mysql命令行导出csv文件时,若字段里有换行符,输出的文件就会在换行符前面加一个反斜杠,这种非标准的csv导入到excel也乱行了。网上查了好多文章,都建议在相应的字段上加replace函数,把换行符替换成特殊标记,这显然是非常笨的做法,无法通用,特别是无法预测哪个字段会有换行符的。所以我的做法是:
1、导出csv时,给字符型字段值加上双引号
mysql --defaults-extra-file=~/.10.16.32.9.my.cnf -h 10.16.32.9 -P 13306 -e "select t.* from loan.loan_partner t INTO OUTFILE '/tmp/loan_partner.csv' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' ESCAPED BY '\\\' LINES TERMINATED BY '\n'"
这样导出的文件里有几个问题,一是mysql会把换行符前加一个反斜杠。二是双引号前面也是加了反斜杠,要变成标准的csv就需要修正。
2、用sed把Csv中“反斜杠+换行符”恢复成“换行符”,把“反斜杠+双引号”也替换成两个双引号
sed -i "s/\\\\$/\n/g" loan_partner.csv
sed -i "s/\\\\\"/\"\"/g" loan_partner.csv
这时就已经符合csv标准了,再用excel打开,就不会有乱行的问题。
如图:
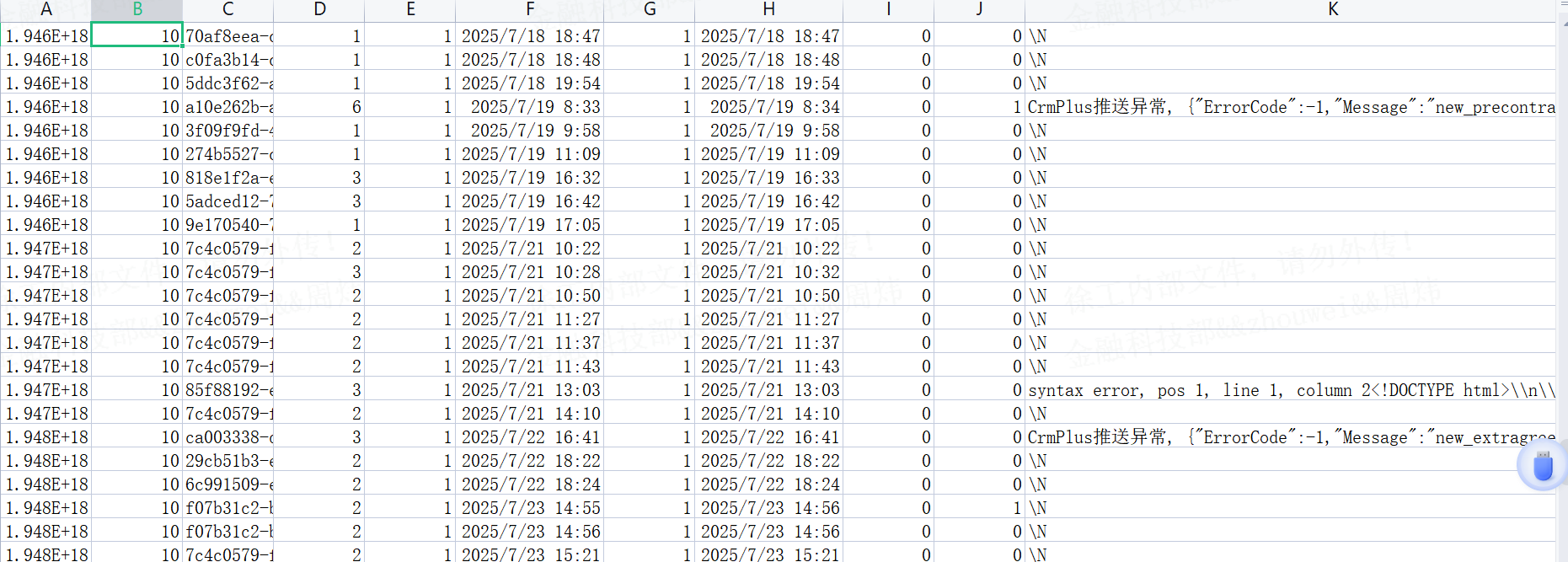
图中\N代表null值,也可以替换成空串。
对这个标准的csv如果要导入出hive中,再参考我另一篇就可以解决了:
https://blog.csdn.net/weixin_45357522/article/details/150390071
另外,hive在csv标准方面兼容性不好,如果字段里有逗号,或双引号,就得前面加反斜杠转义,而标准csv字段值用双引号括起来之后,如果字段里有双引号则在双引号前面再加一个双引号就可以了,逗号不需要转义了。所以导入hive的处理方法为:
echo "3.2 字段中的'\+换行符'恢复成换行符"
sed -i "s/\\\\$/\n/g" ~/${tableName}.csv
echo "3.3 字段中的'\+双引号'替换成两个双引号"
sed -i "s/\\\\\"/\"\"/g" ~/${tableName}.csv
echo "3.4 字段中的'\N'替换成空"
sed -i "s/\\\\N//g" ~/${tableName}.csv
echo "3.5 字段中的换行符替换成\n"
python3 /data/dolphinscheduler/removeInColNewLine.py ~/${tableName}.csv
上面的第5步作用请看:
https://blog.csdn.net/weixin_45357522/article/details/150390071