1. 引言
在当数据驱动的商业环境中,用户标签系统已成为企业了解用户、精准营销和个性化服务的关键工具。标签系统通过对用户静态和动态数据的重新组织,帮助企业获得对用户特征和行为的深入理解。本文将详细介绍一个基于云原生架构的完整标签系统的设计与实现,包括系统架构、核心功能、数据流程以及关键技术点,为企业构建高效、灵活的用户画像平台提供参考。
2. 标签系统概述
2.1 什么是标签系统
标签系统是对用户静态数据(如人口学特征)和动态数据(如行为数据)进行重新组织和分析的系统,通过定义各种标签来描述用户的特征和行为模式。标签可以是直接来源于原始数据指标(如月累计消费金额),也可以是基于其他标签推导出来的(如消费类型:低频、中频、高频消费)。
云原生标签系统是在传统标签系统基础上,利用云计算技术和微服务架构构建的新一代标签系统,具有更高的可扩展性、弹性和可维护性。
2.2 标签系统的价值
- 精准用户画像:通过多维度标签构建全面的用户画像
- 精细化运营:支持基于标签的用户分群和精准营销
- 数据资产化:将原始数据转化为可理解、可使用的业务标签
- 业务决策支持:为产品设计、营销策略提供数据支持
- 个性化推荐:为用户提供个性化的产品和服务推荐
- 风险控制:识别潜在的风险用户,进行风险控制
2.3 标签系统的核心功能
- 标签定义与管理:
-
- 选择相关表的用户界面:用于选择与用户原始数据指标相关的数据表
- 定义标签的用户界面:通过选择原始数据或已有标签来定义新标签
- 管理标签的用户界面:用于激活、禁用、查看和删除标签
- 标签分类管理:支持多级标签分类体系
- 标签计算与存储:
-
- 批量计算引擎:基于Spark的大规模标签计算
- 实时计算引擎:基于Elasticsearch的实时标签计算
- 增量计算支持:只计算变化的数据
- 多存储支持:Elasticsearch、Hive等多种存储方案
- 用户分群与模型:
-
- 用户分群功能:基于标签组合进行用户分群
- 模型定义界面:定义由一组标签组成的模型,每个标签有相应权重
- 模型管理界面:管理模型和查看计算结果
- 模型计算服务:计算模型并存储结果
- 数据可视化与分析:
-
- 标签分布分析:查看标签值的分布情况
- 用户画像展示:多维度展示用户特征
- 分群分析报表:分析不同用户群体的特征差异
- 趋势分析:分析标签值随时间的变化趋势
3. 系统架构设计
3.1 架构设计
3.1.1 业务架构
业务架构展示了系统的核心功能模块和用户交互流程:
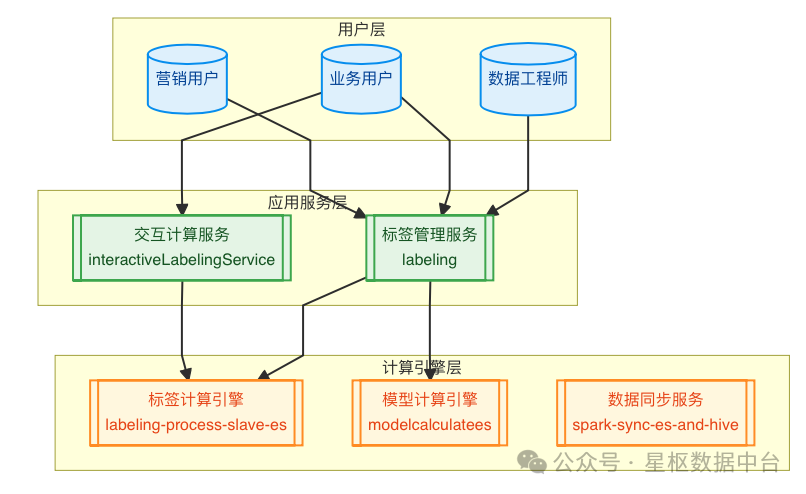
业务架构说明:
- 用户层:系统的核心用户角色
-
- 数据工程师:负责标签和模型的技术实现
- 业务用户:使用标签进行业务分析
- 营销用户:基于标签开展营销活动
- 应用服务层:核心业务功能
-
- 标签管理服务(labeling):标签定义、配置、管理、分群功能
- 交互计算服务(interactiveLabelingService):实时标签计算、SQL测试
- 计算引擎层:数据处理和计算
-
- 标签计算引擎(labeling-process-slave-es):基于Spark的大规模标签计算
- 模型计算引擎(modelcalculatees):基于Spark的模型计算
- 数据同步服务(spark-sync-es-and-hive):ES和Hive数据同步
3.1.2 数据架构
数据架构展示了系统中数据的流动和存储方式:
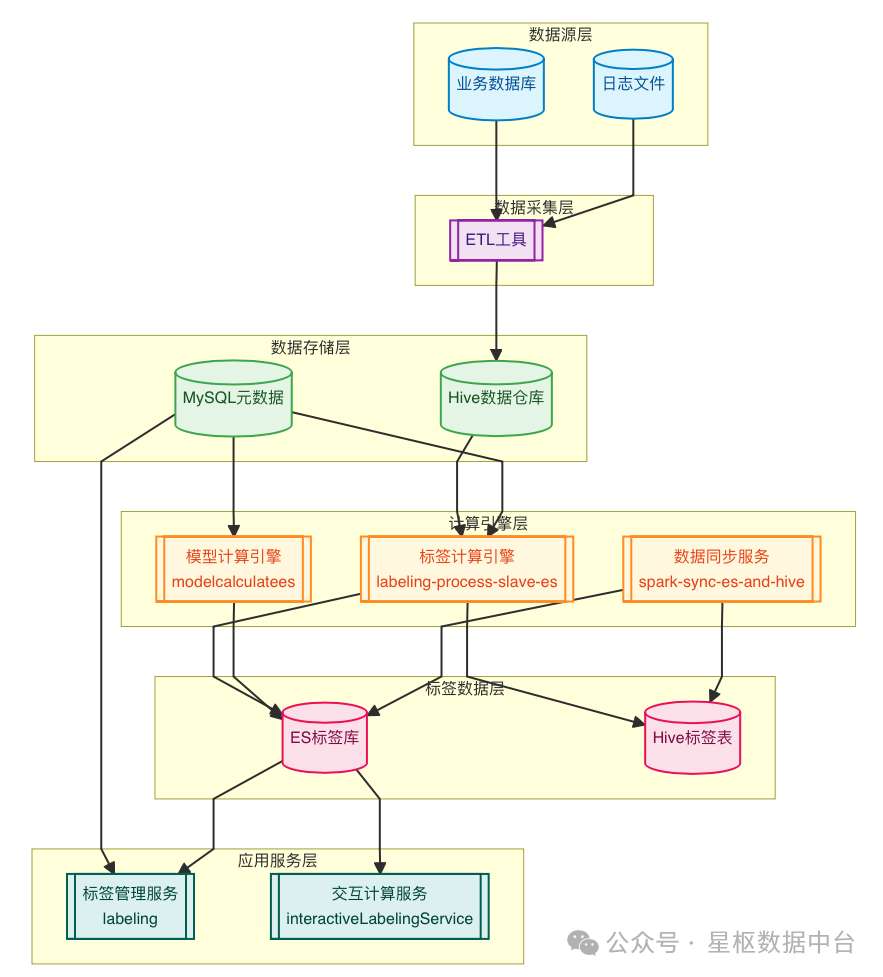
数据架构说明:
- 数据源层:原始数据来源
-
- 业务数据库:用户基础数据、交易数据
- 日志文件:用户行为日志、系统日志
- 数据采集层:数据收集和传输
-
- ETL工具:批量数据抽取转换加载
- 数据存储层:数据持久化
-
- Hive数据仓库:大规模结构化数据存储
- MySQL元数据:系统配置和元数据
- 计算引擎层:数据处理和计算
-
- 标签计算引擎(labeling-process-slave-es):基于Spark的大规模标签计算
- 模型计算引擎(modelcalculatees):基于Spark的模型计算
- 数据同步服务(spark-sync-es-and-hive):ES和Hive数据同步
- 标签数据层:标签结果存储
-
- ES标签库:标签计算结果存储
- Hive标签表:标签数据备份
- 应用服务层:业务服务
-
- 标签管理服务(labeling):标签查询、管理、分群功能
- 交互计算服务(interactiveLabelingService):实时标签计算、SQL测试
3.2 系统组件
根据项目结构,标签系统主要包含以下核心组件:
- labeling:标签配置服务(Spring Boot应用)
-
- 标签定义、配置、管理
- 分群功能(GroupController)
- 提供REST API接口
- 元数据存储(MySQL)
- interactiveLabelingService:交互式计算服务(Spring Boot应用)
-
- 实时标签计算
- SQL测试功能
- 标签结果查询
- labeling-process-slave-es:标签计算引擎(Spark应用)
-
- 基于Spark的大规模标签计算
- 支持单表、多表、标签计算
- 结果写入ES和Hive
- modelcalculatees:模型计算引擎(Spark应用)
-
- 基于Spark的模型计算
- 支持多层级模型结构
- 权重计算和评分
- spark-sync-es-and-hive:数据同步服务(Spark应用)
-
- ES和Hive数据同步
- 确保数据一致性
4. 核心模块设计与实现
4.1 标签配置服务
标签配置服务是整个标签系统的核心,负责标签的定义、管理和元数据存储。
标签配置服务的核心实体包括:
// 标签实体public class LabelEntity implements Serializable { private Integer labelId; // 标签ID private String name; // 标签名称 private String formula; // 标签公式 private String decodeFormula; // 解码公式 private String description; // 标签描述 private String status; // 标签状态 private Integer updateFrequencyId; // 更新频率ID private String resultType; // 结果类型 private Integer categoryId; // 分类ID private Date createTime; // 创建时间 private Date updateTime; // 更新时间}
// 标签详情实体public class LabelDetailEntity extends LabelEntity { private List<LabelThresholdEntity> thresholdValue; // 阈值配置 private TimeRangeEntity timeRange; // 时间范围 private List<LabelTables> tables; // 关联表信息 private String categoryName; // 分类名称 private String updateFrequency; // 更新频率}
// 标签阈值实体public class LabelThresholdEntity { private String thresholdType; // 阈值类型 private String thresholdValue; // 阈值值 private String labelValue; // 标签值 private String operator; // 操作符 private Integer priority; // 优先级}
// 时间范围实体public class TimeRangeEntity { private String timeColumnName; // 时间列名 private long startTime; // 开始时间 private long endTime; // 结束时间 private String timeUnit; // 时间单位 private Integer timeWindow; // 时间窗口}
// 模型系统实体public class ModelSystem implements Serializable { private Integer id; // 模型ID private Integer modelId; // 模型ID private Integer level; // 层级 private String indexId; // 索引ID private String segment; // 分段 private Integer parentId; // 父级ID private Integer labelId; // 标签ID private Float percentage; // 权重 private Float score; // 评分 private Float finalScore; // 最终评分 private List<ModelSystem> children; // 子模型}4.2 标签计算引擎
标签计算引擎基于Spark实现,负责大规模标签计算。
4.2.1 计算流程
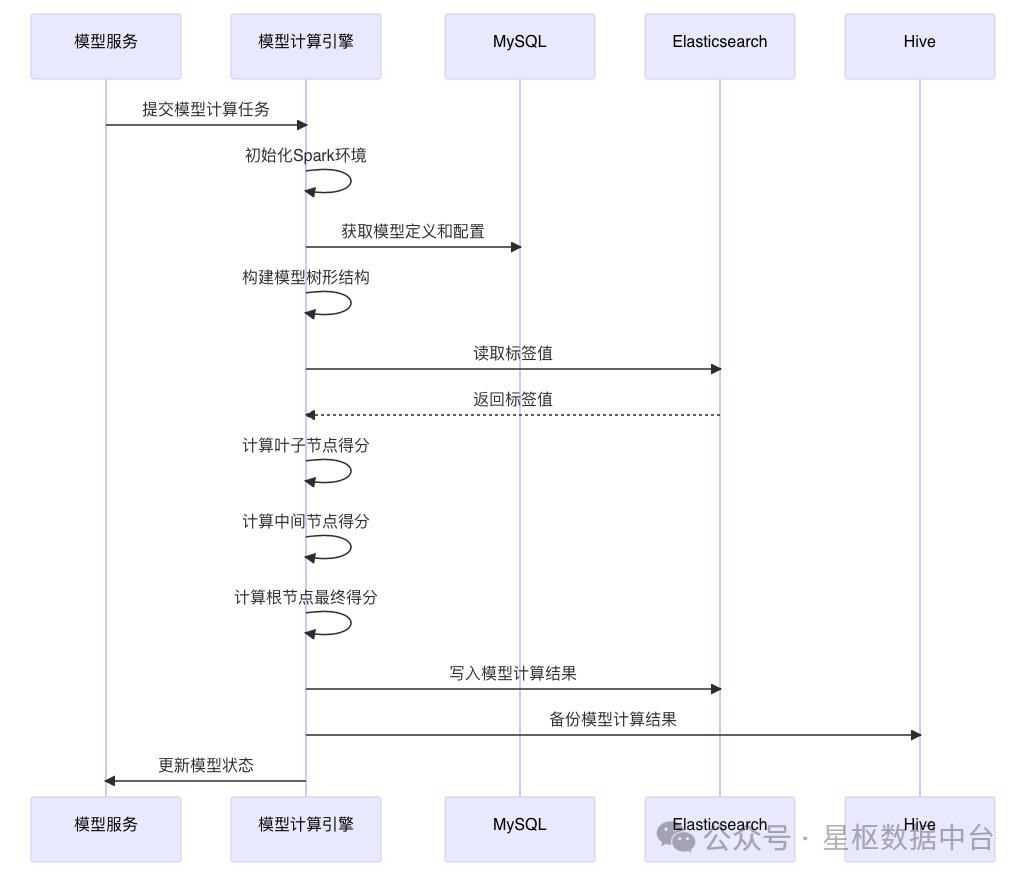
标签计算引擎的计算流程如下:
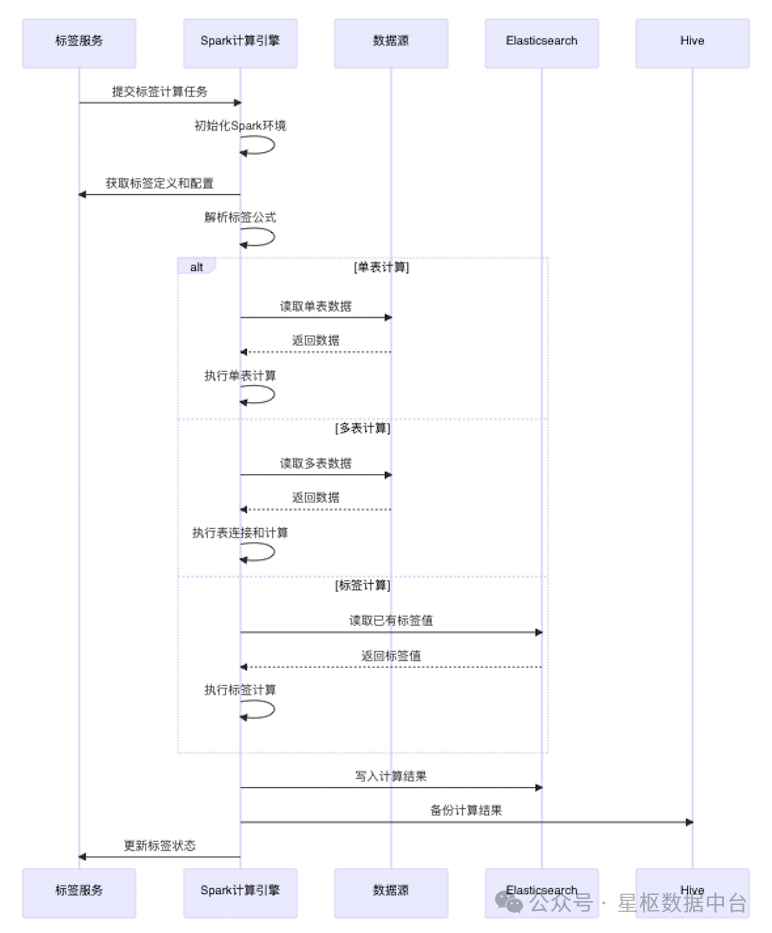
具体实现步骤:
- 从MySQL读取标签定义和配置信息
- 解析标签公式,确定计算类型(单表计算、多表计算、标签计算等)
- 根据计算类型生成相应的SQL语句
- 使用Spark SQL执行计算
- 将计算结果写入Elasticsearch和Hive
4.2.2 标签类型与计算策略
标签计算引擎支持多种类型的标签计算:
- 单表计算:从单个数据表中计算标签值
-
- 直接选择字段作为标签值
- 基于条件筛选的布尔型标签
- 基于聚合函数的数值型标签
- 多表计算:从多个数据表中计算标签值
-
- 表连接后的字段选择
- 表连接后的条件筛选
- 表连接后的聚合计算
- 标签计算:基于已有标签计算新标签
-
- 标签组合
- 标签条件判断
- 标签值计算
4.3 模型计算引擎
模型计算引擎基于Spark实现,负责模型的计算。模型是由一组标签组成的复杂计算结构,用于对用户进行评分或分类。
4.3.1 模型结构
模型采用树形结构设计,包括:
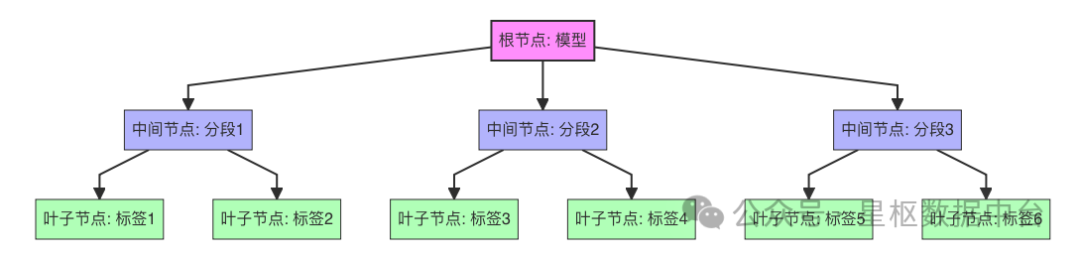
- 根节点:代表整个模型,如"用户价值模型"、"流失风险模型"等
- 中间节点:代表模型的分段(Segment),如"消费能力"、"活跃度"、"忠诚度"等
- 叶子节点:代表具体的标签,如"月均消费金额"、"近30天登录次数"等
每个节点都有权重,模型的最终得分是通过树形结构的计算得出的。
// 模型系统实体case class ModelSystem( id: Int, // 节点ID modelId: Int, // 模型ID level: Int, // 层级 indexId: String, // 索引ID segment: String, // 分段名称 parentId: Int, // 父节点ID labelId: Option[Int], // 标签ID(叶子节点才有) percentage: Float, // 权重 score: Float = 0, // 得分 finalScore: Float = 0, // 最终得分 children: List[ModelSystem] = List() // 子节点)
4.3.2 计算流程
模型计算的流程如下:
具体实现步骤:
- 从MySQL读取模型定义和配置信息
- 构建模型的树形结构
- 从Elasticsearch读取标签值
- 自底向上计算模型得分:
-
- 叶子节点(标签)计算:根据标签值和权重计算得分
- 中间节点(分段)计算:根据子节点得分和权重计算得分
- 根节点计算:得到最终模型得分
- 将计算结果写入Elasticsearch和Hive
4.4 交互式标签计算服务
交互式标签计算服务提供实时标签计算能力,主要用于标签测试和小规模实时计算。它是标签系统中重要的组成部分,为用户提供了快速验证标签定义和查看标签结果的能力。
4.4.1 功能特点
交互式标签计算服务具有以下功能特点:
- 实时计算:支持单个标签的实时计算,快速验证标签定义的正确性
- SQL测试:提供SQL测试功能,帮助用户调试标签公式
- 结果预览:支持标签结果的实时查询和预览,方便用户了解标签分布
- 异步处理:采用异步计算处理机制,提高系统响应性能
- 多数据源支持:支持从Elasticsearch、MySQL等多种数据源获取数据
- 计算监控:提供计算过程监控和日志记录功能
4.4.2 系统架构
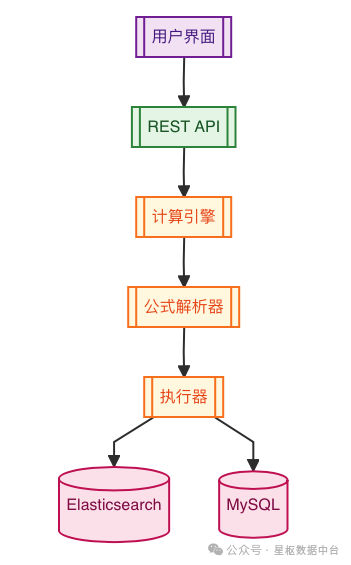
交互式标签计算服务的流程如下:
4.4.3 实现方式
交互式标签计算服务通过直接查询Elasticsearch实现实时计算:
- 接收标签计算请求,获取标签定义
- 解析标签公式,生成Elasticsearch查询语句
- 异步执行查询获取结果
- 处理结果并返回给用户
- 更新标签计算统计信息
5. 关键技术点
5.1 标签公式解析与执行
标签系统的核心是标签公式的解析与执行。系统使用ANTLR实现了一个公式解析器,支持多种表达式:
- 字段选择表达式:
table:db.table.field - 条件表达式:
where field > value - 聚合表达式:
group by field, sum(value) - 标签引用表达式:
label:label_name
解析后的表达式被转换为SQL语句执行计算。
5.2 多层级模型计算
模型采用多层级树形结构设计,支持复杂的计算逻辑:
- 树形结构表示模型的层级关系
- 自底向上计算得分
- 自定义计算函数支持复杂逻辑
5.3 实时与离线计算结合
系统结合了实时和离线计算能力:
- 离线计算:基于Spark的大规模标签和模型计算
- 实时计算:基于Elasticsearch的交互式标签计算
5.4 数据同步与一致性
为保证数据一致性,系统实现了多存储系统间的数据同步:
- MySQL与Elasticsearch的元数据同步
- Elasticsearch与Hive的结果数据同步
- 定期清理过期数据
- END -