国防科技大学智能科学学院周晗老师团队在国际机器人顶会IROS 2025上发表题为”Emergent Cooperative Strategies for Pursuit-Evasion in Cluttered Environments: A Knowledge-Enhanced Multi-Agent Deep Reinforcement Learning Approach” 的论文。该论文提出了一种面向复杂环境多智能体追逃的知识增强深度强化学习方法,并通过大量数值仿真和真实实验验证了本文方法的效率和优越性。NOKOV度量动作捕捉系统为真实实验提供Crazyflie无人机位置和速度数据,助力验证本文算法的有效性。
研究背景
为增强多智能体系统在协同追逐任务中的自主性和适应性,无模型深度强化学习 (DRL) 作为一种有前景的方案受到了越来越多的关注。然而,大多数现有基于DRL的追逐方法仍依赖个体奖励,并且在复杂场景中表现不佳。
本文贡献
为了在复杂环境中促进具有感知限制的追逐者之间的协作行为,本文提出了一种基于团队奖励的知识增强多智能体延迟深度确定性策略梯度 (KE-MATD3) 算法。主要贡献总结如下:
1、提出了一种基于团队奖励的 MADRL 方法,用于在杂乱环境中进行多智能体协同追逐,其中任务被建模为去中心化的部分可观测马尔可夫决策过程。
2、引入了一种知识增强 (KE) 机制,利用改进的人工势场法 (IAPF) 的见解,从而促进了具有挑战性的团队奖励的学习。
3、通过仿真和物理实验验证了追逐者之间协作行为的出现。
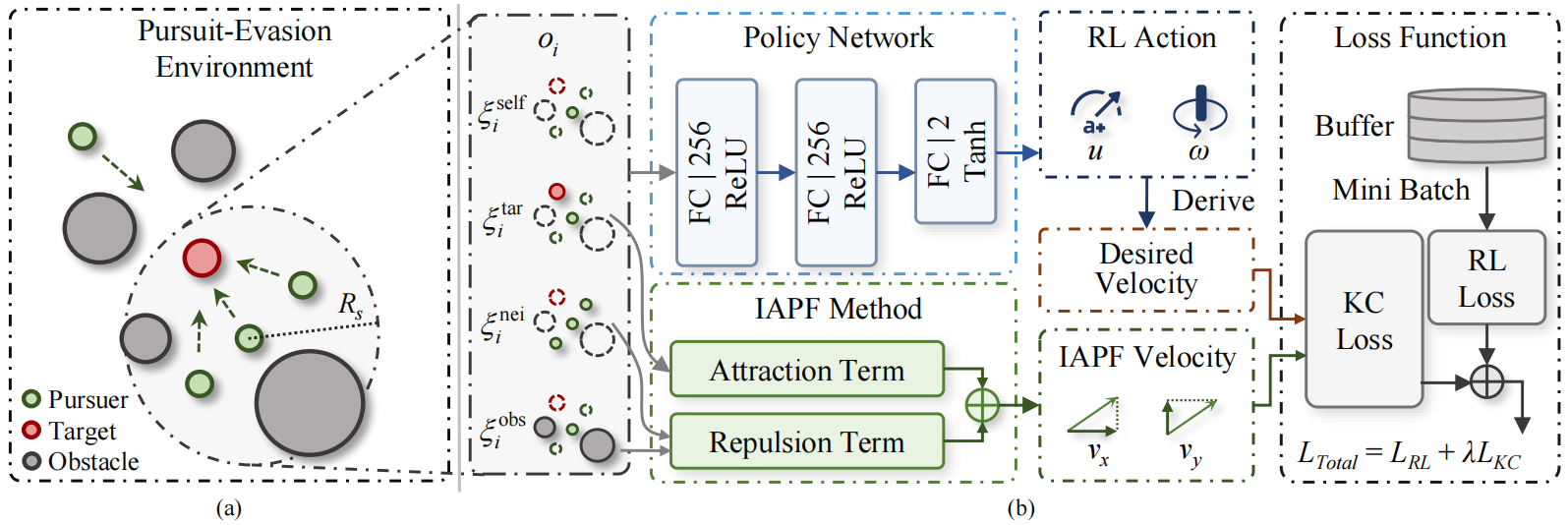
合作追逐任务的系统框架。(a) 多智能体追逐-逃避环境。(b) 本文提出的 KE-MATD3 算法。
数值仿真实验
在数值模拟中,本文算法(KE-MATD3)通过与多种基线算法(如 MATD3、MADDPG、MADDQN 及其变体)的比较,验证了其优越性。
结果显示,本文算法利用知识增强机制,显著提升了学习效率和最终性能,实现了最高的捕获成功率和最低的碰撞率。
在不同障碍物密度下,本文算法始终保持最佳性能,展现出强大的泛化能力。这表明本文算法能**有效促进复杂环境中的协同行为**,实现高效的目标捕获。
真实世界实验
在6.4×11×2 m实验场地中,包含5架Crazyflie 2.1四轴飞行器、NOKOV度量光学动捕捕捉系统、20 个圆柱形障碍物(半径20 cm,高1 m)和机载计算机。
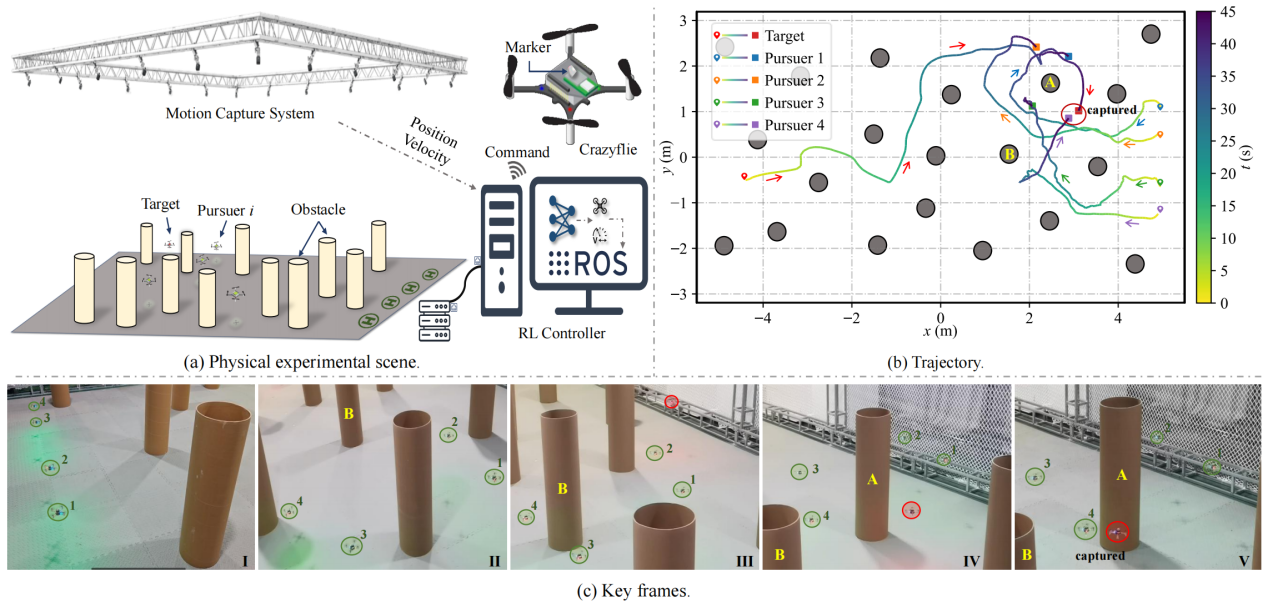
物理实验结果
NOKOV度量动作捕捉系统实时输出Crazyflie无人机的高精度位置和速度数据,通过ROS实时传输到机载计算机。
真实实验表明,本文方法能安全有效地完成捕获任务,同时实现追逐者之间的涌现式协同行为。
物理实验结果
NOKOV度量动作捕捉系统为真实实验提供多架Crazyflie无人机位置和速度数据,助力验证本文算法的有效性。
作者简介
孙懿豪,国防科技大学智能科学学院,博士研究生,主要研究方向为无人机集群分布式决策技术
闫超,南京航空航天大学自动化学院,副研究员,博士,主要研究方向为深度学习、多智能体强化学习、无人集群协同控制与智能决策
周晗,国防科技大学智能科学学院,副教授,博士,主要研究方向为无人系统协同控制
相晓嘉,国防科技大学智能科学学院,研究员,博士生导师,主要研究方向为无人系统技术
姜杰,中国运载火箭技术研究院,中国科学院院士,博士生导师,主要研究方向为导航制导与控制、运载火箭总体设计