1、主从集群
1、构建主从集群
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。主写从读,主可以读也可以写,从只能读
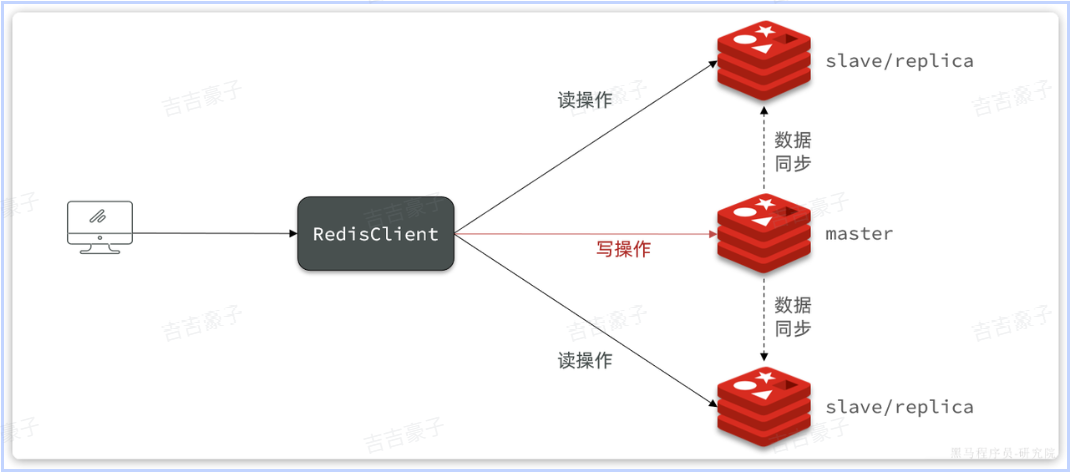
利用docker-compose文件来构建主从集群:
步骤:
- 首先通过docker-compose文件来构建容器,导入资料中准备的文件以及tar包。
- 使用docker load -i redis.tar命令将tar包加载成镜像。
- 执行docker compose up -d来创建并启动所有容器。 -d代表在后台。此时已经建好集群但没有关联。
由于采用的是host模式,我们看不到端口映射。不过能直接在宿主机通过ps命令查看到Redis进程:ps -ef | grep redis。
输入docker exec -it r1 redis-cli --port 7001进入到容器内
docker exec -it 容器名 bash
进入容器 -it (添加一个可输入终端,可以交互了)容器名 bash(表示命令行交互类型) 输入exit 退出

- 此时可以输入 info replication会发现角色是master(role:master),同理进入r2,r3都是master
- 分别进入r2,r3输入 SLAVEOF 192.168.100.128 7001,其就会变成“从”(7001就是r1的端口,相当于就是认r1为主)
- 至此主从集群搭建成功,可以使用:
set num 123 get num来测试r1,r2,r3是否可以读写。
2、主从同步原理
当主从第一次同步连接或断开连接时,从节点都会发送psyn请求,尝试数据同步:
replicationID:每一个master节点都有自己的唯一id,简称replid。当一个节点变成另一个节点的从节点时,他们的replid会改变,并且一样,这样就可以通过判断replid是否相同来判断是不是第一次来。
offset:repl_backlog中写入过的数据长度,写操作越多,offset值越大,主从的offset一致代表数据一致。

主从集群优化:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO。
- 适当提高repl_backlog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步。
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力。

二、哨兵集群
1、哨兵原理
Redis提供了哨兵机制来实现主从集群的自动故障恢复。哨兵的具体作用如下:
状态监控:
Sentinel会不断检查您的master和slave是否按预期工作故障恢复(failover):如果
master故障,Sentinel会将一个slave提升为master。当故障实例恢复后会成为slave状态通知:
Sentinel充当Redis客户端的服务发现来源,当集群发生failover时,会将最新集群信息推送给Redis的客户端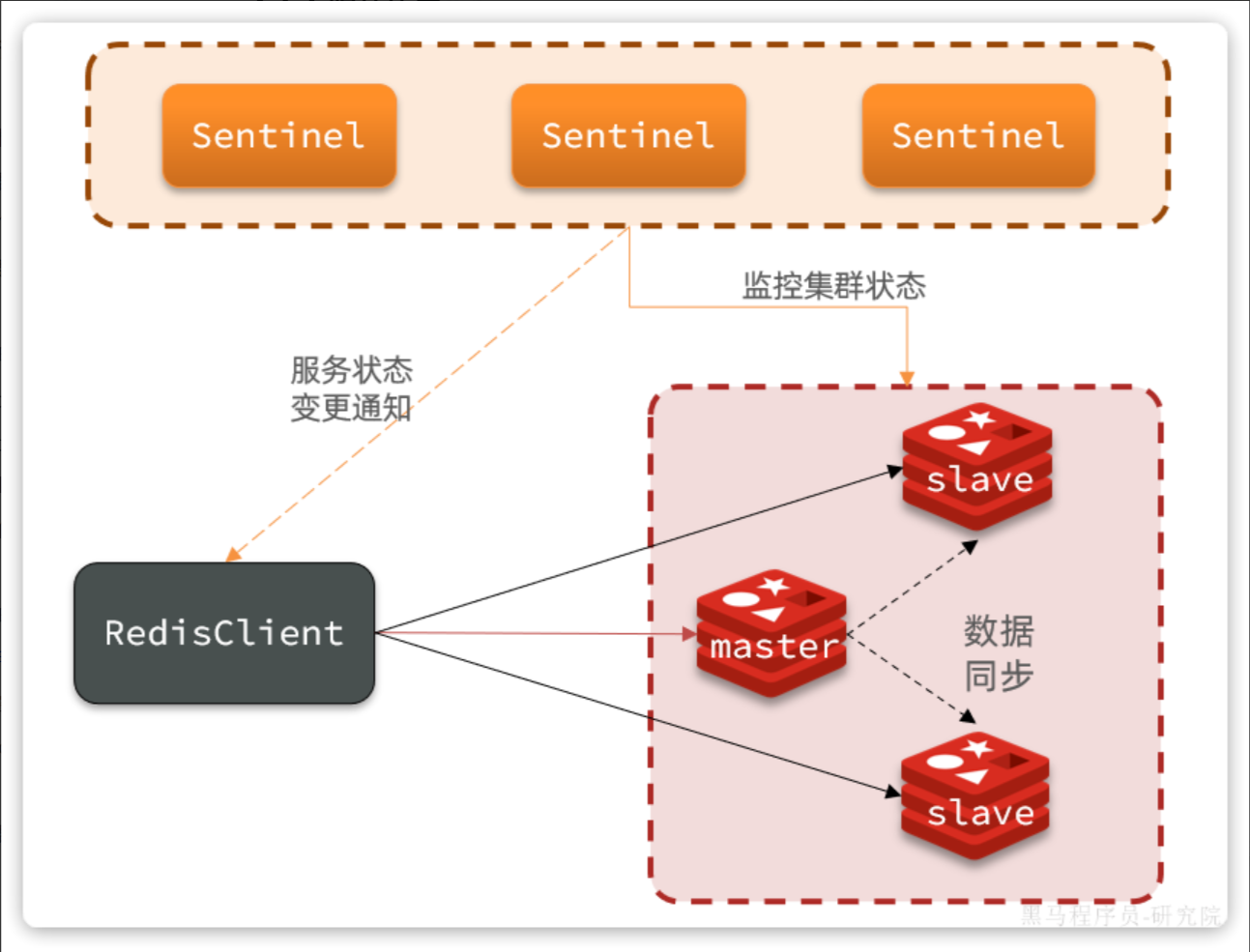
服务状态监控
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个节点发送ping命令,并通过实例的响应结果来做出判断:
主观下线(sdown):如果某sentinel节点发现某Redis节点未在规定时间响应,则认为该节点主观下线。
客观下线(odown):若超过指定数量(通过
quorum设置)的sentinel都认为该节点主观下线,则该节点客观下线。quorum值最好超过Sentinel节点数量的一半,Sentinel节点数量至少3台。
选举新的master
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
首先会判断slave节点与master节点断开时间长短,如果超过
down-after-milliseconds * 10则会排除该slave节点然后判断slave节点的
slave-priority值,越小优先级越高,如果是0则永不参与选举(默认都是1)。如果
slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高最后是判断slave节点的
run_id大小,越小优先级越高(通过info server可以查看run_id)。
实现故障转移
假如master发生故障,slave1当选。则故障转移的流程如下:
1)sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
2)sentinel给所有其它slave发送slaveof 192.168.150.101 7002 命令,让这些节点成为新master,也就是7002的slave节点,开始从新的master上同步数据。
3)最后,当故障节点恢复后会接收到哨兵信号,执行slaveof 192.168.150.101 7002命令,成为slave:

2、搭建哨兵集群
参考讲义
三、分片集群
主从模式可以解决高可用、高并发读的问题。但依然有两个问题没有解决:
海量数据存储
高并发写
要解决这两个问题就需要用到分片集群了。分片的意思,就是把数据拆分存储到不同节点,这样整个集群的存储数据量就更大了。
Redis分片集群的结构如图: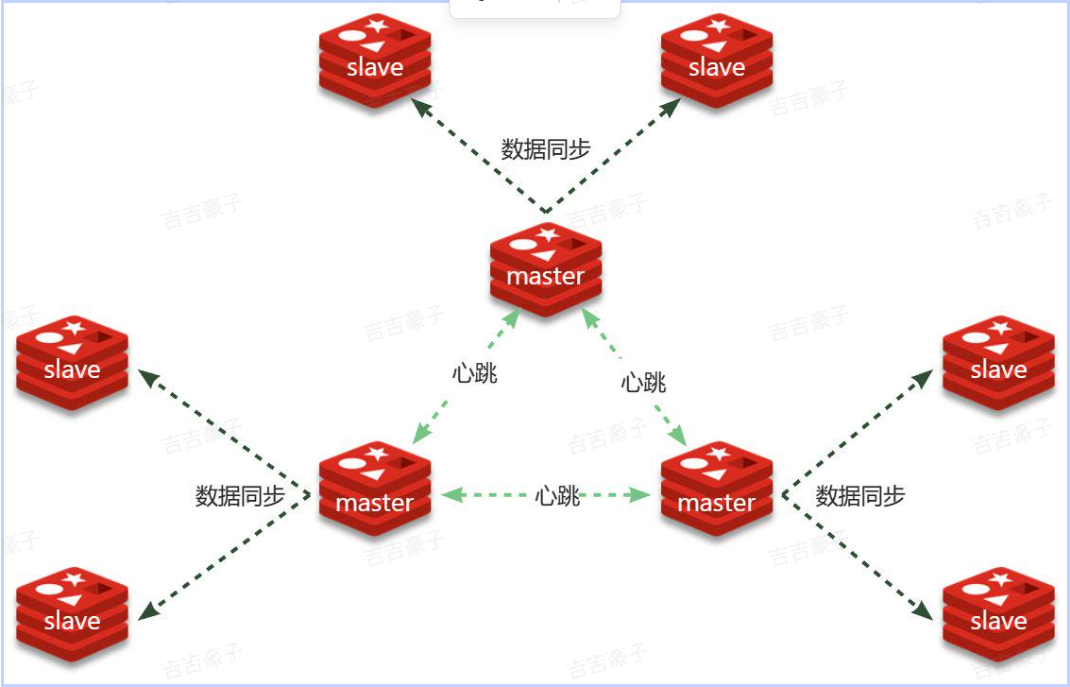
分片集群特征:
集群中有多个master,每个master保存不同分片数据 ,解决海量数据存储问题
每个master都可以有多个slave节点 ,确保高可用
master之间通过ping监测彼此健康状态 ,类似哨兵作用
客户端请求可以访问集群任意节点,最终都会被转发到数据所在节点
搭建分片集群参考讲义
四、Redis数据结构
1、RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象,源码如下:
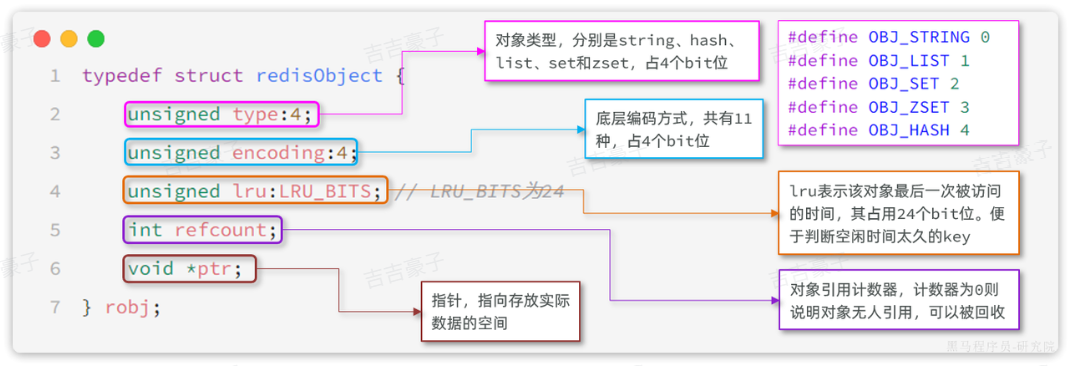
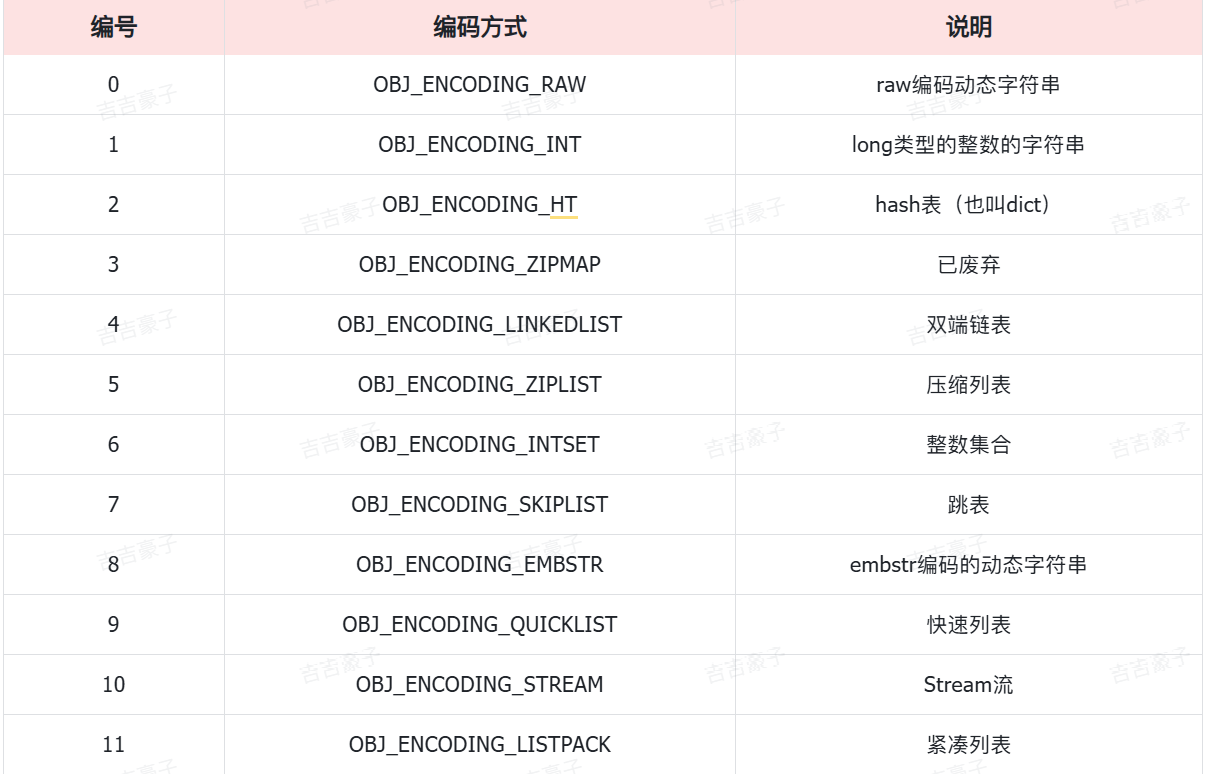
Redis中会根据存储的数据类型不同,选择不同的编码方式,共包含12种不同类型:
Redis中的5种不同的数据类型采用的底层数据结构和编码方式如下:

2、SkipList
SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
元素按照升序排列存储
节点可能包含多个指针,指针跨度不同。
传统链表只有指向前后元素的指针,因此只能顺序依次访问。如果查找的元素在链表中间,查询的效率会比较低。而SkipList则不同,它内部包含跨度不同的多级指针,可以让我们跳跃查找链表中间的元素,效率非常高。
其结构如图:
3、SortedSet
SorteSet数据结构的特点是:
- 每组数据都包含score和member
- member唯一
- 可根据score排序
SortedSet底层既有hash又有SkipList
面试题:Redis的
SortedSet底层的数据结构是怎样的?答:SortedSet是有序集合,底层的存储的每个数据都包含element和score两个值。score是得分,element则是字符串值。SortedSet会根据每个element的score值排序,形成有序集合。
它支持的操作很多,比如:
根据element查询score值
按照score值升序或降序查询element
要实现根据element查询对应的score值,就必须实现element与score之间的键值映射。SortedSet底层是基于HashTable来实现的。
要实现对score值排序,并且查询效率还高,就需要有一种高效的有序数据结构,SortedSet是基于跳表实现的。
加分项:因为SortedSet底层需要用到两种数据结构,对内存占用比较高。因此Redis底层会对SortedSet中的元素大小做判断。如果元素大小小于128且每个元素都小于64字节,SortedSet底层会采用ZipList,也就是压缩列表来代替HashTable和SkipList
不过,
ZipList存在连锁更新问题,因此而在Redis7.0版本以后,ZipList又被替换为Listpack(紧凑列表)。
五、Redis内存回收
1、过期KEY的处理
面试题:Redis如何判断KEY是否过期呢?
答:在Redis中会有两个Dict,也就是HashTable,其中一个记录KEY-VALUE键值对,另一个记录KEY和过期时间。要判断一个KEY是否过期,只需要到记录过期时间的Dict中根据KEY查询即可。
Redis是何时删除过期KEY的呢?
Redis并不会在KEY过期时立刻删除KEY,因为要实现这样的效果就必须给每一个过期的KEY设置时钟,并监控这些KEY的过期状态。无论对CPU还是内存都会带来极大的负担。
Redis的过期KEY删除策略有两种:
惰性删除,顾明思议就是过期后不会立刻删除。那在什么时候删除呢?
Redis会在每次访问KEY的时候判断当前KEY有没有设置过期时间,如果有,过期时间是否已经到期。
周期删除:顾明思议是通过一个定时任务,周期性的抽样部分过期的key,然后执行删除。
执行周期有两种:
SLOW模式:Redis会设置一个定时任务
serverCron(),按照server.hz的频率来执行过期key清理FAST模式:Redis的每个事件循环前执行过期key清理(事件循环就是NIO事件处理的循环)。
2、内存淘汰策略
Redis支持8种不同的内存淘汰策略:
对于某些特别依赖于Redis的项目而言,仅仅依靠过期KEY清理是不够的,内存可能很快就达到上限。因此Redis允许设置内存告警阈值,当内存使用达到阈值时就会主动挑选部分KEY删除以释放更多内存。这叫做内存淘汰机制。
noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰allkeys-random:对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选volatile-random:对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。allkeys-lru: 对全体key,基于LRU算法进行淘汰volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰allkeys-lfu: 对全体key,基于LFU算法进行淘汰volatile-lfu: 对设置了TTL的key,基于LFI算法进行淘汰
比较容易混淆的有两个算法:
LRU(
LeastRecentlyUsed),最近最久未使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。LFU(
LeastFrequentlyUsed),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
六、缓存问题
参考另一个redis面试