论文题目:LightThinker: Thinking Step-by-Step Compression
论文来源:EMNLP 2025,CCF B
论文作者:

论文链接:https://arxiv.org/abs/2502.15589
论文源码:https://github.com/zjunlp/LightThinker
一、摘要
大语言模型(LLMs)在复杂推理任务中展现出卓越性能,但其效率受到生成冗长token所带来的巨大内存和计算开销的严重制约。本文提出了一种新颖的方法——LightThinker,使LLMs能够在推理过程中动态压缩中间思维步骤。受人类认知过程启发,LightThinker将冗长的推理链压缩为紧凑的表示,并丢弃原始推理链,从而显著减少上下文窗口中存储的token数量。该方法通过以下方式实现:构建训练数据以指导模型学习何时以及如何压缩;将隐藏状态映射为少量“gist token”;并设计专门的注意力掩码。此外,我们引入了依赖度(Dependency, Dep)指标,用于通过衡量生成过程中对历史token的依赖程度来量化压缩效果。我们在两个模型和四个数据集上进行了大量实验,结果表明,LightThinker在保持竞争力的准确率的同时,显著降低了峰值内存使用和推理时间。本研究为在不牺牲性能的前提下提升 LMs在复杂推理任务中的效率提供了新的方向。
二、Introduction(简洁版)
问题:“慢思考”虽提升推理准确率,却生成大量中间token,导致KV缓存爆炸、推理延迟飙升。
动机:受人类“只写关键步骤、脑中压缩其余”启发,让模型边推理边压缩,兼顾性能与效率。
方法(提出LightThinker):
- 数据层面:插入特殊token教会模型何时压缩;
- 模型层面:用gist token隐藏状态压缩思维链;
- 训练层面:设计注意力掩码实现压缩与继续推理的解耦;
- 评估层面:引入Dep指标量化压缩程度。
贡献:
- 首次提出“动态压缩推理链”的端到端方法;
- 在4个数据集、2个模型上验证:峰值token↓70%,推理时间↓26%,准确率仅↓1%;
- 提供新的LLM推理加速思路,兼顾效率与性能。
三、相关工作
当前加速LLM推理的研究主要集中在三类方法:模型量化、减少生成token数量,以及缩减KV缓存。模型量化包括参数量化(Lin et al., 2024)和KV缓存量化(Liu et al., 2024b)。值得注意的是,生成长文本与理解长文本是两种不同场景,因此专门针对“预填充阶段”的加速技术(如 AutoCompressor、ICAE、LLMLingua、Activation Beacon、SnapKV、PyramidKV 等)本文不作讨论。受篇幅限制,以下重点介绍后两类方法。
3.1 减少生成token数量
- 离散token缩减:通过提示工程(Han et al., 2024)、指令微调(Liu et al., 2024a)或强化学习(Arora & Zanette, 2025)引导模型在推理时使用更少的离散token。
- 连续token替代:用连续空间的向量代替离散词表token(如 CoConut)。
- 零token推理:把推理过程内化到模型层间,直接生成最终答案(Deng et al., 2023, 2024)。
这三种策略无需推理时额外干预,但加速效果越好,模型泛化性能下降越明显,且第一种对显存节省有限。
3.2 缩减KV缓存
- 基于剪枝的策略:为每个token设计显式淘汰规则,保留重要token(StreamingLLM、H2O、SepLLM)。
- 基于融合的策略:引入anchor token,训练模型把历史关键信息压缩进这些token,实现KV缓存融合(AnLLM)。
二者均需推理时干预;区别在于前者无需训练却需逐token判断,后者需训练但由模型自主决定何时压缩。
四、方法(简洁版)
LightThinker的核心思想是:在推理过程中,让模型自动判断何时压缩当前的冗长思维链,将其压缩成少量“gist tokens”(压缩标记),并丢弃原始长文本,只保留压缩后的信息继续推理。下图为LightThinker的方法框架图
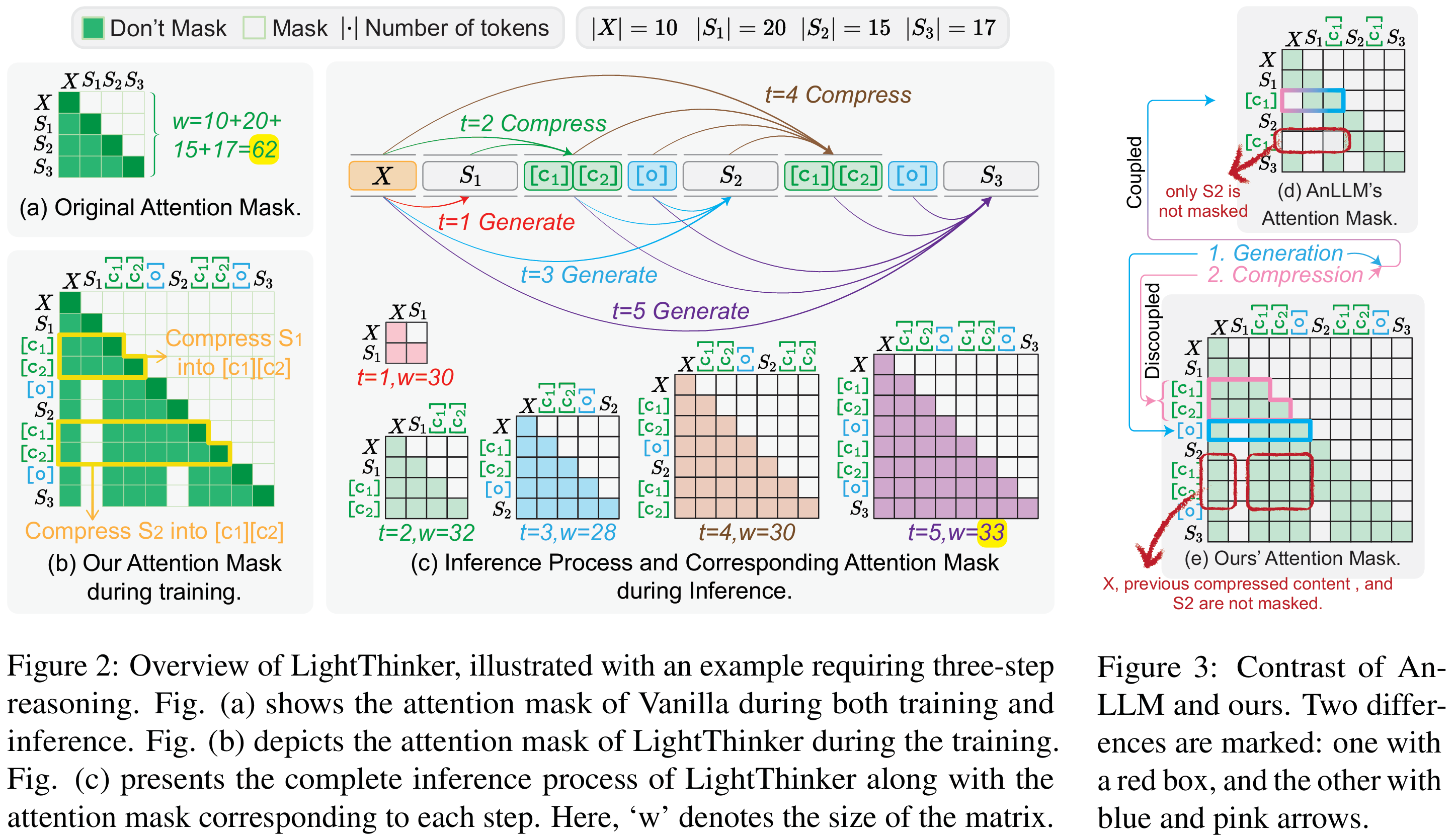
LightThinker涉及到的两个关键问题是何时压缩,以及如何压缩?整个过程可以概括为以下三个关键步骤:
第一步:数据重构——在思考流程中植入压缩指令
LightThinker的第一步是改造训练数据,让LLM明白“压缩”的存在和时机。具体操作是:
- 步骤划分:首先,将模型原本冗长的完整回答Y,按照语义或段落(即一个完整的「想法」)切分成若干个思维步骤S1, S2, S3, ...。
- 插入特殊指令符:在这些思维步骤之间,插入一组特殊的指令令牌。这组指令符主要包含两个部分:
- 缓存令牌(Cache Tokens, [c]):这是一组特殊的、用于存储压缩后信息的摘要令牌。它的作用就像是为即将产生的思想摘要预留的空白便签。
- 输出令牌(Output Token, [o]):这是一个强制性的输出信号,它的作用是告诉模型:“好了,摘要写完了,现在请基于这份摘要继续你下一步的思考”。
经过这样的改造,原本一条完整的思考链,就变成了一个「思考步骤S1 → 进行压缩 → 继续思考步骤S2 → 再次压缩 → ...」的全新格式。这等于是在模型的学习材料中明确地标注出了何时需要进行压缩。注意,研究者在具体实现中,采用换行符作为思维步骤的划分,此处不存在任何数据精心构造的过程。
第二步:注意力改造——学会压缩与理解压缩的内容
教会了模型何时压缩,下一步就是最关键的如何压缩。第二步这主要通过一种名为Thought-based Attention Mask的技术来实现,如Figure2 (b)所示。它能够精确地控制着模型在思考时 “能看什么” 和 “不能看什么” 。这个过程分为两个阶段:
- 压缩阶段(生成思维摘要)。当模型需要将思维步骤Si压缩进缓存令牌C时,注意力掩码会强制这些C令牌只能看到三个东西:最初的问题X、先前已经压缩好的历史摘要、当前正在处理的思维步骤Si。其他所有原始的、未压缩的思维步骤都会被遮蔽。这迫使模型必须将Si中的所有关键信息高度浓缩并存储到C中 。
- 生成阶段(基于摘要生成思维)。当思维步骤Si被成功压缩进C之后,更关键的一步来了。在生成下一个思绪片段S(i+1)时,注意力掩码会彻底遮蔽掉原始的思维步骤Si。此时,模型只能看到最初的问题X和包括刚刚生成的摘要在内的所有历史摘要 。
通过这种方式,模型被迫学会仅依赖紧凑的思想摘要来进行连贯的、层层递进的推理,而不是依赖越来越长的原始思考全文。
第三步:动态推理——即用即弃的高效循环
经过以上两个步骤的训练,LightThinker模型在实际推理时,就会形成一种高效的动态循环,如Figure 1 (b) 和Figure 2 (c) 所示,清晰地展示了“生成→压缩→抛弃”的动态循环过程。下面以Figure 1 (b)为例进行分析:
- 模型接收问题,生成第一段思考(Thought 1)。
- 触发压缩,将Thought 1中的核心信息压缩成紧凑的摘要(C T1)。
- 抛弃原文,将冗长的Thought 1从上下文中丢弃。
- 模型基于问题和摘要(C T1),生成第二段思考(Thought 2)。
- 再次压缩,将Thought 2压缩为摘要(C T2),并丢弃Thought 2原文。
- 如此循环,直到问题解决。
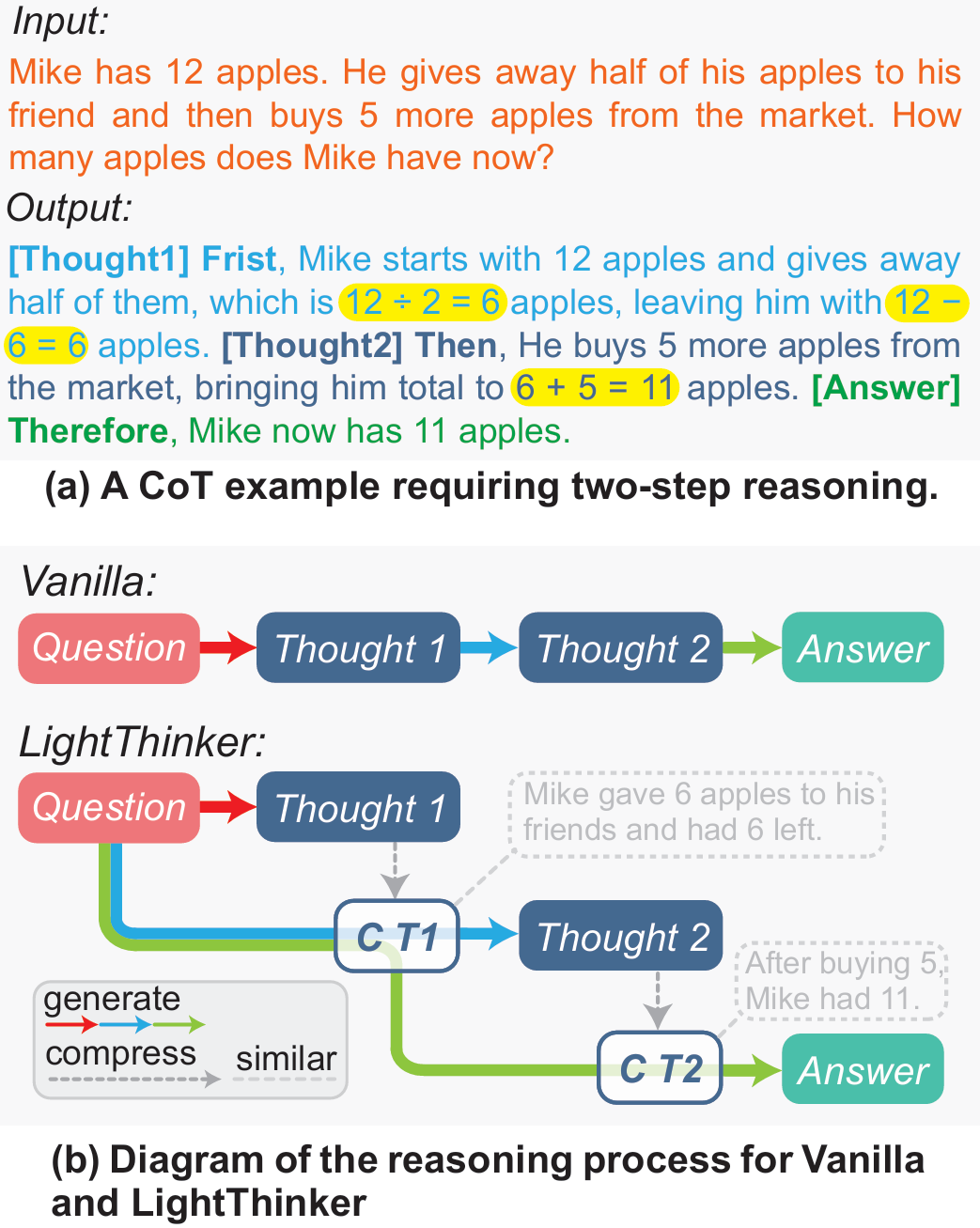
图1 LightThinker与原始CoT的区别
(a) 例子展示冗余性。标准CoT会生成完整句子:“Mike starts with 12 apples … gives away half … buys 5 more …”。黄色高亮的才是“真正影响答案”的关键数字与运算;其余token仅维持语言流畅,可被压缩。
(b) 流程对比:
- Vanilla:从头到尾保留整条推理链(Thought 1 → Thought 2 → Answer),token 数随步骤线性增长。
- LightThinker:每产生一段Thought i后,立即将其压缩成极短的gist token C_Ti,并丢弃原长文本;后续推理只依赖这些压缩表示。结果上下文里始终只有“问题 + 若干gist token”,显著降低KV缓存。
通过这种“即用即弃”的机制,LightThinker确保了模型的上下文窗口始终保持在一个非常小的尺寸,从而解决了因上下文过长导致的内存爆炸和计算缓慢问题,实现了效率与性能的完美平衡。
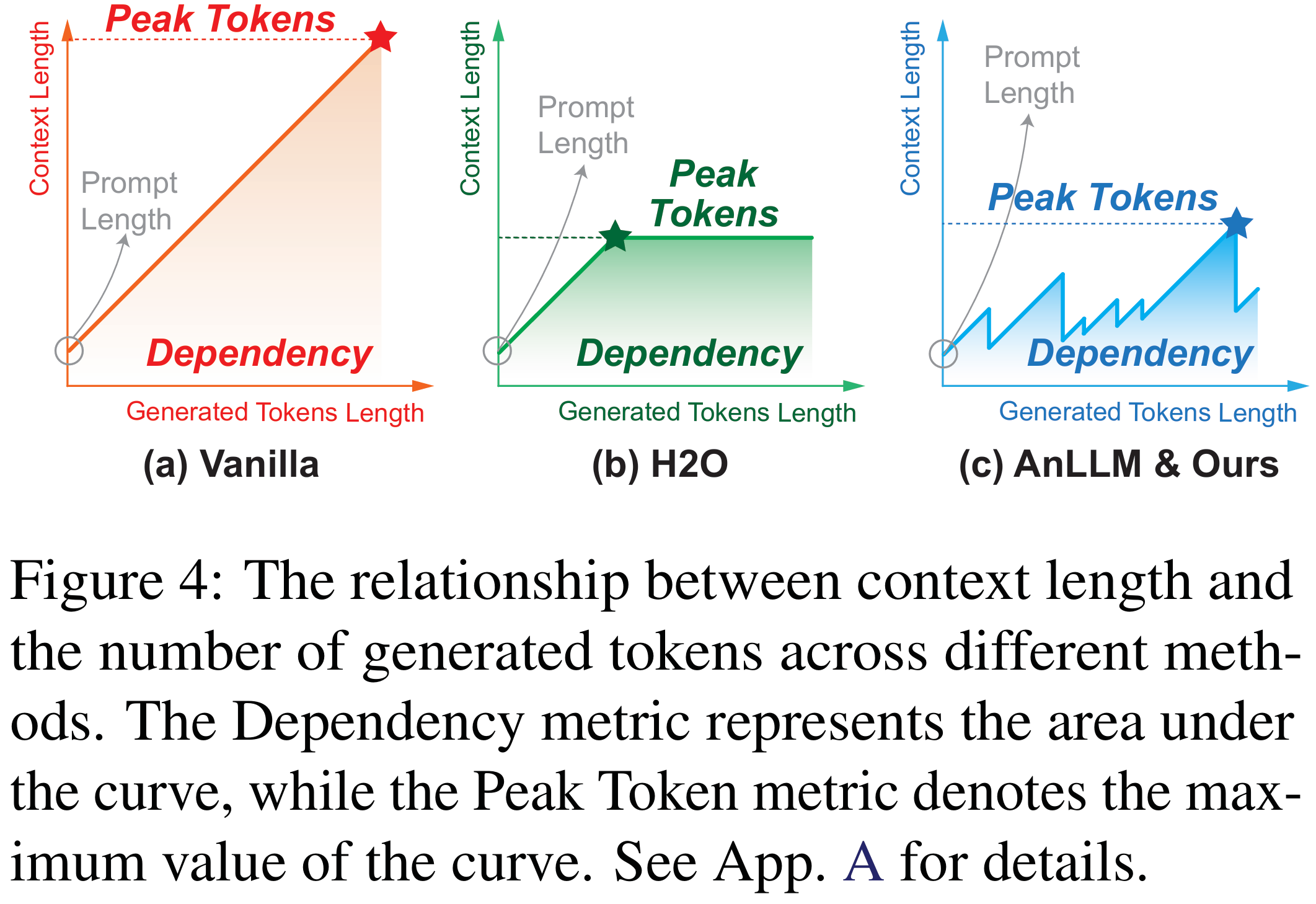
下图展示了不同方法在推理过程中上下文长度的变化,其中曲线和坐标轴围城的面积为我们定义的新指标Dependency,其意义生成token时需要关注token的数量总和。
五、实验(简洁版)
5.1 主要实验
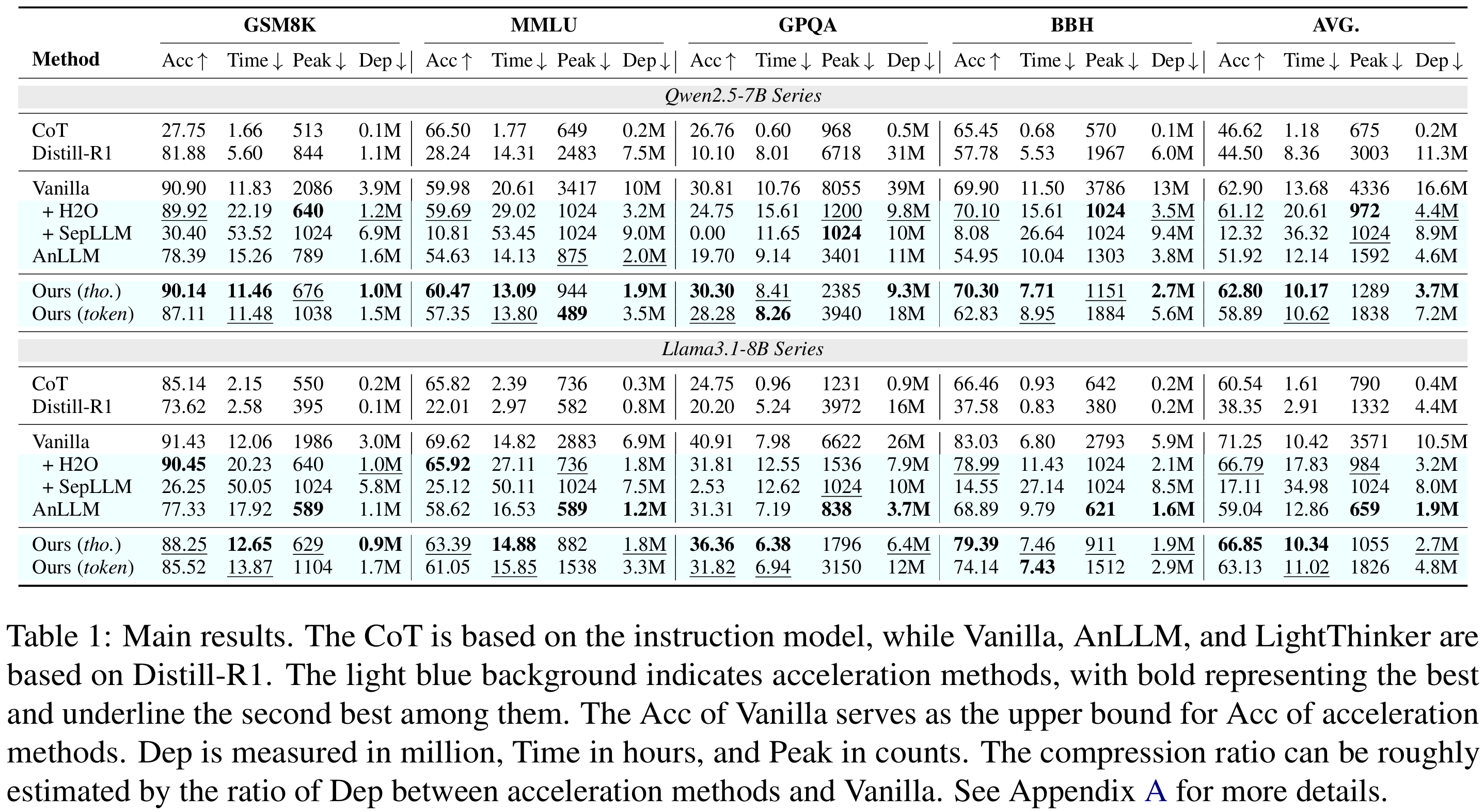
在Qwen-7B与Llama-8B上,LightThinker(thought级)以仅牺牲1-6个百分点的准确率为代价,将峰值token使用量降低约70%,推理时间缩短26%-41%,依赖度Dep(压缩比)提升3.9-4.5倍,全面优于H2O、SepLLM、AnLLM等基线,在准确率与效率之间取得最佳平衡。
5.2 效率(Efficiency)
- 生成token数反而比Vanilla少13~15%。
- 32k token长文本推理时间省44%。
5.3 消融(Ablation)
- 解耦token + 专用注意力掩码合计带来9%准确率提升。
- 增大gist token数|C| → 准确率↑、压缩频率↓、生成token↓。
5.4 Case Study
- 压缩漏掉关键数字会导致最终答案错误,提示需更好处理数值信息。
六、结论
本文提出LightThinker,一种通过在生成过程中动态压缩中间思维链来提升大语言模型复杂推理效率的新方法。通过训练模型学习何时、如何将冗长的思维步骤压缩为紧凑表示,LightThinker在显著降低内存占用与计算成本的同时,仍保持了具有竞争力的准确率。我们引入了Dependency(Dep)指标,用于统一量化不同加速方法的压缩程度。大量实验表明,LightThinker在效率与性能之间取得了良好平衡,为未来的LLM推理加速提供了新的思路。