上一次写文章还是上一次,时隔一年+再次开启学习之路。新机mac没有开发环境,在gpt老师的指导下开始学习之路。
mac开发环境的部署参考了b站程序员云谦和Clover-You的视频教程,然后结合自身及gpt老师的帮助现在开始部署。
g老师的🍎 新机环境搭建路线(适合智能语音开发)
安装顺序建议:
Homebrew(您正在做)
Miniforge(Python环境管理)
VS Code & JupyterLab(开发工具)
PyTorch (MPS加速)(核心深度学习框架)
语音处理库(librosa、speechbrain、paddlespeech等)
辅助软件(Audacity、Git)
第一步选择了clashxmeta。
第二步Homebrew。该听云谦大佬的话,先打开代理,我没有打开直接复制官网链接安装,小慢。然后按照提示配置环境变量。
第三步按照g老师要求安装 Python 环境管理工具
g老师建议建议用 Miniforge (Conda 的轻量版,支持 Apple Silicon M 系列)
HOMEBREW_NO_AUTO_UPDATE=1 brew install --cask miniforge
前半段指令用于跳过自动更新(避免卡在更新阶段),然后直接安装最新的 Miniforge g老师说了不需要制定版本,homebrew会默认安装最新稳定版的miniforge,并且miniforge会自动适配我的m4
安装后检查
conda --version
conda 25.3.1
创建语音开发环境
conda create -n voice python=3.10
conda activate voice
激活环境时报错:
CondaError: Run 'conda init' before 'conda activate'
g老师说是说明 您的 shell(zsh/bash)还没有配置 Conda,所以它不知道怎么激活环境。解决方法:先设置生效然后在激活环境
conda init zsh
source ~/.zshrc
conda activate voice
退出环境命令:
conda deactivate

第四步安装开发工具vscode
brew install --cask visual-studio-code
打开vscode按照建议安装插件

安装python插件,测试插件,创建test.py文件,经典的hello word,运行后可以显示。
测试jupyter插件,新建test.ipynb文件,+code后输入
import sys
print("Python环境:", sys.version)
点击左侧运行,选择已经创建好的conda:voice环境。没有找到环境,需要在voice环境中安装Jupyter 的内核包。
pip install ipykernel
python -m ipykernel install --user --name=voice --display-name "Python (voice)"
点击运行选择kernel-python-voice-测试成功


继续安装JupyterLab,在voice环境下执行
pip install jupyterlab
安装过程会自动拉取 notebook、tornado、traitlets 等依赖。
在终端输入:
jupyter lab
默认会自动在浏览器里打开一个页面
http://localhost:8888/lab
网页端测试新建一个Notebook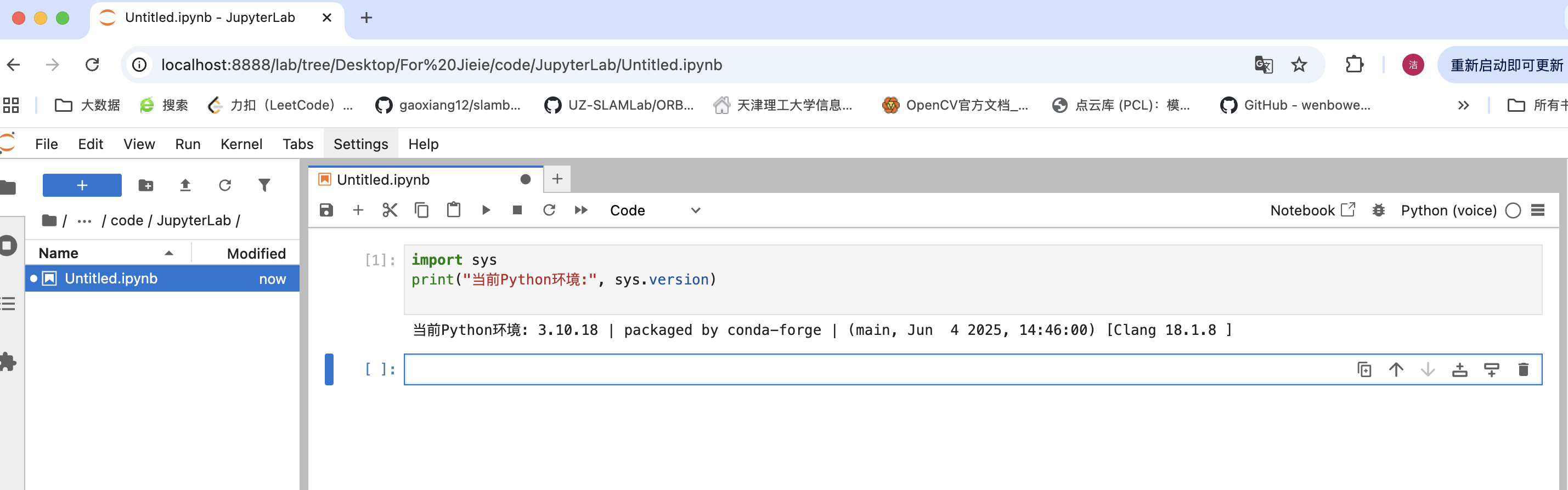
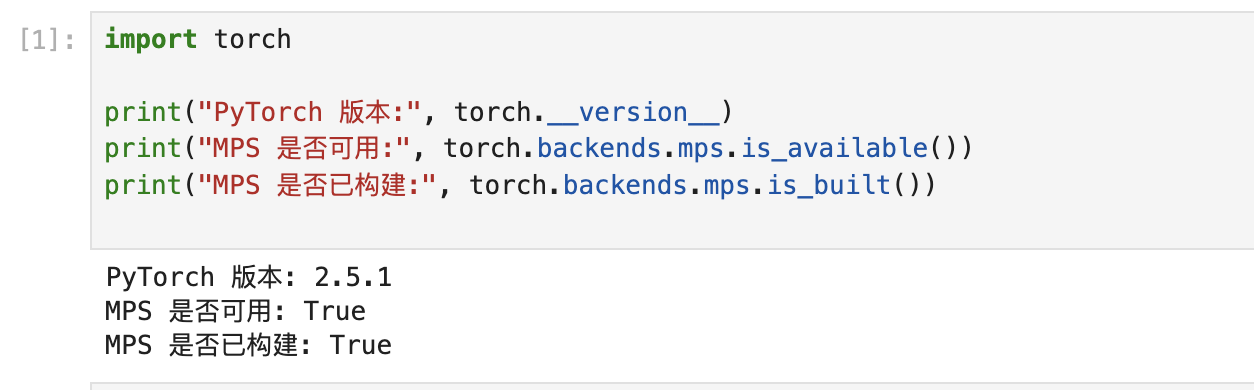
第五步安装 PyTorch(支持 MPS 加速)
在voice环境下安装
conda install pytorch torchvision torchaudio -c pytorch -c conda-forge
pytorch → 核心深度学习框架
torchvision → 图像处理扩展
torchaudio → 语音/音频处理扩展
第六步安装语音处理库
在voice环境下安装语音处理库
pip install librosa pydub transformers speechbrain paddlespeech gradio
这些库的作用:
librosa → 音频特征提取(MFCC、频谱、声谱图)
pydub → 音频格式转换/剪辑(如 mp3 ↔ wav)
transformers → HuggingFace 的预训练模型库(ASR/TTS/NLP)
speechbrain → 语音识别、声纹识别、语音增强等一体化工具包
paddlespeech → 中文语音识别、语音合成(非常适合中文场景)
gradio → 快速搭建 Web 界面演示(方便课堂/实验展示)
在 JupyterLab 里新建一个 Notebook进行测试
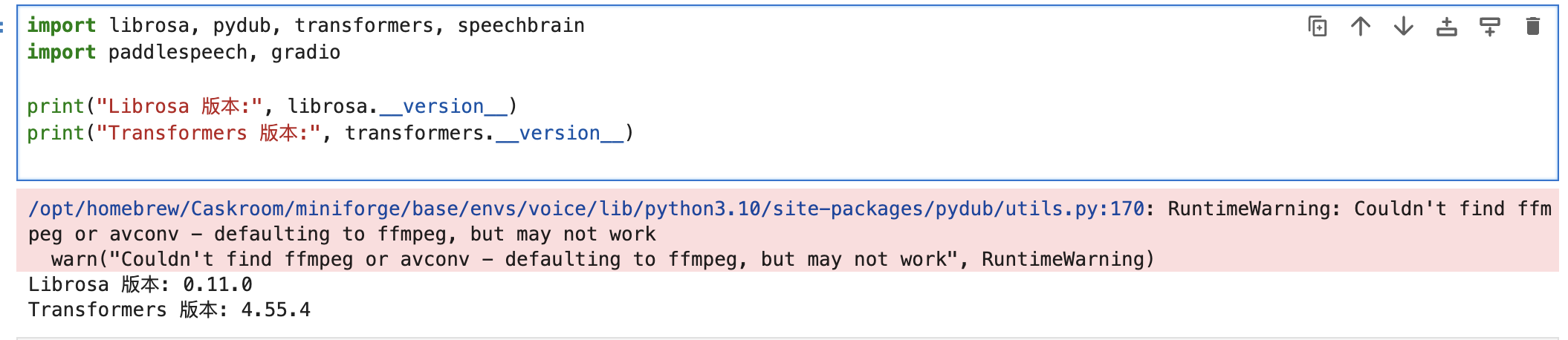
提示:
因为 pydub 依赖于 ffmpeg(或 avconv)来处理音频格式(比如 mp3、wav 转换)。
目前您的环境里没有安装 ffmpeg,所以 pydub 会发出这个警告。
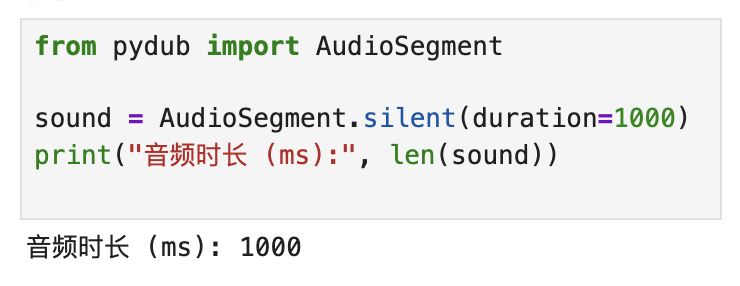
解决办法终端内安装ffmpeg(时间有点小久)
brew install ffmpeg
这个警告不会影响 librosa、transformers 的使用,但会导致 pydub 不能读写 mp3 等格式。
安装好 ffmpeg 以后,pydub 就能处理各种音频格式了(mp3 ↔ wav,剪切、拼接)
第一个小实验录音(sounddevice) → 绘制波形 & 频谱图
首先在voice环境下安装sounddevicede
pip install sounddevice
pip install scipy # 保存为wav文件需要
notebook示例如下:
import sounddevice as sd
from scipy.io.wavfile import write
import librosa, librosa.display
import matplotlib.pyplot as plt
import numpy as np
from pydub import AudioSegment
# 录音参数
duration = 5 # 录音时长(秒)
sample_rate = 16000 # 采样率
print("开始录音,请说话...")
recording = sd.rec(int(duration * sample_rate), samplerate=sample_rate, channels=1, dtype='int16')
sd.wait() # 等待录音结束
print("录音完成!")
# 保存录音为 wav 文件
audio_path = "my_record.wav"
write(audio_path, sample_rate, recording)
print(f"已保存: {audio_path}")
# 用 librosa 加载音频
y, sr = librosa.load(audio_path, sr=None)
print("采样率:", sr)
print("音频时长 (秒):", len(y)/sr)
# 绘制波形
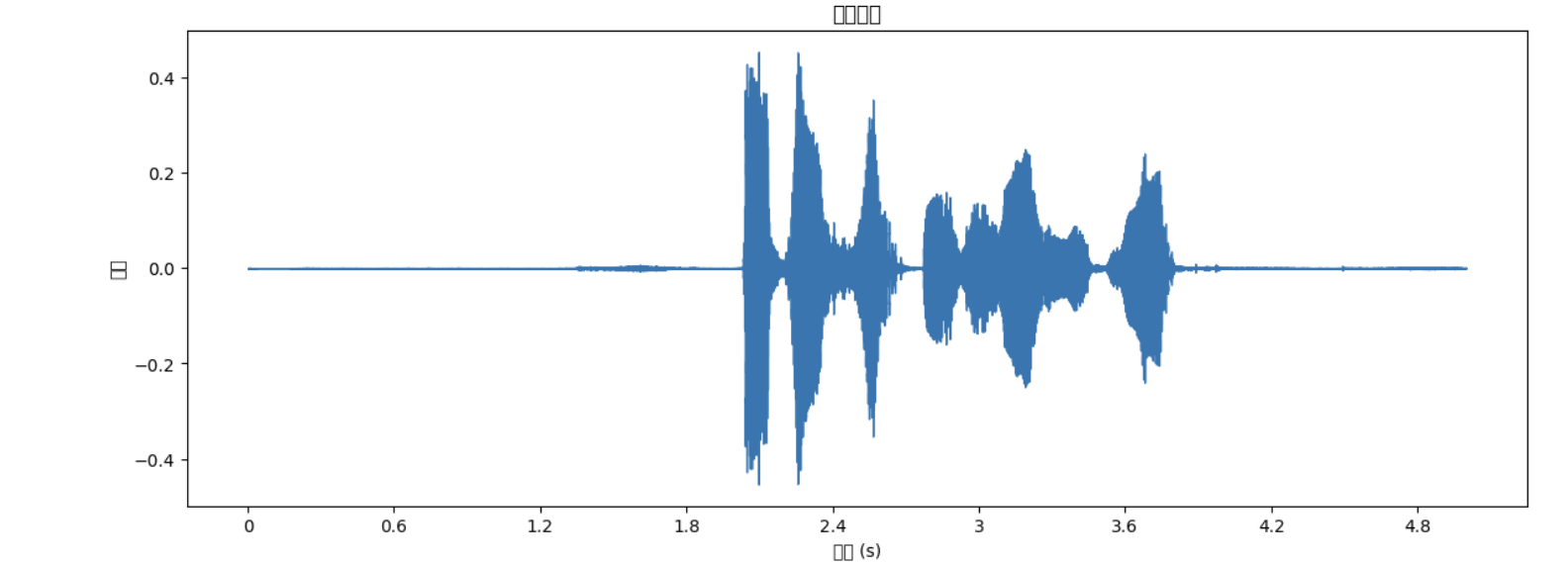
plt.figure(figsize=(14, 5))
librosa.display.waveshow(y, sr=sr)
plt.title("录音波形")
plt.xlabel("时间 (s)")
plt.ylabel("幅度")
plt.show()
# 绘制频谱图
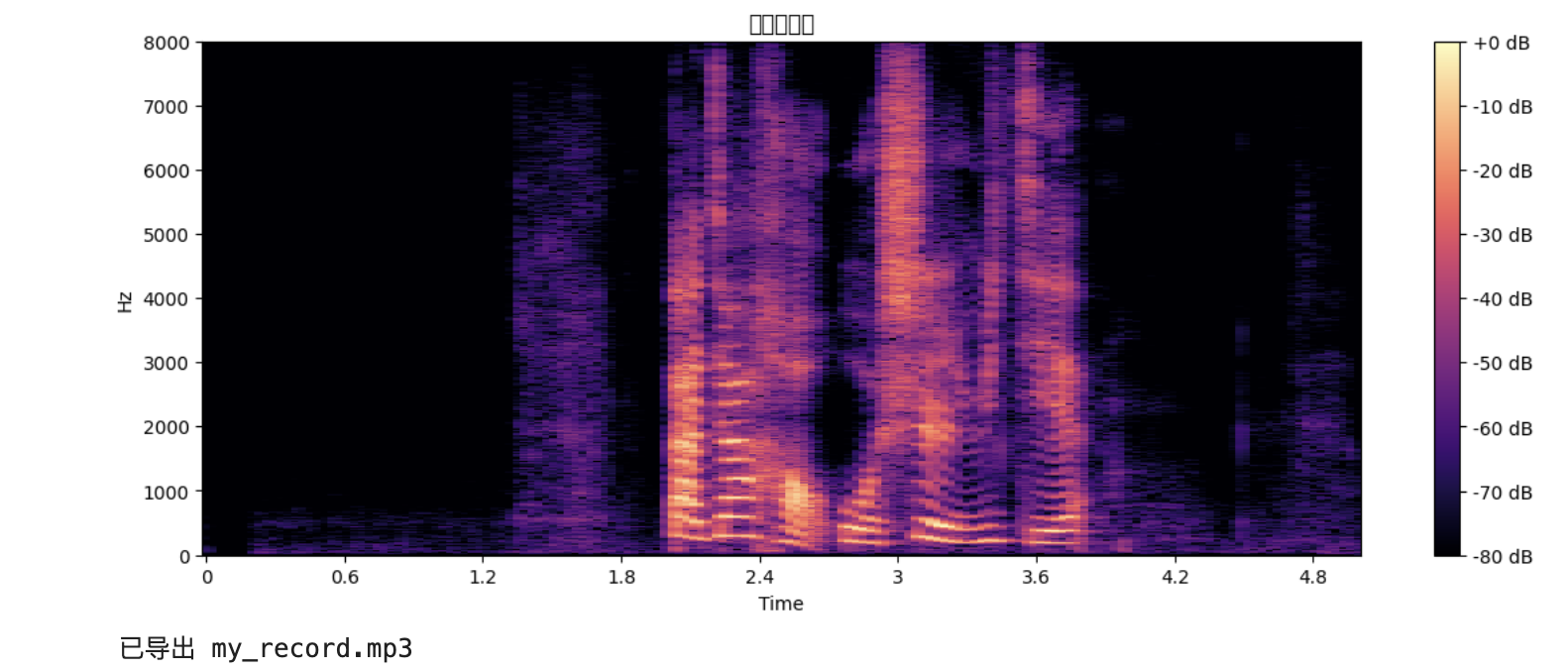
D = np.abs(librosa.stft(y))
DB = librosa.amplitude_to_db(D, ref=np.max)
plt.figure(figsize=(14, 5))
librosa.display.specshow(DB, sr=sr, x_axis="time", y_axis="hz", cmap="magma")
plt.colorbar(format="%+2.0f dB")
plt.title("录音频谱图")
plt.show()
# 使用 pydub 转换格式
sound = AudioSegment.from_file(audio_path, format="wav")
sound.export("my_record.mp3", format="mp3")
print("已导出 my_record.mp3")
运行结果如下:

安装辅助工具
1.音频处理工具,安装 Audacity(开源、跨平台的音频编辑器)
brew install --cask audacity
2.版本控制工具
安装git
brew install git
配置用户名和邮箱:我设置成了和GitHub一致
git config --global user.name "您的名字"
git config --global user.email "您的邮箱"
3.可选,可视化展示工具
Streamlit(可选):另一个好用的快速应用开发框架
pip install streamlit
至此环境配置完成,后续将通过继续学习&实践