Hadoop - 1:Hadoop 技术解析;Hadoop是什么;Hadoop优势;Hadoop组成;HDFS、YARN、MapReduce 三者关系
Hadoop - 1:Hadoop 技术解析
一、Hadoop 是什么
Hadoop 是一个由 Apache 基金会开源的 分布式计算框架,主要用于解决海量数据的存储和计算问题。它最初由 Doug Cutting 和 Mike Cafarella 开发,并受 Google 三篇经典论文(GFS、MapReduce、Bigtable)的启发而诞生。
Hadoop 的核心思想是 通过普通商用硬件搭建大规模分布式集群,在保障高可靠性和高吞吐量的同时,能够高效地处理 TB、PB 级别的大数据。
Hadoop 最常见的应用场景包括:
- 日志分析(如电商、搜索引擎的点击日志)
- 推荐系统(如抖音、淘宝的个性化推荐)
- 数据仓库建设
- 机器学习模型的离线训练
二、Hadoop 优势
1. 高可靠性
Hadoop 会在底层维护多个数据副本,即使某个计算节点或存储节点发生故障,也不会导致数据丢失。数据会自动从副本中恢复,保证业务的连续性。
2. 高扩展性
Hadoop 可以将任务和数据分布到不同的集群节点,理论上可以扩展到成千上万台服务器。例如在电商大促(双 11、618)期间,可以灵活增加集群节点以应对流量高峰。
3. 高效性
Hadoop 采用 MapReduce 并行计算模型,将复杂的计算任务拆分为子任务并行执行,大幅提升数据处理速度。
4. 高容错性
当某个任务执行失败时,Hadoop 会自动重新调度任务到其他节点执行,而无需人工干预,从而提高了系统的健壮性。
三、Hadoop 组成
Hadoop 主要由以下核心组件构成:
- HDFS(Hadoop Distributed File System):分布式文件存储系统,负责将大文件拆分成数据块并存储在多个节点。
- YARN(Yet Another Resource Negotiator):资源管理系统,负责调度和分配集群资源。
- MapReduce:分布式计算框架,用于执行大规模数据处理任务。
1. Hadoop 1.x、2.x、3.x 区别
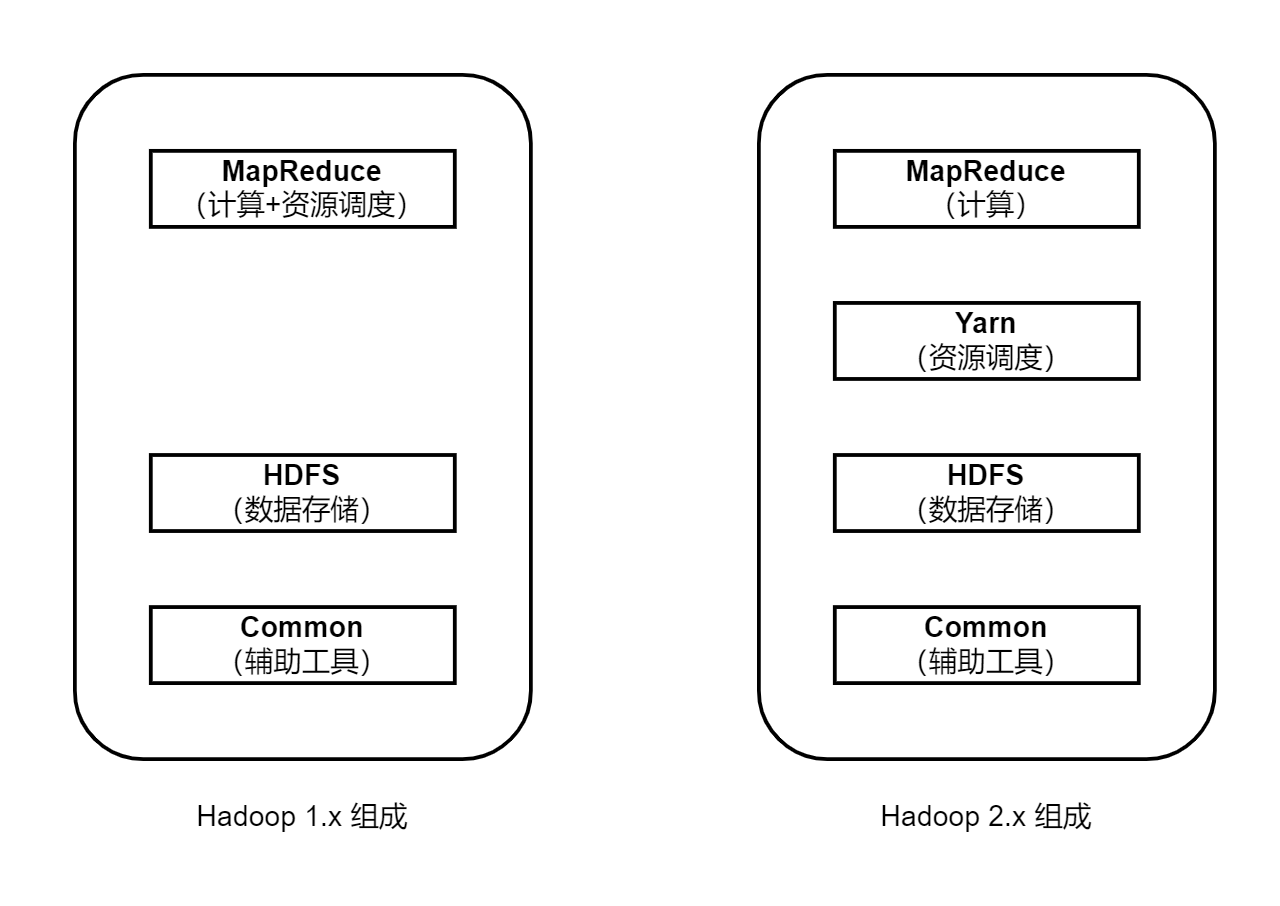
在Hadoop1.x时代Hadoop中的MapReduce百时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce只负责运算。
Hadoop3.x在组成上没有变化。
Hadoop 1.x
- 采用 MapReduce 作为资源管理和计算框架。
- JobTracker 既负责任务调度又负责资源管理,容易成为瓶颈。
Hadoop 2.x
- 引入 YARN,将资源管理和任务调度分离。
- 提升了资源利用率,并支持多种计算框架(不仅仅是 MapReduce,还能跑 Spark、Tez 等)。
Hadoop 3.x
- 支持 纠删码(Erasure Coding),大幅降低存储成本。
- 引入 多 NameNode(支持 Federation),提升了集群的可扩展性。
- 提升了容器化支持,适配云原生环境。
2. HDFS 架构概述
Hadoop Distributed File System,简称HDFS,是 Hadoop 的分布式文件系统,特点是高吞吐量和大文件存储。
- NameNode(nn):元数据管理节点,负责维护文件系统的目录结构、文件与数据块的映射关系:存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):存储节点,在本地文件系统存储文件块数据,以及块数据的校验和。
- SecondaryNameNode(2nn):用于辅助 NameNode 做元数据的合并(并不是 NameNode 的备份)。
数据存储机制:
- 默认会将每个文件切分成 128MB 的数据块。
- 每个数据块会保存 3 个副本,分布在不同节点上。
3. YARN 架构概述
YARN 的主要作用是 资源管理 + 任务调度,它相当于 Hadoop 的“操作系统内核”。
核心组件:
- ResourceManager(RM):整个集群资源(内存、CPU等)的老大。全局资源管理器,负责分配资源。
- NodeManager(NM):单个节点服务器资源老大。运行在每个节点上,负责汇报节点资源使用情况,并执行任务。
- ApplicationMaster(AM):单个任务运行的老大。为具体应用而生,负责任务的拆分和执行调度。
- Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
4. MapReduce 架构概述
MapReduce 是 Hadoop 的分布式计算模型,采用 Map → Shuffle → Reduce 三个阶段:
- Map 阶段:输入数据经过 Map 函数处理,生成中间键值对。
- Shuffle 阶段:对 Map 输出进行分区、排序、分组。
- Reduce 阶段:对相同 key 的数据进行聚合计算,输出最终结果。
典型应用场景:日志统计、倒排索引、离线分析。
四、HDFS、YARN、MapReduce 三者关系
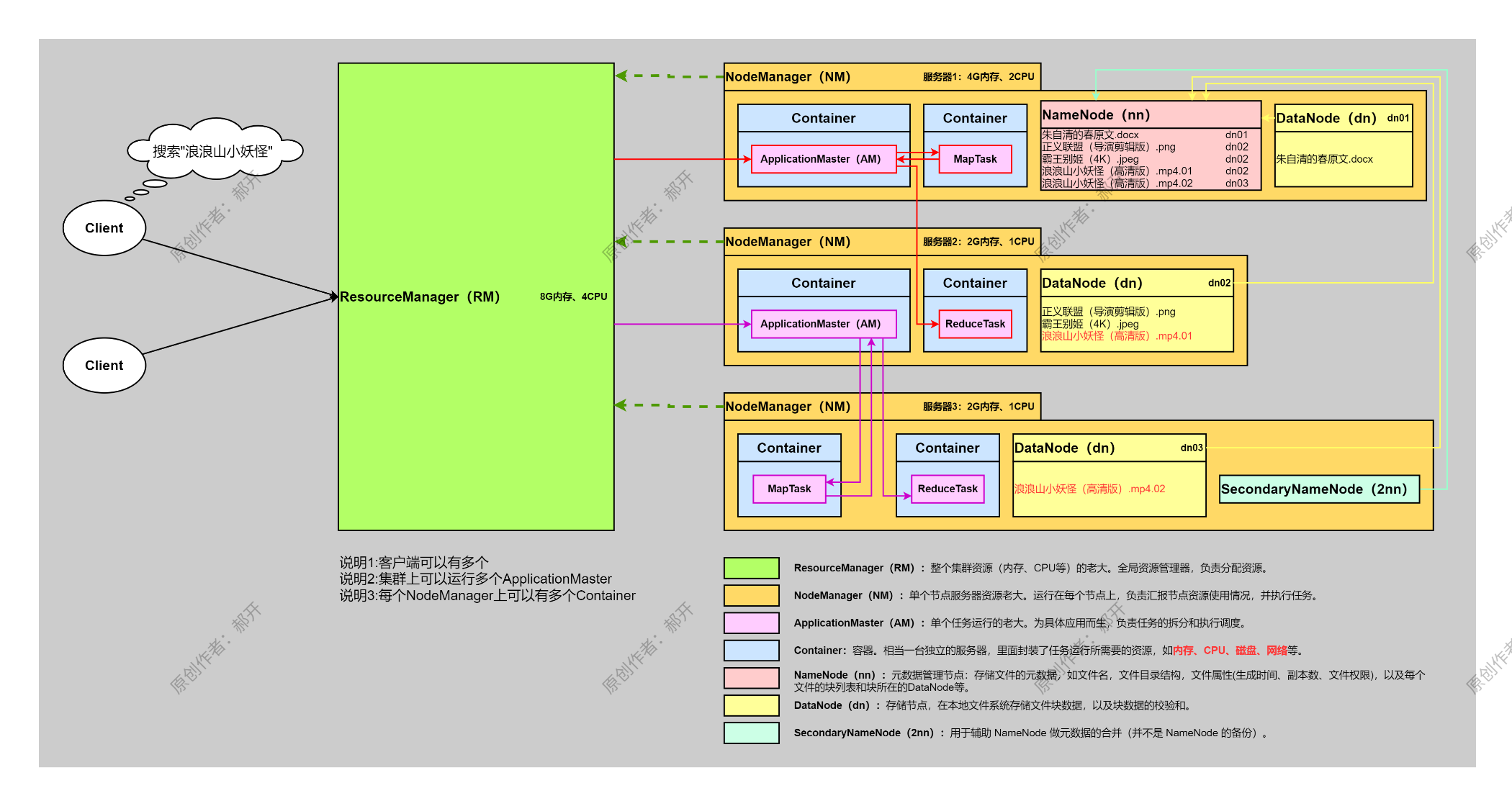
可以简单理解为:
- HDFS:存储海量数据(相当于“硬盘”)。
- YARN:负责集群资源管理(相当于“操作系统”)。
- MapReduce:执行具体的计算任务(相当于“应用程序”)。
三者之间的关系:
- 数据存放在 HDFS 中。
- 用户提交作业,YARN 负责分配资源并调度任务。
- MapReduce 框架在分配到的资源中运行,读取 HDFS 数据并执行计算,最终将结果写回 HDFS。
五、总结
Hadoop 作为大数据生态的核心基础设施,已经成为许多企业进行 大规模数据存储与计算 的首选解决方案。随着 Hadoop 3.x 的发布,它在性能、扩展性、存储成本和云原生支持等方面都有了显著提升。
未来,随着云计算和大数据技术的融合,Hadoop 仍将在离线数据处理领域扮演重要角色,而实时计算则会更多依赖 Spark、Flink 等新一代计算框架。