九、索引
1、索引结构
2、索引分类
3、索引语法
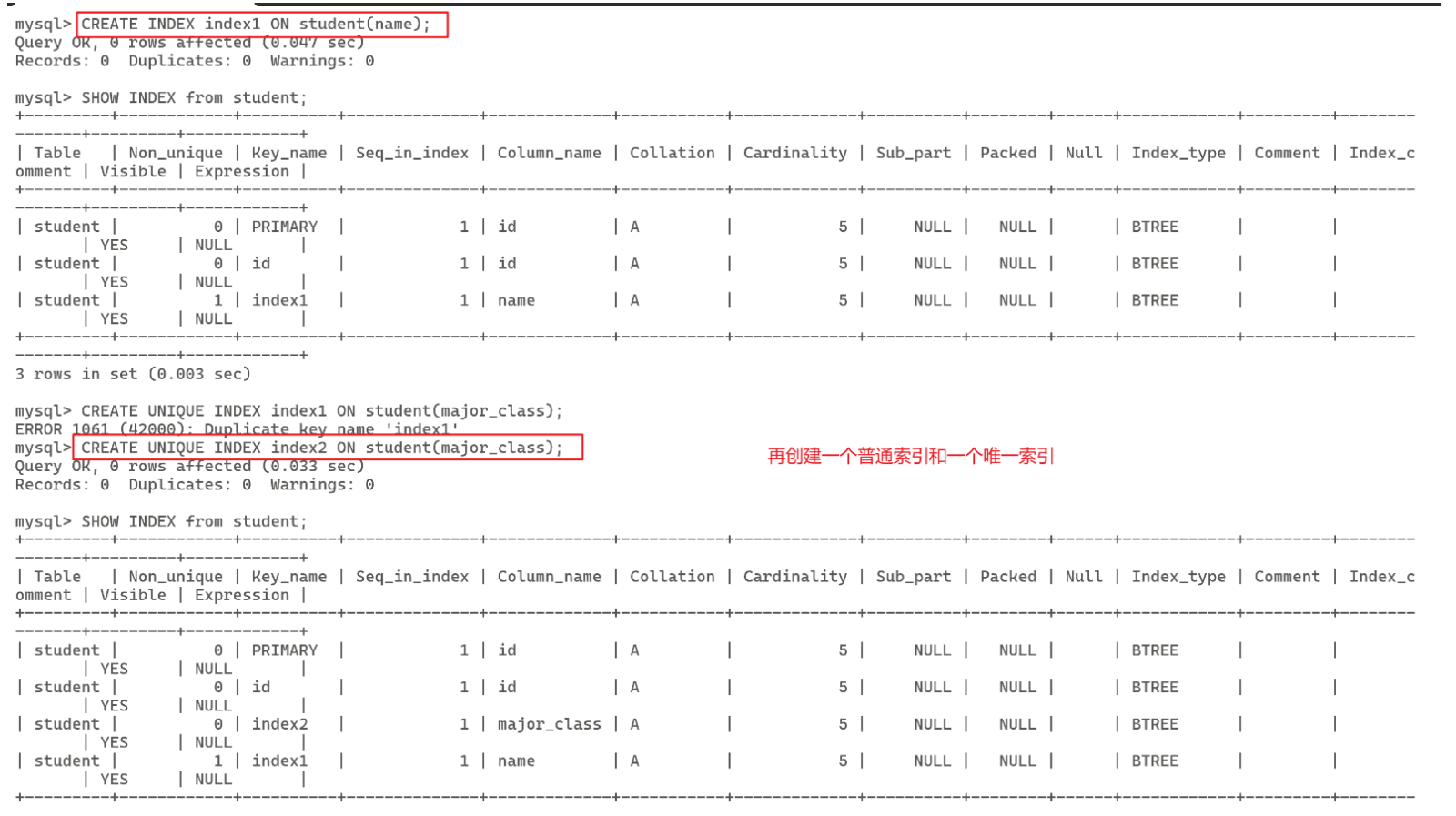
# 1、创建索引
# 创建普通索引(INDEX)
CREATE INDEX index_name ON table_name (column_name);
# 创建唯一索引(UNIQUE)
CREATE UNIQUE INDEX unique_index_name ON table_name (column_name);
# 创建全文索引(FULLTEXT)
CREATE FULLTEXT INDEX fulltext_index_name ON table_name (column_name);
# 创建多列索引
CREATE INDEX index_name ON table_name (column1_name, column2_name);
# 2、查看索引
SHOW INDEX FROM table_name;
# 3、删除索引
DROP INDEX index_name ON table_name;给出演示案例,不需要修改字段我使用大写,需要修改字段(如表名、索引名)我使用小写


4、性能分析
①、慢查询
# 使用语句查看当前使用频繁的操作
show global status like 'Com_______'; # 七个下划线
# 一般来说都是查询操作比较频繁,故我们可使用慢查询进行选择优化,记录哪些操作时间超过慢查询设置的阈值,之后对其进行性能优化即可。
# 默认情况下 MySQL 的慢查询是关闭状态(OFF)
# 查看当前慢查询开关
SHOW VARIABLES LIKE 'slow_query_log';
# 方法(临时生效,重启容器后失效)1、
# 打开慢查询日志
SET GLOBAL slow_query_log = 'ON';
# 设置慢查询阈值为 1 秒
SET GLOBAL long_query_time = 1;
# 方法(重启容器后永久生效)2、
# 编辑 MySQL 的配置文件(存储在/etc/my.cnf)
vi /etc/my.cnf
# 加入以下内容:
slow_query_log = 'ON';
long_query_time = 1;
# 重启容器
docker restart <你的MySQL容器名>
-- 指定慢日志文件路径(可选,MySQL 会自动放在数据目录下)
-- 示例:Linux 默认路径 /var/lib/mysql/localhost-slow.log
-- Windows 默认路径 MySQL\data\hostname-slow.log
-- 若想自定义路径,需要 MySQL 对该路径有写权限
-- SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
# 实时查看查看慢查询日志
sudo tail -f /var/lib/mysql/localhost-slow.log
-- 把未使用索引的查询也记录到慢日志(可选)
SET GLOBAL log_queries_not_using_indexes = 'ON';
# 给出一份测试文件
-- 测试表
CREATE TABLE IF NOT EXISTS test_slow (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
val VARCHAR(200),
rand INT
);
-- 插入 100 万条随机数据(约 10~20 秒完成)
DELIMITER $$
CREATE PROCEDURE insert_test_rows()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000000 DO
INSERT INTO test_slow(val, rand)
VALUES (MD5(RAND()), FLOOR(RAND()*1000000));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL insert_test_rows();②、profile
# show profile 可以帮助我们查看执行的 SQL 语句耗费时间的去向
# 查看当前 MySQL 是否支持 profile 操作
SELECT @@have_profiling;
# 查看当前 profile 操作是否打开
# MySQL 默认 profile 是0,即关闭状态
SELECT @@profiling;
# 打开 profile 为1,即开启状态
SET profiling = 1;
# profile详情,执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
# 查看每一条SQL的耗时基本情况
SHOW PROFILES;
# 查看指定 query_id 的SQL语句各个阶段的耗时情况
SHOW PROFILE FOR QUERY query_id;
# 查看指定 query_id 的SQL语句CPU的使用情况
SHOW PROFILE CPU FOR QUERY query_id;③、explain
# 通过 explain 可以查看其执行计划
# 在查询语句前加上 explain 或 desc 即可
EXPLAIN SELECT <要搜寻的字段名> FROM <表名>;
# eg:
EXPLAIN SELECT name,course_name FROM student,sc,course
WHERE student.id = sc.id AND course.course_id = sc.course_id;EXPLAIN 执行计划各字段含义:
Ⅰ、id
select 查询的序列号,表示查询中执行 select 子句或操作表的顺序。
id 相同:执行顺序从上到下;
id 不同:值越大,越先执行。
Ⅱ、select_type
SELECT 的类型,常见取值:
SIMPLE:简单表(不使用连接或子查询);
PRIMARY:主查询(最外层查询);
UNION:UNION 中第二个或后续查询语句;
SUBQUERY:SELECT/WHERE 后包含的子查询等。
Ⅲ、type
连接类型,性能由好到差:
NULL > system > const > eq_ref > ref > range > index > all。
Ⅳ、possible_keys
可能应用在该表上的索引,一个或多个。
Ⅴ、key
实际使用的索引;为 NULL 表示未使用索引。
Ⅵ、key_len
索引使用的字节数(字段最大可能长度,非实际长度),越短越好。
Ⅶ、rows
MySQL 估算需要扫描的行数(InnoDB 中为估计值)。
Ⅷ、filtered
返回结果行数占读取行数的百分比,值越大越好。
实操举例:

5、索引使用
在之前给出的插入 100 万条随机数据的测试文件中,通过id查询,速度较快,因为我们在创建表时设置了id为主键,即id有索引帮助其查询,之后我们再通过val进行查询,速度明显变慢,这是因为我们的val没有创建索引。我们可以通过添加索引(耗时30s左右,这是在创建B+树结构)来提高我们通过val进行查询的效率。
以上说明:索引可有效提高搜索效率
①、最左前缀法则
最左前缀法则(Leftmost Prefix Rule)是联合索引(复合索引)在 MySQL 中生效的铁律:
只有在查询条件中从联合索引的最左侧列开始连续匹配,索引才会被使用。
注意只要含最左侧即可,不一定最左侧要在第一个
# 联合索引示例
CREATE INDEX idx_a_b_c ON table(col_a, col_b, col_c);| 查询条件 | 是否命中 idx_a_b_c | 理由 |
|---|---|---|
WHERE col_a = 1 |
✅生效 | 从最左列开始 |
WHERE col_b = 2 AND col_a = 1 |
✅生效 | 连续匹配前2列 |
WHERE col_c = 3 AND col_a = 1 AND col_b = 2 |
✅生效 | 连续匹配全部3列 |
WHERE col_a = 1 AND col_c = 3 |
部分生效 | 仅 col_a 部分生效(col_c 跳过 col_b) |
| 查询条件 | 是否命中 | 理由 |
|---|---|---|
WHERE col_b = 2 |
❌不生效 | 未从最左列 col_a 开始 |
WHERE col_b = 2 AND col_c = 3 |
❌不生效 | 缺少最左列 col_a |
WHERE col_c = 3 |
❌不生效 | 缺少最左列 col_a |
②、范围查询
范围查询(如 >、<、BETWEEN)会中断后续列的索引使用
WHERE col_a = 1 AND col_b > 10 AND col_c = 3;
# col_a 和 col_b 部分生效,但 col_c 无法使用索引(因 col_b 是范围查询)
# 建议在业务允许范围内使用>=/<=,不会导致索引失效③、模糊查询
使用模糊查询(%、_)如果是在前面使用则会中断后续列的索引使用,只有后面使用不会中断。
# 前面使用(示例:以轩结尾)—————— 索引失效
SELECT * FROM <表名> WHERE name like '%轩'
# 后面使用(示例:以张开头)—————— 索引不失效
SELECT * FROM <表名> WHERE name like '张%'
# 前后面均使用(示例:名字中带王)—————— 索引失效
SELECT * FROM <表名> WHERE name like '%王%'④、or查询
当使用or时,如果两边都是有索引则最终使用索引进行查询,如果有一边没有索引,则走全表扫描
⑤、数据分布
当MySQL认为使用索引不如全表扫描效率高,则即使有索引也会使用全表扫描,这是由于复合要求的数据较多,即全表大部分数据都复合搜索要求,此时认为使用索引并不能有效提高效率。
⑥、SQL提示
SQL 提示”(SQL Hint) 指的是人为干预优化器的执行计划,强制 SQL 按照我们期望的方式走索引、选择连接方式或忽略缓存等
# 建议 SQL 优化器使用 PRIMARY INDEX(可拒绝)
SELECT * FROM student USE INDEX (PRIMARY) WHERE id = '1' ;
# 建议 SQL 优化器忽略 PRIMARY INDEX(可拒绝)
SELECT * FROM student IGNORE INDEX (PRIMARY) WHERE id = '1' ;
# 强制 SQL 优化器使用 PRIMARY INDEX(不可拒绝)
SELECT * FROM student FORCE INDEX (PRIMARY) WHERE id = '1' ;⑦、覆盖索引
覆盖索引 是一种 使用状态:只要索引里列够用,就不回表;它既可以是聚集索引(主键),也可以是二级索引。
即建议创建的联合索引(二级索引的一种)包含所要查找的数据,就不回表查询,否则会查到主键后回表。
如:
# 创建联合索引 idx_a_b_c
CREATE INDEX idx_a_b_c ON table(col_a, col_b, col_c);
SELECT a,b,c FROM <表名> WHERE <条件>;
# 此时要查询的 a,b,c 包含在联合索引内,故不回表
SELECT a,b,c,d FROM <表名> WHERE <条件>;
# 此时要查询的 a,b,c 包含在联合索引内,但是 d 不在,故要通过联合索引找到主键,通过主键回表查询 d⑧、前缀索引
前缀索引(Prefix Index)是 MySQL 中一种只对字符串列的前 N 个字符(或前 N 个字节)建立索引的技术,目的是:
大幅减小索引体积
降低磁盘/内存占用
提升写入与缓存效率
# 创建前缀索引
-- 普通前缀索引
ALTER TABLE tbl ADD INDEX idx_col_prefix (col(N));
CREATE INDEX idx_col_prefix ON TABLE tbl(col(N));
-- 唯一前缀索引
ALTER TABLE tbl ADD UNIQUE uk_col_prefix (col(N));
CREATE UNIQUE INDEX uk_col_prefix ON TABLE tbl(col(N));
# 在“足够区分度”与“最小长度”之间平衡以选择合适的前缀长度 N
# 计算整体区分度
SELECT COUNT(DISTINCT email) / COUNT(*) AS full_selectivity FROM user;⑨、单列索引和联合索引
单列索引:只对 一列 建索引。
联合索引:对 多列组合 建一个索引,内部按 最左前缀法则 工作。
单列查询够用就不使用联合索引,组合查询才使用联合索引;联合索引遵循最左前缀法则,跳列就失效
6、索引设计原则
针对于数据量较大,且查询比较频繁的表建立索引。
针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
十、SQL优化
1、插入数据
# 优化1、批量插入
INSERT INTO tb_test VALUES(1,'Tom'),(2,'Cat'),(3,'Jerry');
# 优化2、手动插入事务
START TRANSACTION;
INSERT INTO tb_test VALUES(1,'Tom'),(2,'Cat'),(3,'Jdny');
INSERT INTO tb_test VALUES(4,'Tom'),(5,'Cat'),(6,'Jerry');
INSERT INTO tb_test VALUES(7,'Tom'),(8,'Cat'),(9,'Jerry');
COMMIT;
# 优化3、主键顺序插入
# 主键乱序插入:8 1 9 21 88 2 4 15 89 5 7 3
# 主键顺序插入:1 2 3 4 5 7 8 9 15 21 88 89,效率高于乱序插入
# 优化4、load插入
# 适用与大批量数据(几十万,几百万)
# 客户端连接服务端时,加上参数 --local-infile
mysql --local-infile -u root -p
# 设置全局参数 local_infile 为 1(默认是0关闭状态),开启从本地加载文件导入数据的开关
set global local_infile = 1;
# 将数据上传到本地,如/root/sql1.log该路径下
# 执行 load 指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table `<你要插入的表>` fields terminated by ',' lines terminated by '\n';2、主键优化
①、主键设计原则
唯一性:
主键必须唯一标识表中的每一行,不能有重复值。
非空性:
主键字段不能包含 NULL 值。
稳定性:
主键的值不应频繁更改。如果业务逻辑需要更改主键(如用户ID),考虑使用唯一标识符(如 UUID)。
简单性:
尽量选择简单、固定长度的字段作为主键,以减少存储空间和提高处理速度。
相关性:
主键应与表中其他字段具有一定的相关性,以优化查询性能。
单一性:
一个表只能有一个主键。
连续性:
尽量选择连续存储的字段作为主键,以提高数据页的缓存效率。
索引覆盖:
考虑查询中经常一起使用的字段组合可以作为联合索引,覆盖索引可以减少回表次数。
前缀索引:
对于长字符串类型,考虑使用前缀索引以减少索引大小。
避免使用自然主键:
如果没有明显的业务键,考虑使用自增序列或 UUID 作为主键。
②、主键顺序和乱序插入
Ⅰ、顺序插入
前一个页满了,开辟新的页顺序插入
Ⅱ、乱序插入
前一个页满了,开辟新的页,取出前一个页的一半加入到新开辟的页中,将要插入的字段也插入新的页,再调换列表顺序即可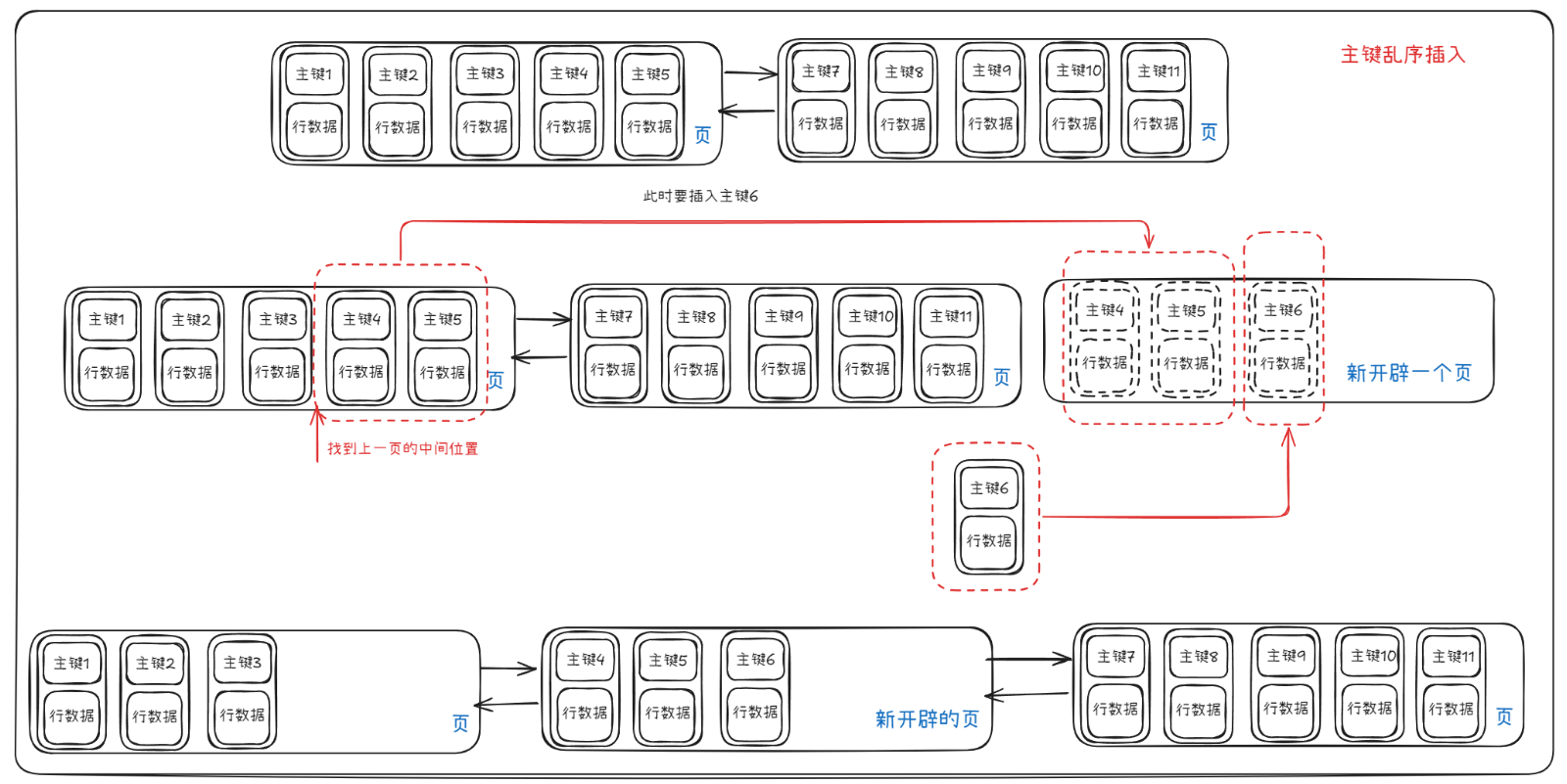
3、order by 优化
①. Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区 sort buffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
②. Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
-- 没有创建索引时,根据 age, phone 进行排序
# Using filesort
EXPLAIN SELECT id, age, phone FROM tb_user ORDER BY age, phone;
-- 创建索引
CREATE INDEX idx_user_age_phone_aa ON tb_user(age, phone);
-- 创建索引后,根据 age, phone 进行升序排序
# Using index
EXPLAIN SELECT id, age, phone FROM tb_user ORDER BY age, phone;
-- 创建索引后,根据 age, phone 进行降序排序
# Using index
EXPLAIN SELECT id, age, phone FROM tb_user ORDER BY age DESC, phone DESC;
-- 根据 age, phone 进行降序一个升序,一个降序
# Using filesort + Using index
EXPLAIN SELECT id, age, phone FROM tb_user ORDER BY age ASC, phone DESC;
-- 创建索引
CREATE INDEX idx_user_age_phone_ad ON tb_user(age ASC, phone DESC);
-- 根据 age, phone 进行降序一个升序,一个降序
# Using index
EXPLAIN SELECT id, age, phone FROM tb_user ORDER BY age ASC, phone DESC;根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
尽量使用覆盖索引。
多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
如果不可避免的出现 filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)。
4、group by优化
group by 的优化也是通过建立联合索引(覆盖索引)来进行提高查询效率
5、limit优化
limit分页查询时,数据量越大,想查询的数据越靠后效率越低
可使用覆盖索引+子查询的方法
如:查询2000000-2000010的数据
# 获取2000000-2000010的数据的主键id
# 得到表b
SELECT id FROM <表A名> limit 2000000,10;
# 获取对应id的数据
SELECT <表A名>.* FROM <表A名> WHERE <表A名>.id = b.id
# 整合
SELECT a.* FROM <表A名> a, (SELECT id FROM <表A名> limit 2000000,10) b WHERE a.id = b.id;6、count优化
count 的几种用法
null则不加,非null,count+1
①、count(主键)
InnoDB 引擎会遍历整张表,把每一行的主键 id 值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为 null)。
②、count(字段)
没有 not null 约束:InnoDB 引擎会遍历整张表,把每一行的字段值都取出来,返回给服务层,服务层判断是否为 null,不为 null,计数累加。
有 not null 约束:InnoDB 引擎会遍历整张表,把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
③、count(1)
InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数学“1”进去,直接按行进行累加。
④、count(*)
InnoDB 引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
效率:count(*)约等于count(1)>count(主键)>count(字段)
建议多使用count(*)
7、update优化
MySQL默认适用InnoDB引擎,InnoDB的行锁是针对索引的而不是记录,且该索引不可失效,否则行锁会升级为表锁,导致性能降低,操作失败。
即更新数据时必须要有未失效的索引,否则会导致行锁升级为表锁,进而操作性能降低。