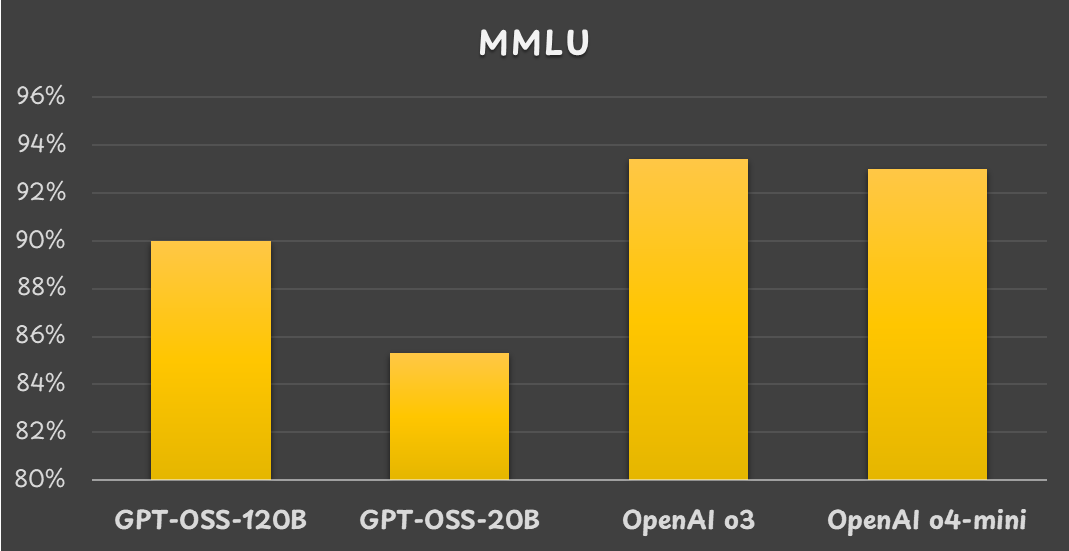
大规模多任务语言理解(MMLU)基准测试结果
距离 OpenAI 首次公开其大语言模型(LLM)的工作原理已有数年时间。尽管名称中带有“open”(开放)一词,但 OpenAI 尚未披露 GPT-4 和 GPT-5 的内部运作机制。
不过,随着开源权重模型 GPT-OSS 的发布,我们终于获得了有关 OpenAI LLM 设计流程的新信息。若想了解当前最先进的 LLM 架构,建议深入研究 OpenAI 的 GPT-OSS。
LLM 模型整体架构
要全面理解 LLM 架构,需回顾 OpenAI 关于 GPT-1、GPT-2、GPT-3 以及 GPT-OSS 的论文。
LLM 模型的整体架构可总结如下:
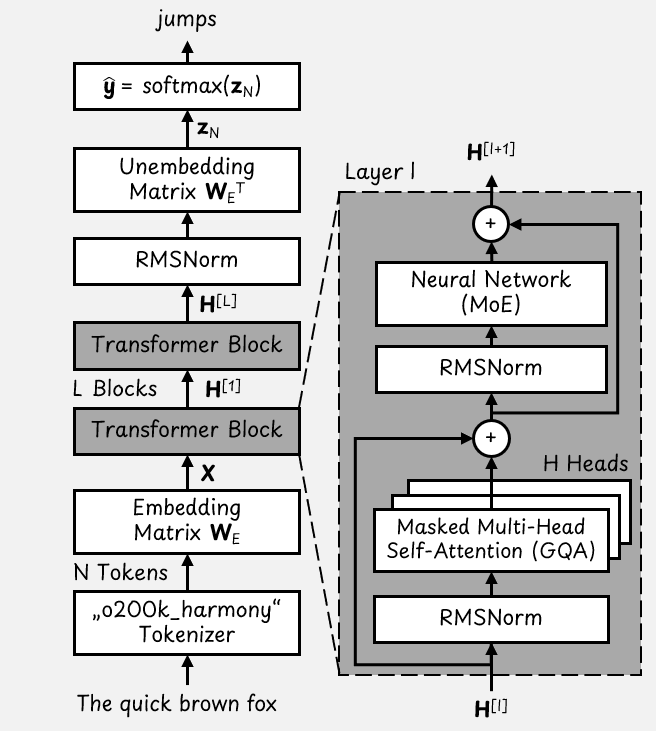
GPT-OSS 基础 Transformer 架构
根据该图,我们从最底部的示例输入句子“The quick brown fox”(敏捷的棕色狐狸)开始。LLM 的目标是预测下一个token,此处可能是“jumps”(跳跃)。
分词(Tokenization)
首先,分词器会将输入句子转换为包含 N 个 token 的列表。o200k_harmony 分词器基于字节对编码(BPE)算法 ,其词汇表包含 201,088 个 token。
这意味着每个 token 都是一个维度为 |V| = 201,088 的独热向量(仅一个元素为 1,其余均为 0)。因此,输入句子会转化为一个形状为 [N x 201,088] 的矩阵。
Token 嵌入(Token Embeddings)
嵌入矩阵会将 token 列表转换为形状为 [N x D] 的密集矩阵。对于 GPT-OSS,模型维度 D = 2,880。最终,我们得到一个形状为 [N x 2,880] 的 token 嵌入矩阵 X。
Transformer 块(Transformer Blocks)
Transformer 模型由多层 Transformer 块组成:
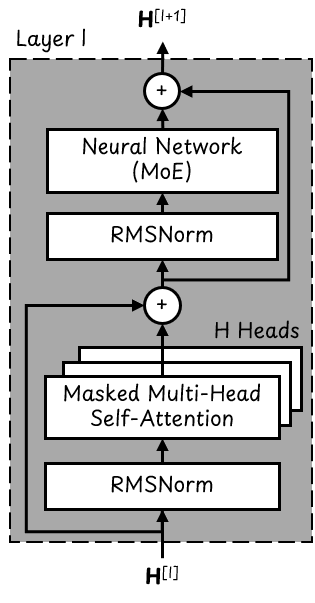
单个 Transformer 块
Token 嵌入会依次经过这些垂直堆叠的 Transformer 块层。其中,GPT-OSS-20B 包含 L = 24 层,而 GPT-OSS-120B 包含 L = 36 层。
每个 Transformer 块都包含两个层归一化块,这两个块采用 RMSNorm 算法,以确保流经 Transformer 的数值保持在合理范围内。
每个 Transformer 块还配有 H = 64 个并行注意力头(attention heads)以及一个混合专家(Mixture of Experts, MoE)神经网络。后续我们将对此展开更详细的介绍。
每个 Transformer 块的输入和输出都是一个形状为 [N x 2,880] 的矩阵 H。
语言模型头(Language Model Head)
语言模型头由解嵌入矩阵(unembedding matrix)和最终的 softmax 层组成。解嵌入矩阵会将嵌入向量转换回 token 空间。解嵌入后,得到的矩阵维度为 [N x 201,088]。
softmax 层会将 N 个 token 向量(称为 logits,对数几率)中的每一个都转换为概率。若要预测下一个 token,我们只需使用最后一个 logit。
最终输出是一个维度为 201,088(即分词器词汇表大小)的概率向量,该向量可能会显示“jumps”这个 token 的概率为 98%。
混合专家模型(Mixture of Experts, MoE)
近年来,涌现出了众多大型MoE模型,例如Qwen 3、Llama 4、DeepSeek V3以及Grok 3。因此,GPT-OSS同样属于MoE模型也就不足为奇了。
MoE层会替代Transformer块中的标准神经网络,它由一个路由组件(router)和多个神经网络(即“专家网络,experts”)组成。
路由组件本质上是一个小型神经网络,其作用是决定由哪个专家网络处理每个输入token。不过,路由组件并非只选择一个专家网络,而是会选择多个专家网络,并为它们分配不同的权重。例如:A = 0.7 × 神经网络2 + 0.3 × 神经网络4。

MoE层的工作原理。在此示例中,会从4个专家网络中选用排名前2的专家网络。
在GPT-OSS中,两款模型(GPT-OSS-20B与GPT-OSS-120B)均会激活排名前4的专家网络。专家网络的总数会根据模型规模有所不同:例如,GPT-OSS-120B共有128个专家网络,而GPT-OSS-20B则有32个。
这也是MoE模型会区分“活跃参数(active parameters)”与“总参数(total parameters)”的原因。在推理过程中,模型在每个MoE层中仅会使用少数几个活跃的神经网络。
量化(Quantization)
由于MoE参数占总参数数量的90%以上,因此在训练后处理流程中,这些参数会被量化为4位浮点数。
具体而言,OpenAI为GPT-OSS采用了MXFP4格式,该格式每个参数占用4位;同时,每32个参数会共享同一个缩放因子(scaling factor) 。缩放因子为8位数值,这意味着每个参数会额外占用8/32 = 0.25位。因此,包含缩放因子在内,每个参数总共占用4.25位。
注意力机制(Attention)
分组查询注意力(GQA Attention)
GPT-OSS并未采用标准的自注意力头,而是使用了分组查询注意力(Grouped-Query Attention, GQA)。
在标准多头注意力中,每个注意力头都配有一个查询矩阵(W_Q)、一个键矩阵(W_K)和一个值矩阵(W_V)。
因此,对于一个拥有H个注意力头的模型,需要3H个矩阵来计算查询(queries)、键(keys)和值(values)。随着注意力头数量的增加,这一过程的资源消耗会愈发显著,在大型LLM中表现得尤为突出。
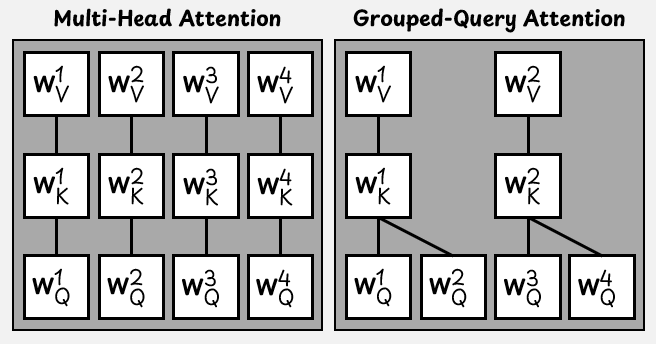
H=4个并行注意力头场景下的标准多头注意力与分组查询注意力对比。
为提升效率,GQA中多个查询头会共享同一个键头和值头。
在GPT-OSS中,每个注意力层包含64个查询头和8个键值头(key-value heads)。
长上下文注意力(Long Context Attention)
最初,Transformer架构会在嵌入向量中添加位置编码(positional encoding) ;但如今,包括GPT-OSS在内的许多现代LLM都改用了旋转位置编码(Rotary Positional Encodings, RoPE)。
RoPE会在注意力机制内部对查询向量和键向量进行旋转,以此融入token的位置信息。输入序列中某个token的位置可通过整数k表示:第一个token的k=0,第二个token的k=1,以此类推。
RoPE会将给定向量按与token位置相关的角度进行逆时针旋转。
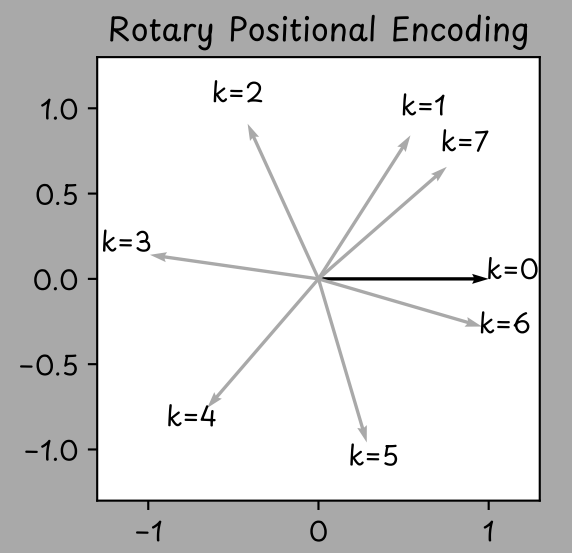
二维嵌入向量会按与输入序列中token位置k相关的角度进行逆时针旋转。
GPT-OSS采用并扩展了RoPE,使其支持的上下文长度最高可达131,072个token。
此外,GPT-OSS还针对长上下文输入采用了一种名为带状窗口注意力(banded window attention)的技术。
在标准掩码自注意力(standard masked self-attention)中,每个token都能“看到”自身以及所有之前的token。若输入序列包含N个token,就会生成一个N×N的注意力矩阵。LLM的上下文长度越长,这一机制带来的问题就越明显。
而在稀疏注意力机制(sparse attention mechanism)中,token能“回溯查看”的范围存在限制。在GPT-OSS中,这一限制(即注意力窗口)的长度为128个token。
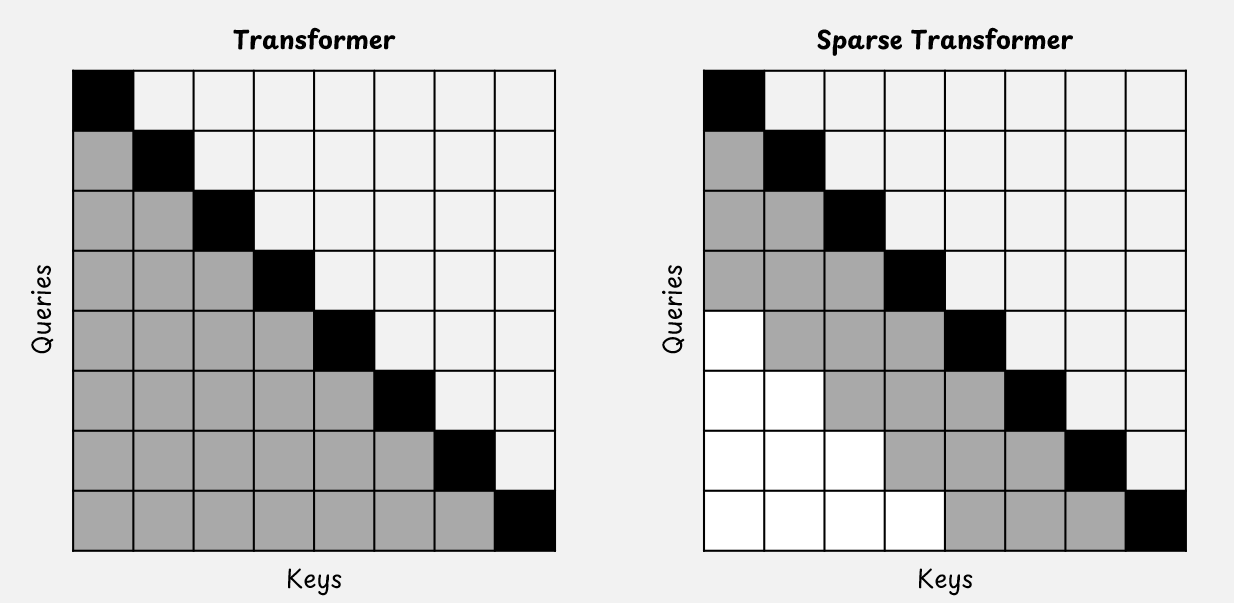
标准注意力机制与稀疏注意力机制对比。查询(query)只能查看其之前的键(key)(黑色与灰色部分)。
GPT-OSS会在两种注意力机制间交替:一种是全注意力(full attention) ,可考虑整个全局上下文;另一种是“带状窗口注意力”,仅关注文本中较小的局部部分。
结论
继GPT-3之后,我们终于迎来了OpenAI的最新动态——这一动态让我们得以一窥其当前LLM的架构。
GPT-OSS并无令人意外或新颖之处。事实证明,它与近期发布的其他LLM(例如Qwen 3)其实非常相似。事实上,GPT-OSS-20B的架构与Qwen3–30B-A3B的架构几乎完全一致。
我们有理由推测,GPT-4和GPT-5也采用类似架构,只是规模大幅扩大。当然,也不排除OpenAI掌握了一些未通过GPT-OSS披露的隐藏技术——不过,我认为这种可能性并不大。
模型的性能并非仅受LLM架构影响;训练数据和训练流程同样发挥着重要作用。或许,这才是OpenAI模型真正的优势所在。