业务痛点:为什么ETL中的数据一致性问题屡见不鲜?
老刘至今对负责过的一个合作项目印象深刻,我们被外包给一个金融风控系统升级的项目,当时那银行的数据仓库出现了交易记录错乱的问题:清算模块显示的数据与源系统账簿不一致,导致对账延迟了4小时,我们负责后期数据的也只好干等着。
相信对于许多后端开发工程师和数据架构师而言,这样的例子并不陌生。数据一致性校验是ETL(Extract-Transform-Load)流程中最容易被忽视但代价极高的环节,一旦出现偏差,整个业务决策和下游分析都会被误导。
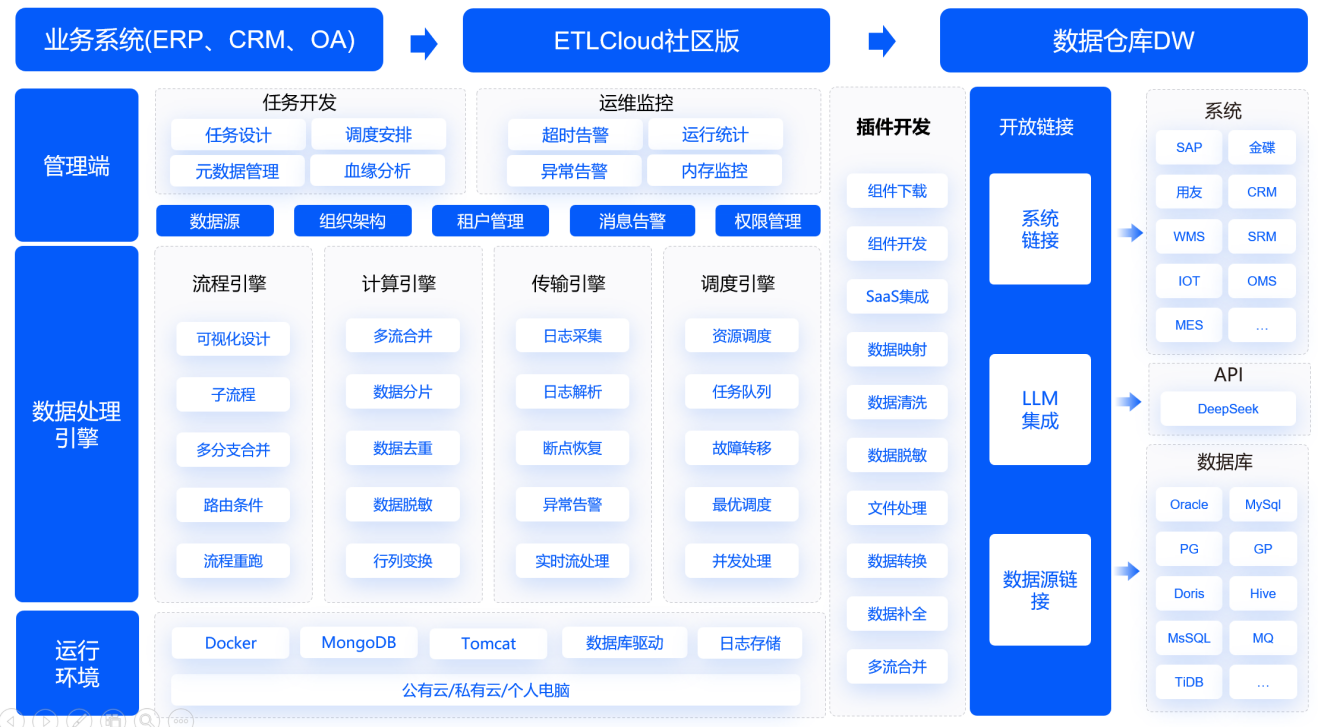
什么是数据一致性校验,为什么它是ETL的核心保障?
数据一致性校验指确保在ETL抽取、转换和加载各环节中,数据未被丢失、篡改或重复。根据Gartner的报告(Data Quality Market Guide),一套更高质量的数据校验机制至少可以降低80%的生产环境数据错误率。
需要老刘特别提到的要点是:数据一致性不仅指字段值一致,还包括业务逻辑一致、时间戳同步、跨系统数据血缘可追踪。
其覆盖范围比我们想象中的更广,一旦出现差错,后果往往不可设想 。因此,完备的数据一致性校验,是ETL工具稳定运行的核心保障。
如何在ETL流程中高效实现数据一致性校验?
1.在数据抽取阶段进行源端校验
校验字段完整性:确保所有关键主键和外键都被完整抽取,没有遗漏或丢失。
数据量比对:记录抽取的总行数是否与源系统日志匹配。
时间戳一致性:验证在抽取批次的时间窗口内有无遗漏记录,确保时间窗口保持一致性。
2.在数据转换阶段进行规则校验
数据类型匹配:避免由于类型转换(如int到varchar)导致的数据精度丢失。
业务逻辑验证:如“订单状态=已支付”时,“支付时间”字段必须非空。
使用自动化单元测试:通过SQL断言或数据质量框架(如Great Expectations)提前发现异常。
3.在数据加载阶段进行目标端校验
加载后行数一致性检查:抽取-加载两端行数必须相符。
哈希值或校验和验证:通过MD5或SHA算法比对源数据与目标数据。
数据血缘追踪:借助ETL工具(如Informatica、Talend)生成血缘图,定位异常数据来源。
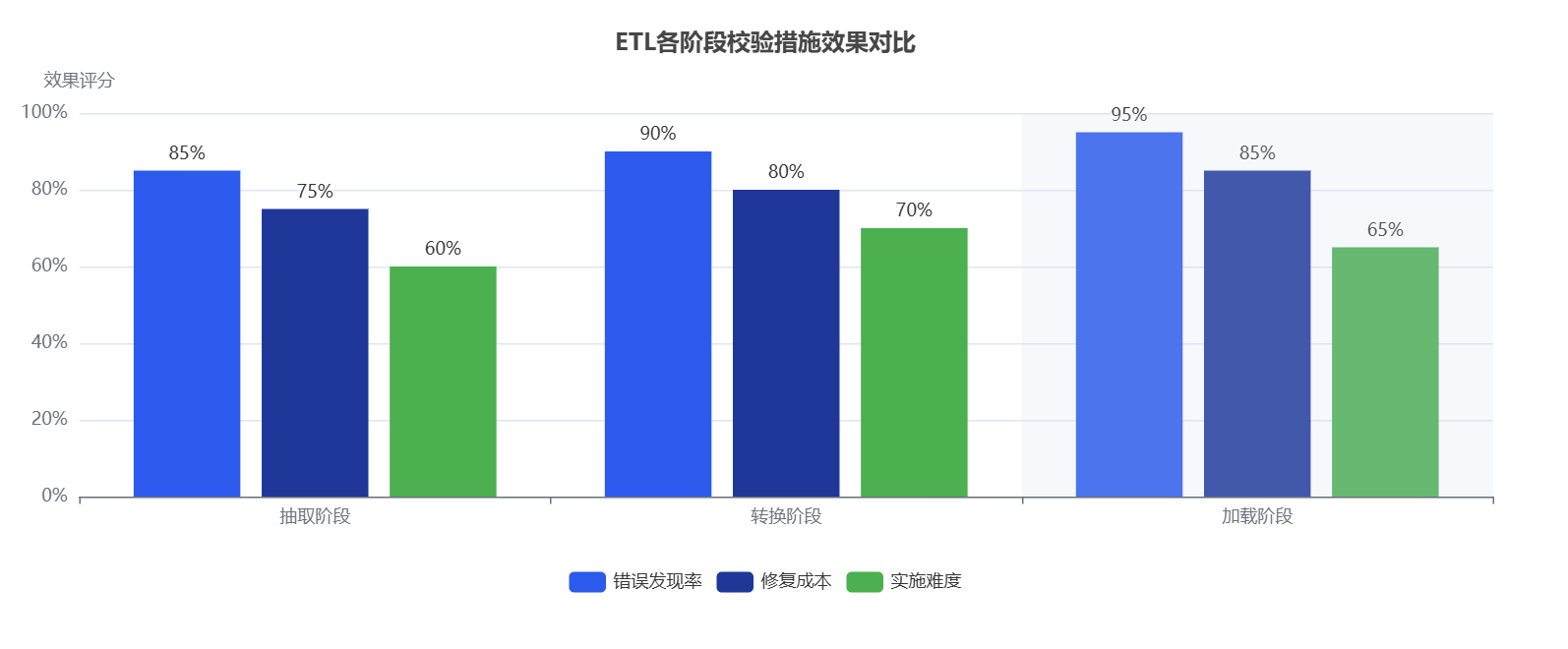
常见问题FAQ:企业在做ETL一致性校验时最容易忽视什么?
问题1:为什么ETL跑得很快但数据依旧不可信?
原因:只关注性能优化(如并行加载、异步队列),却忽略了数据质量校验模块的设计。
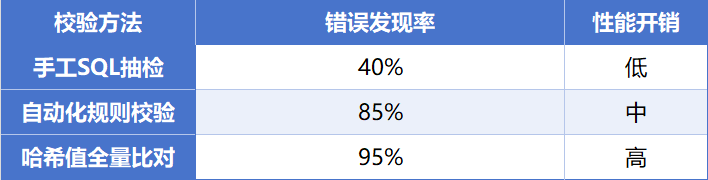
问题2:手工SQL校验能否替代自动化校验?
结论:不建议完全依赖手工校验。人工方式无法应对大规模数据,且容易遗漏边界条件。
问题3:如何评估校验机制的有效性?
指标参考:
- 错误发现率:发现错误的占比≥95%。
- 校验性能开销:校验耗时占ETL总耗时≤15%。
- 修复成本:单条错误数据修复平均耗时≤5分钟。
示例对比表:
哪些技术和工具能显著提升数据一致性校验效果?
数据质量框架:Great Expectations、Deequ(支持可编程断言)。
ETL工具内置校验:Informatica、Talend、AWS Glue提供血缘追踪与校验报告。
日志与监控集成:通过Prometheus+Grafana、ETLCloud实时监控数据一致性指标。
Schema Markup建议:为FAQ部分添加FAQPage标记,为步骤部分添加HowTo标记,有助于搜索引擎索引与引用。
数据一致性校验是ETL可靠性的生命线
数据一致性校验不是可选项,而是确保信息准确无误的关键步骤。企业应在ETL的抽取、转换、加载各环节构建自动化、可追踪的校验机制,并通过指标化评估效果。实践证明,在ETL流程中加入全链路一致性校验,可将数据错误率降低至1%以下,极大提升分析与决策的可信度。
更多关于ETL性能优化与数据质量管理的实战经验,可参考ETLCloud—国内最大的数据集成社区,让人人都能成为数据集成大师