default config# Block-wise quant: BLOCK_SIZE_N must be divisible by block_size[0]# BLOCK_SIZE_K must be divisible by block_size[1]
config ={"BLOCK_SIZE_M":64,"BLOCK_SIZE_N": block_size[0],"BLOCK_SIZE_K": block_size[1],"GROUP_SIZE_M":32,"num_warps":4,"num_stages":2,}defgrid(META):return(triton.cdiv(M, META["BLOCK_SIZE_M"])*
triton.cdiv(N, META["BLOCK_SIZE_N"]),)
_w8a8_block_fp8_matmul[grid](
A,
B,
C,
As,
Bs,
M,
N,
K,
block_n,
block_k,# dot_dtype,
A.stride(-2),
A.stride(-1),
B.stride(1),
B.stride(0),
C.stride(-2),
C.stride(-1),
As.stride(-2),
As.stride(-1),
Bs.stride(1),
Bs.stride(0),**config,)return C
defget_default_config(
M:int,
E:int,
N:int,
K:int,
topk:int,
dtype: Optional[str],
is_marlin:bool,
block_shape: Optional[list[int]]=None,)->dict[str,int]:if dtype =="fp8_w8a8"and block_shape isnotNone:# Block-wise quant: BLOCK_SIZE_N must be divisible by block_shape[0]# BLOCK_SIZE_K must be divisible by block_shape[1]# num_stages=3 can cause triton.runtime.errors.OutOfResources# on ROCm, set it to 2 instead.
config ={"BLOCK_SIZE_M":64,"BLOCK_SIZE_N": block_shape[0],"BLOCK_SIZE_K": block_shape[1],"GROUP_SIZE_M":32,"num_warps":4,# "num_stages": 3 if not current_platform.is_rocm() else 2,"num_stages":2}elif dtype in["int4_w4a16","int8_w8a16"]and block_shape isnotNone:# moe wna16 kernels# only set BLOCK_SIZE_M# BLOCK_SIZE_N and BLOCK_SIZE_K would be set later
bit =4if dtype =="int4_w4a16"else8
use_moe_wna16_cuda = should_moe_wna16_use_cuda(M * topk,
block_shape[1], E, bit)if use_moe_wna16_cuda:
config ={"BLOCK_SIZE_M":min(16, M)}elif M <=20:
config ={"BLOCK_SIZE_M":16,"GROUP_SIZE_M":1}elif M <=40:
config ={"BLOCK_SIZE_M":32,"GROUP_SIZE_M":1}else:
config ={"BLOCK_SIZE_M":64,"GROUP_SIZE_M":1}elif is_marlin:for block_size_m in[8,16,32,48,64]:if M * topk / E / block_size_m <0.9:breakreturn{"BLOCK_SIZE_M": block_size_m}elif M <= E:
config ={"BLOCK_SIZE_M":16,"BLOCK_SIZE_N":32,"BLOCK_SIZE_K":64,"GROUP_SIZE_M":1,}else:
config ={"BLOCK_SIZE_M":64,"BLOCK_SIZE_N":64,"BLOCK_SIZE_K":32,"GROUP_SIZE_M":8,}return config
deftry_get_optimal_moe_config(
w1_shape:tuple[int,...],
w2_shape:tuple[int,...],
top_k:int,
dtype: Optional[str],
M:int,
is_marlin:bool=False,
block_shape: Optional[list[int]]=None,)->dict[str,int]:from vllm.model_executor.layers.fused_moe import get_config
override_config = get_config()if override_config:
config = override_config
else:# First try to load optimal config from the file
E, _, N = w2_shape
if dtype =="int4_w4a16":
N = N *2
block_n = block_shape[0]if block_shape else0
block_k = block_shape[1]if block_shape else0# Else use the default config
config = get_default_config(M, E, N, w1_shape[2], top_k, dtype,
is_marlin, block_shape)return config
@triton.jitdef_w8a8_block_fp8_matmul(# Pointers to inputs and output
A,
B,
C,
As,
Bs,# Shape for matmul
M,
N,
K,# Block size for block-wise quantization
group_n,
group_k,# dot_dtype,# Stride for inputs and output
stride_am,
stride_ak,
stride_bk,
stride_bn,
stride_cm,
stride_cn,
stride_As_m,
stride_As_k,
stride_Bs_k,
stride_Bs_n,# Meta-parameters
BLOCK_SIZE_M: tl.constexpr,
BLOCK_SIZE_N: tl.constexpr,
BLOCK_SIZE_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr,):"""Triton-accelerated function used to perform linear operations (dot
product) on input tensors `A` and `B` with block-wise quantization, and
store the result in output tensor `C`.
"""# dot_dtype = tl.bfloat16
dot_dtype =None
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m =min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m +(pid % group_size_m)
pid_n =(pid % num_pid_in_group)// group_size_m
offs_am =(pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M))% M
offs_bn =(pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N))% N
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = A +(offs_am[:,None]* stride_am + offs_k[None,:]* stride_ak)
b_ptrs = B +(offs_k[:,None]* stride_bk + offs_bn[None,:]* stride_bn)
As_ptrs = As + offs_am * stride_As_m
offs_bsn = offs_bn // group_n
Bs_ptrs = Bs + offs_bsn * stride_Bs_n
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)for k inrange(0, tl.cdiv(K, BLOCK_SIZE_K)):
a = tl.load(a_ptrs,
mask=offs_k[None,:]< K - k * BLOCK_SIZE_K,
other=0.0)
b = tl.load(b_ptrs,
mask=offs_k[:,None]< K - k * BLOCK_SIZE_K,
other=0.0)
k_start = k * BLOCK_SIZE_K
offs_ks = k_start // group_k
a_s = tl.load(As_ptrs + offs_ks * stride_As_k)
b_s = tl.load(Bs_ptrs + offs_ks * stride_Bs_k)if dot_dtype isnotNone:
a = a.to(dot_dtype)
b = b.to(dot_dtype)
accumulator += tl.dot(a, b)* a_s[:,None]* b_s[None,:]
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
if C.dtype.element_ty == tl.bfloat16:
c = accumulator.to(tl.bfloat16)elif C.dtype.element_ty == tl.float16:
c = accumulator.to(tl.float16)else:
c = accumulator.to(tl.float32)
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
c_ptrs = C + stride_cm * offs_cm[:,None]+ stride_cn * offs_cn[None,:]
c_mask =(offs_cm[:,None]< M)&(offs_cn[None,:]< N)
tl.store(c_ptrs, c, mask=c_mask)defget_config_dtype_str(
dtype: torch.dtype,
use_int4_w4a16: Optional[bool]=False,
use_int8_w8a16: Optional[bool]=False,
use_fp8_w8a8: Optional[bool]=False,
use_mxfp4_w4a4: Optional[bool]=False)-> Optional[str]:if use_fp8_w8a8:return"fp8_w8a8"elif use_int8_w8a16:return"int8_w8a16"elif use_int4_w4a16:return"int4_w4a16"elif use_mxfp4_w4a4:return"mxfp4_w4a4"elif dtype == torch.float:# avoiding cases where kernel fails when float32 MoE# use fp16/bfloat16 configsreturn"float32"returnNonedefinvoke_fused_moe_kernel(A: torch.Tensor,
B: torch.Tensor,
C: torch.Tensor,
A_scale: Optional[torch.Tensor],
B_scale: Optional[torch.Tensor],
B_zp: Optional[torch.Tensor],
topk_weights: Optional[torch.Tensor],
sorted_token_ids: torch.Tensor,
expert_ids: torch.Tensor,
num_tokens_post_padded: torch.Tensor,
mul_routed_weight:bool,
top_k:int,
config:dict[str, Any]=None,
compute_type: tl.dtype = tl.bfloat16,
use_fp8_w8a8:bool=True,
use_int8_w8a8:bool=False,
use_int8_w8a16:bool=False,
use_int4_w4a16:bool=False,
per_channel_quant:bool=False,
block_shape: Optional[list[int]]=[128,128],
dot_dtype =None)->None:ifisinstance(dot_dtype,int)and dot_dtype ==1:
dot_dtype = tl.bfloat16
assert topk_weights isnotNoneornot mul_routed_weight
assert topk_weights isNoneor topk_weights.stride(1)==1assert sorted_token_ids.stride(0)==1if config isNone:
M = A.size(0)
config_dtype = get_config_dtype_str(use_fp8_w8a8=use_fp8_w8a8,
use_int8_w8a16=use_int8_w8a16,
use_int4_w4a16=use_int4_w4a16,
use_mxfp4_w4a4=False,
dtype=A.dtype)
get_config_func = functools.partial(
try_get_optimal_moe_config,
B.size(),
B.size(),
top_k,
config_dtype,
block_shape=block_shape,)
config = get_config_func(M)# config = {# 'BLOCK_SIZE_K': 128,# 'BLOCK_SIZE_M': 64,# 'BLOCK_SIZE_N': 128,# 'GROUP_SIZE_M': 32,# 'num_warps': 4,# 'num_stages': 2# }if use_fp8_w8a8 or use_int8_w8a8:assert B_scale isnotNoneassert(block_shape isNoneor triton.cdiv(B.size(-2), block_shape[0])== B_scale.size(-2))assert(block_shape isNoneor triton.cdiv(B.size(-1), block_shape[1])== B_scale.size(-1))elif use_int8_w8a16 or use_int4_w4a16:assert B_scale isnotNoneassert block_shape isNoneor block_shape[0]==0else:assert A_scale isNoneassert B_scale isNone
M = A.size(0)
num_tokens = M * top_k
EM = sorted_token_ids.size(0)if A.size(0)< config["BLOCK_SIZE_M"]:# optimize for small batch_size.# We assume that top_ids of each token is unique, so# so num_valid_experts <= batch_size <= BLOCK_SIZE_M,# and we can skip some invalid blocks.
EM =min(sorted_token_ids.size(0),
A.size(0)* top_k * config['BLOCK_SIZE_M'])
grid =lambda META:(triton.cdiv(EM, META['BLOCK_SIZE_M'])* triton.cdiv(
B.size(1), META['BLOCK_SIZE_N']),)
config = config.copy()
BLOCK_SIZE_K = config.pop("BLOCK_SIZE_K")if block_shape isnotNone:
BLOCK_SIZE_K =min(BLOCK_SIZE_K,min(block_shape[0],
block_shape[1]))
fused_moe_kernel[grid](
A,
B,
C,
A_scale,
B_scale,
topk_weights,
sorted_token_ids,
expert_ids,
num_tokens_post_padded,
B.size(1),
B.size(2),
EM,
num_tokens,
A.stride(0),
A.stride(1),
B.stride(0),
B.stride(2),
B.stride(1),
C.stride(1),
C.stride(2),
A_scale.stride(0)if A_scale isnotNoneand A_scale.ndim ==2else0,
A_scale.stride(1)if A_scale isnotNoneand A_scale.ndim ==2else0,
B_scale.stride(0)if B_scale isnotNoneand B_scale.ndim >=2else0,
B_scale.stride(2)if B_scale isnotNoneand B_scale.ndim ==3else0,
B_scale.stride(1)if B_scale isnotNoneand B_scale.ndim >=2else0,0if block_shape isNoneelse block_shape[0],0if block_shape isNoneelse block_shape[1],
MUL_ROUTED_WEIGHT=mul_routed_weight,
top_k=top_k,
compute_type=compute_type,
use_fp8_w8a8=use_fp8_w8a8,
use_int8_w8a8=use_int8_w8a8,
use_int8_w8a16=use_int8_w8a16,
per_channel_quant=per_channel_quant,
BLOCK_SIZE_K=BLOCK_SIZE_K,**config,)@triton.jitdefwrite_zeros_to_output(c_ptr, stride_cm, stride_cn, pid_n, N, offs_token,
token_mask, BLOCK_SIZE_M, BLOCK_SIZE_N,
compute_type):
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=compute_type)
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
c_ptrs = c_ptr + stride_cm * offs_token[:,None]+ stride_cn * offs_cn[None,:]
c_mask = token_mask[:,None]&(offs_cn[None,:]< N)
tl.store(c_ptrs, accumulator, mask=c_mask)@triton.jitdeffused_moe_kernel(# Pointers to matrices
a_ptr,
b_ptr,
c_ptr,
a_scale_ptr,
b_scale_ptr,
topk_weights_ptr,
sorted_token_ids_ptr,
expert_ids_ptr,
num_tokens_post_padded_ptr,# Matrix dimensions
N,
K,
EM,
num_valid_tokens,# The stride variables represent how much to increase the ptr by when# moving by 1 element in a particular dimension. E.g. `stride_am` is# how much to increase `a_ptr` by to get the element one row down# (A has M rows).
stride_am,
stride_ak,
stride_be,
stride_bk,
stride_bn,
stride_cm,
stride_cn,
stride_asm,
stride_ask,
stride_bse,
stride_bsk,
stride_bsn,# Block size for block-wise quantization
group_n: tl.constexpr,
group_k: tl.constexpr,# Meta-parameters
BLOCK_SIZE_M: tl.constexpr,
BLOCK_SIZE_N: tl.constexpr,
BLOCK_SIZE_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr,
MUL_ROUTED_WEIGHT: tl.constexpr,
top_k: tl.constexpr,
compute_type: tl.constexpr,
use_fp8_w8a8: tl.constexpr,
use_int8_w8a8: tl.constexpr,
use_int8_w8a16: tl.constexpr,
per_channel_quant: tl.constexpr,):"""
Implements the fused computation for a Mixture of Experts (MOE) using
token and expert matrices.
Key Parameters:
- A: The input tensor representing tokens with shape (*, K), where '*' can
be any shape representing batches and K is the feature dimension of
each token.
- B: The stacked MOE weight tensor with shape (E, N, K), where E is
the number of experts, K is the input feature dimension, and N is
the output feature dimension.
- C: The output cache tensor with shape (M, topk, N), where M is the
total number of tokens post padding, topk is the number of times
each token is repeated, and N is the output feature dimension.
- sorted_token_ids: A tensor containing the sorted indices of tokens,
repeated topk times and arranged by the expert index they are
assigned to.
- expert_ids: A tensor containing the indices of the expert for each
block. It determines which expert matrix from B should be used for
each block in A.
This kernel performs the multiplication of a token by its corresponding
expert matrix as determined by `expert_ids`. The sorting of
`sorted_token_ids` by expert index and padding ensures divisibility by
BLOCK_SIZE_M, which is necessary to maintain consistency in block matrix
multiplication across different blocks processed by the same expert.
"""
dot_dtype = tl.bfloat16
# dot_dtype = None# -----------------------------------------------------------# Map program ids `pid` to the block of C it should compute.# This is done in a grouped ordering to promote L2 data reuse.
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(EM, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m =min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m +((pid % num_pid_in_group)% group_size_m)
pid_n =(pid % num_pid_in_group)// group_size_m
# ----------------------------------------------------------# Create pointers for the first blocks of A and B.# We will advance this pointer as we move in the K direction# and accumulate# `a_ptrs` is a block of [BLOCK_SIZE_M, BLOCK_SIZE_K] pointers# `b_ptrs` is a block of [BLOCK_SIZE_K, BLOCK_SIZE_N] pointers
num_tokens_post_padded = tl.load(num_tokens_post_padded_ptr)if pid_m * BLOCK_SIZE_M >= num_tokens_post_padded:return
offs_token_id = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M).to(
tl.int64)
offs_token = tl.load(sorted_token_ids_ptr + offs_token_id)
token_mask = offs_token < num_valid_tokens
off_experts = tl.load(expert_ids_ptr + pid_m).to(tl.int64)if off_experts ==-1:# -----------------------------------------------------------# Write back zeros to the output when the expert is not# in the current expert parallel rank.
write_zeros_to_output(c_ptr, stride_cm, stride_cn, pid_n, N,
offs_token, token_mask, BLOCK_SIZE_M,
BLOCK_SIZE_N, compute_type)return
offs_bn =(pid_n * BLOCK_SIZE_N +
tl.arange(0, BLOCK_SIZE_N).to(tl.int64))% N
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = a_ptr +(offs_token[:,None]// top_k * stride_am +
offs_k[None,:]* stride_ak)
b_ptrs = b_ptr + off_experts * stride_be +(offs_k[:,None]* stride_bk +
offs_bn[None,:]* stride_bn)if use_int8_w8a16:
b_scale_ptrs = b_scale_ptr + off_experts * stride_bse + offs_bn[None,:]* stride_bsn
b_scale = tl.load(b_scale_ptrs)if use_fp8_w8a8 or use_int8_w8a8:# block-wiseif group_k >0and group_n >0:
a_scale_ptrs = a_scale_ptr +(offs_token // top_k)* stride_asm
offs_bsn = offs_bn // group_n
b_scale_ptrs =(b_scale_ptr + off_experts * stride_bse +
offs_bsn * stride_bsn)# channel-wiseelif per_channel_quant:
b_scale_ptrs = b_scale_ptr + off_experts * stride_bse + offs_bn[None,:]* stride_bsn
b_scale = tl.load(b_scale_ptrs)# Load per-token scale for activations
a_scale_ptrs = a_scale_ptr +(offs_token // top_k)* stride_asm
a_scale = tl.load(a_scale_ptrs, mask=token_mask, other=0.0)[:,None]# tensor-wiseelse:
a_scale = tl.load(a_scale_ptr)
b_scale = tl.load(b_scale_ptr + off_experts)# -----------------------------------------------------------# Iterate to compute a block of the C matrix.# We accumulate into a `[BLOCK_SIZE_M, BLOCK_SIZE_N]` block# of fp32 values for higher accuracy.# `accumulator` will be converted back to fp16 after the loop.
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)for k inrange(0, tl.cdiv(K, BLOCK_SIZE_K)):# Load the next block of A and B, generate a mask by checking the# K dimension.
a = tl.load(a_ptrs,
mask=token_mask[:,None]&(offs_k[None,:]< K - k * BLOCK_SIZE_K),
other=0.0)
b = tl.load(b_ptrs,
mask=offs_k[:,None]< K - k * BLOCK_SIZE_K,
other=0.0)if dot_dtype isnotNone:
a = a.to(dot_dtype)
b = b.to(dot_dtype)# We accumulate along the K dimension.if use_int8_w8a16:
accumulator = tl.dot(a, b.to(compute_type), acc=accumulator)elif use_fp8_w8a8 or use_int8_w8a8:if group_k >0and group_n >0:
k_start = k * BLOCK_SIZE_K
offs_ks = k_start // group_k
a_scale = tl.load(a_scale_ptrs + offs_ks * stride_ask,
mask=token_mask,
other=0.0)
b_scale = tl.load(b_scale_ptrs + offs_ks * stride_bsk)
accumulator += tl.dot(a, b)* a_scale[:,None]* b_scale[None,:]else:if use_fp8_w8a8:# acc used to enable fp8_fast_accum
accumulator = tl.dot(a, b, acc=accumulator)else:
accumulator += tl.dot(a, b)else:
accumulator += tl.dot(a, b)# Advance the ptrs to the next K block.
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
if MUL_ROUTED_WEIGHT:
moe_weight = tl.load(topk_weights_ptr + offs_token,
mask=token_mask,
other=0)
accumulator = accumulator * moe_weight[:,None]if use_int8_w8a16:
accumulator =(accumulator * b_scale).to(compute_type)elif use_fp8_w8a8 or use_int8_w8a8:if group_k >0and group_n >0:
accumulator = accumulator.to(compute_type)else:
accumulator =(accumulator * a_scale * b_scale).to(compute_type)else:
accumulator = accumulator.to(compute_type)# -----------------------------------------------------------# Write back the block of the output
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
c_ptrs = c_ptr + stride_cm * offs_token[:,None]+ stride_cn * offs_cn[None,:]
c_mask = token_mask[:,None]&(offs_cn[None,:]< N)
tl.store(c_ptrs, accumulator, mask=c_mask)