Redis 的主从复制模式下,一旦主节点由于故障不能提供服务,需要人工进
行主从切换,同时大量的客户端需要被通知切换到新的主节点上,对于上了一定规模的应用来说,这种方案是无法接受的,于是Redis从2.8开始提供了RedisSentinel(哨兵)来解决这个问题。
哨兵模式的作用
哨兵也叫 sentinel,它的作用是能够在后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
如果master宕机了,sential会从剩下的从服务器节点中选择一台提升为master,然后自动修改相关配置,选举策略如下:
选择优先级靠前的服务器。优先级的配置在 redis.conf 文件中的
replica-priority配置,默认为 100,值越小优先级越高。选择偏移量最大的。偏移量是指获得原主机数据最全的。
选择 runid 最小的从服务器。每个redis实例启动后都会随机生成一个40位的runid。
Redis Sentinel中的Sentinel节点个数应该为大于等于3且最好为奇数。
哨兵集群为什么建议部署 “奇数个节点”?比如 3 个、5 个,而不是 2 个、4 个?
核心原因:避免 “投票脑裂”,确保故障转移时能选出 “领头哨兵” 和新主库。
哨兵的关键投票场景需要 “超过半数节点同意”:
配置哨兵模式
- 首先配置好三台主机的/etc/reids/redis.cnf文件
vim /etc/redis/redis.conf
bind 0.0.0.0
protected-mode no
daemonize no
- 重新启动redis服务
systemctl start redis
- 配置好redis的主从同步
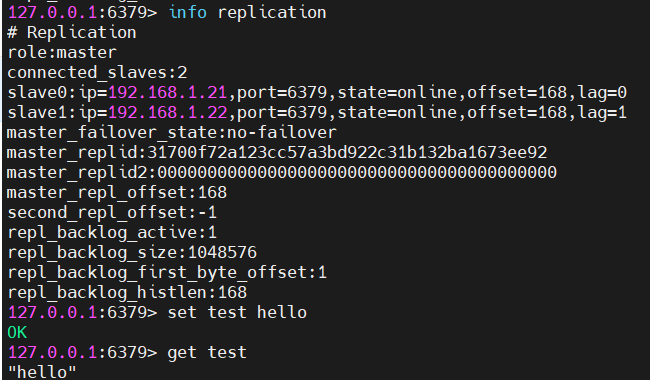
- 查看master主从情况---------- 两个从都是在线的状态下
- 接着配置三台主机的哨兵配置文件
port 26379 #监听端口
daemonize no #后台运行
pidfile /var/run/redis-sentinel.pid
logfile /var/log/redis/sentinel.log
sentinel monitor mymaster 192.168.1.20 6379 2
#monitor:监控
#mymaster为监控对象起的服务名称
#2表示只有2个或2个以上的哨兵认为主节点不可用的时候,才会把 master 设置为客观下线状态,然后进行 failover 操作。
sentinel down-after-milliseconds mymaster 30000 #master中断时长, 30秒连不上视为master下线
sentinel parallel-syncs mymaster 1 #发生故障转移后,同时开始同步新master数据的slave数量
sentinel failover-timeout mymaster 180000 #整个故障切换的超时时间为3分钟- 现在master上配置好哨兵配置文件---再将配置好的哨兵文件传到slave1.slave2上对他们原来的哨兵文件进行覆盖
scp /etc/redis/sentinel.conf root@192.168.1.21:/etc/redis
scp /etc/redis/sentinel.conf root@192.168.1.22:/etc/redis 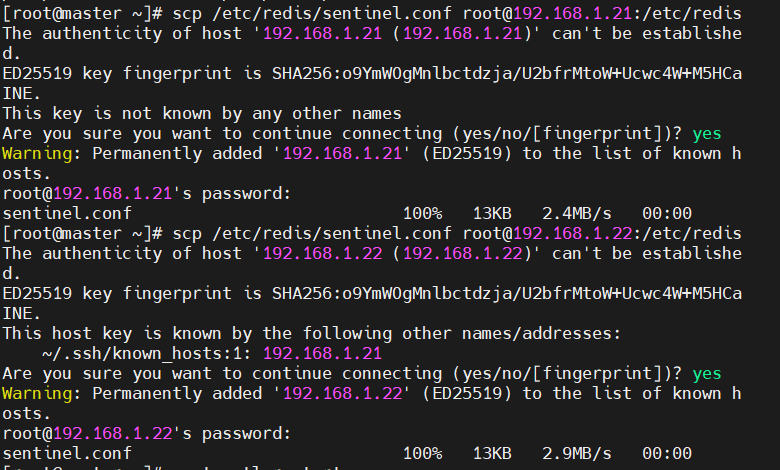
重新启动哨兵服务
systemctl restart redis-sentinel.service
测试---模拟master故障
- 首先将master的redis服务关闭
shutdown

- 然后查看slave1的状态----查看master是否成功转移slave1上
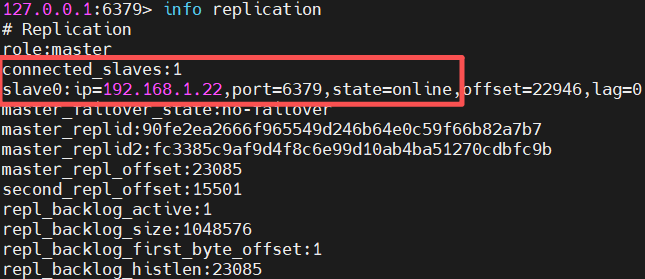
- 查看slave2的主从状态

master成功转移到slave1上并,salve2的主库也成功变成slave1
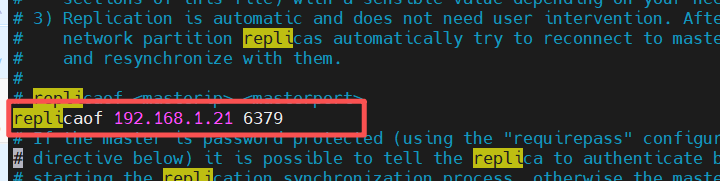
- 查看slave2的redis配置文件--查看哨兵是否检测到故障并且更改slave2文件的主
哨兵自动更改了master的IP为slave1的ip
注意
/etc/redis/sentinel.conf 文件在用哨兵程序调用后会被更改,如果需要重新做要删掉文件重新编辑。
- 由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
- 在生产环境中如果master和slave中的网络出现故障,由于哨兵的存在会把master提出去当网络恢复谷master发现环境发生改变,master就会把自己的身份转换成slave。master变成slave后会把网络故障那段时间写入自己中的数据清掉,这样数据就丢失了。
- 解决办法:master在被写入数据时会持续连接slave, mater确保有2slave可以写入我才允许写入,如果slave数量少于2个便拒绝写入