第五章:注意力机制增强(IPCA)
欢迎回到1Prompt1Story🐻❄️
在第四章中,我们掌握了**语义向量重加权(SVR)**技术,通过语义向量调节实现核心要素强化。
但当场景从"雪地嬉戏"切换至"浆果觅食"时,仍可能出现红狐头部畸变或浆果异常附着等问题。这些现象源于AI注意力机制的分散性特征。
智能聚光灯:引导AI视觉焦点
将UNet神经网络(第六章详解)的注意力机制类比为画家的视觉焦点:
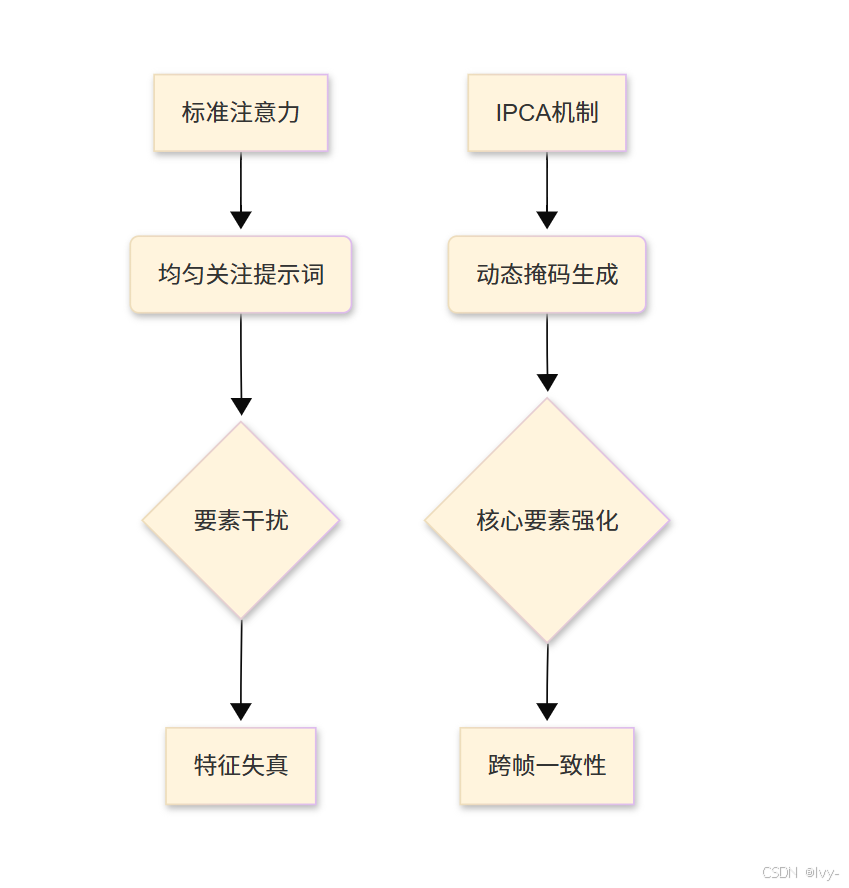
- 常规模式:均匀关注提示词各要素,易导致
次要元素干扰 - IPCA模式:通过动态掩码锁定核心要素,实现注意力定向增强
IPCA启用方法
通过生成行为控制器配置参数:
# 配置示例(摘自main.py简化版)
from unet.unet_controller import UNetController
controller = UNetController()
controller.Use_ipca = True # 启用IPCA
# 层级作用域配置
controller.Ipca_position = ['down0', 'down1', 'mid', 'up1'] # 指定UNet作用层
controller.Ipca_start_step = 10 # 去噪第10步后启用
# 掩码参数优化
controller.Use_embeds_mask = True # ID提示区域保护
controller.Ipca_dropout = 0.05 # 非核心区域随机丢弃率
过拟合
就是模型在训练数据上表现太好,反而在没见过的新数据上表现很差,相当于“死记硬背不会灵活应用”。
参数解析表
| 参数 | 功能描述 | 推荐值域 |
|---|---|---|
Ipca_position |
作用网络层(控制细节粒度) | UNet层级名称 |
Ipca_start_step |
生效起始步数(防早期过拟合) | 总步长10%-30% |
Use_embeds_mask |
核心区域保护开关 | True/False |
Ipca_dropout |
随机丢弃率(防过关注) | 0.01-0.1 |
技术实现
核心代码路径
IPCA逻辑主要实现在:
unet/unet.py的Attention模块unet/utils.py的ipca2与ipca函数
# 注意力模块改造(unet/unet.py简化版)
class Attention(nn.Module):
def forward(self, hidden_states, unet_controller=None):
# 生成QKV向量
q = self.to_q(hidden_states)
k = self.to_k(encoder_hidden_states)
v = self.to_v(encoder_hidden_states)
# IPCA条件检测
if 控制器启用且满足层级/步数条件:
attn_output = utils.ipca2(q, k, v, scale, unet_controller)
else:
# 标准注意力计算
attn_weights = torch.softmax(scores, dim=-1)
attn_output = torch.matmul(attn_weights, v)
return attn_output
IPCA核心算法
# 增强注意力计算(unet/utils.py简化版)
def ipca(q, k, v, scale, controller):
# 分离正负提示分支
q_pos, q_neg = q.chunk(2)
k_pos, k_neg = k.chunk(2)
# 构建增强键值对
k_plus = torch.cat([k_pos, *stored_keys], dim=2) # 历史键值整合
v_plus = torch.cat([v_pos, *stored_values], dim=1)
# 动态掩码生成
dropout_mask = torch.bernoulli(1 - controller.Ipca_dropout) # 随机丢弃矩阵
if controller.Use_embeds_mask:
embeds_mask = generate_embeds_mask(q_pos, controller.id_prompt) # ID区域掩码
final_mask = dropout_mask * embeds_mask
# 掩码注意力计算
scores = (q_pos @ k_plus) * scale
scores += torch.log(final_mask) # 掩码叠加
attn_weights = torch.softmax(scores, dim=-1)
return attn_weights @ v_plus
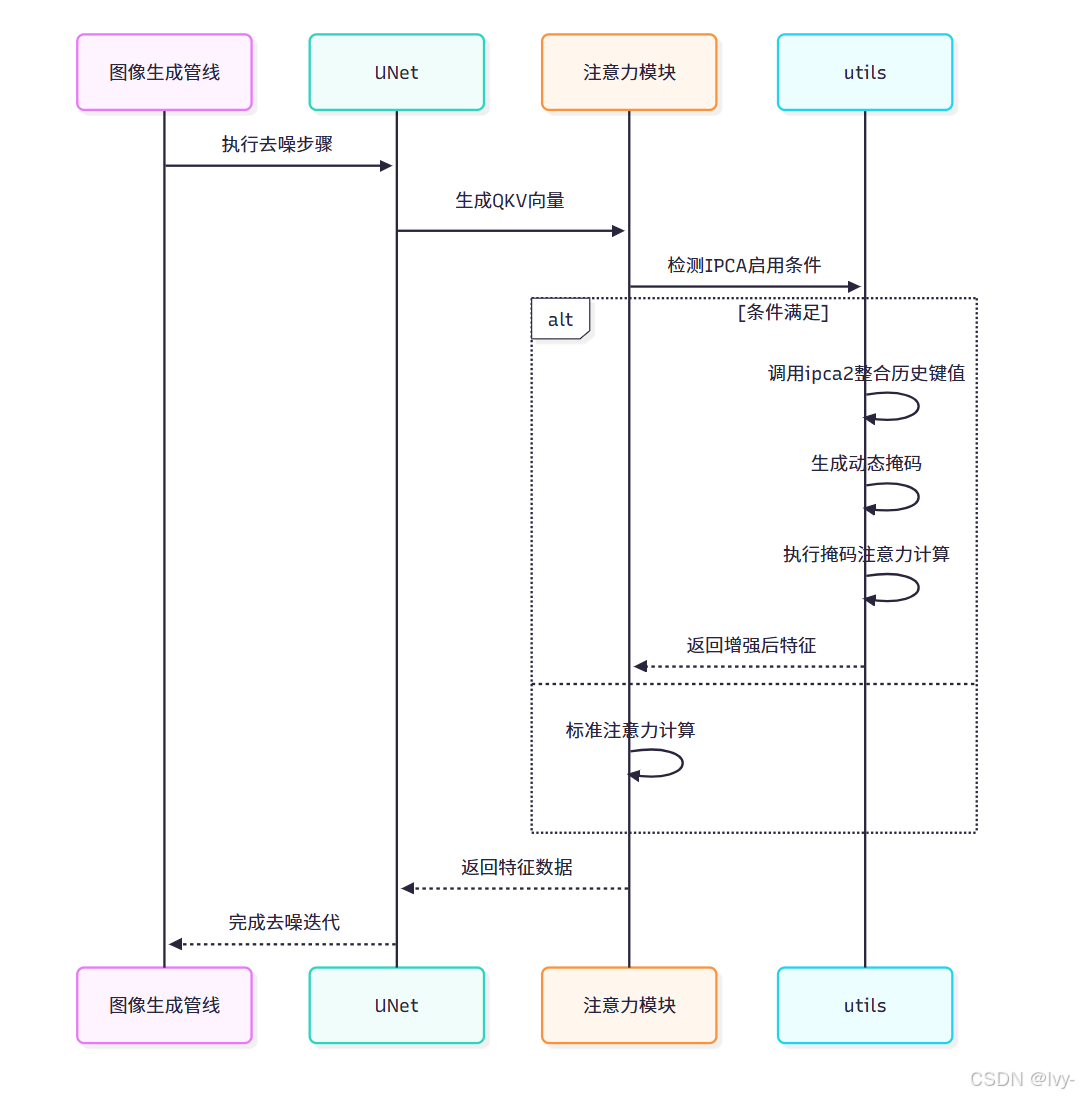
IPCA(Improved Prompt-Conditioned Attention)通过动态整合历史键值对和智能掩码机制,实现更精准的注意力控制。
核心是将当前提示与历史记忆结合,并通过随机丢弃与语义掩码的双重过滤,增强关键特征的注意力权重。
关键实现逻辑:
分支处理
将查询(q)、键(k)、值(v)张量沿通道维度切分为正负提示两个独立分支,仅对正向提示分支进行增强处理。
记忆增强
通过拼接当前键值(k_pos/v_pos)与存储的历史键值(stored_keys/values),扩展模型的上下文感知范围,形成k_plus/v_plus增强键值对。
动态掩码
采用伯努利采样生成随机丢弃矩阵(dropout_mask),结合基于ID提示生成的语义区域掩码(embeds_mask),通过逐元素相乘得到最终注意力掩码。
掩码注意力
在标准注意力得分计算后,将对数掩码值直接叠加到得分矩阵,通过softmax使被掩码位置的权重趋近于零,实现特征级精确定位。
工作流程
技术优势
IPCA为1Prompt1Story带来三大突破:
- 特征锁定:通过
历史键值整合,维持跨帧特征一致性 - 干扰隔离:动态掩码有效隔离场景变化带来的噪声干扰
- 自适应增强:阶梯式启用机制平衡细节生成与特征保留
结合语义向量重加权与统一噪声基底技术,IPCA将跨帧一致性提升至新高度。
在第六章中,我们将深入解析UNet工作原理,揭示三大技术协同作用的底层机制。
第六章:去噪神经网络(UNet)
迄今为止,我们已经学习了滑动窗口故事生成器如何巧妙准备故事提示词,图像生成管线如何统筹整个图像创建流程,以及我们的"导演"——生成行为控制器如何运用语义向量重加权(SVR)和注意力机制增强(IPCA)等强大技术确保惊人的连贯性。
但所有这些准备、控制和巧妙的提示词操作,最终都是为了一个目标:引导真正负责"绘制"图像的核心"艺术家"。
这位艺术家就是去噪神经网络,通常被称为UNet。
核心艺术家:从噪点到故事
想象我们有一块神奇的画布,初始状态完全被随机噪点填满,就像没有信号的旧电视屏幕。我们的目标是将这些噪点转化为"红狐在雪地嬉戏"的美丽画面。同时我们拥有详细指令(提示词)和导演(UNetController)在耳边的指引。
UNet正是这位魔法艺术家。
它不从空白画布开始,而是从纯粹的随机噪声(第2章图像生成管线中提到的"潜在变量")起步。它的工作是通过反复"去噪"——逐步消除随机性,分步骤揭示清晰连贯的图像。
在每个步骤中,UNet会观察当前含噪图像,听取文本提示(来自第2章的"嵌入向量"),同时密切关注UNetController的具体指令(如SVR和IPCA规则)。
综合这些信息,它预测需要去除哪些噪声才能使图像更清晰、更符合提示词。这个过程重复多次(例如50步),逐步将抽象噪点转化为具体的视觉特征。
UNet是实现原始创意转化的核心,将抽象的"概念"(潜在表征)转化为毛皮、树木、雪花等真实视觉元素。
为何称为"UNet"?U型数据流
UNet中的"U"指其特殊架构,形似字母U。
这种U型结构对图像处理极为有效,因为它能同时理解整体形状(如"此处有狐狸轮廓")和精细细节(如"狐狸有胡须")。
架构解析:
- 下采样路径(U型左侧):如同画家勾勒
大体轮廓。接收含噪图像并逐步缩小、抽象化(降采样)。每个阶段捕捉高层级信息——非逐像素细节,而是整体形状和概念。 - 瓶颈层(U型底部):信息
最压缩、最抽象的层级。此处进行核心"思考",受文本提示词深度影响。 - 上采样路径(U型右侧):画家
精修阶段。获取瓶颈层的抽象信息,逐步重建图像并添加细节(升采样)直至恢复原始尺寸。 - 跳跃连接:精妙设计!艺术家在右侧精修细节时,可回看左侧的原始草图。这些"跳跃连接"直接将
同层级的下采样信息传递给上采样路径,确保锐利边缘等精细特征不被丢失。
1Prompt1Story如何运用UNet
我们并不直接操作UNet,而是通过图像生成管线来管理。每当管线执行"去噪步骤"(通常需数十次),都会将当前含噪图像、文本提示的"思考"(嵌入向量)和UNetController传递给UNet。
UNet执行噪声预测后,管线利用预测结果略微净化图像,循环往复。
以下是管线调用UNet的简化流程(源自第2章图像生成管线):
# 简化自 unet/pipeline_stable_diffusion_xl.py(__call__方法内部)
for i, t in enumerate(self.timesteps):
# 将潜在变量和当前时间步传递给UNet
# UNet使用prompt_embeds(AI的"思考")预测噪声
noise_pred = self.unet(
latent_model_input, # 当前含噪图像数据
t, # 当前时间步(去噪阶段指示)
encoder_hidden_states=prompt_embeds, # 提示词生成的"思考"
unet_controller=unet_controller, # 实现1Prompt1Story特性的关键!
return_dict=False,
)[0]
# 使用调度器应用噪声预测,获得更干净的潜在变量
latents = self.scheduler.step(noise_pred, t, latents)[0]
# ...(后续处理流程)...
注意
unet_controller如何直接传入self.unet调用。
这至关重要,因为它使得UNet能够访问第3章生成行为控制器配置的所有连贯性设置,并在绘制过程中应用。
内部机制:UNet的绘制过程
让我们深入UNet的工作原理。
迭代精修流程
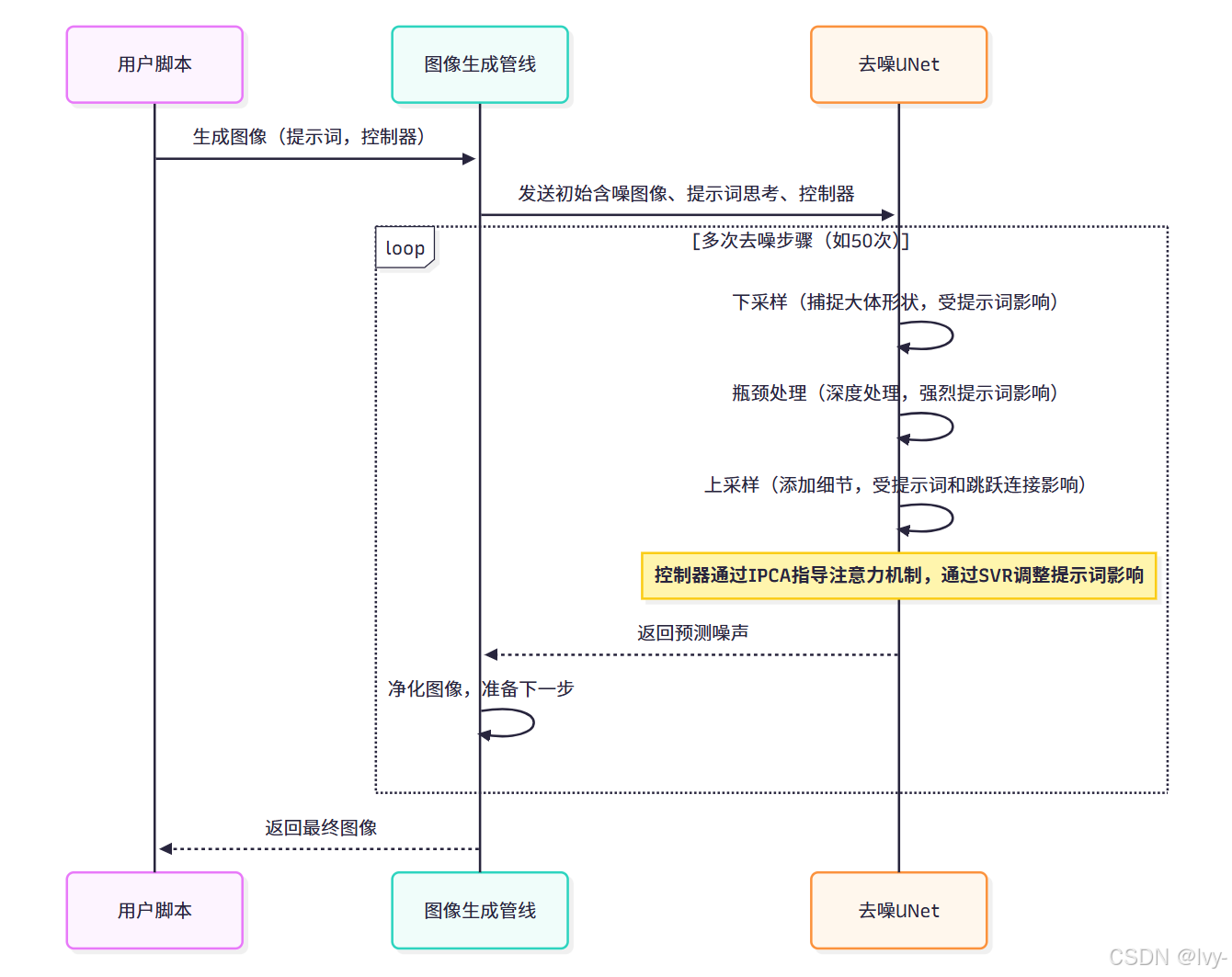
在每次循环中,UNet接收当前含噪图像并预测其内部噪声。这个预测过程深度依赖encoder_hidden_states(对提示词的"思考")和unet_controller。
代码解析:unet/unet.py
核心UNet模型定义在unet/unet.py的UNet2DConditionModel类中,主要流程体现在forward方法:
# 简化自 unet/unet.py(UNet2DConditionModel.forward方法)
class UNet2DConditionModel(ModelMixin, ConfigMixin):
# ...(初始化各层:conv_in、time_embedding、down_blocks等)...
def forward(
self, sample, timesteps, encoder_hidden_states, added_cond_kwargs,
unet_controller: Optional[UNetController] = None, **kwargs
):
# 1. 准备时间和文本嵌入
# 'emb'包含当前去噪步骤和文本提示信息
# 此处处理'added_cond_kwargs'(如第2章的text_embeds)
# ...(准备'emb'的代码)...
sample = self.conv_in(sample) # 初始卷积
# 2. 下采样路径(U型左侧)
# 每个下采样块缩小图像尺寸并提取特征
# s0、s1、s2等为"跳跃连接"保留的特征
if unet_controller is not None:
unet_controller.current_unet_position = 'down0' # 告知控制器当前位置
sample, [s1, s2, s3] = self.down_blocks[0](sample, temb=emb)
if unet_controller is not None:
unet_controller.current_unet_position = 'down1'
sample, [s4, s5, s6] = self.down_blocks[1](
sample, temb=emb,
encoder_hidden_states=encoder_hidden_states,
unet_controller=unet_controller # 传递控制器!
)
# ...(类似处理其他下采样块)...
# 3. 中间块(U型底部)- 最深层次处理
if unet_controller is not None:
unet_controller.current_unet_position = 'mid'
sample = self.mid_block(
sample, emb,
encoder_hidden_states=encoder_hidden_states,
unet_controller=unet_controller
)
# 4. 上采样路径(U型右侧)
# 每个上采样块增大尺寸并添加细节,使用跳跃连接
if unet_controller is not None:
unet_controller.current_unet_position = 'up0'
sample = self.up_blocks[0](
hidden_states=sample, temb=emb,
res_hidden_states_tuple=[s6, s7, s8], # 使用跳跃连接
encoder_hidden_states=encoder_hidden_states,
unet_controller=unet_controller
)
# ...(类似处理其他上采样块)...
# 5. 最终卷积层(像素级预测)
# ...(最终层处理代码)...
return [sample]
关键要素:
sample:当前待优化的含噪图像数据(潜在变量)timesteps:指示去噪过程进度encoder_hidden_states:文本提示的"思考"嵌入unet_controller:实现IPCA等增强机制的关键
注意力机制核心
在Transformer2DModel(用于各跨注意力块)中,Attention模块是图像数据与文本提示交互的核心枢纽:
# 简化自 unet/unet.py(Attention.forward方法)
class Attention(nn.Module):
def forward(self, hidden_states, encoder_hidden_states=None,
unet_controller: Optional[UNetController] = None):
q = self.to_q(hidden_states) # 图像特征查询向量
k = self.to_k(encoder_hidden_states) # 提示词键向量
v = self.to_v(encoder_hidden_states) # 提示词值向量
if (unet_controller启用IPCA且满足条件):
# 应用IPCA增强的注意力计算
attn_output = utils.ipca2(q,k,v,self.scale,unet_controller)
else:
# 标准注意力计算
scores = torch.matmul(q, k.transpose(-2, -1)) * self.scale
attn_weights = torch.softmax(scores, dim=-1)
attn_output = torch.matmul(attn_weights, v)
return attn_output
此处汇聚了所有技术精华:
- 图像特征通过跨注意力机制与提示词交互
- SVR优化后的提示词嵌入指导内容生成
- IPCA通过控制器动态调整注意力模式
总结
IPCA技术通过动态掩码和历史键值整合,实现AI生成图像时的核心要素锁定,有效解决场景切换导致的特征畸变问题。
- 该技术包含
分支处理、记忆增强和动态掩码三大机制,通过控制器参数精确调节注意力分布。
作为核心生成引擎,UNet采用U型架构分步去噪,下采样路径提取整体轮廓,上采样路径补充细节,将随机噪声逐步转化为符合提示词的视觉内容。
- IPCA与UNet的协同工作,显著
提升了跨帧一致性和特征保持能力,是AI图像生成实现高质量连续叙事的关键技术组合
我们已触及1Prompt1Story的核心🐻❄️去噪神经网络(UNet) 是将随机噪声转化为连贯图像的动力引擎。
其U型架构既能把握整体构图,又能雕琢精微细节,在UNetController的精密调控下,协同滑动窗口故事生成器、语义向量重加权等技术,最终实现视觉叙事的高度连贯性。
至此,我们已完成1Prompt1Story核心架构的探索之旅,相信你已经了解了这个创新工具如何将文字提示转化为精彩视觉叙事!
END ★,°:.☆( ̄▽ ̄).°★ 。