剪枝
模型剪枝(Model Pruning) 是一种 模型压缩(Model Compression) 技术,主要思想是:
深度神经网络里有很多 冗余参数(对预测结果贡献很小)。
通过去掉这些冗余连接/通道/卷积核,能让模型更小、更快,同时尽量保持精度。
非结构化剪枝(Unstructured Pruning)
对单个权重参数设置阈值,小于阈值的直接置零。
优点:保留了原始网络结构,容易实现。
缺点:稀疏矩阵计算对普通硬件加速有限(需要专门稀疏库)。
#将所有的卷积层通道减掉30%
for module in pruned_model.modules():
if isinstance(module,nn.Conv2d):
#这行代码的作用是对指定模块按照L2范数的标准,沿着输出通道维度剪去30%的不重要通道,
prune.ln_structured(module,name = "weight",amount = 0.3,n=2,dim = 0)
对ResNet18减和不减的效果差不多,一个是精度,另一个是一轮推理的时间
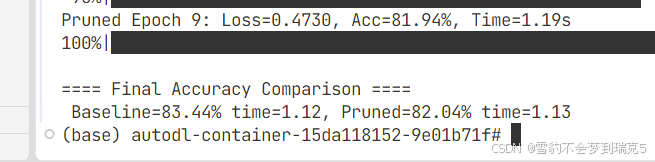
分析原因 确实把 30% 卷积核置零,但是模块结构没变:Conv2d 还是原来那么大,只是部分权重被置零, PyTorch 的默认实现不会自动跳过这些“无效通道”, 所以 FLOPs 还是一样,ptflops 统计出来的数字没减少, GPU 上仍然执行全量卷积,推理时间几乎不会变化
结构化剪枝(Structured Pruning)
删除整个卷积核、通道、层。
优点:能直接减少计算量和推理时间。
缺点:剪掉的多了容易掉精度。
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.utils.prune as prune
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
import time
from tqdm import tqdm
from ptflops import get_model_complexity_info
import torch_pruning as tp
# ======================
# 1. 数据准备
# ======================
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100,
shuffle=False, num_workers=2)
device = torch.device( "cuda" if torch.cuda.is_available() else "cpu" )
# ======================
# 2. 定义训练和测试函数
# ======================
def train(model,optimizer,criterion,epoch):
model.train()
for inx,(inputs,targets) in enumerate(trainloader):
inputs,targets = inputs.to(device),targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,targets)
loss.backward()
optimizer.step()
def test(model,criterion,epoch,tag = ""):
model.eval()
start = time.time()
correct,total,loss_sum = 0,0,0.0
with torch.no_grad():
for inputs, targets in testloader:
inputs,targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss_sum = criterion(outputs,targets).item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
acc = 100. * correct / total
end = time.time()
time_cost = end - start
print(f"{tag} Epoch {epoch}: Loss={loss_sum:.4f}, Acc={acc:.2f}%, Time={time_cost:.2f}s")
return acc,time_cost
def print_model_stats(model,tag = ""):
#统计模型参数和flops
mac, params = get_model_complexity_info(model,(3,32,32),as_strings = True,print_per_layer_stat = False,verbose = False)
print(f"{tag} Params:{params},FLOPs:{mac}")
# ======================
# 3. 训练基线模型
# ======================
print("===============BaseLine ResNet18")
baseline_model = models.resnet18(pretrained = True)
baseline_model.fc = nn.Linear(baseline_model.fc.in_features,10)
baseline_model = baseline_model.to(device)
print_model_stats(baseline_model,"Baseline")
criterion = nn.CrossEntropyLoss()
optimer = optim.SGD(baseline_model.parameters(),lr = 0.01,momentum = 0.9,weight_decay = 5e-4)
baseline_acc = []
baseline_time = []
for epoch in tqdm(range(10)):
train(baseline_model,optimer,criterion,epoch)
acc,time_cost = test(baseline_model,criterion,epoch,"Baseline")
baseline_acc.append(acc)
baseline_time.append(time_cost)
# ======================
# 4. 剪枝 + 微调
# ======================
pruned_model = models.resnet18(pretrained = True)
pruned_model.fc = nn.Linear(pruned_model.fc.in_features,10)
pruned_model = pruned_model.to(device)
#===============非结构化剪枝=====================
# #将所有的卷积层通道减掉30%
# for module in pruned_model.modules():
# if isinstance(module,nn.Conv2d):
# #这行代码的作用是对指定模块按照L2范数的标准,沿着输出通道维度剪去30%的不重要通道,
# prune.ln_structured(module,name = "weight",amount = 0.3,n=2,dim = 0)
#==========================结构化剪枝=====================
# 创建依赖图对象,用于处理剪枝时各层之间的依赖关系
DG = tp.DependencyGraph()
# 构建模型的依赖关系图,需要提供示例输入来追踪计算图
# example_inputs用于追踪模型的前向传播路径,确定各层之间的依赖关系
DG.build_dependency(pruned_model,example_inputs = torch.randn(1,3,32,32).to(device))
def prune_conv_by_ratio(conv, ratio=0.3):
# 计算每个输出通道的L1范数(绝对值求和),用于评估通道的重要性
# conv.weight.data.abs().sum((1, 2, 3)) 对卷积核的后三维(H, W, C_in)求和,得到每个输出通道的L1范数
weight = conv.weight.data.abs().sum((1, 2, 3))
# 根据指定的剪枝比例计算需要移除的通道数量
num_remove = int(weight.numel() * ratio)
# 找到L1范数最小的num_remove个通道的索引
# torch.topk返回最大的k个元素,设置largest=False后返回最小的k个元素
_, idxs = torch.topk(weight, k=num_remove, largest=False)
# 获取剪枝组,指定要剪枝的层、剪枝方式和剪枝索引
# tp.prune_conv_out_channels表示沿输出通道维度进行剪枝
group = DG.get_pruning_group(conv, tp.prune_conv_out_channels, idxs=idxs.tolist())
# 执行剪枝操作,物理移除指定的通道
group.prune()
# 遍历剪枝模型的所有模块
for m in pruned_model.modules():
# 检查模块是否为卷积层
if isinstance(m, nn.Conv2d):
# 对该卷积层执行剪枝操作,移除30%的输出通道
prune_conv_by_ratio(m, ratio=0.3)
#=======================================================
print_model_stats(pruned_model,"Pruned")
criterion1 = nn.CrossEntropyLoss()
optimer1 = optim.SGD(pruned_model.parameters(),lr = 0.01,momentum = 0.9,weight_decay = 5e-4)
pruned_acc = []
pruned_time = []
for epoch in tqdm(range(10)):
train(pruned_model,optimer1,criterion1,epoch)
acc,time_cost = test(pruned_model,criterion1,epoch,"Pruned")
pruned_acc.append(acc)
pruned_time.append(time_cost)
# ======================
# 5. 对比结果
# ======================
print("\n==== Final Accuracy Comparison ====")
print(f" Baseline={max(baseline_acc):.2f}% time={sum(baseline_time)/len(baseline_time):.2f}, Pruned={max(pruned_acc):.2f}% time={sum(pruned_time)/len(pruned_time):.2f}")
最终训练10轮的情况下精度下降7%,模型参数量减少4倍,感觉能够接受
Params:11.18 M – > 2.7M
FLOPs:37.25 MMac --> 9.48 MMac
acc : 82.86% —> 75.77%
time : 1.20 ----> 1.12

基于正则化/稀疏约束
在训练时加上稀疏正则项,让网络自动学习出“重要性低”的权重趋近于零,再做剪枝。