文章声明:本内容为个人的业余研究,和任何单位,机构没有关系,文章出现的股票代码,全部只是测试例子,不做投资参考,投资有风险,代码学习使用,不做商业用途
最近在看动量模型,市场常用的2个计算一个是收益,一个是斜率,波动率排序,本身是一样的计算趋势强度,但是这个跟参数的时间有关系,太长的时间调整慢,回撤大,时间参数小,轮动快。回撤小一点,我后面利用我的想法优化一下,控制回撤提高收益
这个是聚合宽的回撤,和pt回撤感觉差别有一点大,我在检测原因
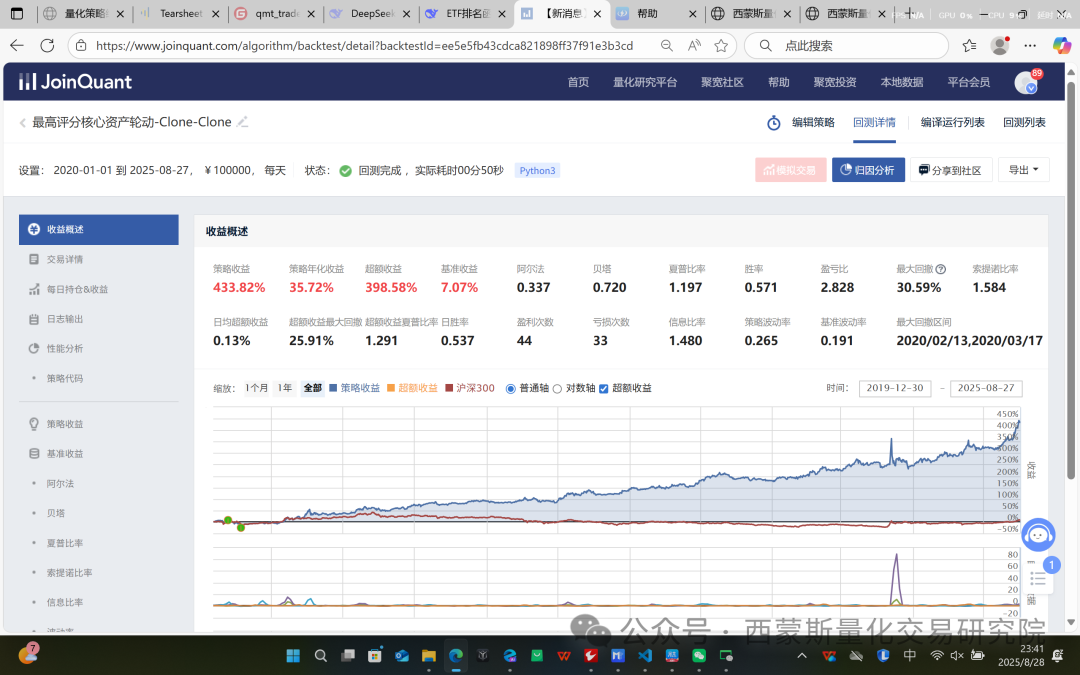
pt的回测数据,我后面优化一下2.0板块
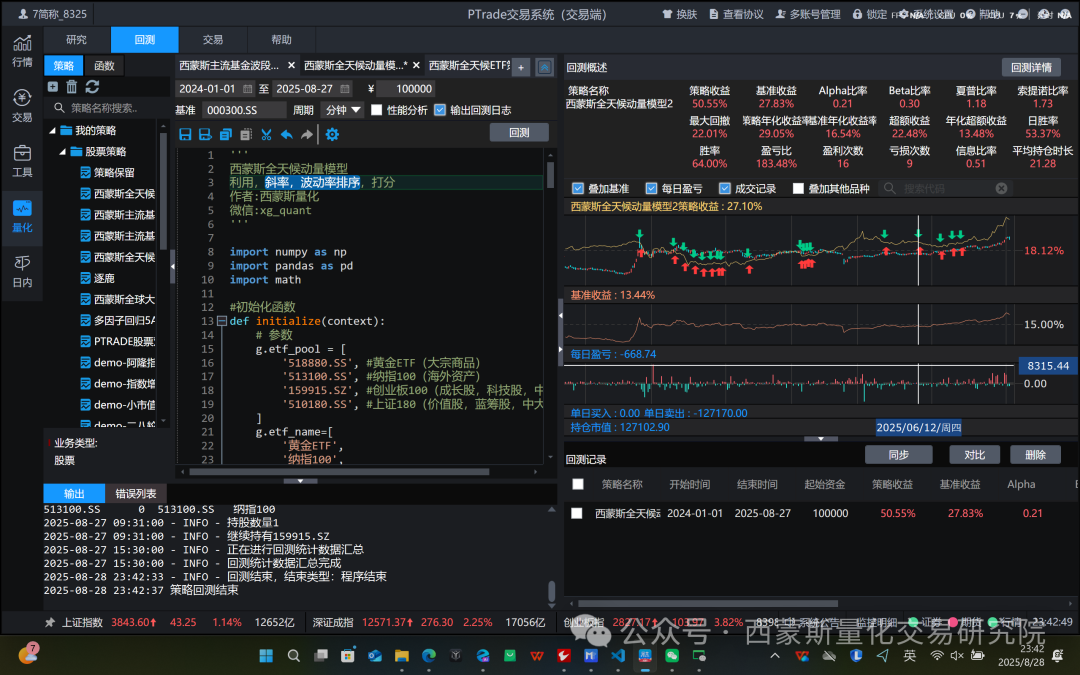
看策略的原理
策略分析:西蒙斯全天候动量模型2
策略概述
“西蒙斯全天候动量模型2”是一个基于动量效应的ETF轮动策略,旨在通过量化指标从多个资产类别中选取趋势最强、最稳定的ETF进行投资。策略的核心思想是结合年化收益率和趋势稳定性(R平方) 来评估ETF的动量质量,从而实现资产配置的优化。该策略每天调仓,确保及时捕捉动量变化,适用于全天候投资环境。
策略组件详细分析
1. 投资标的与资产配置
ETF池:策略覆盖4个主要资产类别,实现分散化投资:
518880.SS(黄金ETF):代表大宗商品,具有避险属性。513100.SS(纳指100ETF):代表海外科技股,增长潜力大。159915.SZ(创业板100ETF):代表国内成长股、科技股和中小盘。510180.SS(上证180ETF):代表国内价值股、蓝筹股和中大盘。
资产覆盖:策略通过这4个ETF覆盖了商品、海外市场、成长股和价值股,降低了单一市场风险,符合“全天候”理念。
2. 动量计算机制(get_rank函数)
数据获取:对于每个ETF,获取过去25天(
g.m_days)的每日收盘价。对数转换:对收盘价取自然对数(
np.log),将价格序列转换为对数空间,更适合线性模型分析。线性回归:使用
np.polyfit进行一元线性回归,拟合时间(自变量x)与对数价格(因变量y)的关系,得到斜率(slope)和截距(intercept)。年化收益率计算:
公式:
annualized_returns = math.pow(math.exp(slope), 250) - 1逻辑:斜率
slope近似每日对数收益率,通过指数化和年化(250个交易日)得到年化收益率。这衡量了ETF的趋势强度。
R平方(R²)计算:
公式:
r_squared = 1 - (sum((y - (slope * x + intercept))**2) / ((len(y) - 1) * np.var(y, ddof=1)))逻辑:R平方衡量回归模型的拟合优度,值越接近1表示趋势越稳定、噪音越小。这衡量了ETF趋势的可靠性。
动量得分:得分 = 年化收益率 × R平方。这个综合指标同时考虑了收益和稳定性,得分高的ETF代表“高质量动量”(即收益高且趋势稳定)。
排序:根据得分从高到低对ETF排序,返回排序后的ETF列表。
3. 交易逻辑(trade函数)
目标持仓:每次只持有得分最高的1个ETF(
target_num = 1),集中投资于最佳动量资产。调仓流程:
卖出:如果当前持有的ETF不在目标列表中,则全部卖出。
买入:如果目标ETF不在当前持仓中,则使用可用现金买入目标ETF(等分现金,但由于只持有一个ETF,所有现金用于买入一个)。
每日执行:策略每天在开盘时(9:30)运行,确保及时捕捉动量变化。
4. 辅助函数
get_xg_account:获取账户信息,包括现金、总资产、持仓价值等,用于资金管理。get_xg_position:获取当前持仓详情,包括股票代码、数量、价格等。get_xg_order:获取委托订单信息,用于监控交易执行。get_xg_position_on:获取特定证券的持仓情况。
策略优点
简单有效:策略逻辑清晰,易于理解和实现。动量因子是市场公认的有效因子。
风险分散:ETF池覆盖多资产类别,减少单一市场风险,符合全天候投资理念。
质量动量:通过R平方过滤噪音,优先选择趋势稳定的ETF,避免高波动资产,可能提高胜率。
及时调仓:每日调仓能快速响应市场变化,捕捉动量转换。
低交易成本:ETF交易成本较低,且调仓频率适中(每日),适合实战。
策略缺点与风险
动量失效风险:动量策略在市场转折点(如趋势反转)可能表现不佳,导致追高杀跌。
参数敏感性:动量窗口(25天)是固定的,可能不适合所有市场环境。不同周期可能导致表现差异。
黑天鹅事件:极端市场事件(如金融危机)可能使动量策略失效,所有资产相关性增加。
单一持仓风险:只持有一个ETF,虽然集中了收益,但也放大了风险。如果该ETF短期回调,策略会遭受损失。
忽略基本面:策略纯技术面驱动,忽略宏观经济和基本面因素,可能在某些环境下失效。
改进建议
动态动量窗口:测试不同动量窗口(如20天、50天)的表现,或使用波动率自适应窗口。
多ETF持仓:考虑持有top 2或top 3 ETF,分散单一持仓风险。
加入止损机制:设置回撤止损,例如当ETF从高点下跌一定比例时卖出,控制下行风险。
结合市场状态:引入市场情绪指标(如VIX)或宏观经济数据,在风险偏好低时减少仓位。
优化资金管理:使用风险平价或波动率加权分配资金,而不是等分现金。
回测验证:在不同市场周期(牛、熊、震荡)进行回测,确保策略稳健性。
总结
“西蒙斯全天候动量模型2”是一个简单但有效的动量轮动策略,通过综合评估收益和趋势稳定性来选择ETF。它适合趋势明显的市场环境,能在资产类别间灵活切换,追求超额收益。然而,策略也存在动量失效和单一持仓风险,投资者应充分回测并结合自身风险偏好使用。总体而言,策略体现了量化投资的核心理念——基于数据驱动决策,实现系统化交易。
详细的内容说明量化研究---年化30%ptrade西蒙斯全天候动量模型![]() https://mp.weixin.qq.com/s/7zZ_dlRnPg7rX-SqXKEmcw
https://mp.weixin.qq.com/s/7zZ_dlRnPg7rX-SqXKEmcw
核心的计算打分函数说明
def get_rank(etf_pool):'''基于年化收益和判定系数打分的动量因子轮动'''score_list = []for etf in etf_pool:print(etf,'**************************')df = get_history(g.m_days, frequency="1d", field="close", security_list=etf )y = df['log'] = np.log(df.close)x = df['num'] = np.arange(df.log.size)slope, intercept = np.polyfit(x, y, 1)annualized_returns = math.pow(math.exp(slope), 250) - 1r_squared = 1 - (sum((y - (slope * x + intercept))**2) / ((len(y) - 1) * np.var(y, ddof=1)))score = annualized_returns * r_squaredscore=round(score)score_list.append(score)df = pd.DataFrame(index=etf_pool, data={'score':score_list})df = df.sort_values(by='score', ascending=False)rank_list = list(df.index)df['证券代码']=df.index.tolist()print(df)df['名称']=df['证券代码'].apply(lambda x:g.name_dict.get(x,x))print(df)return rank_list
该函数的主要目的是对一个给定的ETF基金池进行综合排名。它并非仅仅依据传统的收益率进行排序,而是采用了一个独特的综合评价指标(得分),该指标同时考虑了收益水平和趋势的稳定性与可靠性。最终,函数会按照这个综合得分从高到低返回ETF代码的排名列表。
工作原理分步详解
函数的工作原理可以分解为以下几个核心步骤:
第一步:循环处理每一只ETF
函数接收一个包含多只ETF代码的列表作为输入。然后,它会遍历这个列表,对列表中的每一只ETF单独进行计算和分析。
第二步:获取历史价格数据
对于当前正在处理的ETF,函数会调用一个外部接口(get_history函数),获取该ETF在过去指定天数(g.m_days)内的每日收盘价数据。这些数据是后续所有计算的基础。
第三步:数据预处理与转换
获取到原始价格数据后,函数会进行两项关键的转换,为接下来的数学建模做准备:
对数转换:将每日的收盘价转换为它们的自然对数值。在金融分析中,对数收益率比简单收益率在数学性质上更优越(例如,可加性),并且能更好地消除价格水平本身带来的偏差,使得时间序列更平稳,更适合做线性回归分析。
创建时间序列:生成一个简单的从0开始递增的整数序列,代表每一个交易日。例如,
[0, 1, 2, 3, ..., n]。这个序列将作为线性回归模型中的自变量(X),代表“时间”。
第四步:执行线性回归分析
函数使用一元线性回归模型来拟合经过预处理的数据。它将上一步创建的时间序列(X)作为自变量,将对数价格序列(Y)作为因变量,进行拟合。
拟合的结果会得到两个关键参数:
斜率:回归线的斜率。这个值至关重要,它代表了价格对数随时间变化的平均日增长率。一个正的斜率表示整体上涨趋势,负的斜率则表示下跌趋势。斜率的绝对值越大,趋势越强。
截距:回归线的截距,在本次分析中重要性较低。
第五步:计算年化收益率
将回归得到的斜率(日对数增长率)进行转换,计算出年化收益率。
首先,通过对斜率取指数函数(
math.exp(slope)),将对数日增长率转换回简单的日收益率。然后,基于金融领域通常假设一年有250个交易日,将日收益率复利投资250天,从而得到年化收益率(
(1 + 日收益率)^250 - 1)。这个值代表了如果该ETF保持当前趋势,理论上一年可能获得的收益率。
第六步:计算趋势可靠性(R平方)
为了衡量第五步计算出的收益率是否可靠,函数计算了回归模型的R平方值。
R平方是一个统计学指标,取值范围在0到1之间。它表示因变量(价格对数)的变化中有多大比例可以由自变量(时间)的变化来解释。
R平方值越高(越接近1),说明价格的变化越能用一个清晰的、稳定的时间趋势来解释,模型的拟合度越好,我们对该趋势就越有信心。
R平方值越低(越接近0),说明价格变化更多地是随机波动,而不是一个明确的趋势,之前计算出的高斜率(高收益率)可能只是噪音,并不可靠。
第七步:计算综合得分
这是整个函数最核心的一步。它将收益性和可靠性两个维度结合起来,生成一个综合得分。
综合得分 = 年化收益率 × R平方
设计逻辑:一个理想的投资标的,应该既有高的年化收益率(斜率高),又有高的趋势稳定性(R平方高)。这个乘法公式确保了:
一只收益率极高但波动巨大、趋势不明显的ETF(高收益率 × 低R平方)得分会降低。
一只趋势非常稳定但收益率极低甚至为负的ETF(低收益率 × 高R平方)得分也会降低。
只有那些同时具备较高收益和较高趋势稳定性的ETF,才能获得最高的综合得分。
第八步:结果整理与输出
所有ETF都计算完毕后,函数将所有ETF代码及其对应的综合得分整理成一个表格,并按照得分从高到低进行排序。此外,为了增强结果的可读性,它还将ETF代码转换成了具体的基金名称(从一个预设的字典g.name_dict中查找),并将完整的排名表格打印出来。最终,函数返回排序后的ETF代码列表。
代码我直接给大家学习使用不做商业用途,ptrade的代码,给我点赞转发就可以
'''西蒙斯全天候动量模型利用,斜率,波动率排序,打分作者:西蒙斯量化微信:xg_quant'''import numpy as npimport pandas as pdimport math#初始化函数def initialize(context):# 参数g.etf_pool = ['518880.SS', #黄金ETF(大宗商品)'513100.SS', #纳指100(海外资产)'159915.SZ', #创业板100(成长股,科技股,中小盘)'510180.SS', #上证180(价值股,蓝筹股,中大盘)]g.etf_name=['黄金ETF','纳指100','创业板100','上证180']g.name_dict=dict(zip(g.etf_pool,g.etf_name))g.m_days = 25 #动量参考天数run_daily(context,trade, time='9:30') #每天运行确保即时捕捉动量变化def get_rank(etf_pool):'''基于年化收益和判定系数打分的动量因子轮动'''score_list = []for etf in etf_pool:print(etf,'**************************')df = get_history(g.m_days, frequency="1d", field="close", security_list=etf )y = df['log'] = np.log(df.close)x = df['num'] = np.arange(df.log.size)slope, intercept = np.polyfit(x, y, 1)annualized_returns = math.pow(math.exp(slope), 250) - 1r_squared = 1 - (sum((y - (slope * x + intercept))**2) / ((len(y) - 1) * np.var(y, ddof=1)))score = annualized_returns * r_squaredscore=round(score)score_list.append(score)df = pd.DataFrame(index=etf_pool, data={'score':score_list})df = df.sort_values(by='score', ascending=False)rank_list = list(df.index)df['证券代码']=df.index.tolist()print(df)df['名称']=df['证券代码'].apply(lambda x:g.name_dict.get(x,x))print(df)return rank_list# 交易def trade(context):# 获取动量最高的一只ETFtarget_num = 1target_list = get_rank(g.etf_pool)[:target_num]# 卖出hold_stock=get_xg_position(context)if hold_stock.shape[0]>0:hold_stock=hold_stock[hold_stock['持有数量']>=10]if hold_stock.shape[0]>0:hold_list=hold_stock['证券代码'].tolist()else:hold_list=[]else:hold_list=[]for etf in hold_list:if etf not in target_list:order_target_value(etf, 0)print('卖出' + str(etf))else:print('继续持有' + str(etf))# 买入if len(hold_list) < target_num:value = context.portfolio.cash / (target_num - len(hold_list))for etf in target_list:if etf not in hold_list:order_target_value(etf, value)print('买入' + str(etf))else:print('继续持有' + str(etf))def get_xg_account(context):'''获取小果账户数据'''df=pd.DataFrame()df['可用金额']=[context.portfolio.cash]df['总资产']=[context.portfolio.portfolio_value]df['持仓价值']=[context.portfolio.positions_value]df['已使用现金']=[context.portfolio.capital_used]df['当前收益比例']=[context.portfolio.returns]df['初始账户总资产']=[context.portfolio.pnl]df['开始时间']=[context.portfolio.start_date]return dfdef get_xg_position(context):'''获取小果持股数据'''data=pd.DataFrame()positions=context.portfolio.positionsstock_list=list(set(positions.keys()))print('持股数量{}'.format(len(stock_list)))for stock in stock_list:df=pd.DataFrame()df['证券代码']=[positions[stock].sid]df['可用数量']=[positions[stock].enable_amount]df['持有数量']=[positions[stock].amount]df['最新价']=[positions[stock].last_sale_price ]df['成本价']=[positions[stock].cost_basis ]df['今日买入']=[positions[stock].today_amount ]df['持股类型']=[positions[stock].business_type ]data=pd.concat([data,df],ignore_index=True)'''if data.shape[0]>0:if g.is_del=='是':print('开始策略隔离**********')data['隔离']=data['证券代码'].apply(lambda x: '是' if x in g.stock_list else '不是')data=data[data['隔离']=='是']else:print('不开启策略隔离*********')'''return datadef get_xg_order(context):'''获取小果委托数据'''orders=get_orders()print("委托数量{}".format(len(orders)))data=pd.DataFrame()if len(orders)>0:for ors in orders:df=pd.DataFrame()df['订单号']=[ors.id]df['订单产生时间']=[ors.dt]df['指定价格']=[ors.limit ]df['证券代码']=[ors.symbol ]df['委托数量']=[ors.amount ]df['订单生成时间']=[ors.created ]df['成交数量']=[ors.filled ]df['委托编号']=[ors.entrust_no]df['盘口档位']=[ors.priceGear ]df['订单状态']=[ors.status ]data=pd.concat([data,df],ignore_index=True)else:data=datareturn datadef get_xg_position_on(context,security=''):''''获取单股的持股情况'''pos=get_positions(security=security)df=pd.DataFrame()if len(pos)>0:df['证券代码']=[pos[security].sid]df['可以数量']=[pos[security].enable_amount]df['持有数量']=[pos[security].amount]df['最新价']=[pos[security].last_sale_price ]df['成本价']=[pos[security].cost_basis ]df['今日买入']=[pos[security].today_amount ]df['持股类型']=[pos[security].business_type ]else:df=dfreturn df'''聚宽源代码# 克隆自聚宽文章:https://www.joinquant.com/post/42673# 标题:【回顾3】ETF策略之核心资产轮动# 作者:wywy1995import numpy as npimport pandas as pd#初始化函数def initialize(context):# 设定基准set_benchmark('000300.XSHG')# 用真实价格交易set_option('use_real_price', True)# 打开防未来函数set_option("avoid_future_data", True)# 设置滑点 https://www.joinquant.com/view/community/detail/a31a822d1cfa7e83b1dda228d4562a70set_slippage(FixedSlippage(0.000))# 设置交易成本set_order_cost(OrderCost(open_tax=0, close_tax=0, open_commission=0.0002, close_commission=0.0002, close_today_commission=0, min_commission=5), type='fund')# 过滤一定级别的日志log.set_level('system', 'error')# 参数g.etf_pool = ['518880.XSHG', #黄金ETF(大宗商品)'513100.XSHG', #纳指100(海外资产)'159915.XSHE', #创业板100(成长股,科技股,中小盘)'510180.XSHG', #上证180(价值股,蓝筹股,中大盘)]g.m_days = 25 #动量参考天数run_daily(trade, '9:30') #每天运行确保即时捕捉动量变化# 基于年化收益和判定系数打分的动量因子轮动 https://www.joinquant.com/post/26142def get_rank(etf_pool):score_list = []for etf in etf_pool:df = attribute_history(etf, g.m_days, '1d', ['close'])y = df['log'] = np.log(df.close)x = df['num'] = np.arange(df.log.size)slope, intercept = np.polyfit(x, y, 1)annualized_returns = math.pow(math.exp(slope), 250) - 1r_squared = 1 - (sum((y - (slope * x + intercept))**2) / ((len(y) - 1) * np.var(y, ddof=1)))score = annualized_returns * r_squaredscore_list.append(score)df = pd.DataFrame(index=etf_pool, data={'score':score_list})df = df.sort_values(by='score', ascending=False)rank_list = list(df.index)print(df)record(黄金 = round(df.loc['518880.XSHG'], 2))record(纳指 = round(df.loc['513100.XSHG'], 2))record(成长 = round(df.loc['159915.XSHE'], 2))record(价值 = round(df.loc['510180.XSHG'], 2))return rank_list# 交易def trade(context):# 获取动量最高的一只ETFtarget_num = 1target_list = get_rank(g.etf_pool)[:target_num]# 卖出hold_list = list(context.portfolio.positions)for etf in hold_list:if etf not in target_list:order_target_value(etf, 0)print('卖出' + str(etf))else:print('继续持有' + str(etf))# 买入hold_list = list(context.portfolio.positions)if len(hold_list) < target_num:value = context.portfolio.available_cash / (target_num - len(hold_list))for etf in target_list:if context.portfolio.positions[etf].total_amount == 0:order_target_value(etf, value)print('买入' + str(etf))'''
聚宽的回测代码
# 克隆自聚宽文章:https://www.joinquant.com/post/42673# 标题:【回顾3】ETF策略之核心资产轮动# 作者:wywy1995import numpy as npimport pandas as pd#初始化函数def initialize(context):# 设定基准set_benchmark('000300.XSHG')# 用真实价格交易set_option('use_real_price', True)# 打开防未来函数set_option("avoid_future_data", True)# 设置滑点 https://www.joinquant.com/view/community/detail/a31a822d1cfa7e83b1dda228d4562a70set_slippage(FixedSlippage(0.000))# 设置交易成本set_order_cost(OrderCost(open_tax=0, close_tax=0, open_commission=0.0002, close_commission=0.0002, close_today_commission=0, min_commission=5), type='fund')# 过滤一定级别的日志log.set_level('system', 'error')# 参数g.etf_pool = ['518880.XSHG', #黄金ETF(大宗商品)'513100.XSHG', #纳指100(海外资产)'159915.XSHE', #创业板100(成长股,科技股,中小盘)'510180.XSHG', #上证180(价值股,蓝筹股,中大盘)]g.m_days = 25 #动量参考天数run_daily(trade, '9:30') #每天运行确保即时捕捉动量变化# 基于年化收益和判定系数打分的动量因子轮动 https://www.joinquant.com/post/26142def get_rank(etf_pool):score_list = []for etf in etf_pool:df = attribute_history(etf, g.m_days, '1d', ['close'])y = df['log'] = np.log(df.close)x = df['num'] = np.arange(df.log.size)slope, intercept = np.polyfit(x, y, 1)annualized_returns = math.pow(math.exp(slope), 250) - 1r_squared = 1 - (sum((y - (slope * x + intercept))**2) / ((len(y) - 1) * np.var(y, ddof=1)))score = annualized_returns * r_squaredscore_list.append(score)df = pd.DataFrame(index=etf_pool, data={'score':score_list})df = df.sort_values(by='score', ascending=False)rank_list = list(df.index)print(df)record(黄金 = round(df.loc['518880.XSHG'], 2))record(纳指 = round(df.loc['513100.XSHG'], 2))record(成长 = round(df.loc['159915.XSHE'], 2))record(价值 = round(df.loc['510180.XSHG'], 2))return rank_list# 交易def trade(context):# 获取动量最高的一只ETFtarget_num = 1target_list = get_rank(g.etf_pool)[:target_num]# 卖出hold_list = list(context.portfolio.positions)for etf in hold_list:if etf not in target_list:order_target_value(etf, 0)print('卖出' + str(etf))else:print('继续持有' + str(etf))# 买入hold_list = list(context.portfolio.positions)if len(hold_list) < target_num:value = context.portfolio.available_cash / (target_num - len(hold_list))for etf in target_list:if context.portfolio.positions[etf].total_amount == 0:order_target_value(etf, value)print('买入' + str(etf))