LLM Paper Web Reader:一款专为学术研究者设计的轻量级论文辅助阅读工具
作者留:总之我觉得挺好用的,具体的介绍我也懒得再写了,功能很简单,感兴趣可以clone下来用一下。不感兴趣就算了。shandianchengzi/llmreadpaper: 这是一个非常轻量的可以部署到自己服务器上的网页,支持登录,并且拖入PDF并用大模型逐页解析成可以被理解的中文内容,并且可以导出原文和译文,方便阅读论文,功能也非常简单。是我精心设计过的提示词我觉得很好用,而且我自己用着也很好用,所以开源安利给大家。
在科研工作中,阅读和理解英文论文是许多研究者日常面临的重要任务。语言障碍、专业术语以及复杂的句式结构常常成为阅读过程中的拦路虎。为了帮助学术研究者更高效地阅读和理解论文内容,我开发了LLM Paper Web Reader——一款轻量级、本地化运行的论文辅助阅读工具。
工具特点
1. 部署简单,快速上手
LLM Paper Web Reader提供了两种极其简单的部署方式,满足不同用户的需求:
本地部署(适合已有Python环境的用户):
./start_app.sh
Docker部署(适合希望环境隔离的用户):
./start_docker.sh
只需几个命令,即可在本地服务器上搭建完整的论文阅读辅助系统,无需复杂的配置流程。
2. 完全本地化运行,隐私性强
与许多依赖云端服务的工具不同,LLM Paper Web Reader完全在本地运行:
- 所有论文处理均在用户自己的服务器上完成
- 论文内容不会上传到任何第三方服务器
- 支持离线环境运行,确保研究资料的完全保密
- 通过Ollama本地大模型进行处理,数据不出内网
这一特性特别适合处理敏感研究内容和高保密要求的学术资料。
3. 功能实用,专注学术阅读
工具专注于解决学术论文阅读的实际需求:
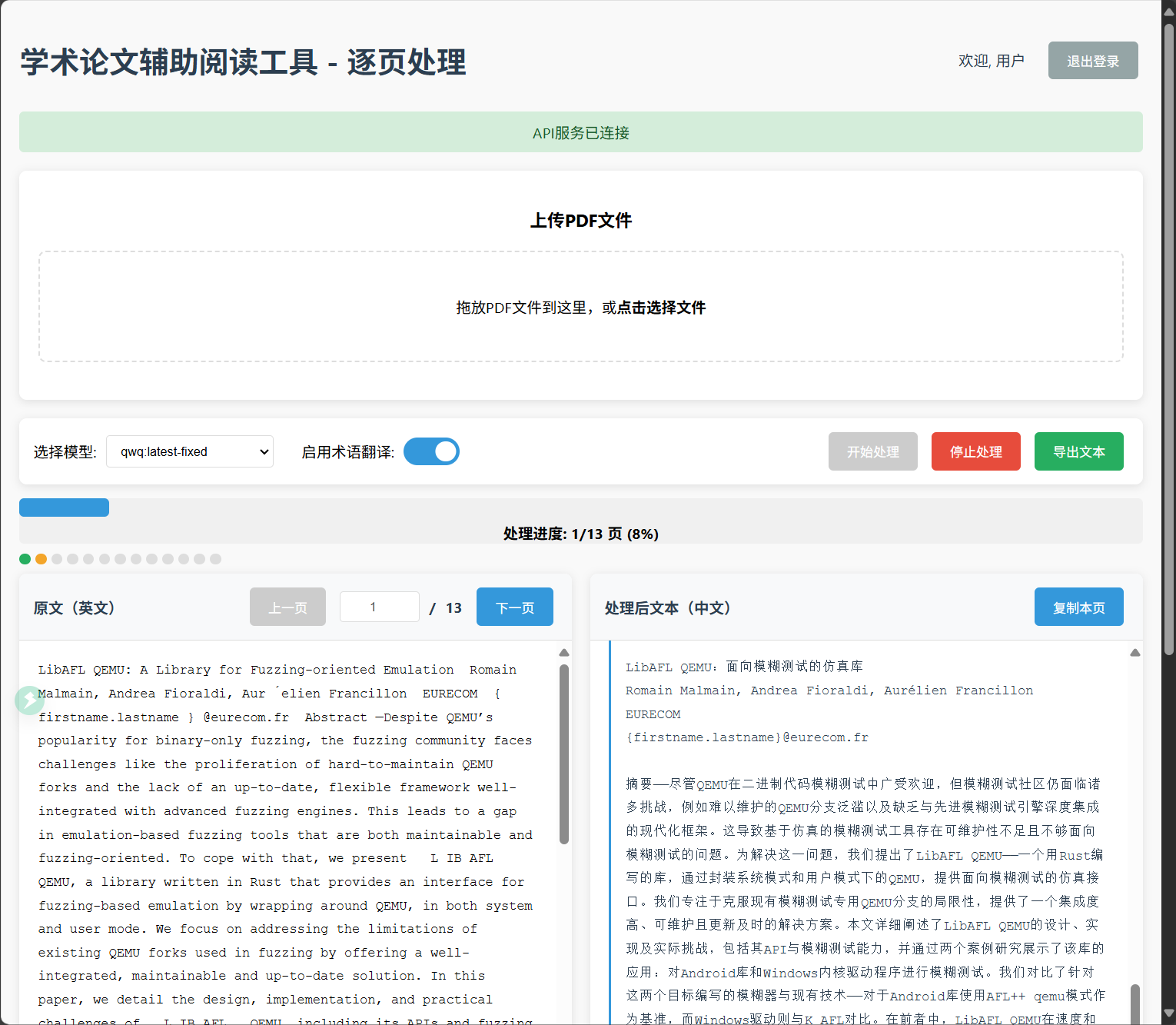
逐页处理机制:
- 上传PDF论文后,系统自动分页提取文本
- 可选择性处理特定页面,避免资源浪费
- 实时显示处理进度,清晰掌握处理状态
双语对照展示:
- 左侧显示英文原文,右侧显示中文译文
- 支持页面导航,方便前后对照阅读
- 单页译文复制功能,便于笔记整理
多种导出选项:
- 导出纯原文文本
- 导出纯译文文本
- 导出原文+译文对照文本
- 自动标注处理进度,明确哪些页面已完成翻译
4. 精心设计的提示词系统
工具的核心优势在于其精心优化的提示词设计,确保翻译质量:
专业术语处理:
# 专业术语保留英文原名(如ResNet)
# 硬件寄存器保留原始格式(如CR.TXEN)
# 常见非专业术语可翻译为中文
技术细节保留:
- 100%保留原文技术细节
- 所有数字用【】标注(如【92.3%】)
- 数学符号/公式原样保留
中文优化策略:
- 被动语态转主动(“is proposed"→"本研究提出”)
- 长句拆分(>35字且含3+技术名词时)
- 删除冗余表达(“的情况下"→"时”)
结构要求严格:
- 保持原文段落结构
- 使用自然衔接词
- 禁止添加术语翻译对照表
- 禁止使用分点编号
- 禁止改变原文段落顺序
这样的提示词设计确保了翻译结果既准确又符合学术文献的专业要求。
技术架构
LLM Paper Web Reader采用简洁高效的技术栈:
- 后端:Fl框架,提供RESTful API和用户认证
- 前端:原生HTML/CSS/JavaScript,兼容性强
- PDF处理:PDF.js库,高效提取文本内容
- AI能力:通过Ollama集成本地大模型
- 部署:支持原生Python环境和Docker容器化部署
使用场景
这款工具特别适合以下场景:
- 非英语母语研究者:快速理解英文论文核心内容
- 文献调研:快速浏览多篇论文,筛选相关研究
- 组会准备:快速提取论文要点,准备汇报内容
- 论文写作:参考英文表达和学术写作风格
- 教学辅助:教师为学生准备双语对照学习材料
结语
LLM Paper Web Reader是我在学术研究过程中的实践总结,旨在解决论文阅读中的实际痛点。通过本地化部署、精心设计的提示词和实用的功能设计,这款工具为学术研究者提供了一个安全、高效、易用的论文阅读辅助解决方案。
欢迎各位研究者试用并提供宝贵意见,共同改进这款工具,让学术研究变得更加高效和愉悦。
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://shandianchengzi.blog.csdn.net/article/details/151407624。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。