在卷积神经网络(CNN)的发展与应用中,池化操作虽能有效降低特征图的空间分辨率、减少计算量并扩大感受野,却会不可避免地导致特征图中有效信息的丢失,尤其在处理精细特征(如小目标、复杂结构边缘)时,这种信息损失会显著影响模型性能。同时,传统 CNN 对特征图通道间依赖关系的建模能力较弱,各通道特征往往被独立处理,难以充分挖掘通道间的关联信息,进而限制了特征表达的有效性。
在天文图像分割(如太阳暗条分割)、医学影像分析、自然场景目标检测与分割等任务中,既需要模型具备高效的特征提取能力,又需兼顾轻量化需求以适应硬件资源受限场景(如嵌入式设备、太空观测仪器)。传统注意力机制(如自注意力)虽能有效建模通道或空间依赖,但常伴随大量矩阵运算,导致计算复杂度和内存占用过高,难以在轻量化模型中应用。
为解决上述矛盾,CSA-ConvBlock(通道自注意力卷积块)被提出。它旨在通过优化通道间权重分配,在增强通道依赖建模能力的同时,控制计算成本,弥补池化操作带来的信息损失,为轻量化网络(如 Flat U-Net)提供高效的特征提取单元,适配各类对精度与效率均有要求的计算机视觉任务。
1.CSA-ConvBlock原理
CSA-ConvBlock 的核心原理是基于通道自注意力机制,通过重构特征图通道间的关联关系,动态分配通道权重,强化有效特征、抑制冗余信息,同时结合残差连接与归一化操作,提升特征提取的稳定性与有效性。具体原理可分为以下步骤:
1. 特征映射与转换:对输入的多通道特征图(维度为C×H×W,其中C为通道数、H为高度、W为宽度),通过无偏卷积操作分别生成查询(Query,Fq)、键(Key,Fk)和值(Value,Fv)三个特征图。这一步骤的目的是将原始特征转换为适合计算通道关联的形式,为后续注意力权重计算奠定基础。
2. 通道相似度计算:通过广播机制对Fq的每个通道与Fk的所有通道进行点积运算,生成通道间的相似度张量T。为避免因特征维度差异导致的梯度不稳定问题,引入归一化因子H×W(因任务中H与W通常相等,也可简化为H)对相似度值进行缩放,确保计算结果的数值稳定性。
3. 全局通道权重生成:对相似度张量T的每个通道应用全局平均池化操作,将空间维度的信息压缩为单通道的全局特征描述子s(维度为C),再通过 Softmax 函数将s转换为归一化的通道权重s~(权重总和为 1)。这一步骤实现了对通道重要性的全局评估,使模型能聚焦于对任务更关键的通道特征。
4. 特征加权与残差融合:利用生成的通道权重s~对Fv的每个通道进行加权,得到重构后的特征图F~v,该特征图已强化有效通道信息、抑制冗余通道干扰。最后,将F~v与原始输入特征图进行残差连接(Element-wise Addition),并通过批量归一化(Batch Normalization)稳定训练过程、加速收敛,再经过 ReLU 激活函数引入非线性,输出最终的特征图Y。
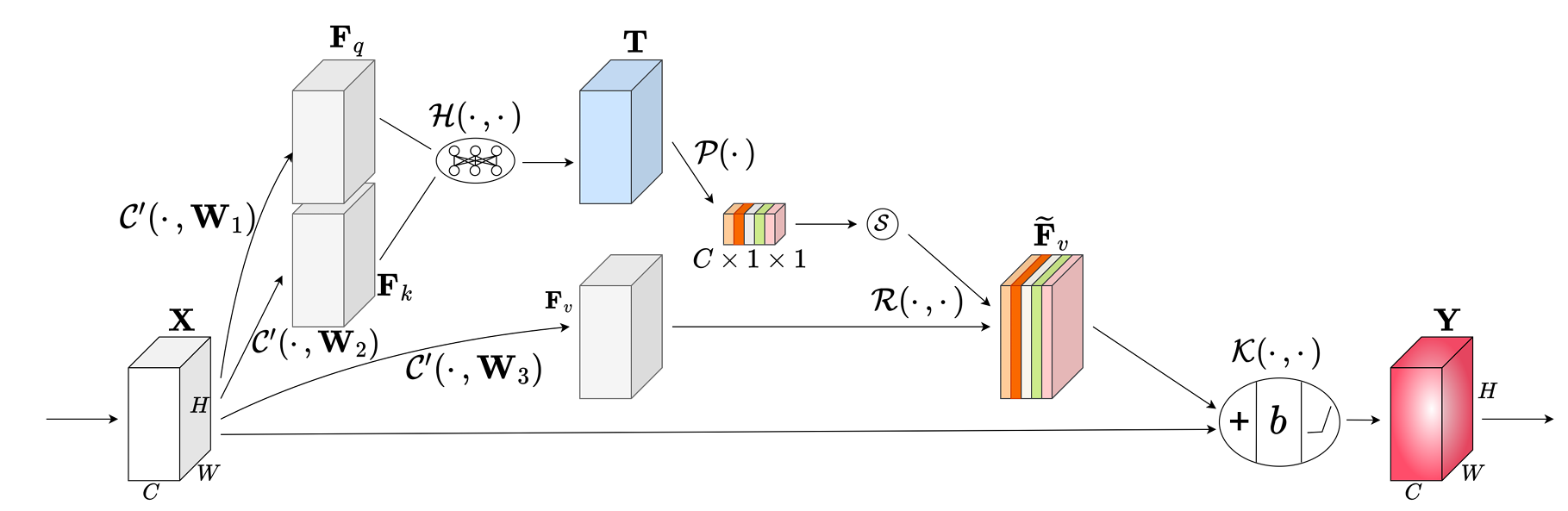
CSA-ConvBlock 的结构围绕 “特征转换 - 注意力计算 - 权重应用 - 残差融合” 的流程设计,整体呈现模块化、可复用的特点,具体结构组成如下:
1. 输入层:接收单通道或多通道特征图(在实际应用中,通常需先通过卷积将单通道输入扩展为多通道,如太阳 Hα 图像从 1 通道扩展为C通道),输入维度为C×H×W。
2. 无偏卷积层:包含 3 个并行的无偏卷积操作(卷积核权重初始化无偏置),分别将输入特征图转换为Fq、Fk、Fv,三者维度均与输入保持一致(C×H×W),该层是实现注意力机制的核心转换单元。
3. 相似度计算模块:通过广播点积运算计算Fq与Fk的通道相似度,生成维度为C×H×W的相似度张量T,并通过归一化因子缩放,确保数值稳定性。
4. 全局平均池化层:对T的每个通道进行空间维度的全局平均池化,将C×H×W的张量压缩为C维的向量s,实现空间信息向通道权重的转化。
5. Softmax 激活层:对向量s进行 Softmax 归一化,生成通道权重s~,确保各通道权重非负且总和为 1,明确通道重要性排序。
6. 特征加权层:将s~与Fv的每个通道进行逐元素乘法(Channel-wise Multiplication),生成重构特征图F~v,完成有效特征的强化。
7. 残差连接与归一化激活层:将F~v与输入特征图进行残差相加,随后通过批量归一化(BN)层消除内部协变量偏移,再经过 ReLU 激活函数引入非线性,最终输出维度为C×H×W的特征图,该输出可直接作为下一层网络的输入。
2. CSA-ConvBlock习作思路
在目标检测中的优点
在目标检测任务中,CSA-ConvBlock 能够显著提升模型对目标特征的捕捉能力与检测精度。一方面,它通过通道自注意力机制动态评估各通道的重要性,可针对性强化目标相关特征(如目标的边缘、纹理、局部结构)对应的通道权重,同时抑制背景噪声通道的干扰,尤其在复杂场景(如遮挡、光照变化、多目标重叠)下,能有效降低背景误检率,提升目标定位的准确性;另一方面,CSA-ConvBlock 无需额外增加过多参数(仅通过少量卷积与池化操作实现注意力计算),在增强特征表达能力的同时,避免了模型复杂度的急剧上升,可适配实时目标检测场景对速度的需求,即使在处理小目标时,也能通过通道间关联信息的挖掘,弥补小目标特征不完整的缺陷,提升小目标检测的召回率。
在分割中的优点
在图像分割任务中,CSA-ConvBlock 对精细分割结果的提升作用尤为突出。首先,分割任务对像素级特征的准确性要求极高,CSA-ConvBlock 通过全局通道权重分配,可充分挖掘不同通道间的互补信息(如分割任务中,部分通道聚焦目标轮廓,部分通道聚焦目标内部纹理),重构后的特征图能更全面地表征目标的像素级特征,减少因特征缺失导致的分割边缘模糊、孔洞等问题;其次,分割任务中常因池化操作导致空间信息丢失,而 CSA-ConvBlock 的残差连接设计可保留原始输入的空间细节,结合注意力加权后的特征,有效缓解池化带来的信息损失,尤其在处理具有复杂结构的目标(如医学影像中的器官边缘、天文图像中的不规则暗条)时,能提升分割结果的完整性与精细度;此外,CSA-ConvBlock 的轻量化特性使其可嵌入到分割网络的多个层级,从低维到高维特征均能进行通道优化,避免了传统分割模型因层级加深导致的特征冗余问题,在保证分割精度的同时,降低模型的内存占用与推理时间。
3. YOLO与CSA-ConvBlock的结合
将 CSA-ConvBlock 融入 YOLO 系列模型,可从精度与效率两方面提升目标检测性能。一方面,YOLO 模型通过多尺度特征融合检测不同大小的目标,CSA-ConvBlock 能在特征提取阶段强化目标关键通道特征(如小目标的局部细节、大目标的结构特征),减少背景噪声对检测结果的干扰,尤其在复杂场景下,可显著提升小目标与遮挡目标的检测召回率与定位精度;另一方面,CSA-ConvBlock 参数增量小,不会大幅增加 YOLO 模型的计算复杂度,适配 YOLO 实时检测的核心需求,即使在嵌入式设备等资源受限场景,也能在保证检测速度的前提下,进一步优化检测性能。
4.CSA-ConvBlock代码部分
https://www.bilibili.com/video/BV1A3Ycz6EC7/?vd_source=8a6043a22d94a87da35299c073140577
YOLOv11模型改进讲解,教您如何修改YOLOv11_哔哩哔哩_bilibili
代码获取:YOLOv8_improve/YOLOV12.md at master · tgf123/YOLOv8_improve · GitHub
5. CSA-ConvBlock到YOLOv11中
第一: 将下面的核心代码复制到D:\model\yolov11\ultralytics\change_model路径下,如下图所示。
第二:在task.py中导入包

第三:在task.py中的模型配置部分下面代码
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行代码
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
import torch
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO("/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/models/11/yolo11_CSA_ConvBlock.yaml")\
# .load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data="/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/datasets/VOC_my.yaml",
epochs=300,
imgsz=640,
batch=4,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = False
)