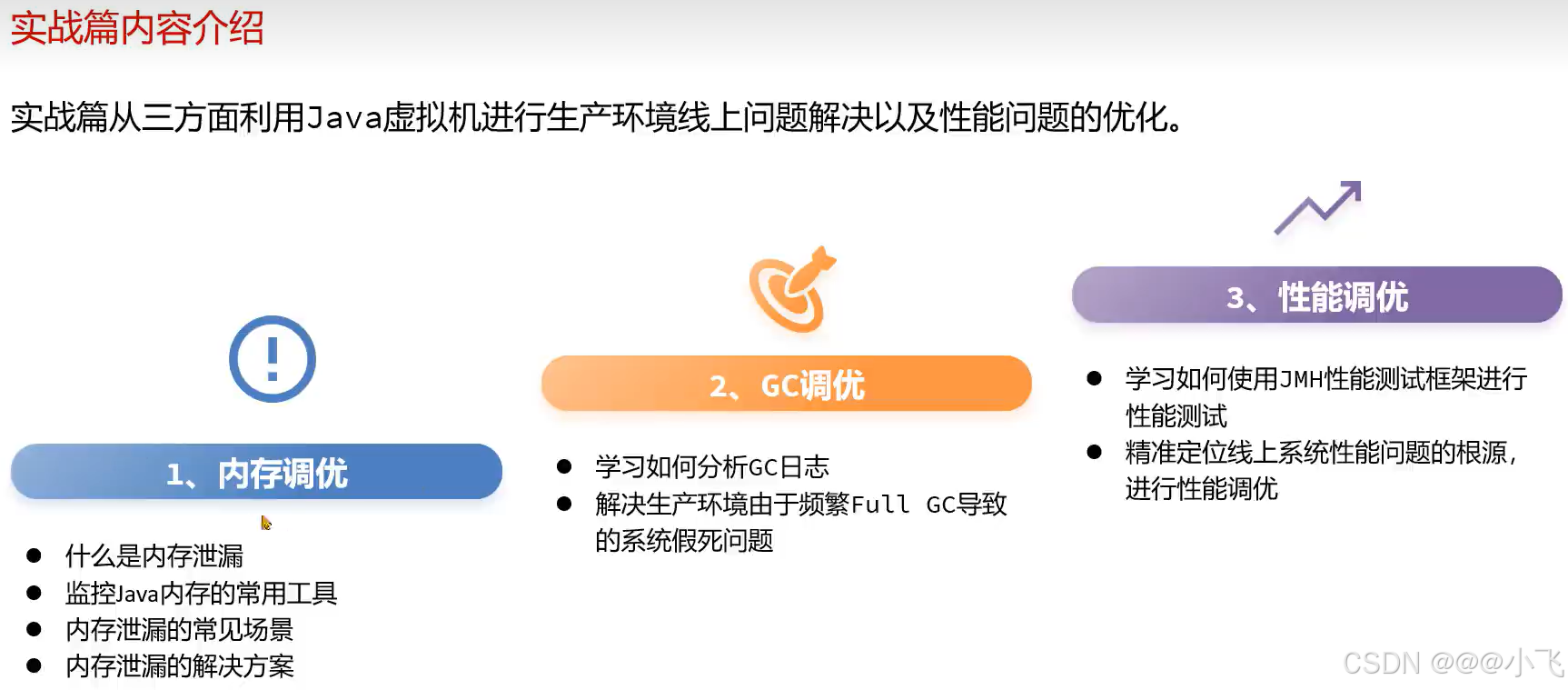

内存泄漏和内存溢出
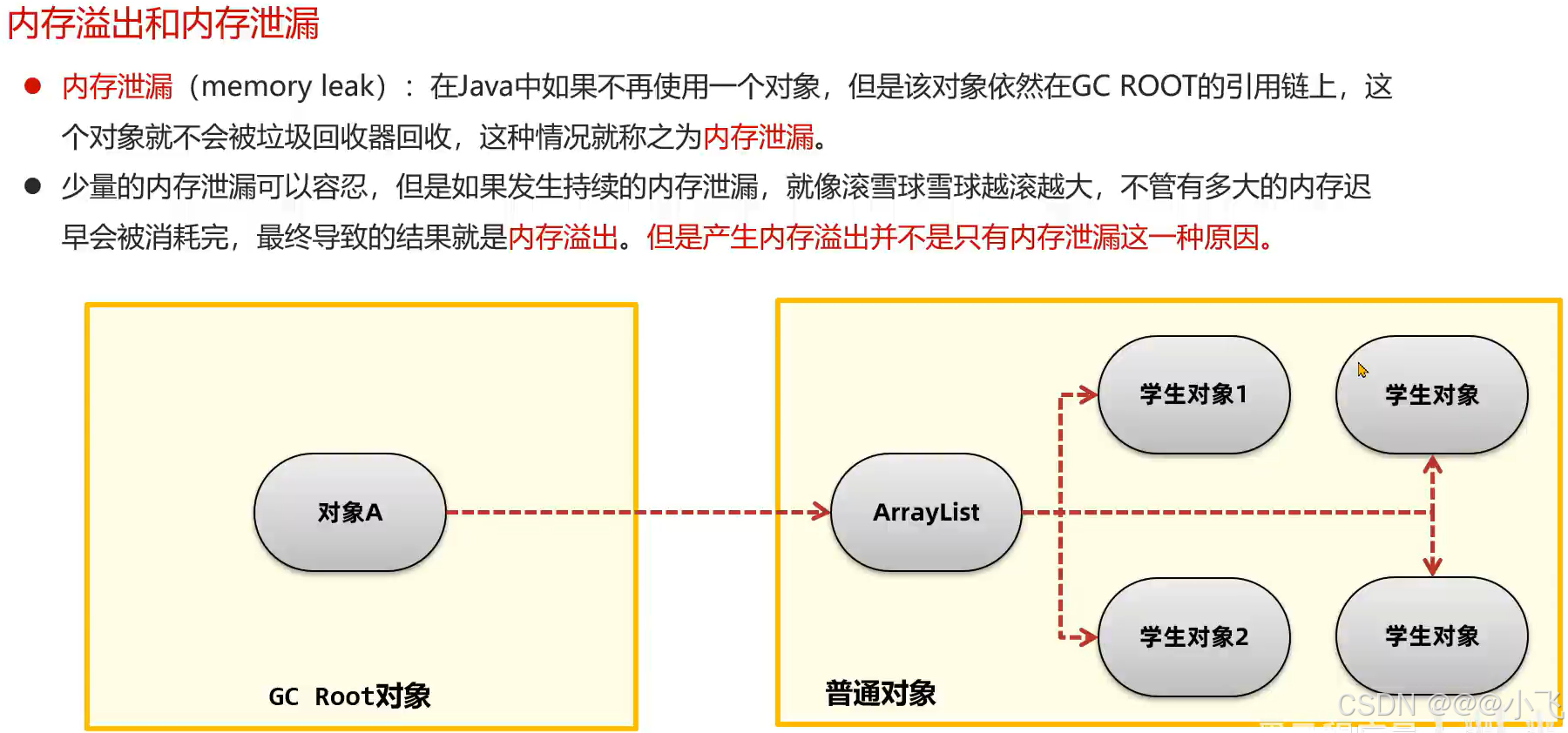
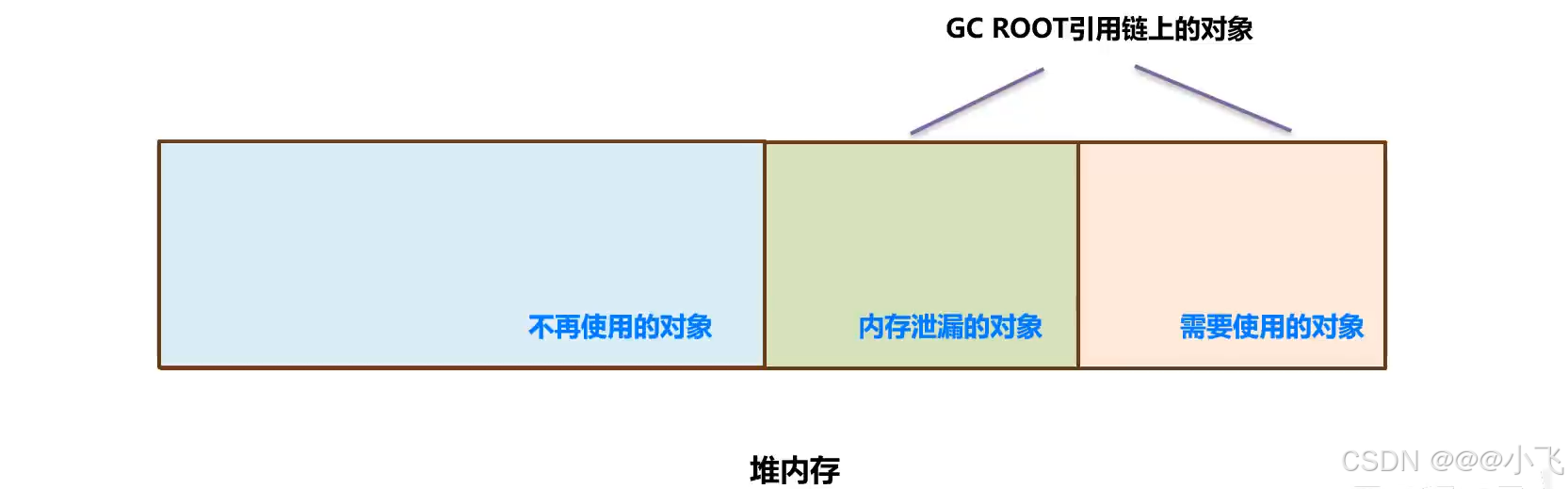
解决内存泄漏
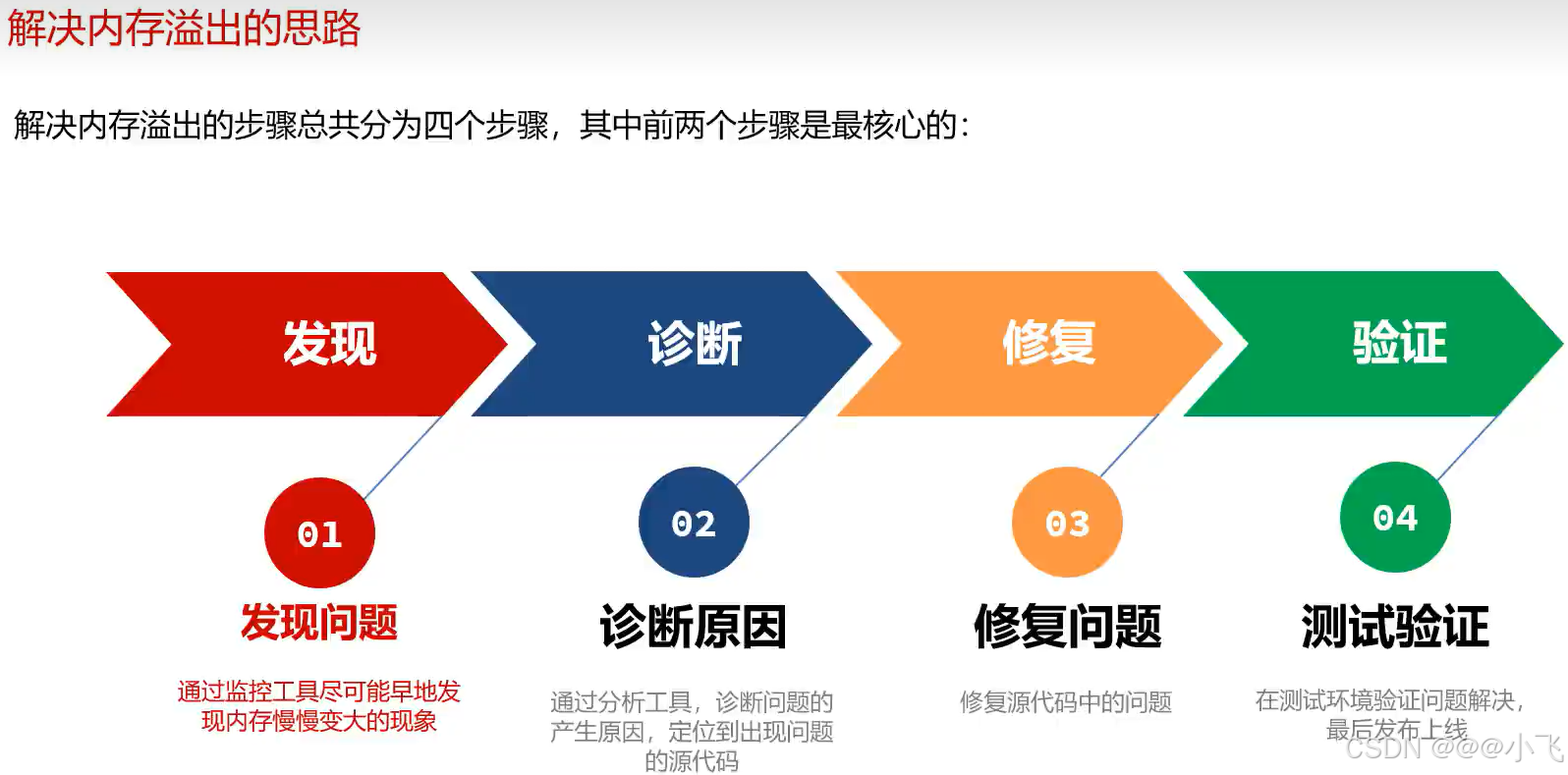
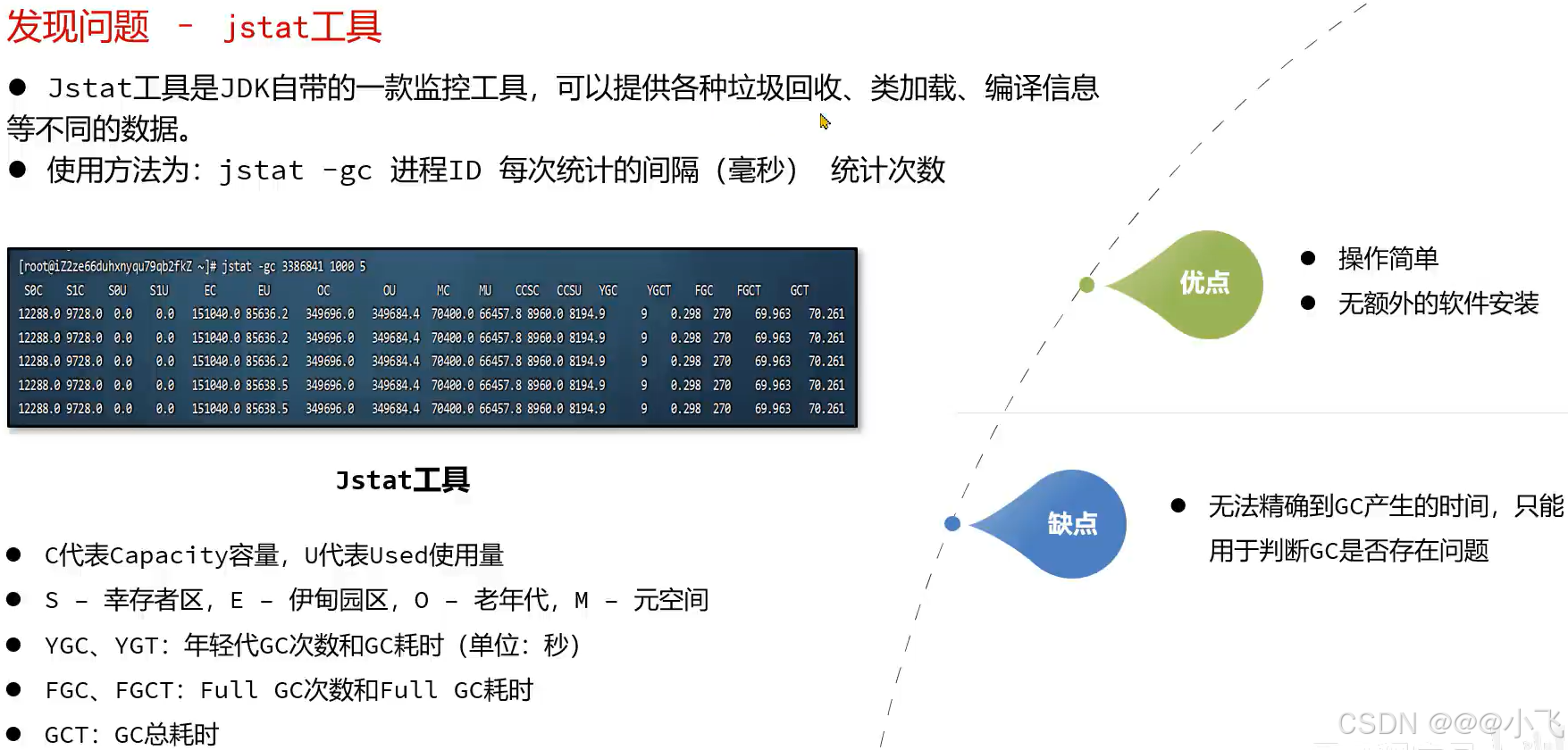
发现问题
监控 top 命令

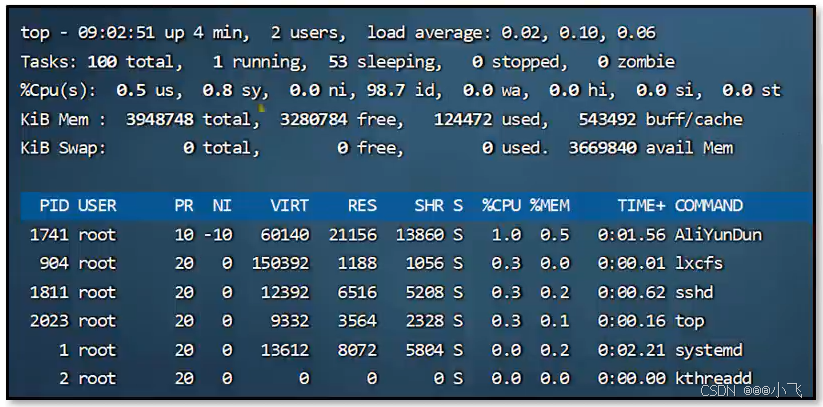
load average: 0.0.2, 0.10, 0.06:过去的1、5、15分钟系统负载率为 2%、10%、6%
3948748 total:代表系统总内存,单位为 KB
3280784 free:代表系统剩余内存,单位为 KB
used:当前使用的内存
buff/cache:系统缓存
PID:进程ID
VIRT:虚拟内存(不用过多关注)
RES:常驻内存(重点关注,基本代表该进程使用了多少内存)
SHR:共享内存(操作系统只加载一次,多进程共享,由于常驻内存包含了共享内存,所有计算进程使用的内存需要用常驻内存减去共享内存)
&CPU:cpu使用率,1.0 代表cpu有 1%的使用时间
%MEM:进程占用系统实际的物理内存
TIME+:进程启动以来所累计消耗cpu的时间
COMMAND:进程启动命令
该命令只能看在系统的大致情况,无法查看JVM中的内存情况,命令适合做初步判断
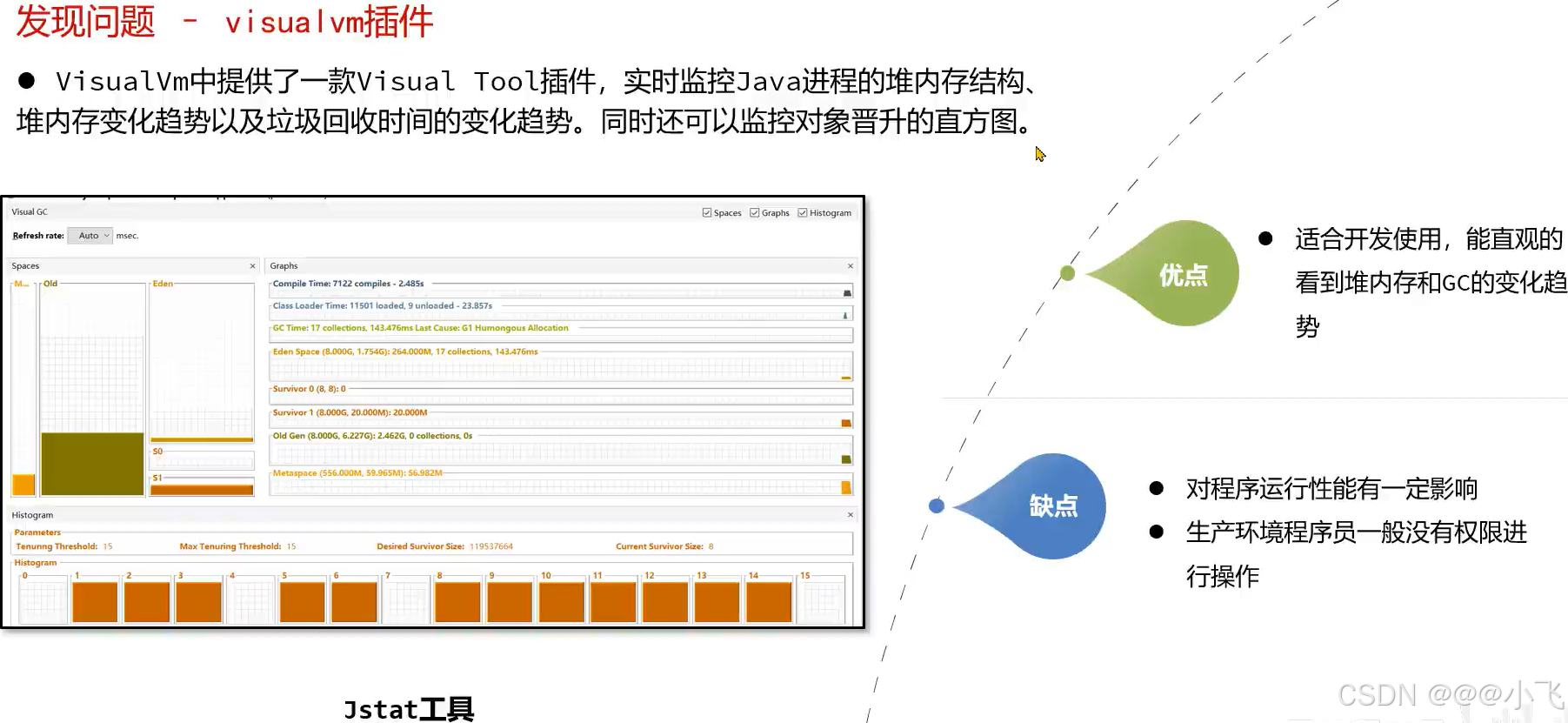
Visualvm
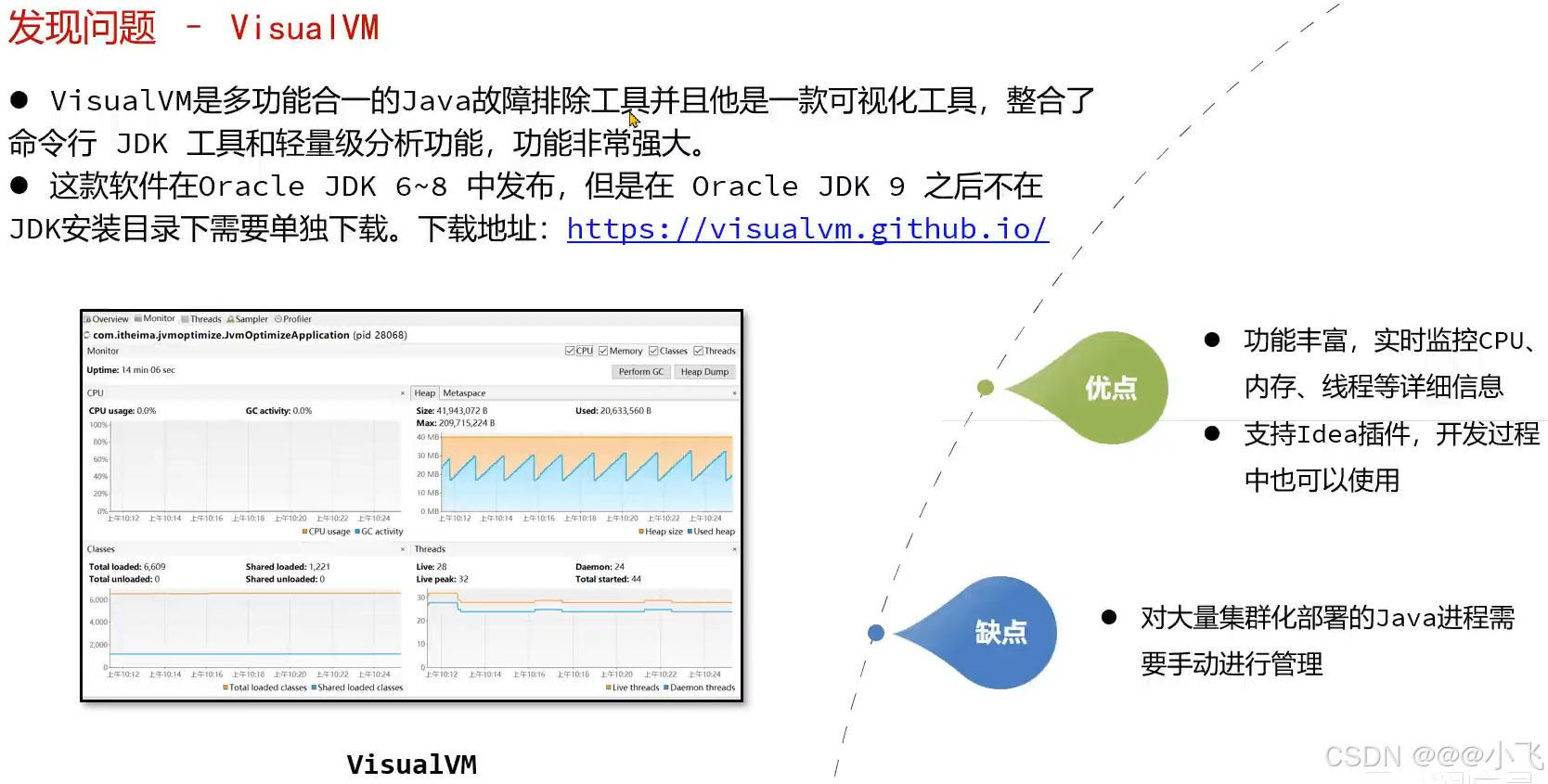
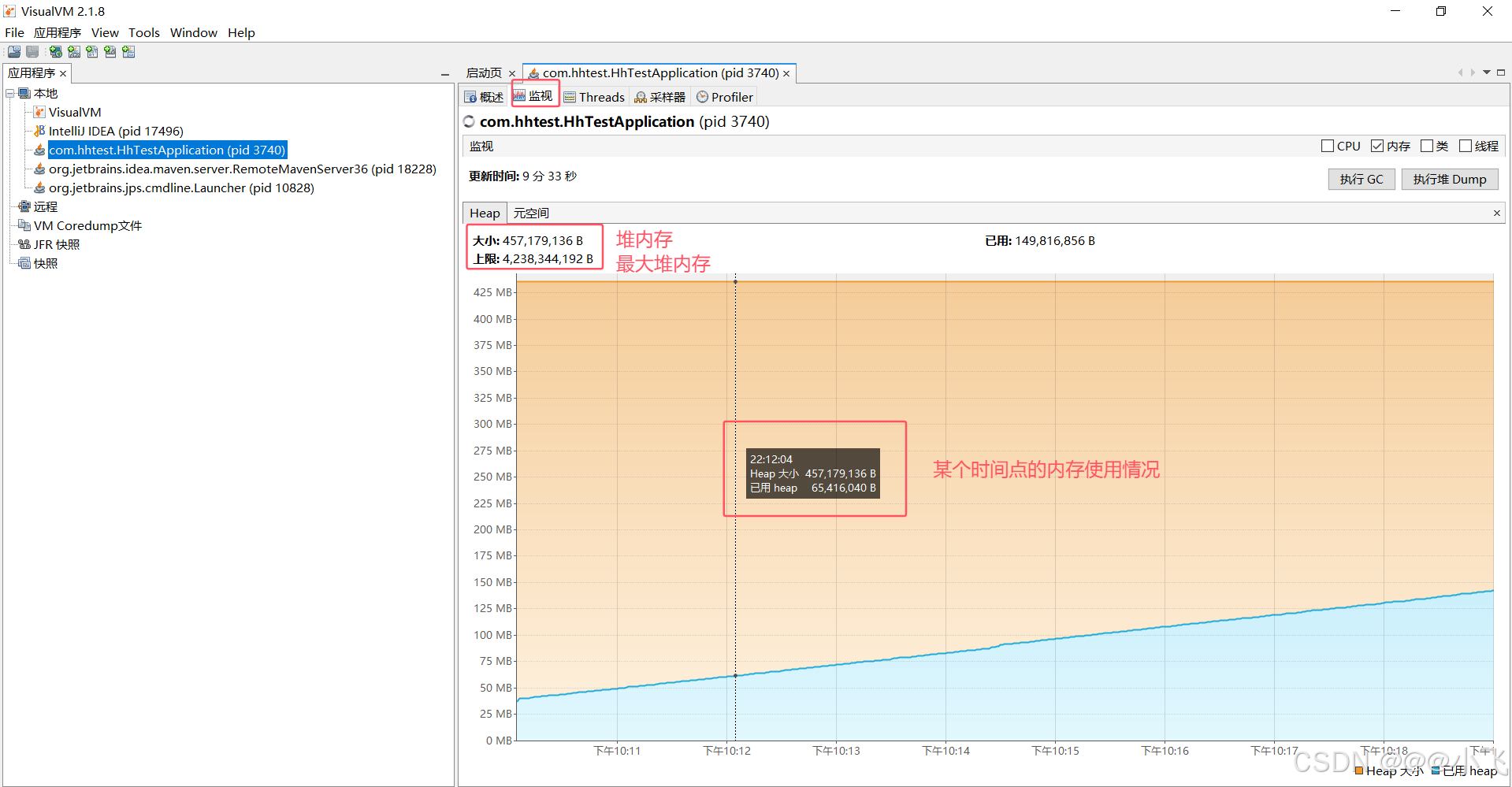
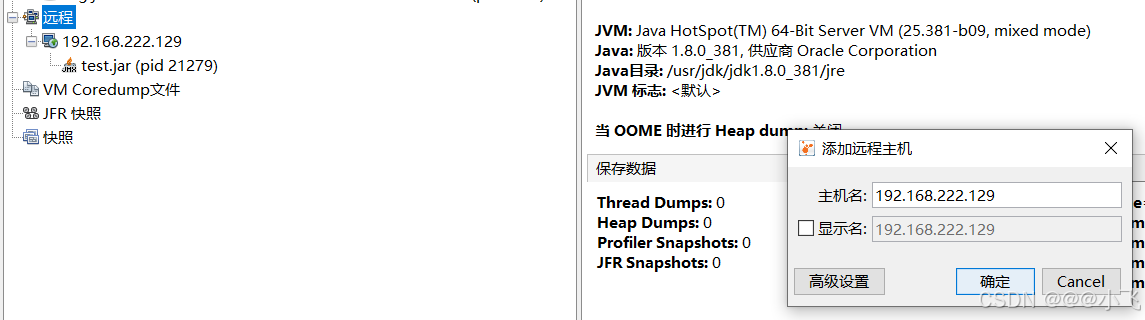
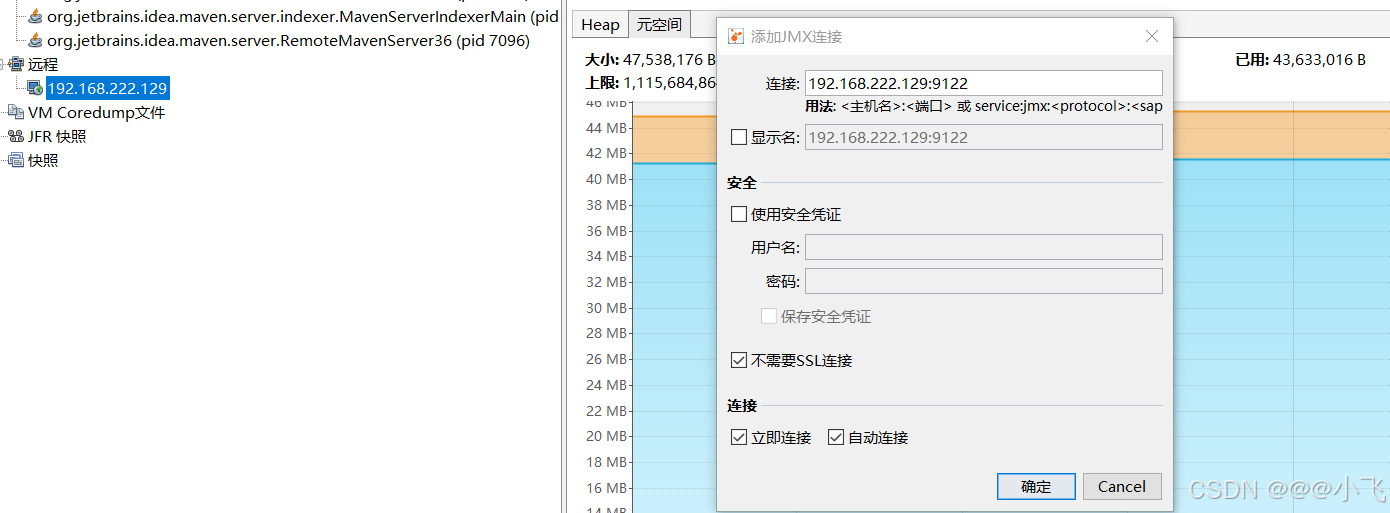
使用 Visualvm 远程连接
禁止线上环境 使用 Visualvm 连接(可能导致不稳定),建议在测试环境来定位问题
运行 jar 包的时候开启 Visualvm 远程连接功能,比如:
java -Djava.rmi.server.hostname=<你的服务器IP地址> \
-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=<指定的端口号> \
-Dcom.sun.management.jmxremote.ssl=false \
-Dcom.sun.management.jmxremote.authenticate=false \
-jar your-app.jar
-Dcom.sun.management.jmxremote.ssl=false :不使用 SSL
-Dcom.sun.management.jmxremote.authenticate=false :不需要认证
Arthas
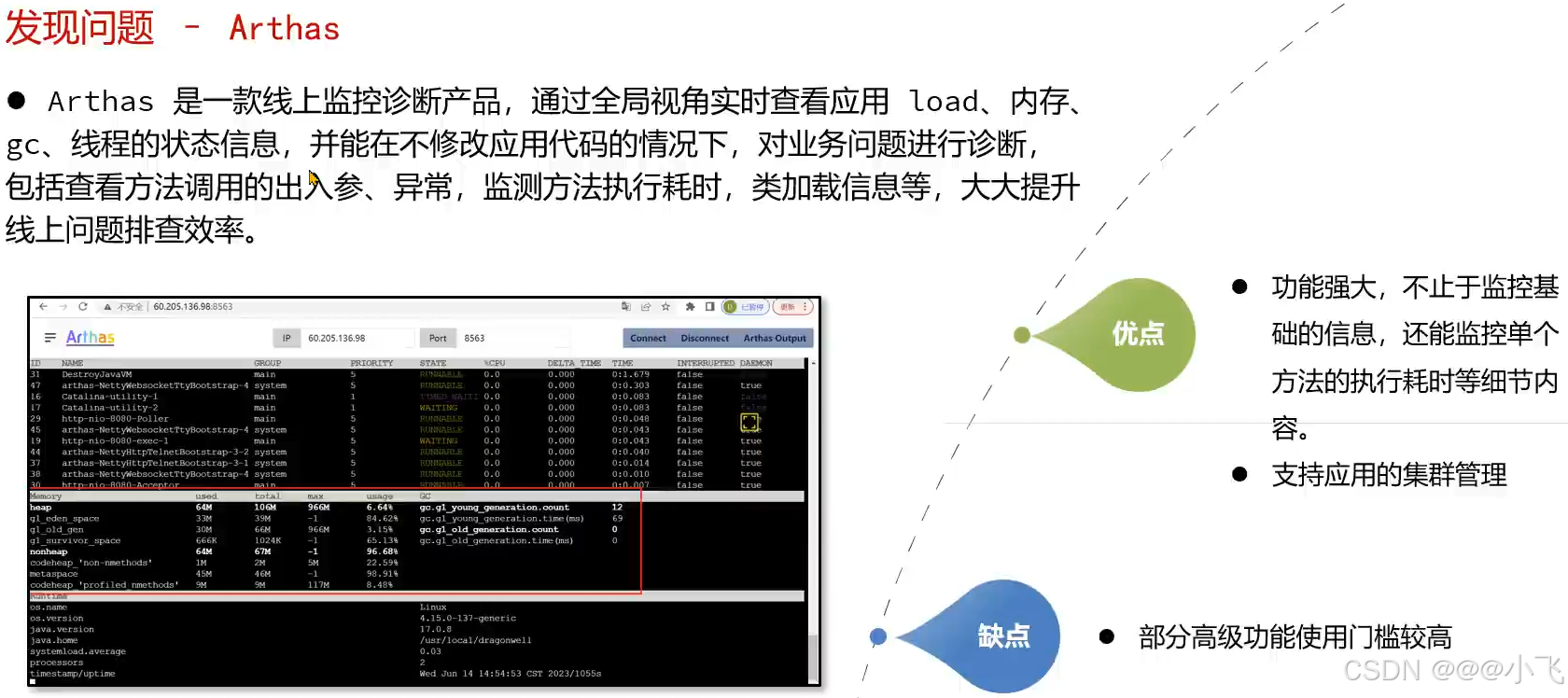

Arthas Tunnel | arthas (aliyun.com) 文档,下载好 arthas-tunnel-server 服务后就可以启动了
java -jar -Darthas.enable-detail-pages=true arthas-tunnel-server-4.0.2-fatjar.jar-Darthas.enable-detail-pages=true 是开启Web页面
<!-- Arthas 依赖 -->
<dependency>
<groupId>com.taobao.arthas</groupId>
<artifactId>arthas-spring-boot-starter</artifactId>
<version>3.6.7</version>
</dependency>
# arthas 配置
arthas:
app-name: ${spring.application.name} # 应用名称
tunnel-server: ws://127.0.0.1:7777/ws # tunnelServer地址,默认7777端口
# http-port: 8080 # http访问端口 # 浏览器访问 Arthas 的 Web 界面端口,不配置默认8080
# telnet-port: 9999 # Telnet 远程连接 Arthas 并执行命令 的端口,不配做默认9999启动tunnel服务之后就可以在 127.0.0.1:8080/apps.html 看到所有连接的 springboot 程序了


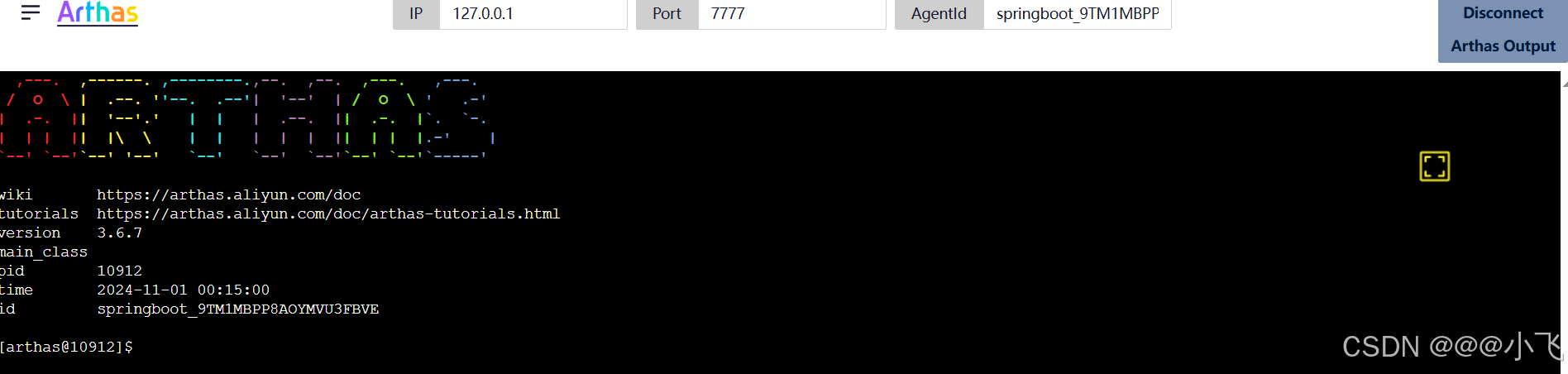
这样就可以在浏览器上同时管理多个SpringBoot 程序了
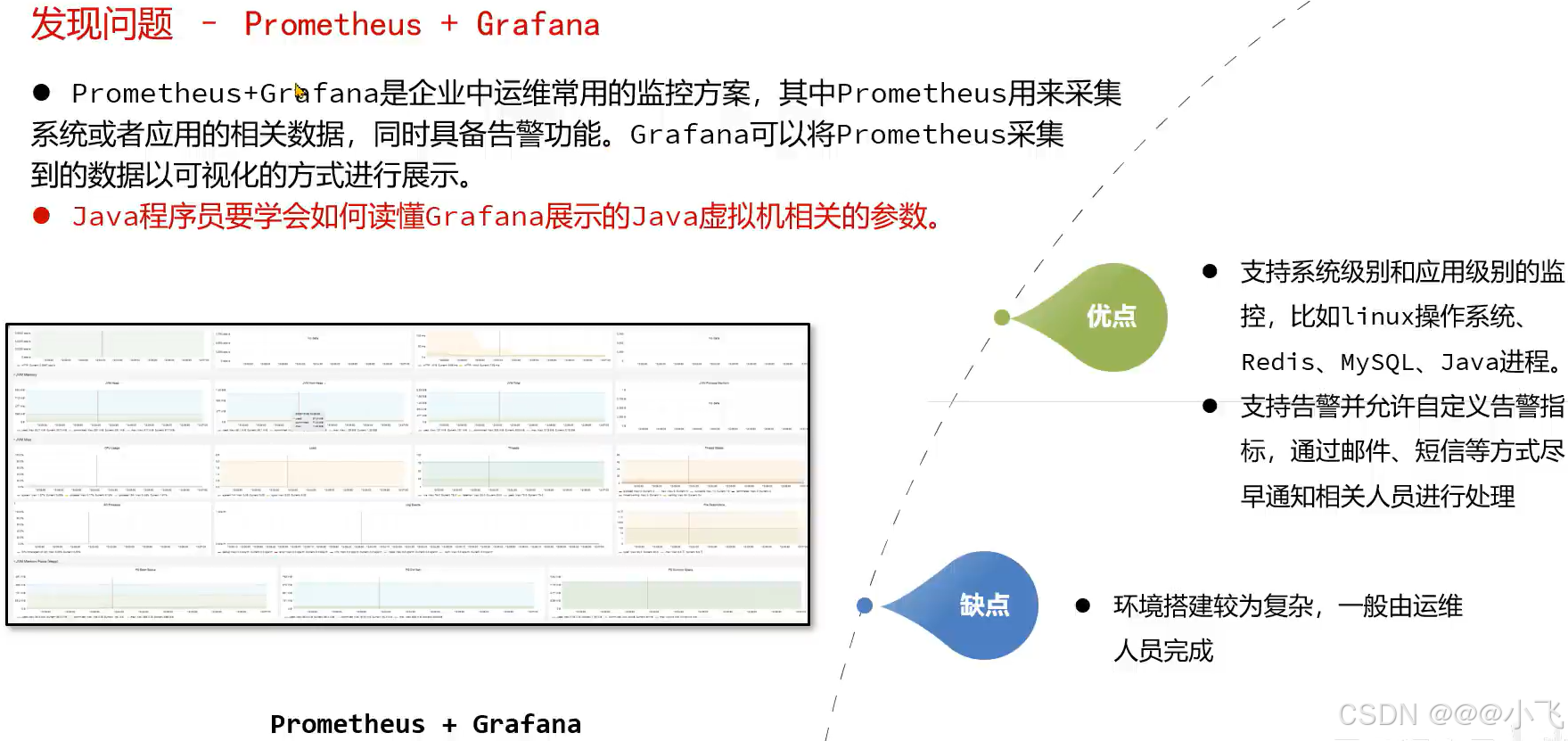
Prometheus + Grafana
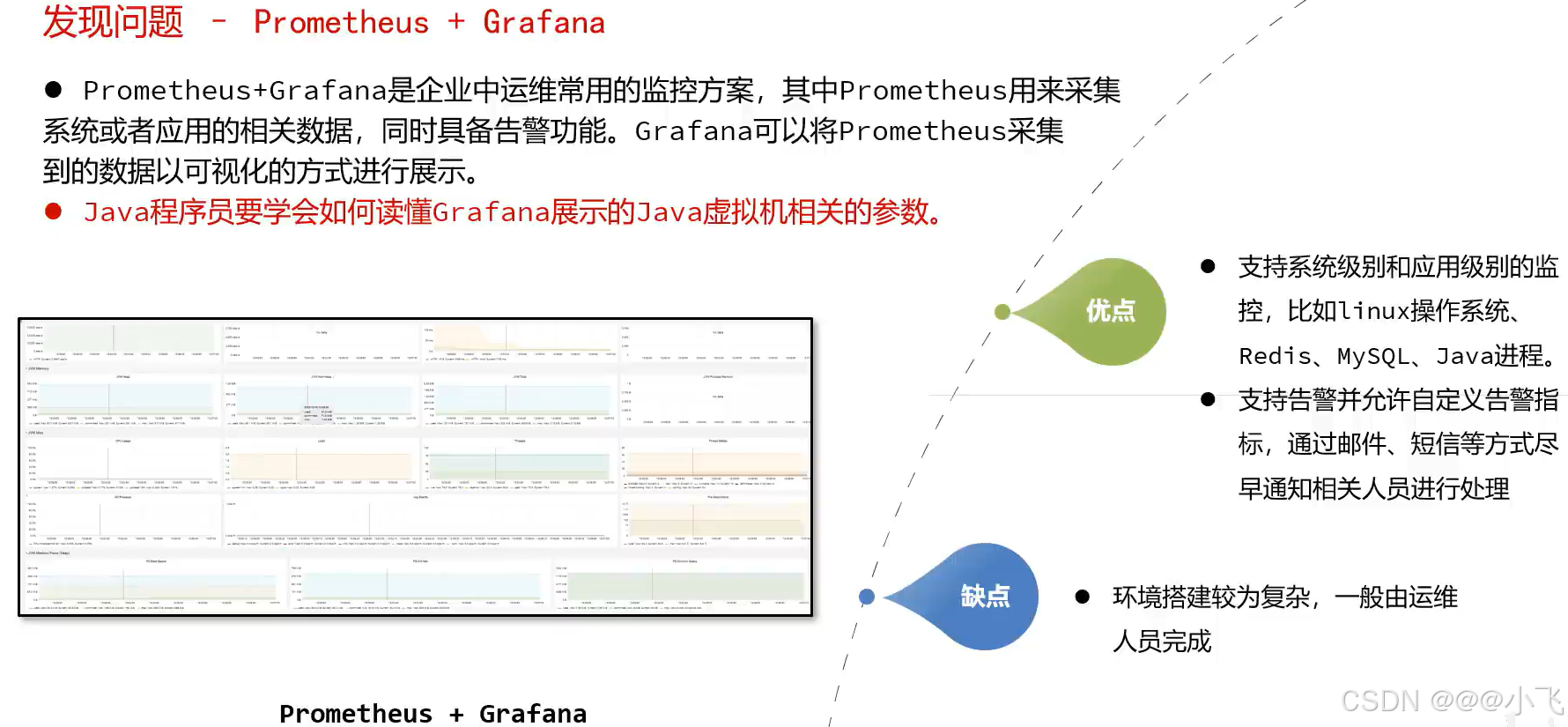
在 SpringBoot 将 JVM 参数通过HTTP 的形式暴露出去:
<!-- 监控 springboot 程序依赖-actuator -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Prometheus监控依赖,可以将 actuator 的指标数据转换为 Prometheus 的格式,实现可视化监控 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
<scope>runtime</scope>
</dependency>management:
endpoints:
web:
exposure:
include: "*" # 开发所有端点。这意味着所有管理端点都将通过 HTTP 暴露出来,方便进行监控和管理。
endpoint:
metrics:
enabled: true # 启用指标端点。这允许收集和暴露应用程序的各种指标数据。
metrics:
export:
prometheus:
enabled: true # 启用 Prometheus 指标导出。这使得应用程序的指标数据可以被 Prometheus 监控系统抓取和分析。
tags:
application: ${spring.application.name} # 应用名称启动后就可以在 /actuator 或者 /actuator/prometheus 接口中查看 jvm 参数了
注:两者框架都可以监控 jvm ,micrometer-registry-prometheus 可以可视化监控指标,但是监控不全面,没有健康检查、日志、线程 等监控信息。而 spring-boot-starter-actuator 监控全面但是不能可视化监控指标。两者结合,相得益彰。
堆内存状况对比

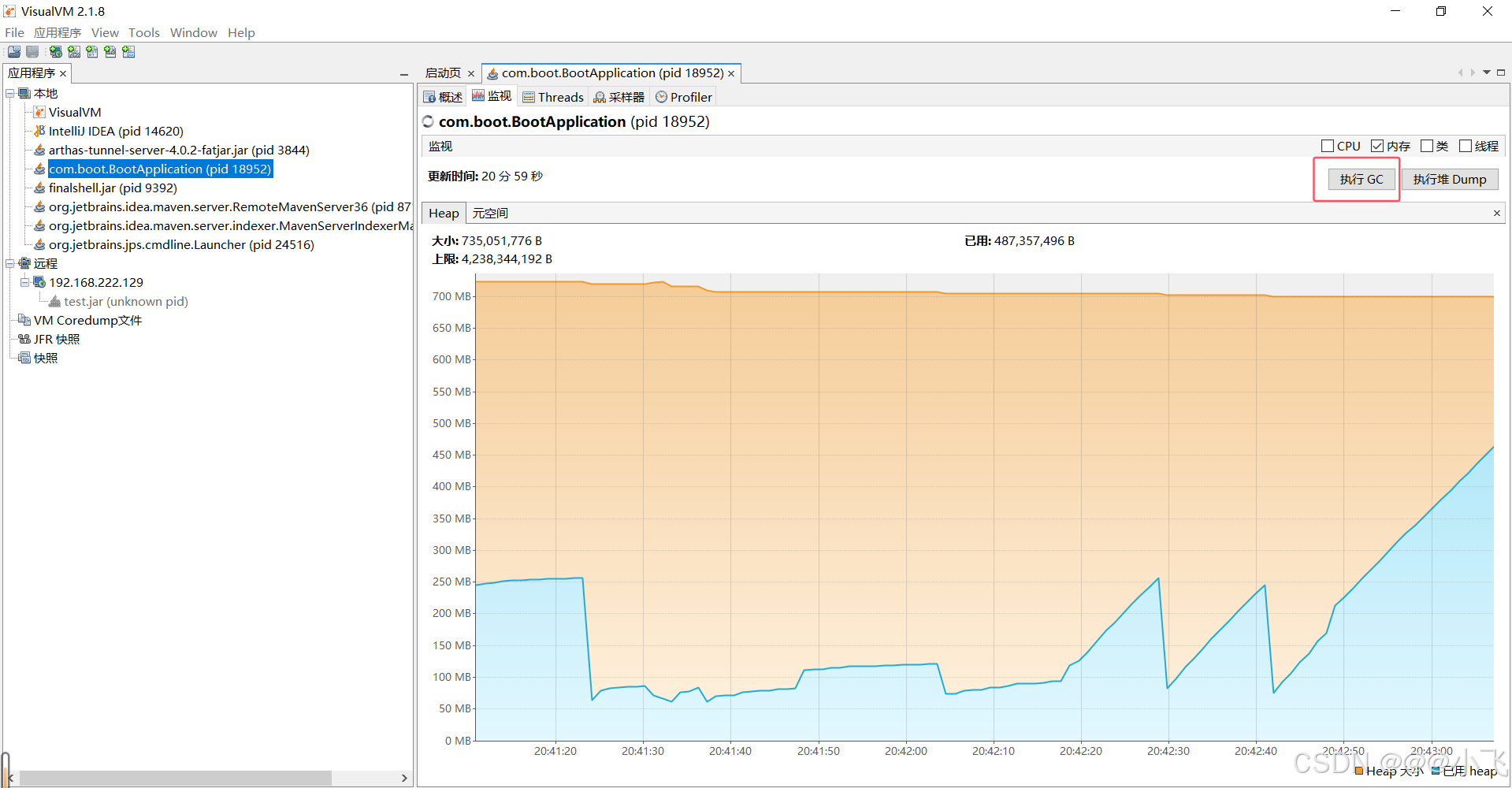
可以观察多次FGC之后内存占比有没有增加
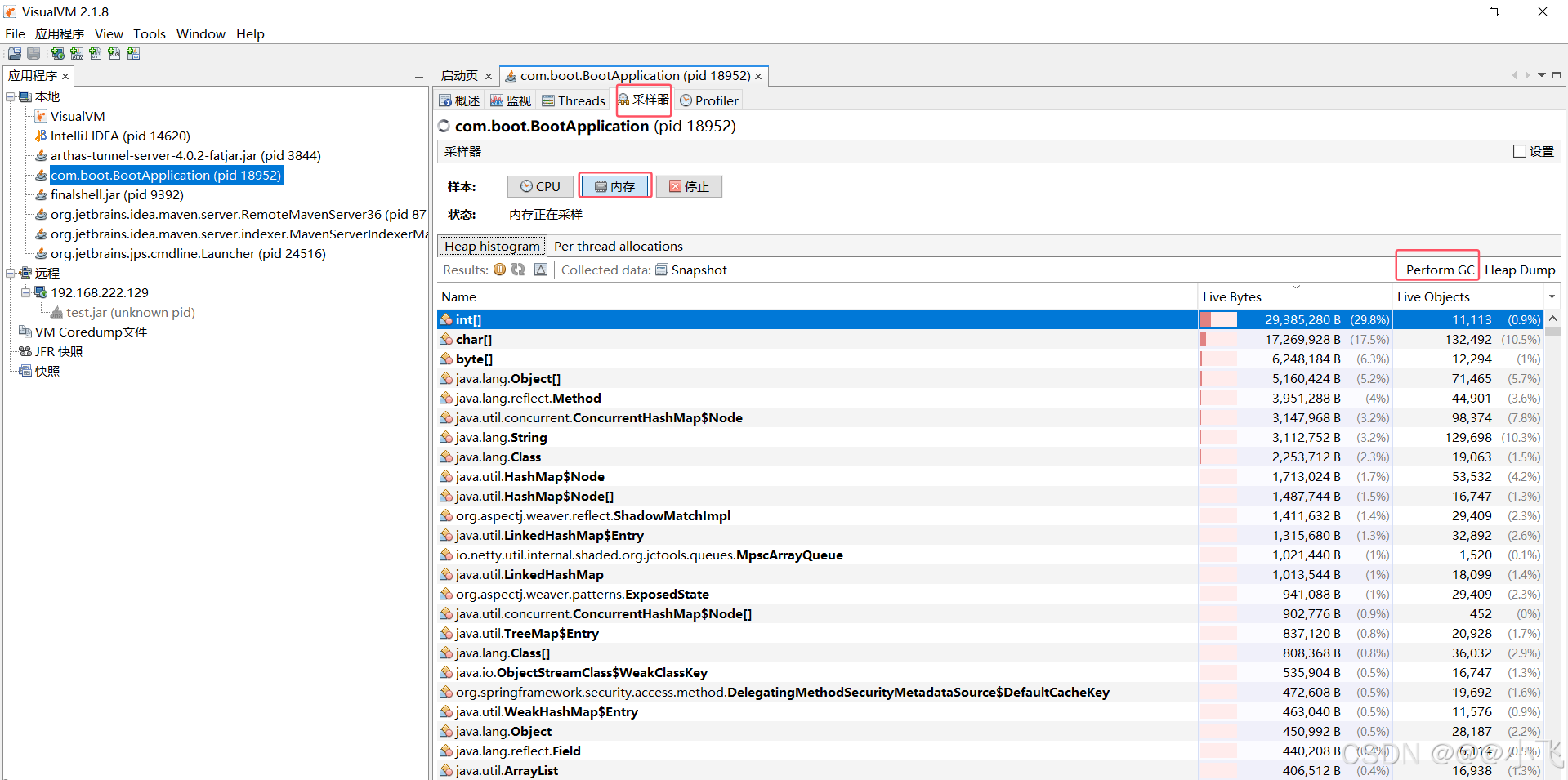
也可以通过采样器来观察GC之后又哪些对象占比多少,是否一直存在.
代码中的内存泄露
equals() 和 hashCode() 导致


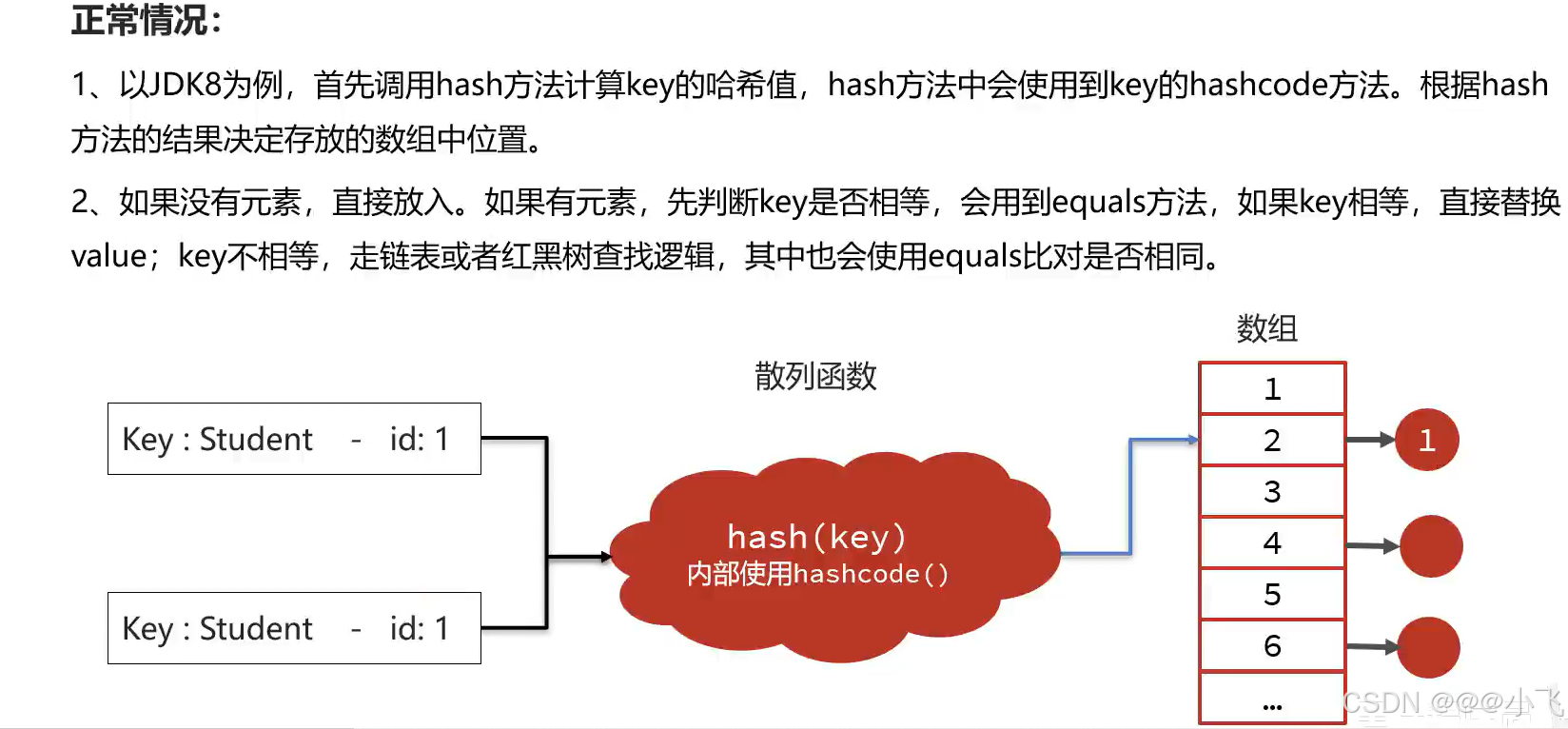
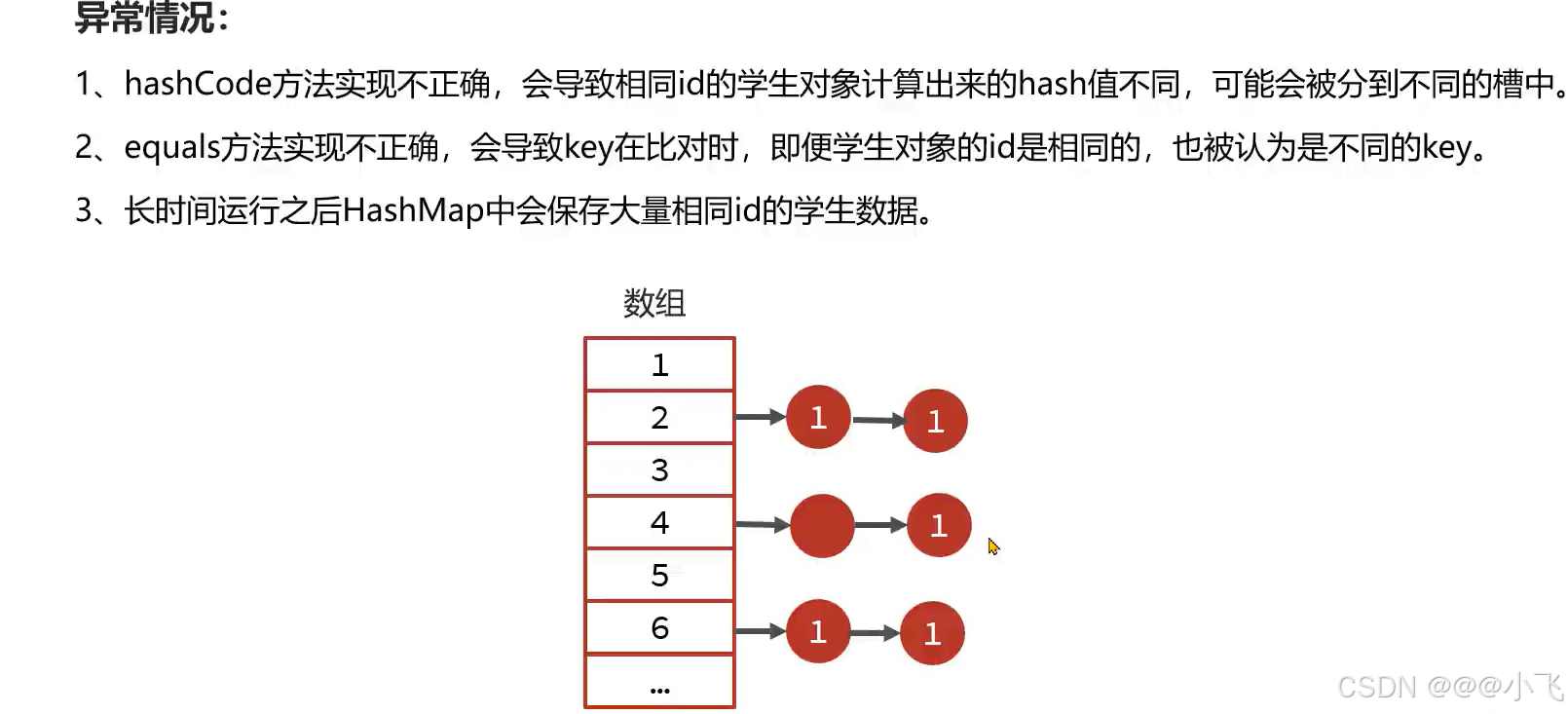

当向 HashMap put 一个数据时,HashMap 会对 Key 先调用 hashCode() 方法来判断哈希冲突,如果哈希冲突就会调用 equals() 判断是否相同,不相同就尾插法道数组中(或者红黑树),相同就不能插入(key相同)。
如果类没有重写 equals() 和 hashCode() 方法,那么在调用的时候就会使用父类 Object 的 equals() 和 hashCode() 方法。Object 类的 hashCode() 方法为每个对象返回一个唯一的哈希码(通常是基于对象的内存地址),而 Object 类的 equals() 方法仅当两个对象引用指向同一个对象时才返回 true。
内部类引用外部类

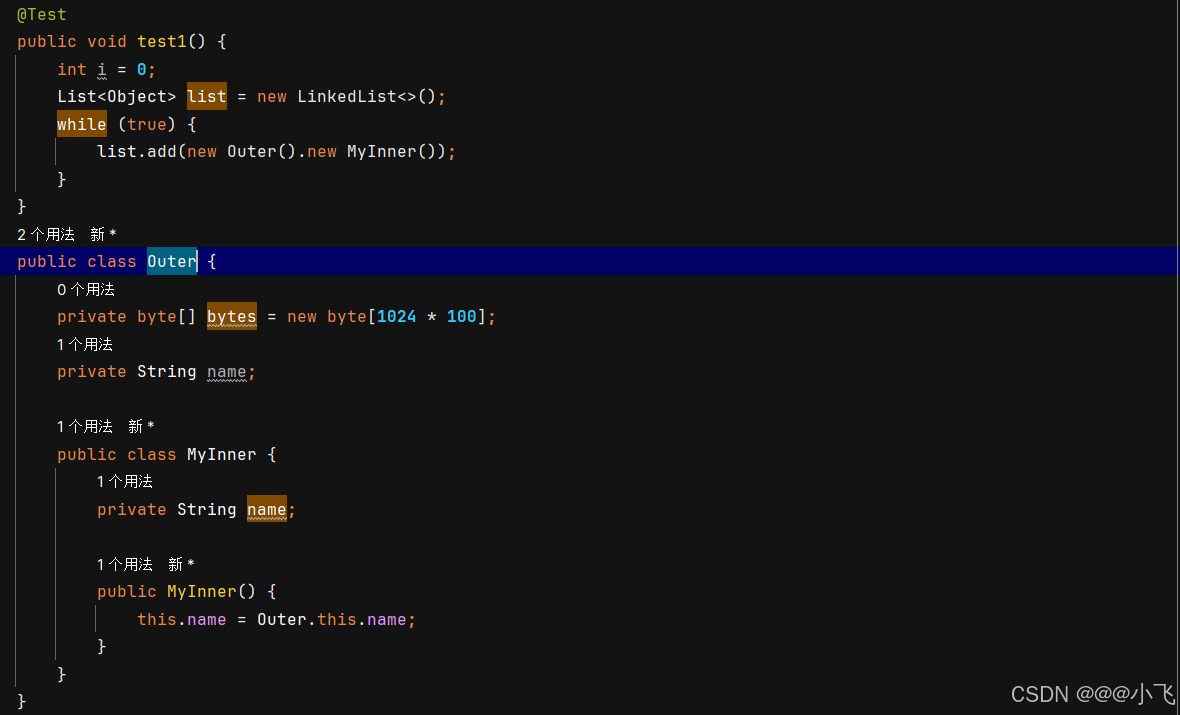
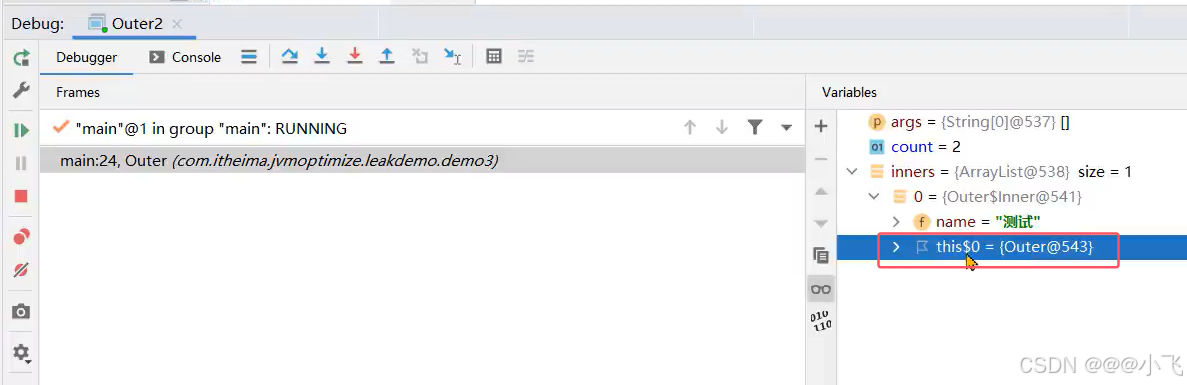


反编译之后看到内名内部类是会传入调用者对象作为赋值,一直持有改对象


ThreadLocal 的使用

String 的 intern 方法

intern 方法是将字符串存到字符串常量池,这个在 JDK8(8的常量池在堆中) 中依然会内存溢出
静态字段保存对象

@Lazy :懒加载注解,Spring 容器启动的时候并不会马上去加载这个Bean,而是当这个类被使用的时候才去加载到 IOC 中
资源没有正常关闭
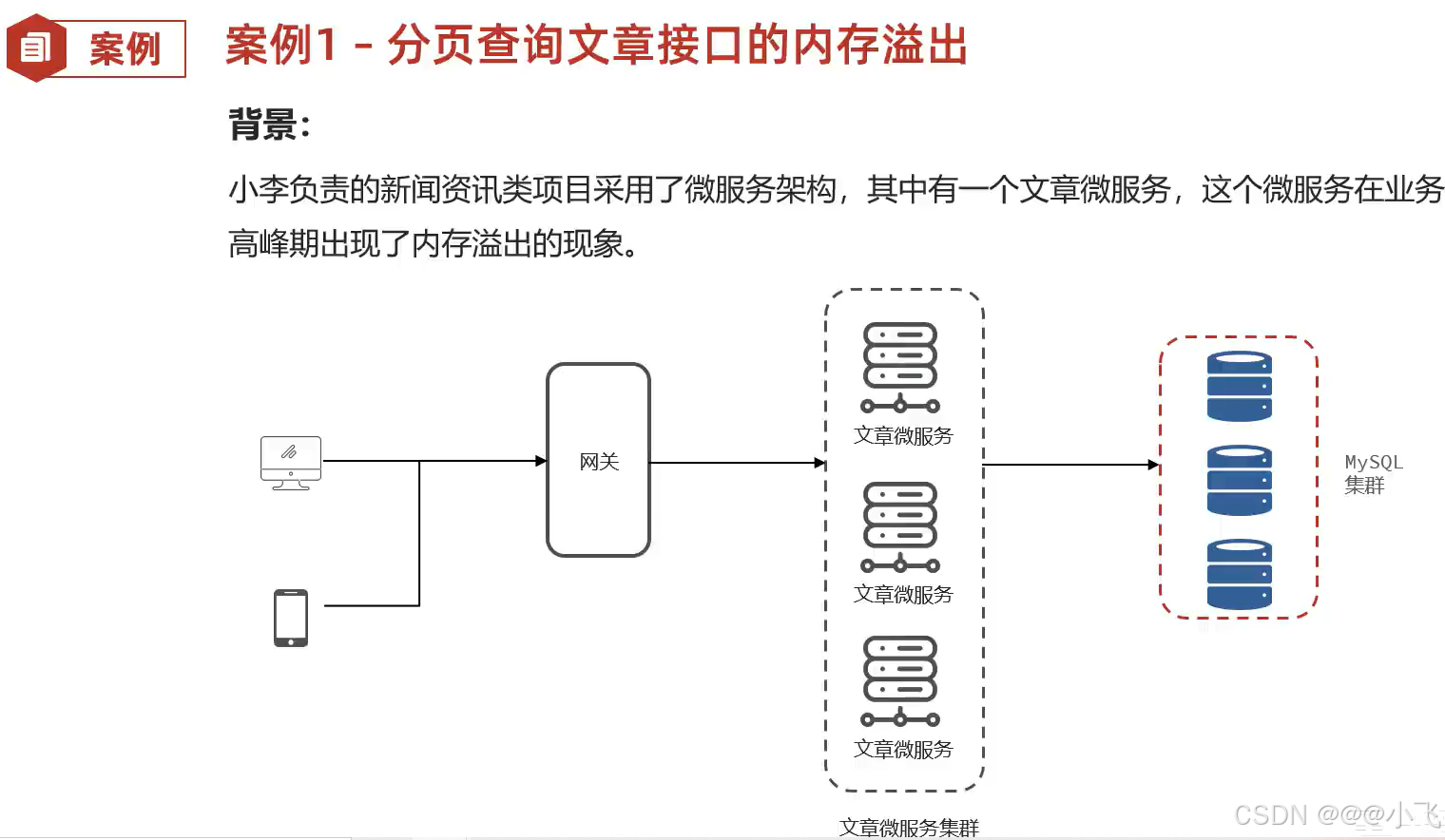
并发请求导致内存溢出
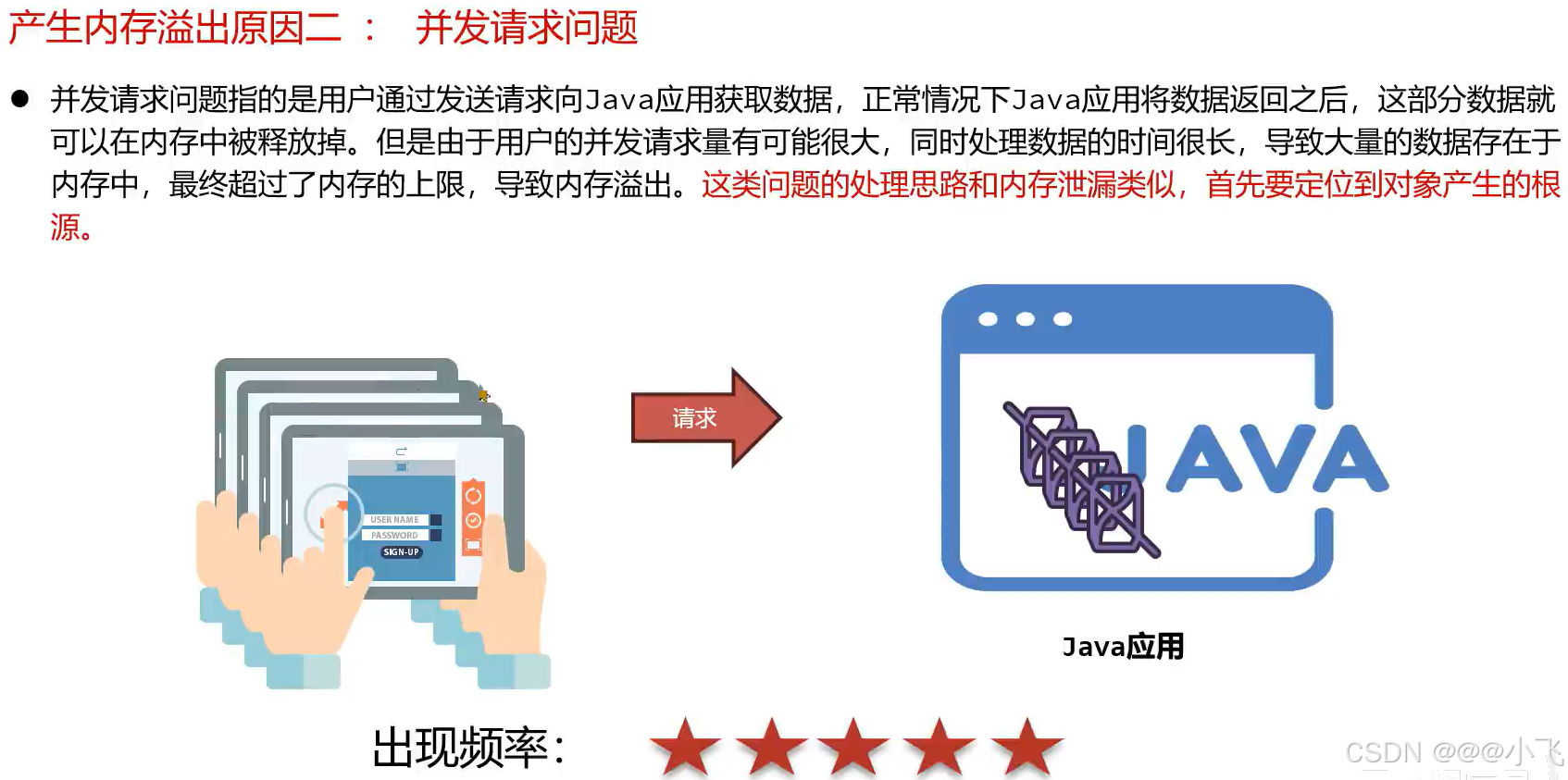
这个问题导致内存溢出有一般满足3中情况:
1、单次请求的数据量较大
2、并发量超过了200(springboot 中 tomcat 默认线程并发数是200)
3、单次处理时间比较长

这里可以使用 Apifox 一体化工具测试来并发测试发现内存溢出问题
问题诊断
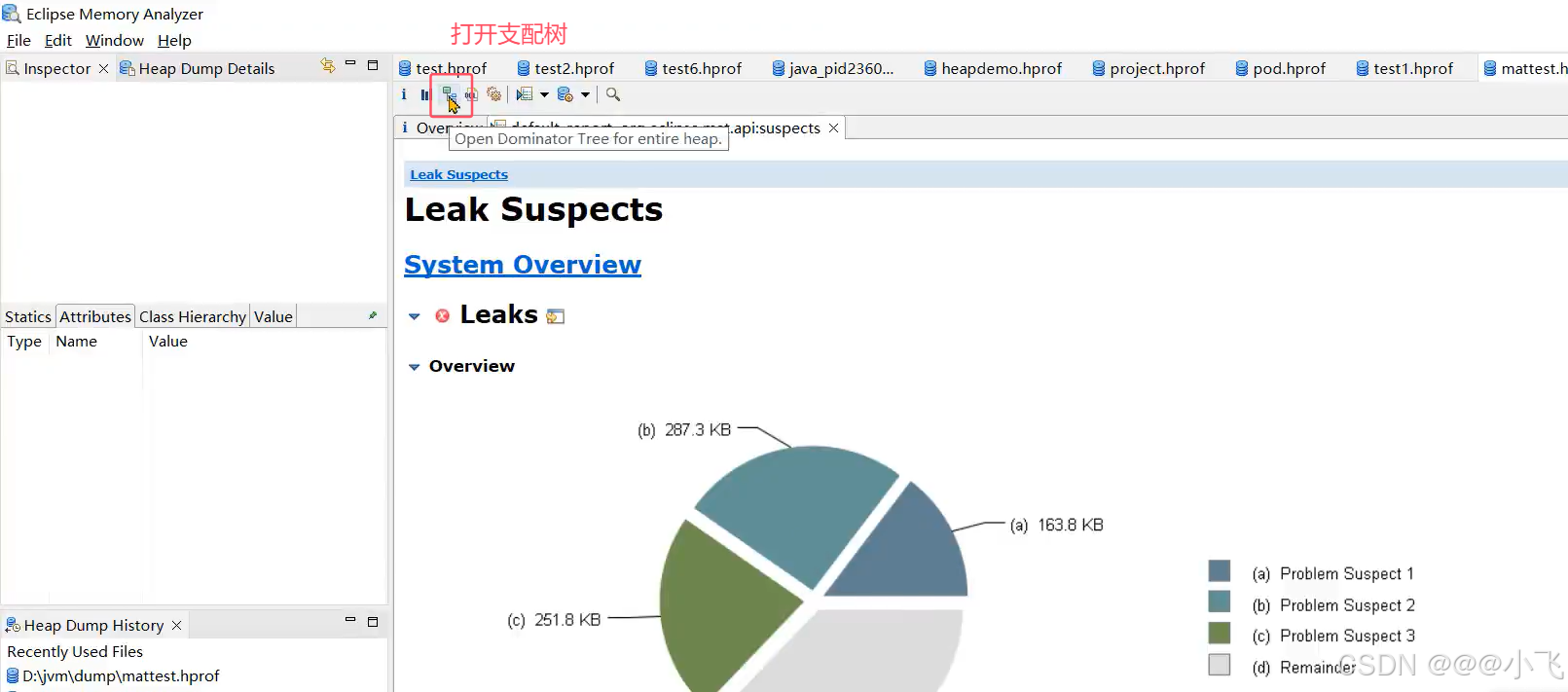
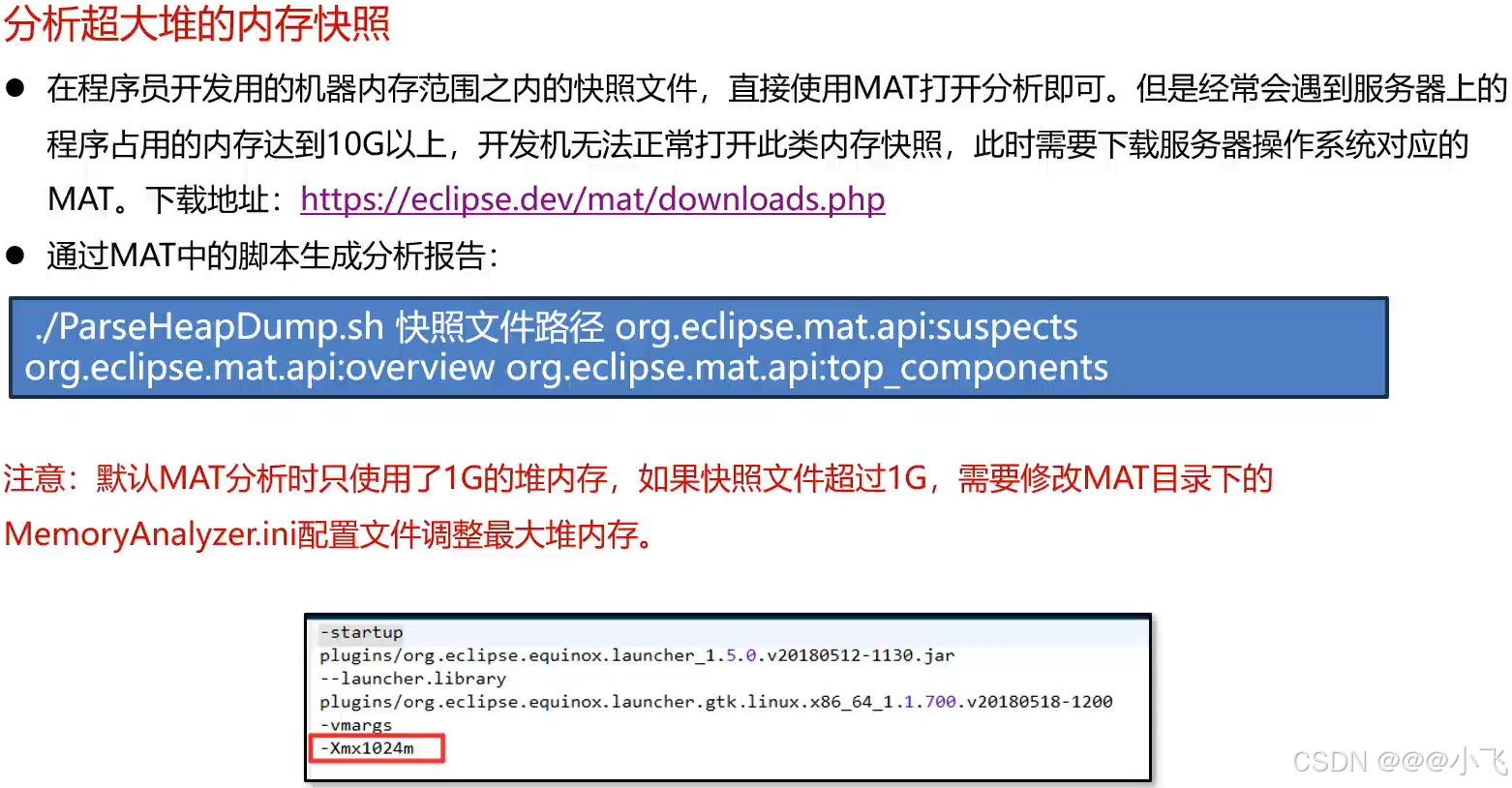
MemoryAnalyzer 诊断工具

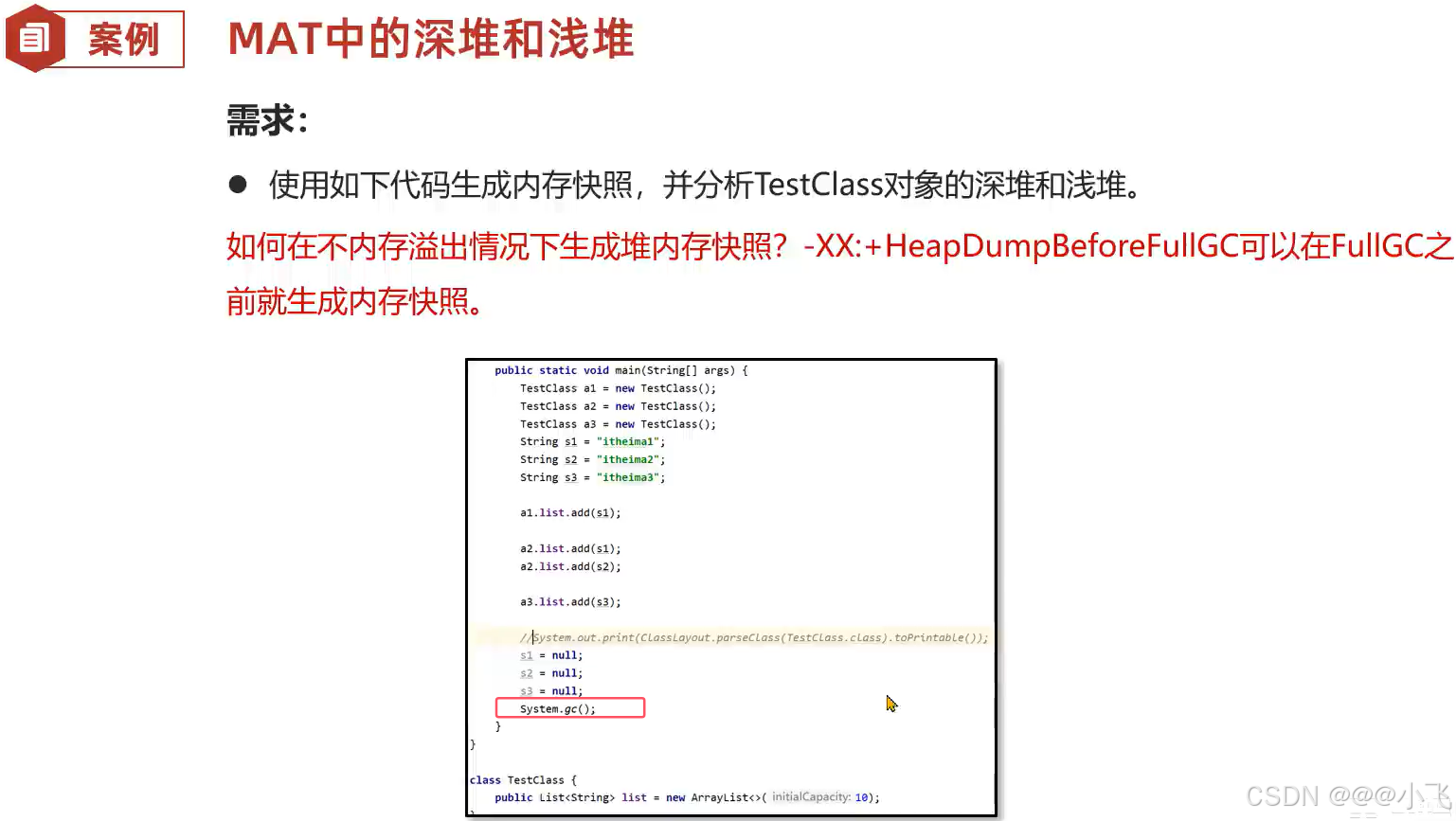
可以设置如下参数来测试内存溢出生成的快照文件:
-Xms256m -Xmx256m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=E:\\java\\study\\springboot\\src\\main\\resources\\jvm\\memory.hprof
当内存溢出时会生成一个内存快照 .hprof 文件,可以使用 MemoryAnalyzer (MAT)这种 jvm 内存分析工具打开改该文件,根据展示的信息可以定位到问题在哪。
也可以简单的将 .hprof 文件 拖到 IDEA 中 也可以定位问题
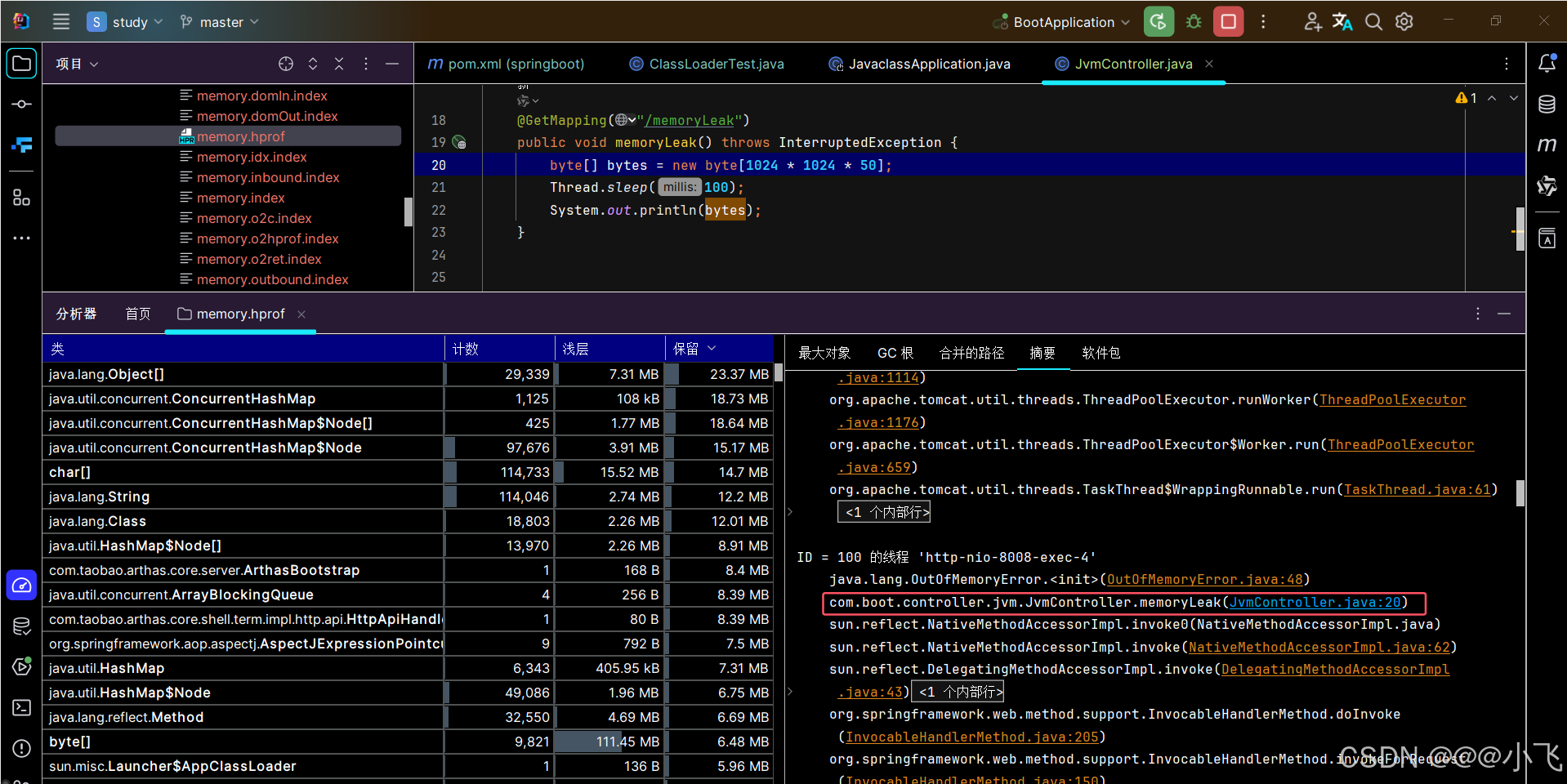
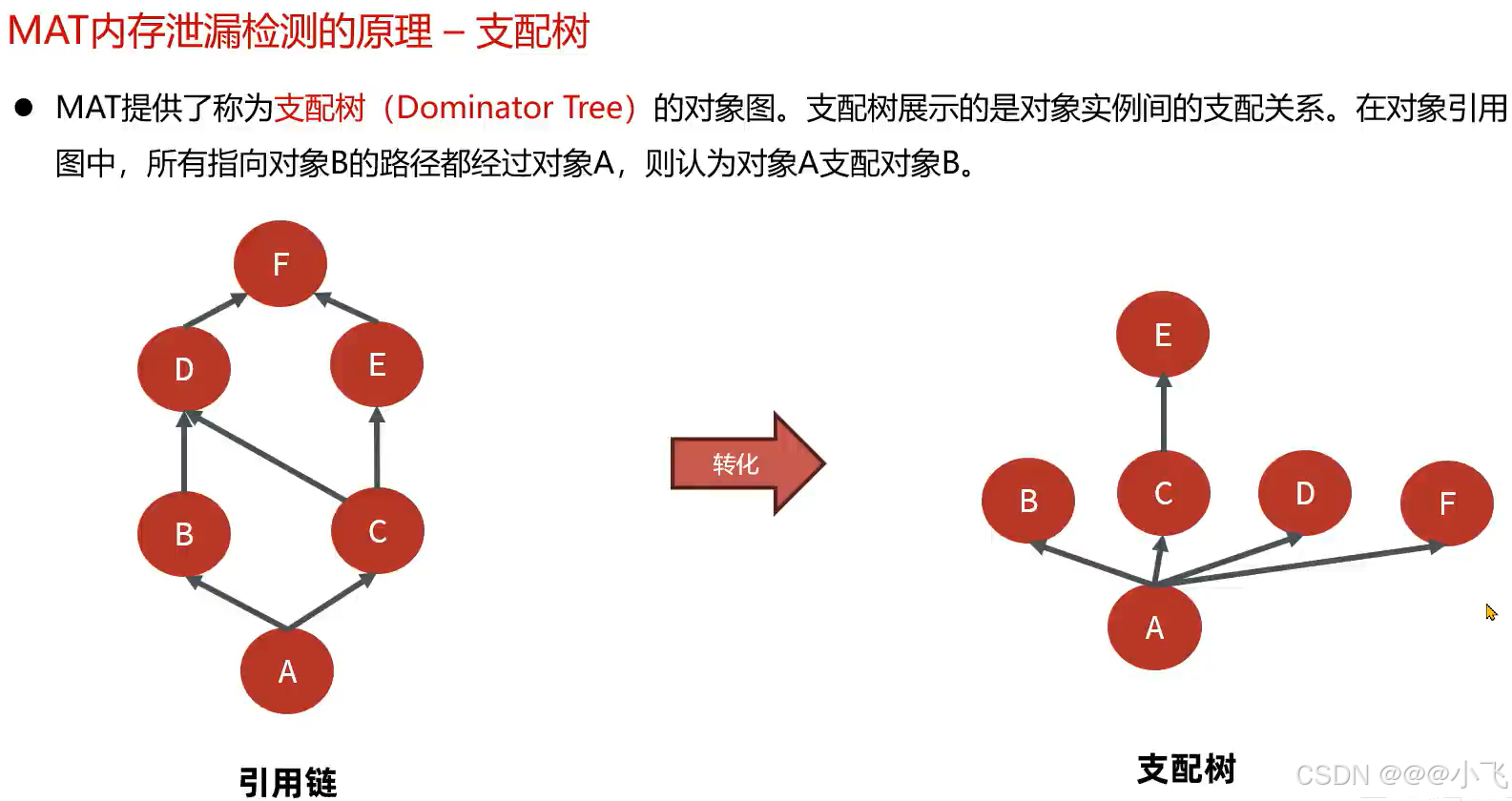
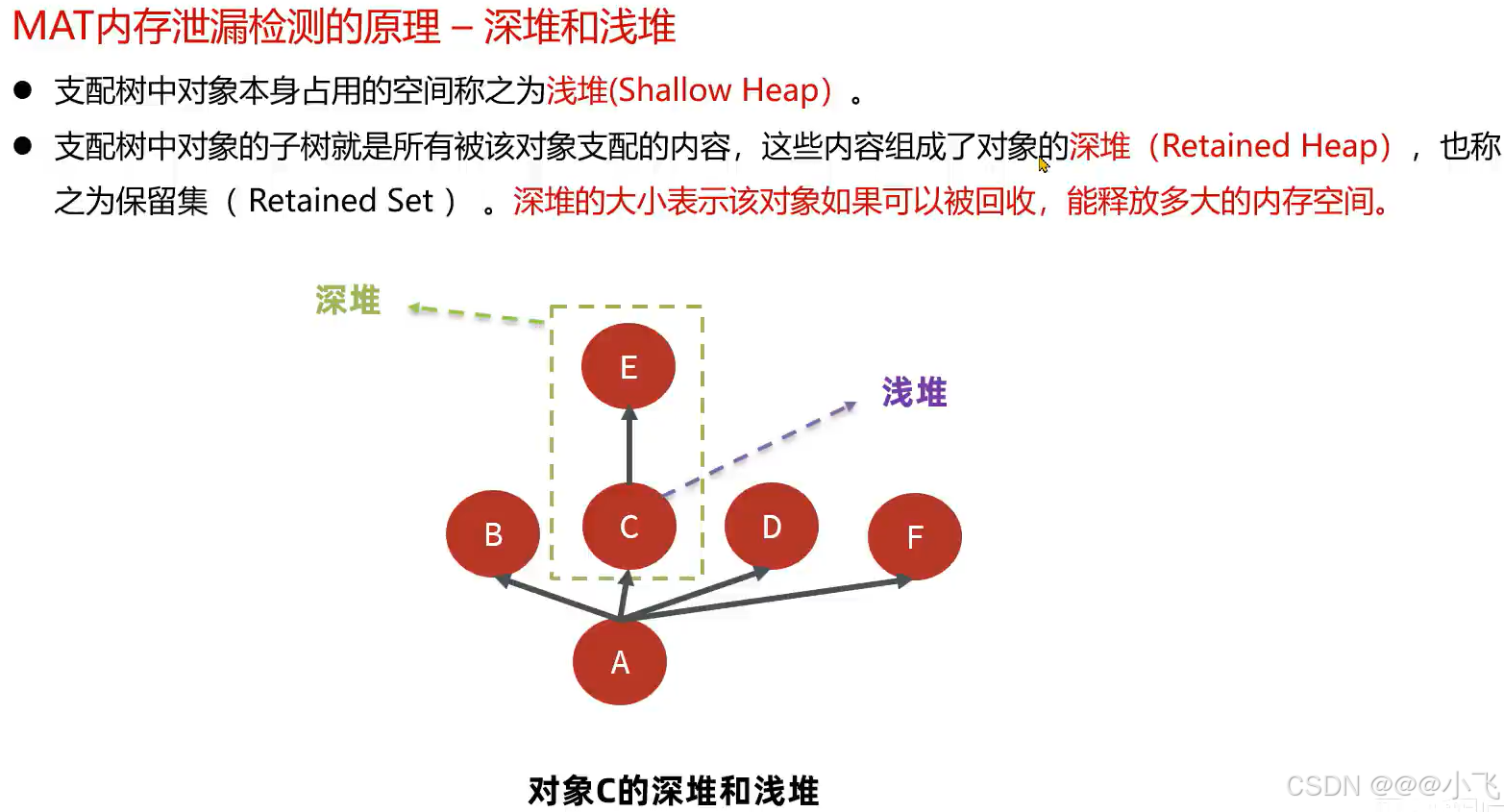
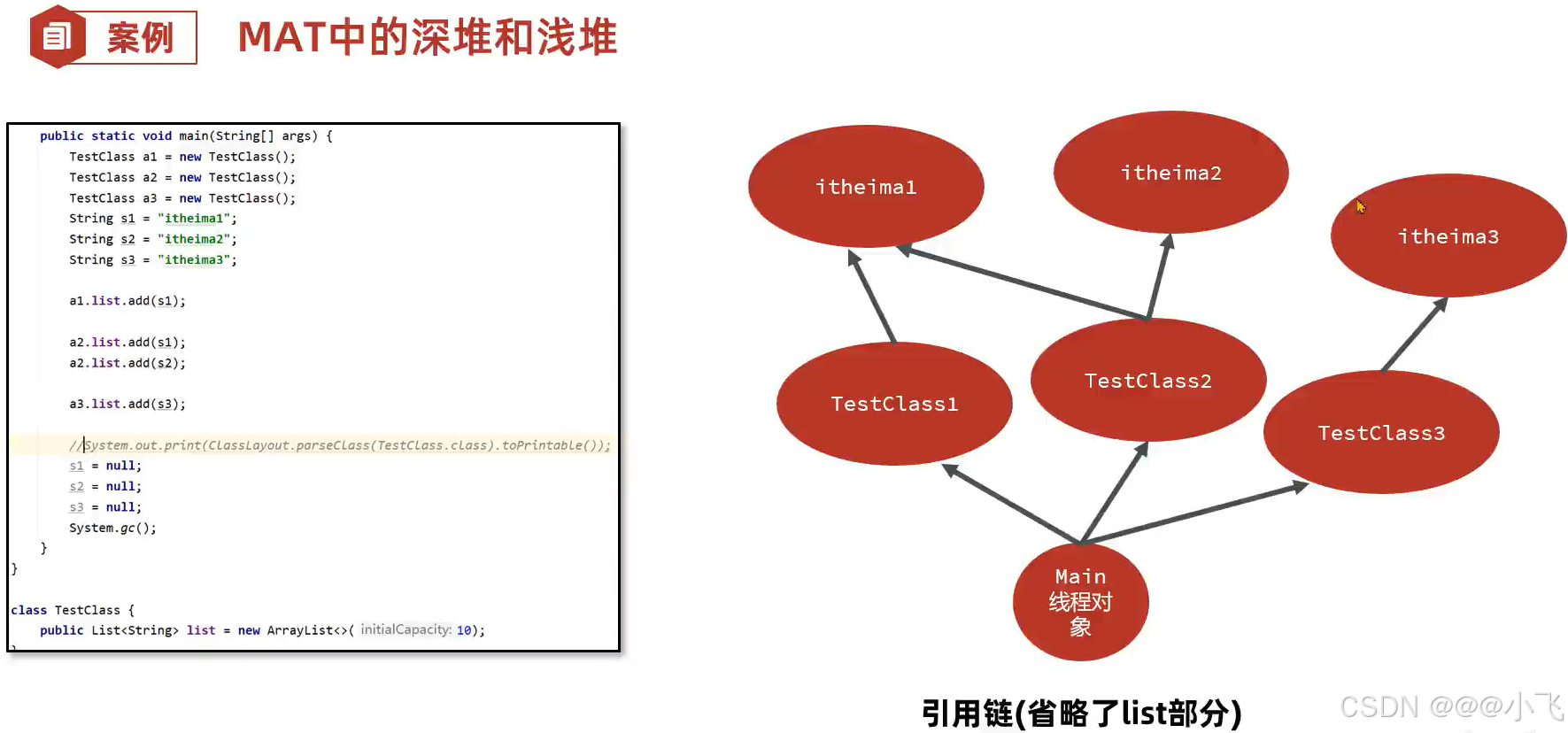
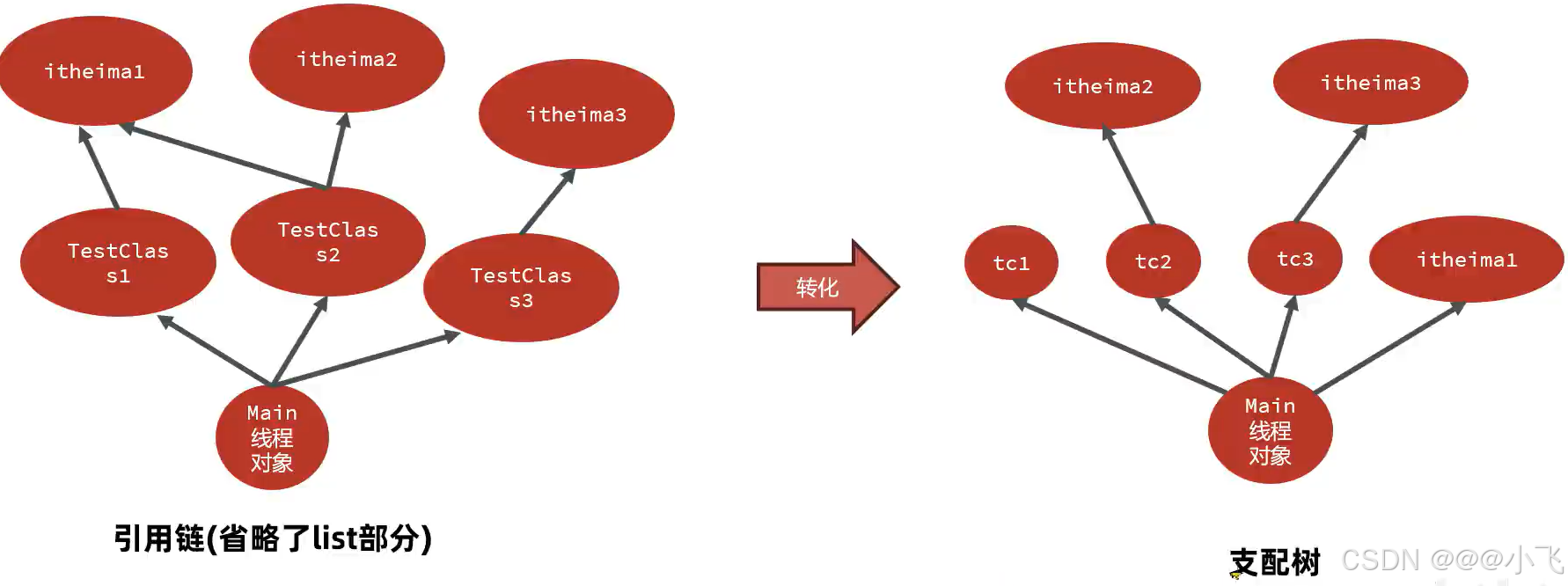
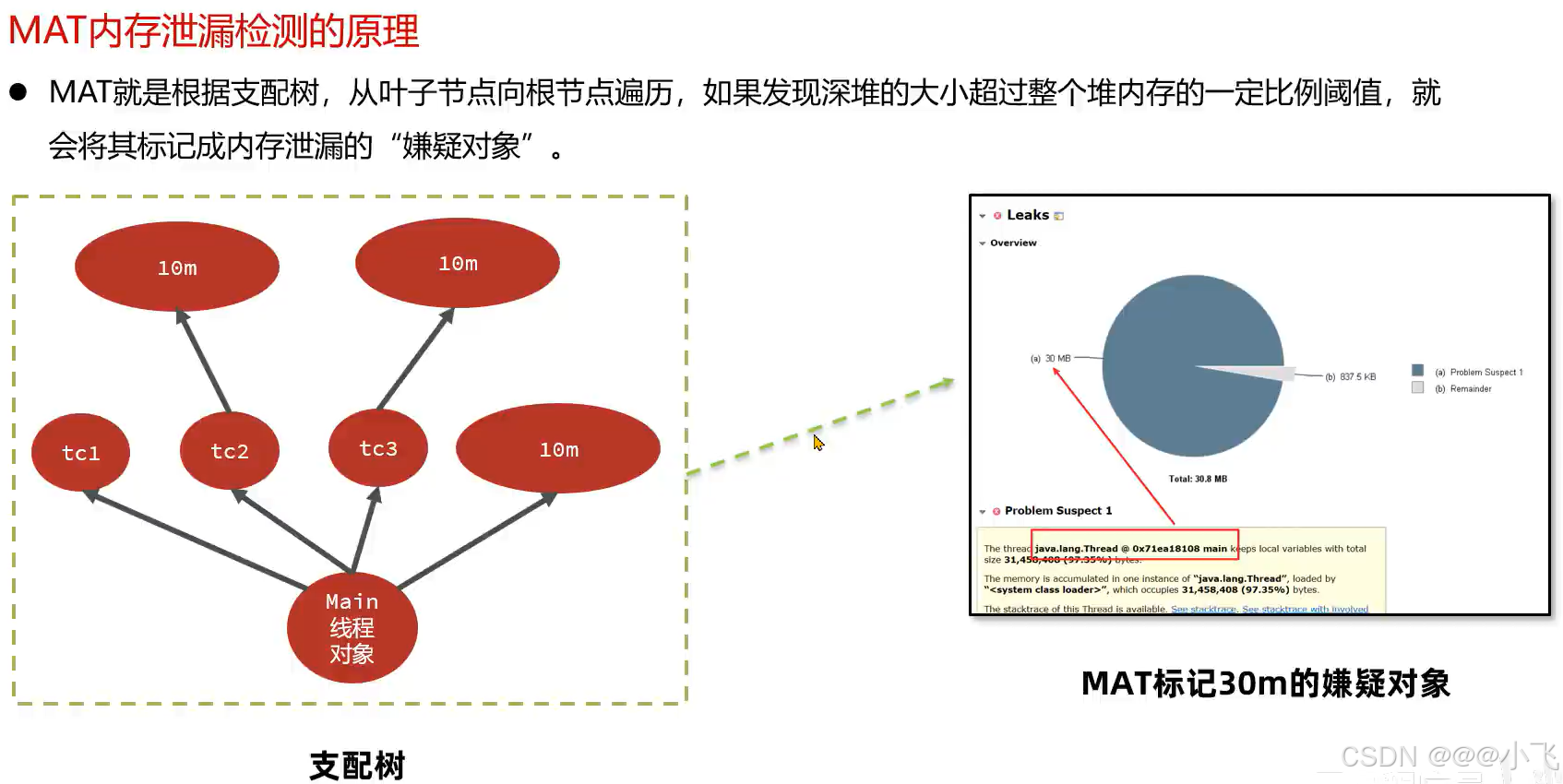
MAT内存泄露检查原理
<!-- jol依赖,用于打印对象内存对象布局,用于排查内存泄漏 -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.17</version>
</dependency>System.out.println(ClassLayout.parseClass(String.class).toPrintable());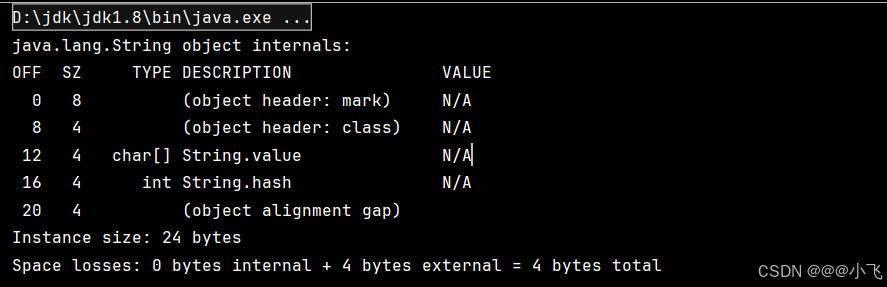
这里显示 String类 中内容分布:
(object header: mark/class):类的基本信息,一共12字节
char[] String.value:String 类中的数组,4个字节保存对char[] 的引用
object alignment gap:对象对齐填充,我的是操作系统是64位,所有需要能被8整除,所以补4个字节,24能整除8
服务器导出内存快照和MAT使用小技巧

修复问题-实战解决
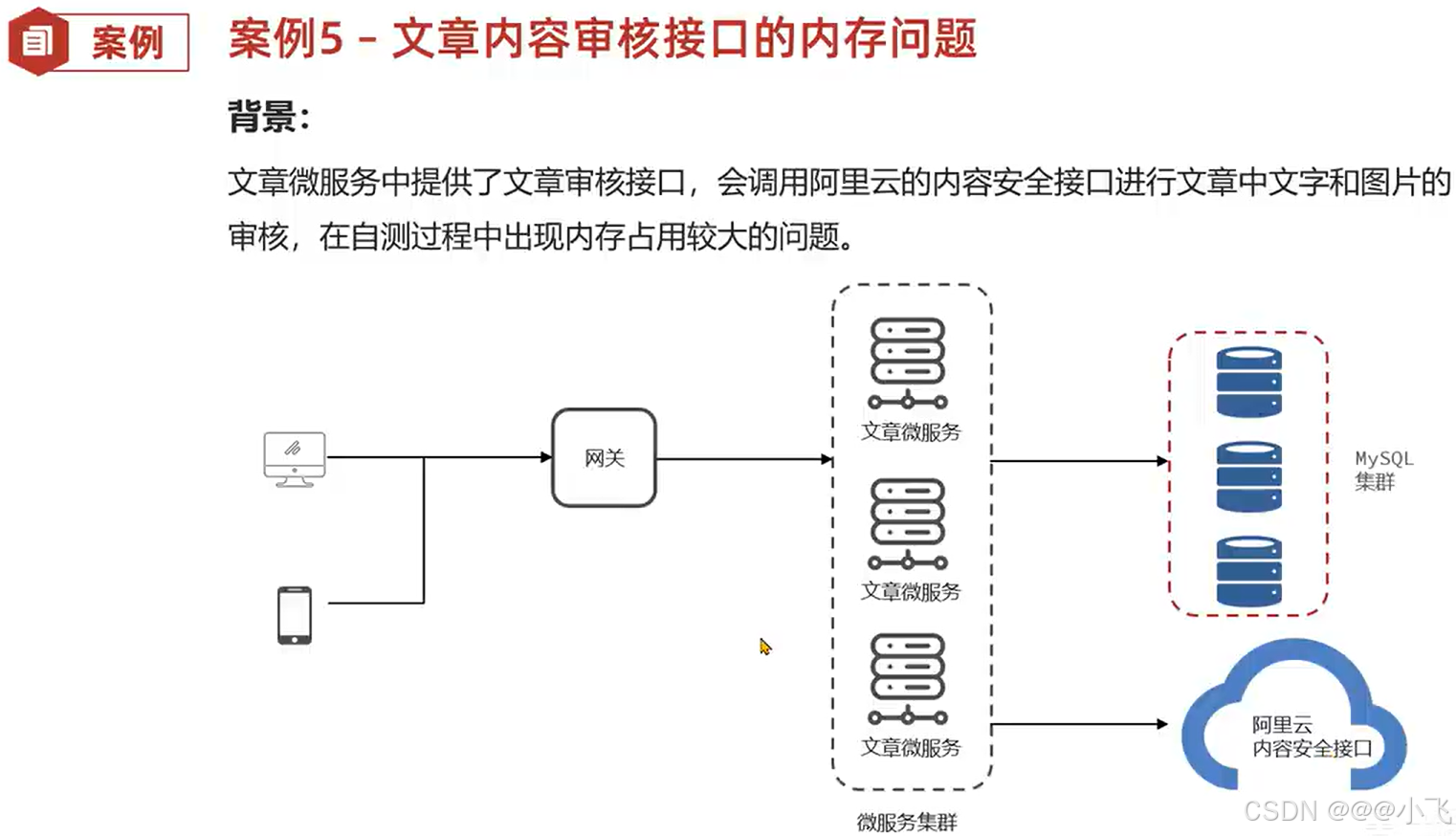
查询大量数据导致的内存溢出


mybatis 导致的内存溢出
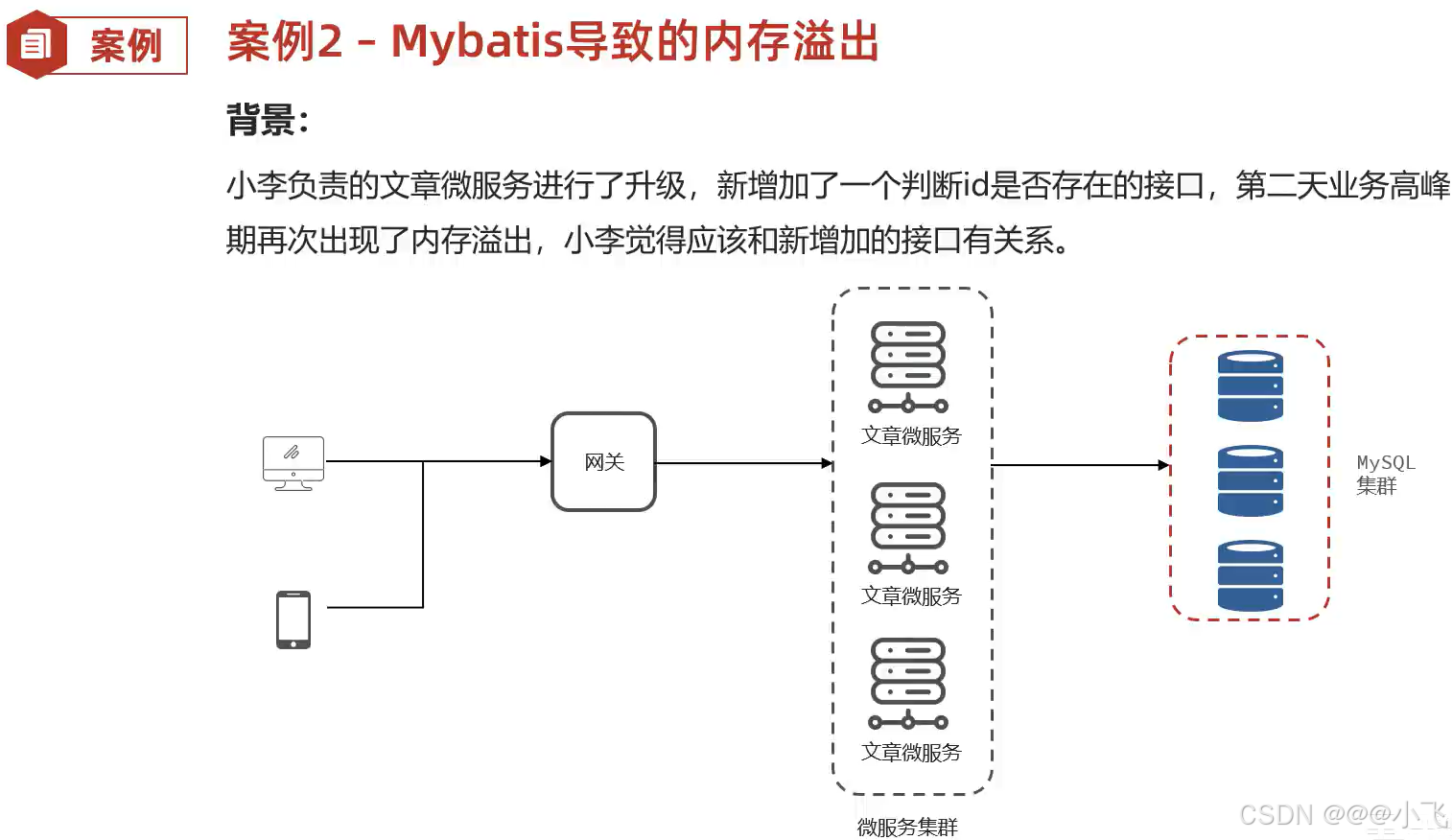
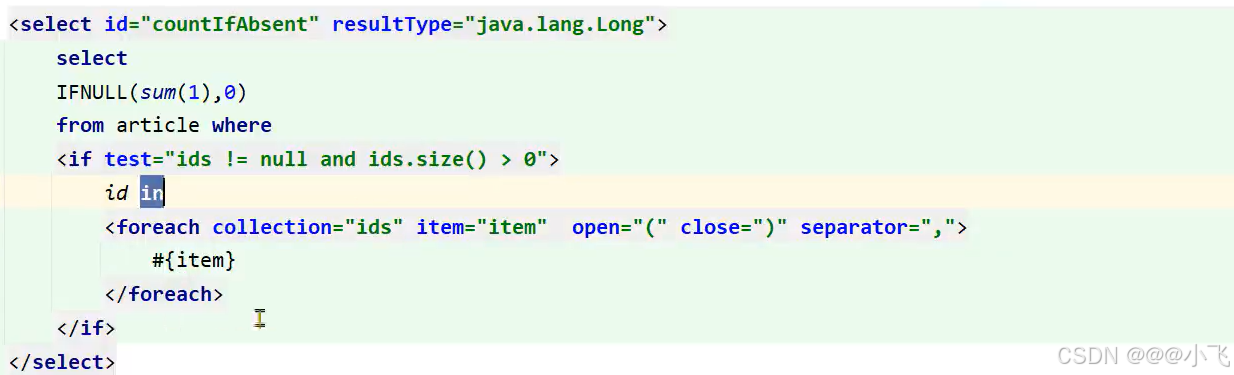
MyBatis 在处理 <foreach> 标签时会遍历集合或数组,会存到map中,key是参数名称,值是List<值>。Java 的字符串拼接机制可能会导致大量的临时字符串对象被创建。

K8s容器环境大文件导致大文件内存溢出
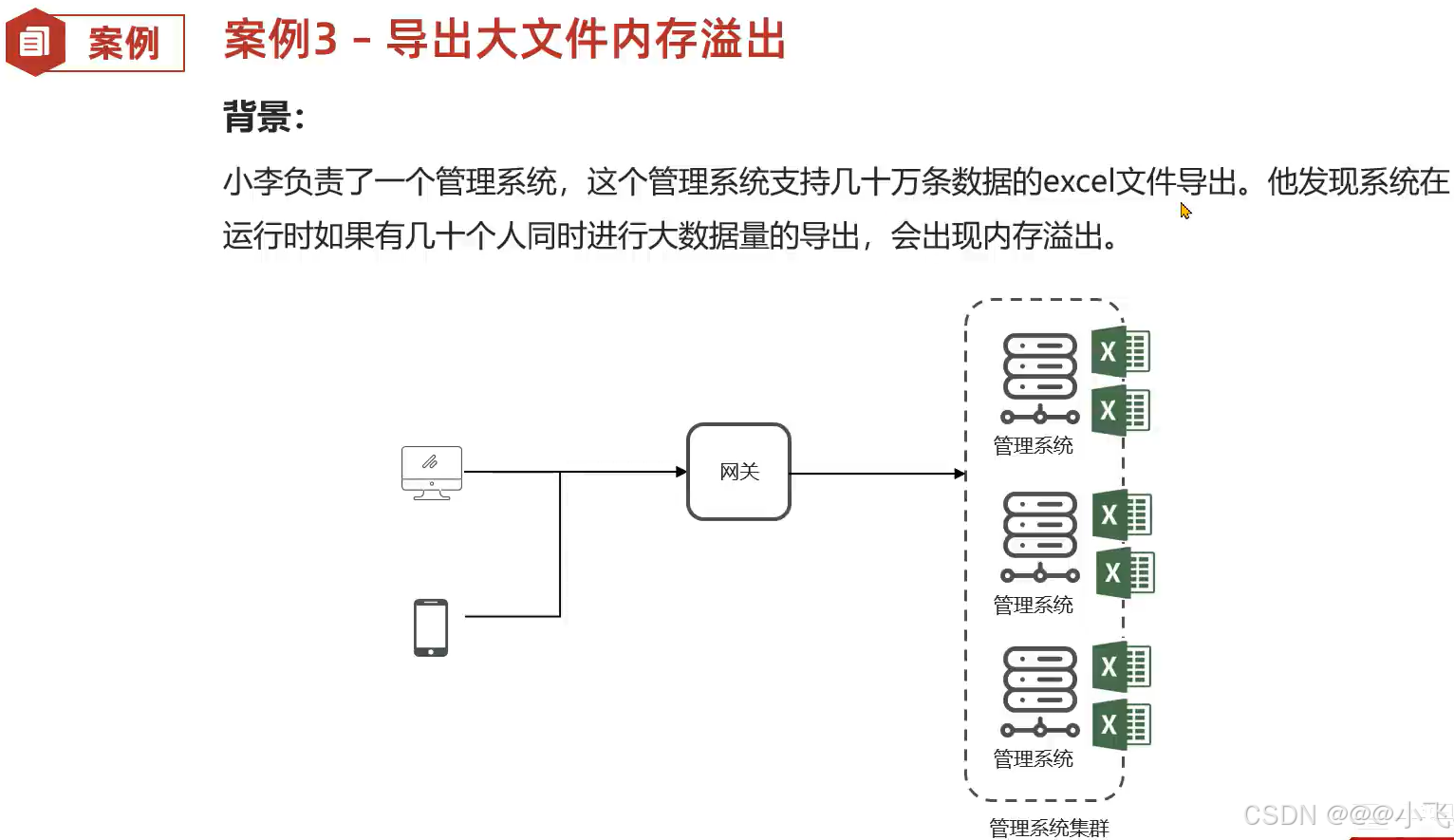
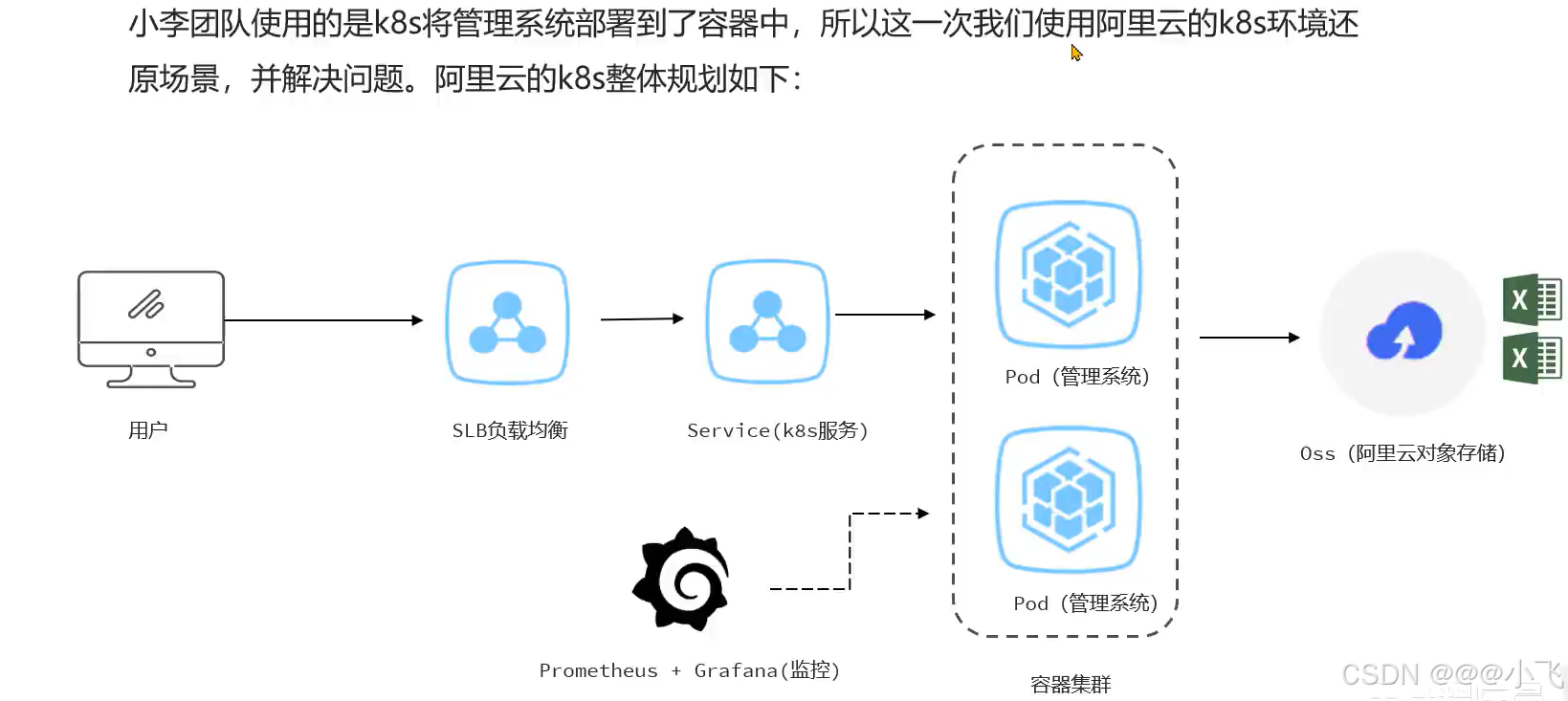
由于没有学习过 K8S,所以 .....

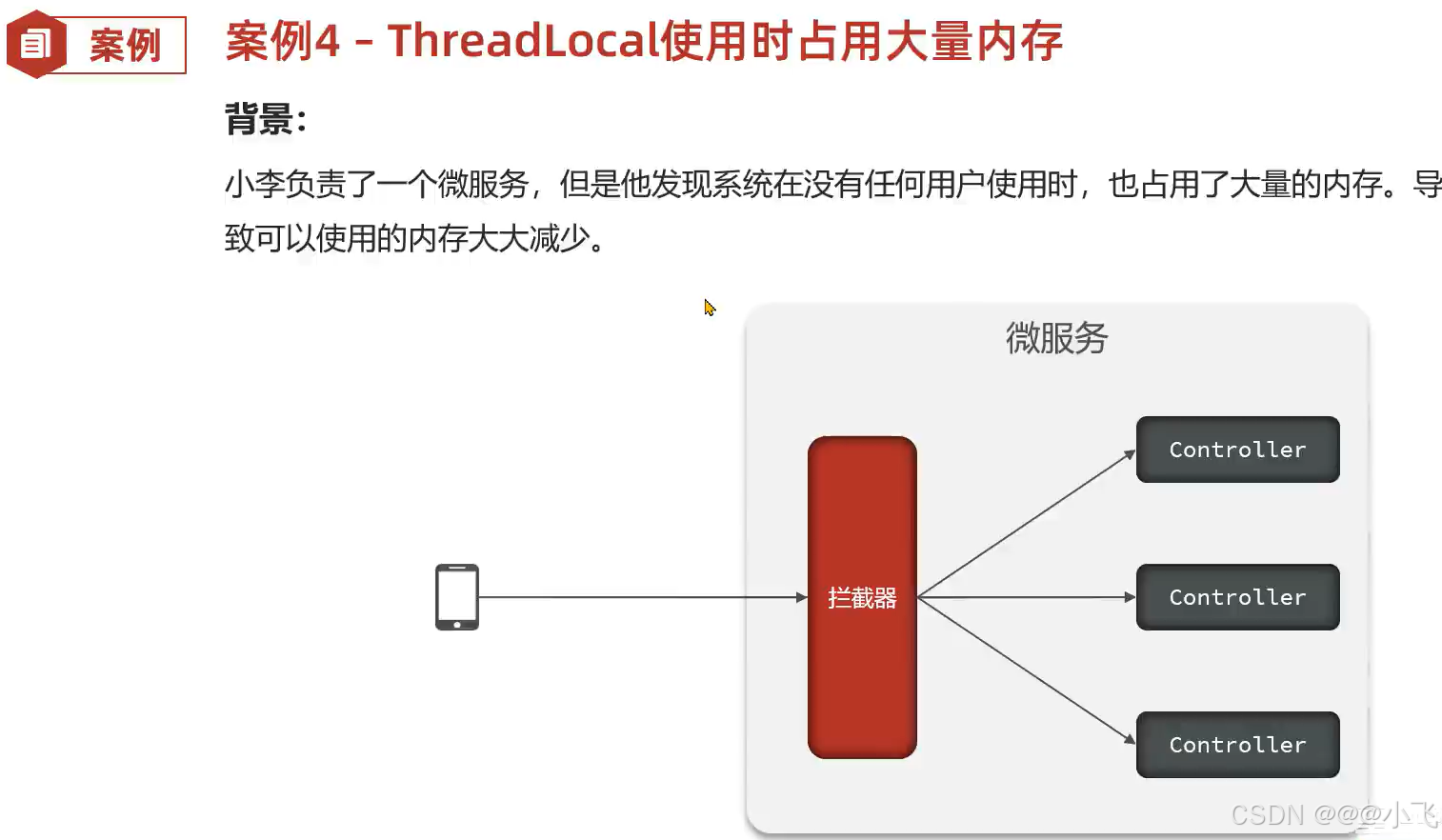
系统不处理业务时也占用大量内存

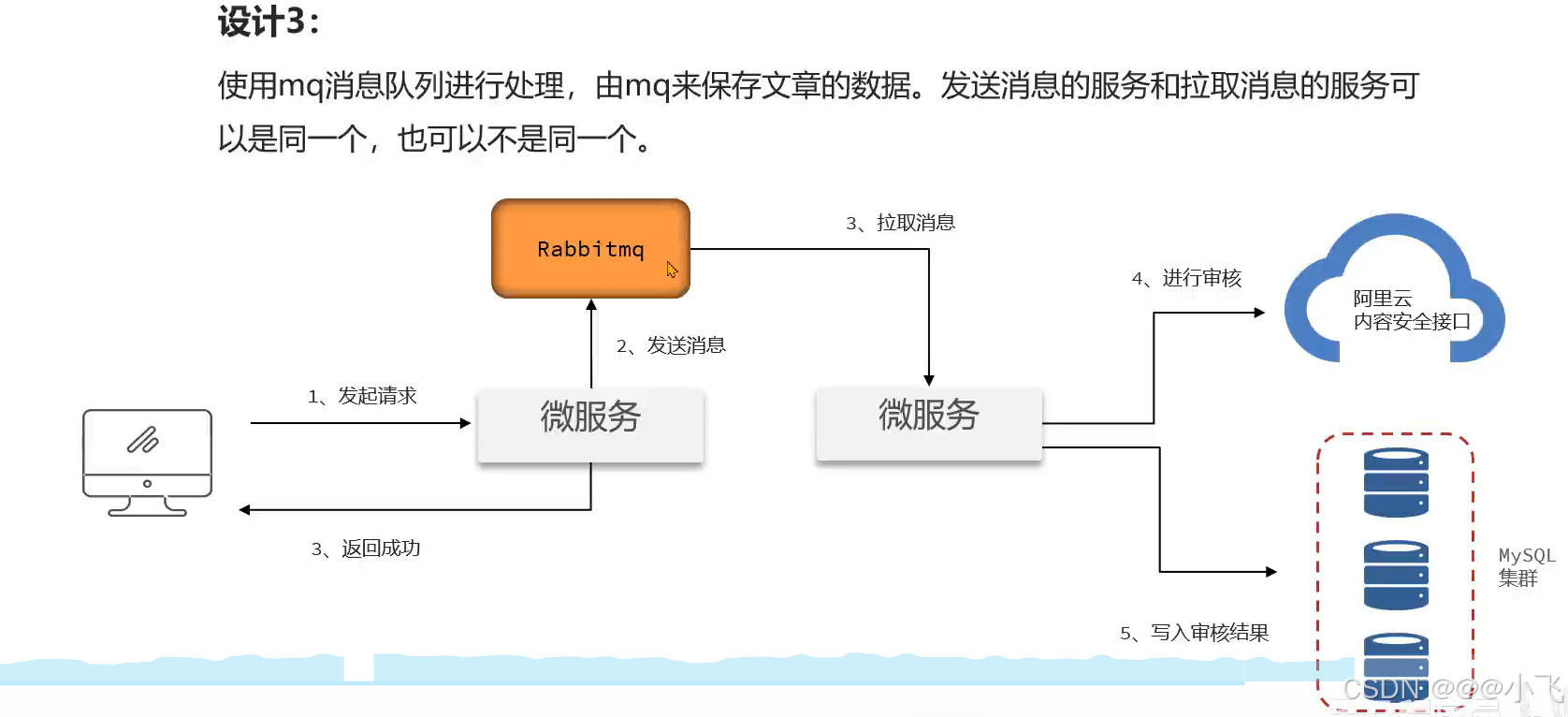
文章内存审核接口内存问题*
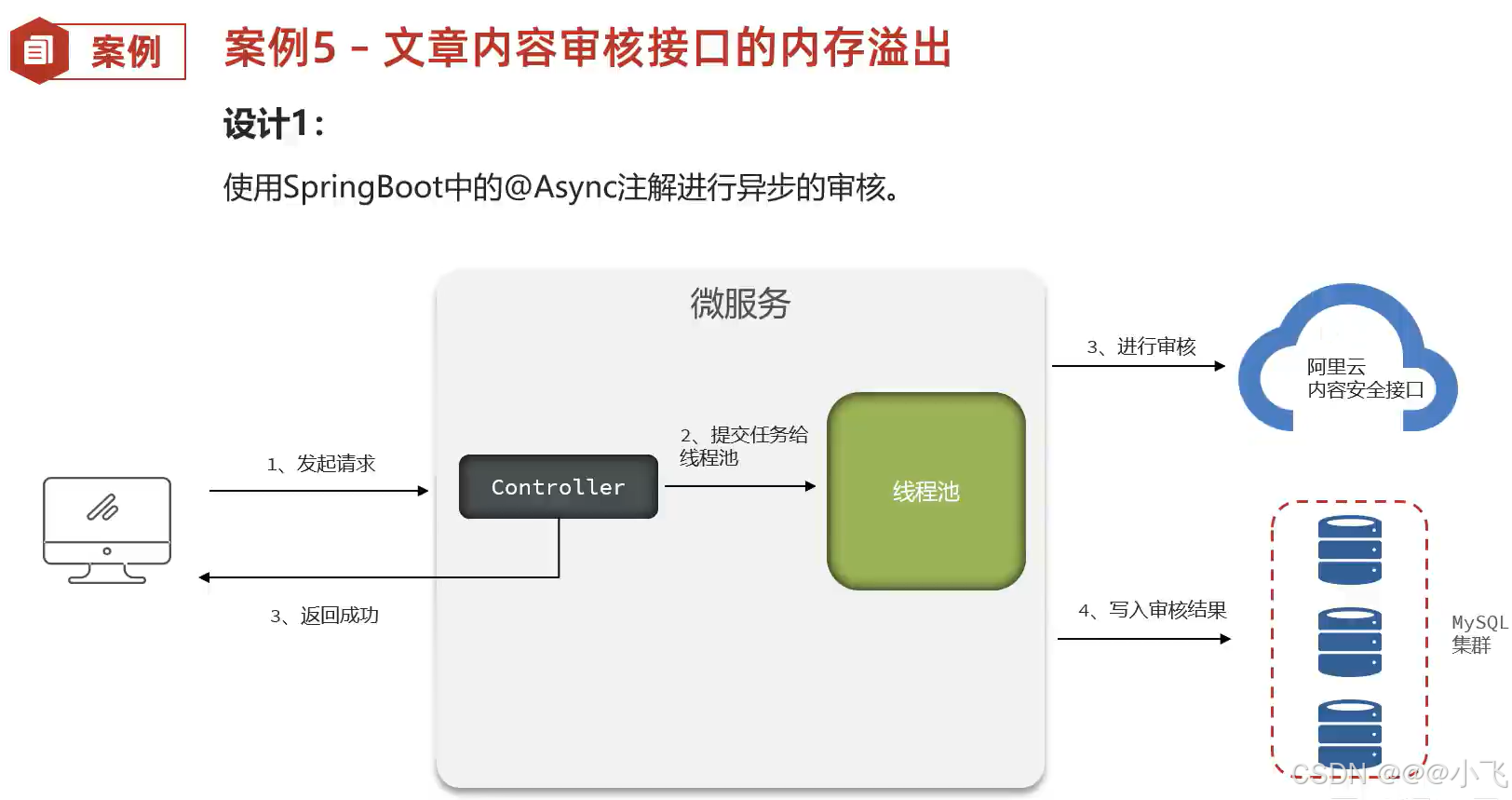
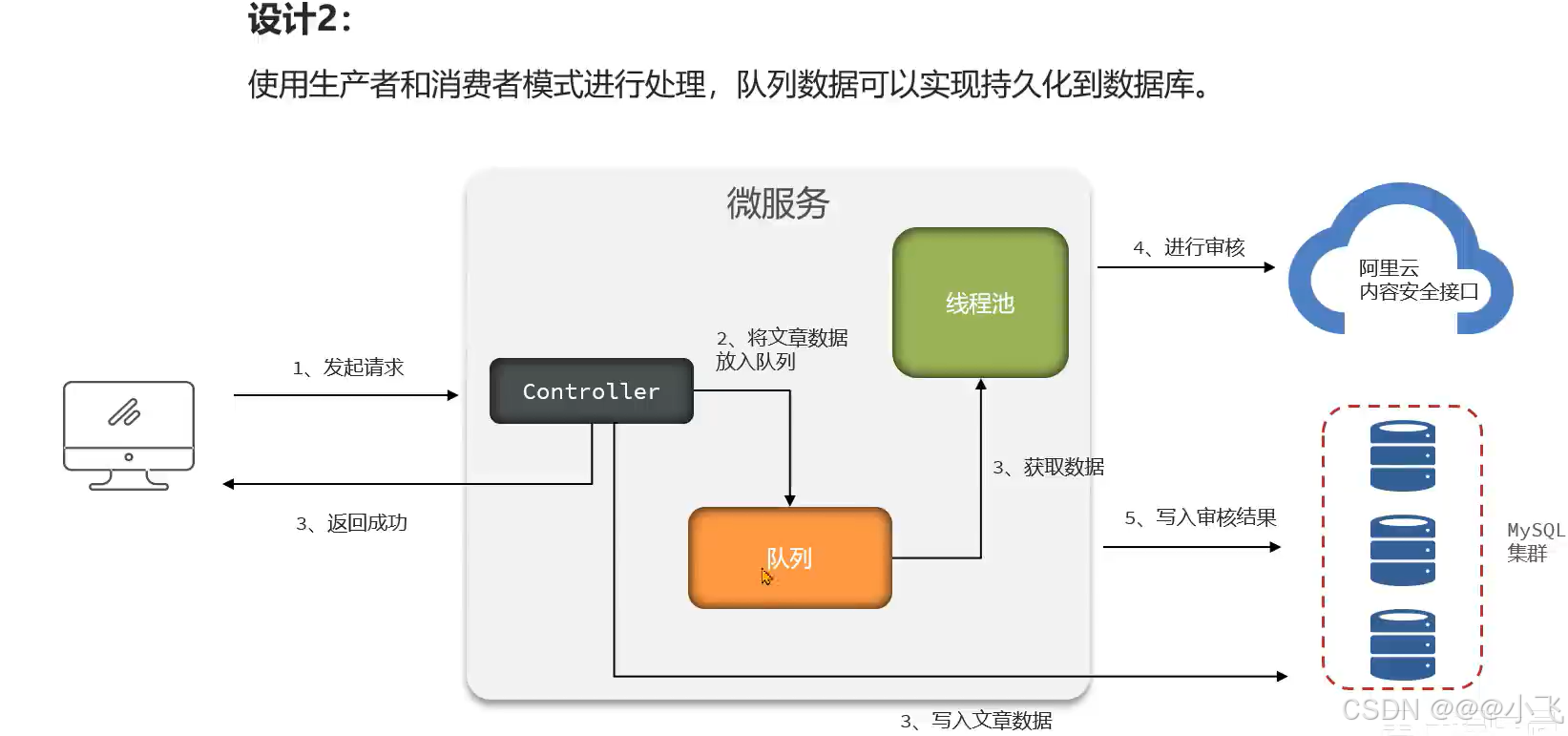
然后设置线程池参数,如果最大线程数设置过大,可能导致大量线程任务保持在内存中;设置过小,可能导致其他进入的线程报错,因此线程池参数是一个难点。如果断电或者重启会丢失任务,所以使用线程池做文章审核不是一个很好的选择


btrace和arthas在线定位问题


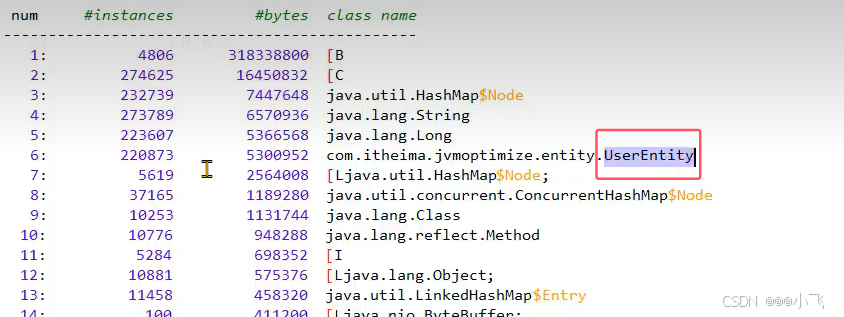
使用 jamp -histo:live 进程ID > 1.txt 命令保存的直方图文本中可以看到我们编写的类中UserEntity占比最多,很可能是这个类内存溢出
然后再 Arthas 的 stack 命令就可以出打印运行过程中 userEntity 类在带代码哪个地方调用
也可以使用 btrace 工具打印出具体的堆栈信息
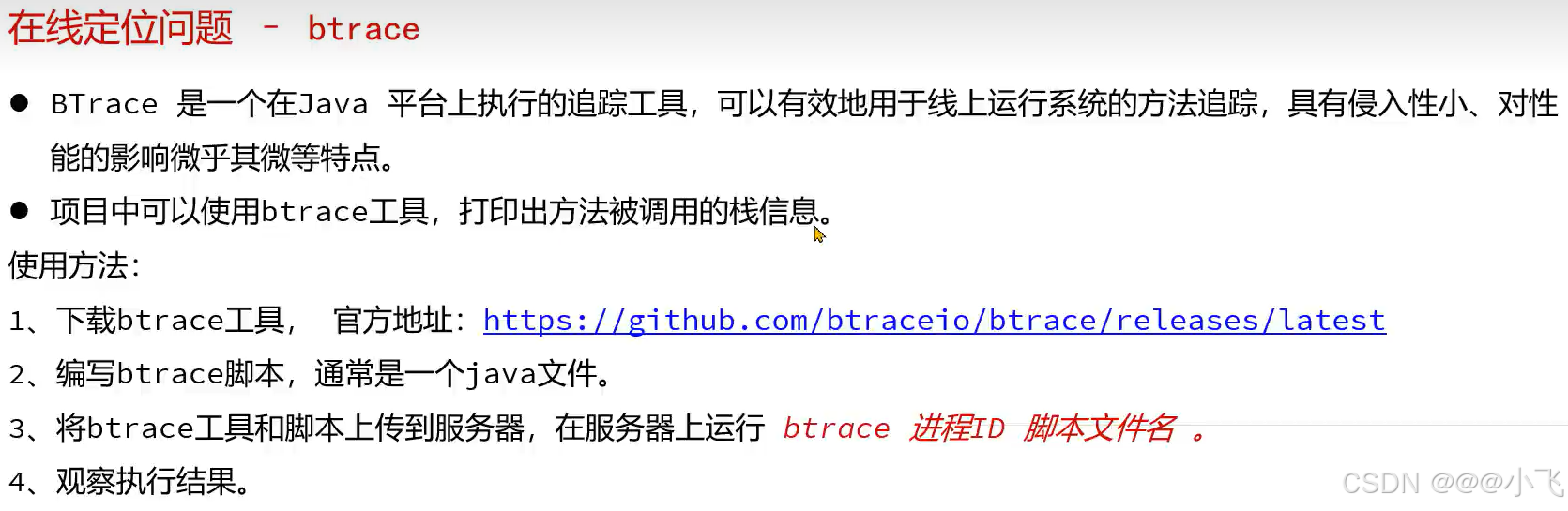
下载好之后在配置环境变量 :D:\app\Btrace\btrace-v2.2.6-bin\bin
创建一个maven工程编写 brtace 脚本:
添加依赖:(就是 D:\app\Btrace\btrace-v2.2.6-bin\libs 目录下的3个jar包)
<dependency>
<groupId>org.openjdk.btrace</groupId>
<artifactId>btrace-agent</artifactId>
<version>${btrace.version}</version>
<scope>system</scope>
<systemPath>D:\app\Btrace\btrace-v2.2.6-bin\libs\btrace-agent.jar</systemPath>
</dependency>
<dependency>
<groupId>org.openjdk.btrace</groupId>
<artifactId>btrace-boot</artifactId>
<version>${btrace.version}</version>
<scope>system</scope>
<systemPath>D:\app\Btrace\btrace-v2.2.6-bin\libs\btrace-boot.jar</systemPath>
</dependency>
<dependency>
<groupId>org.openjdk.btrace</groupId>
<artifactId>btrace-client</artifactId>
<version>${btrace.version}</version>
<scope>system</scope>
<systemPath>D:\app\Btrace\btrace-v2.2.6-bin\libs\btrace-client.jar</systemPath>
</dependency>在 IDEA中 pom 文件爆红是正常现象
编写代码:
@BTrace
public class BtraceScript {
/**
* 打印com.boot.controller.jvm类所有方法的堆栈跟踪
*/
@OnMethod(clazz="com.boot.controller.JvmController", method="/.*/")
public static void jvmControllerTack() {
jstack(); // 打印当前线程的堆栈跟踪
}
}Linux执行命令:ps -ef|grep java 查看程序的进程id,执行命令打印对应的堆栈信息:(未成功)
btrace 9652 D:\app\Btrace\brtace-script-demo\src\main\java\com\zwf\BtraceScript.java GC调优
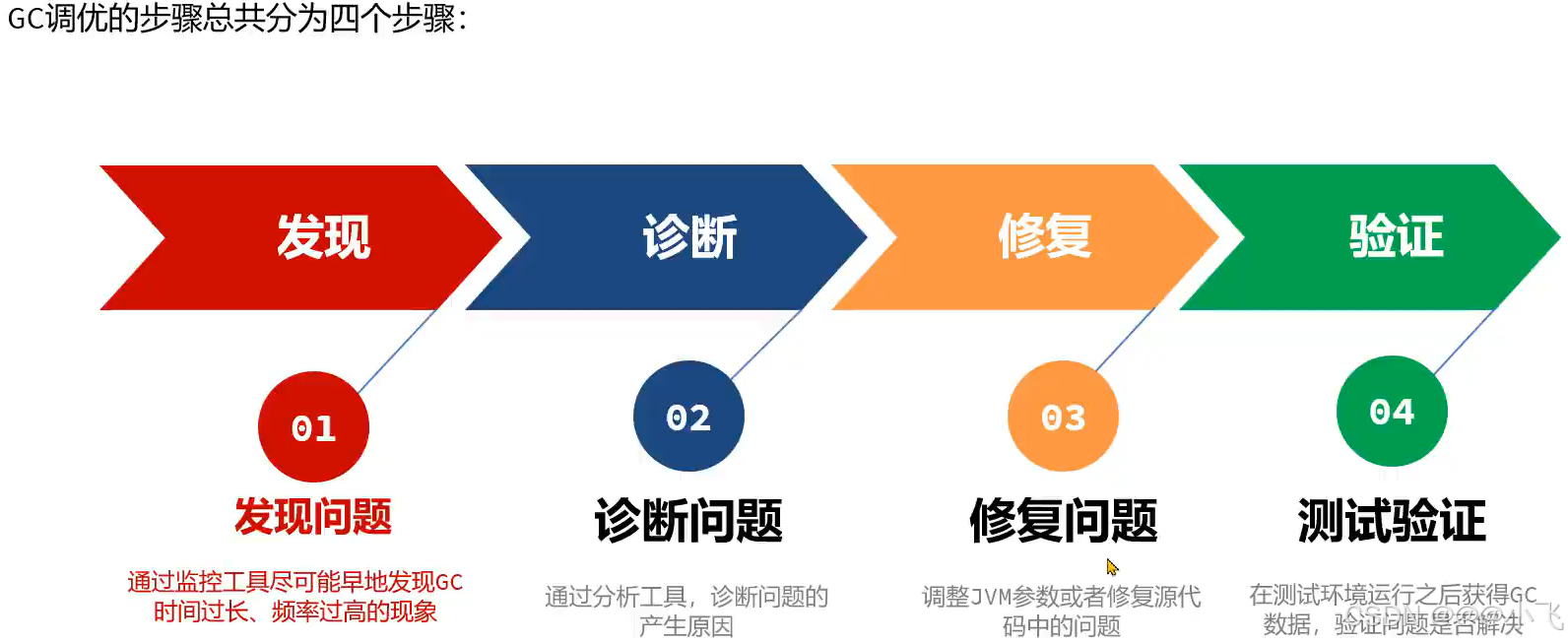
核心目标



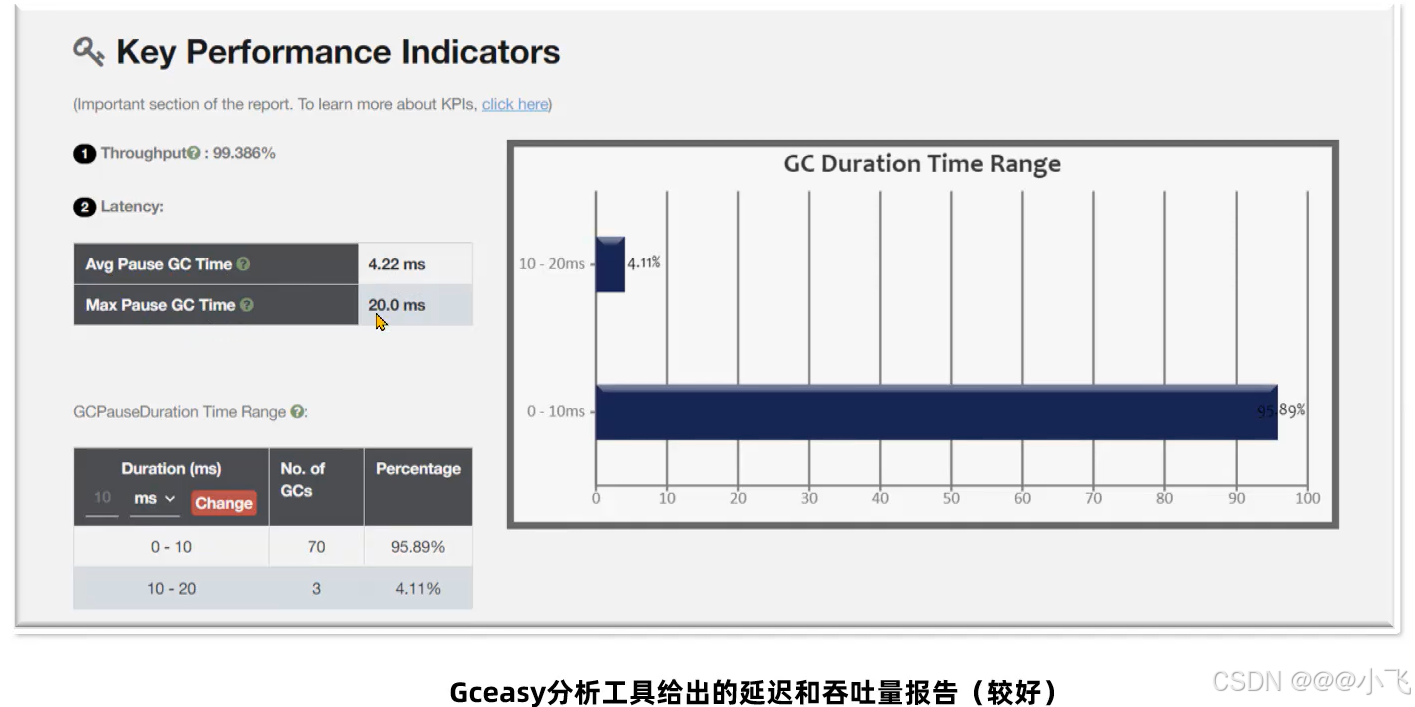
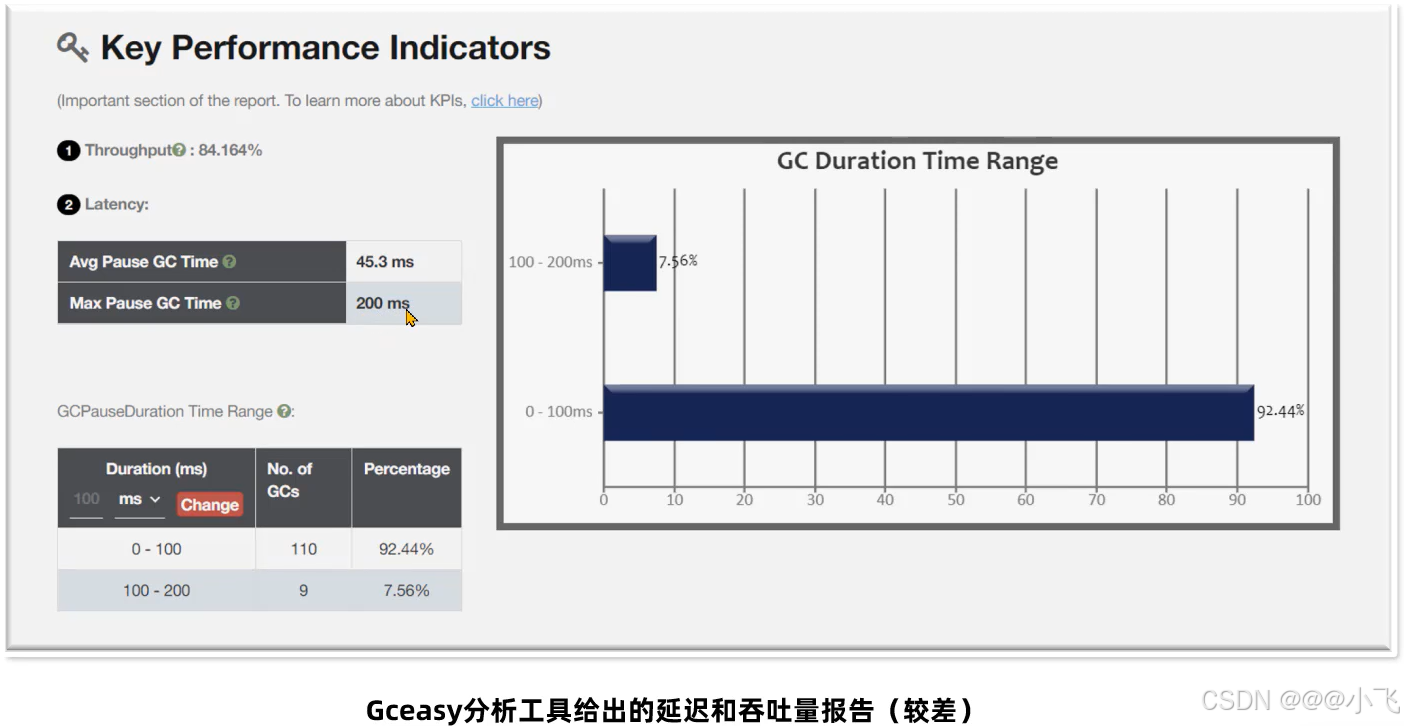
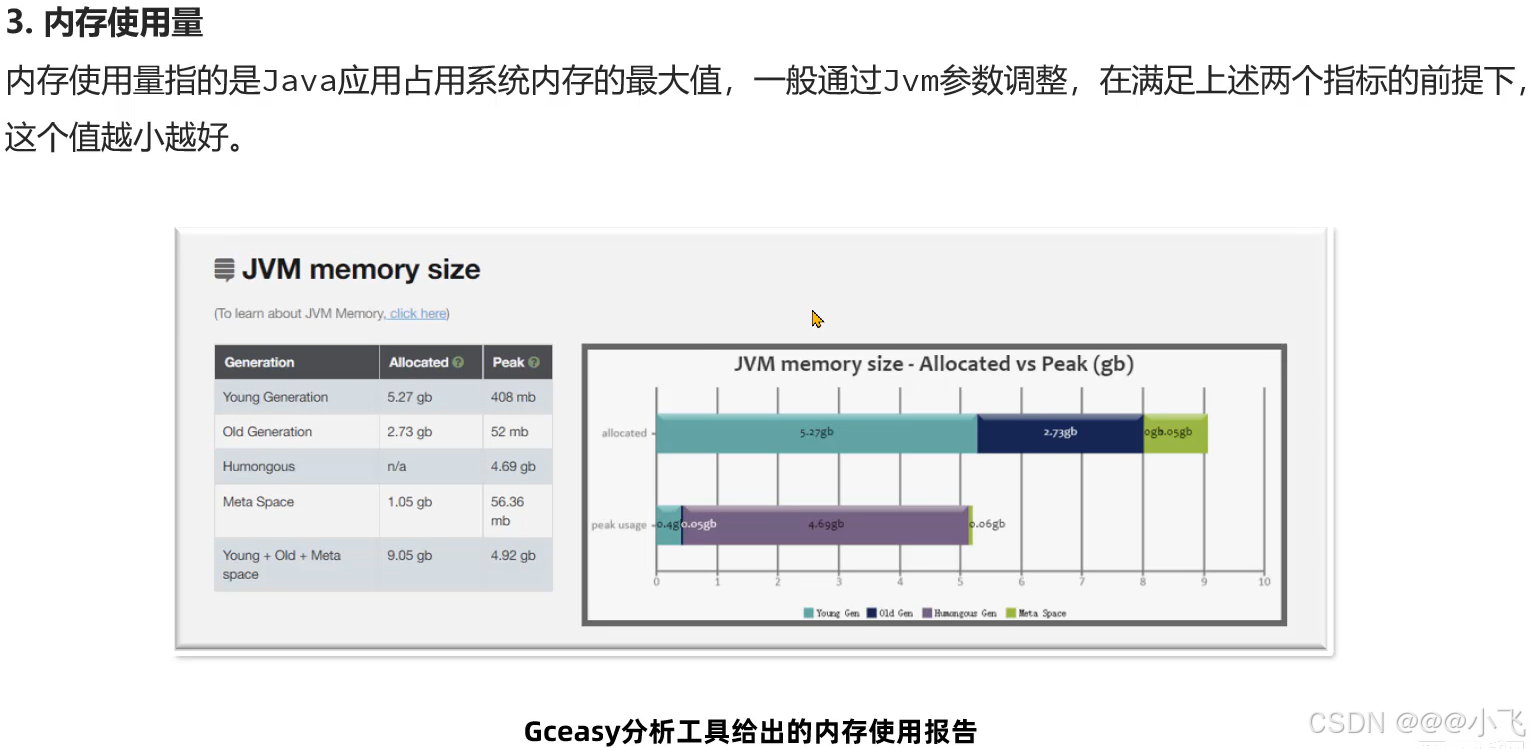
常用工具

输出目录为xxx.log
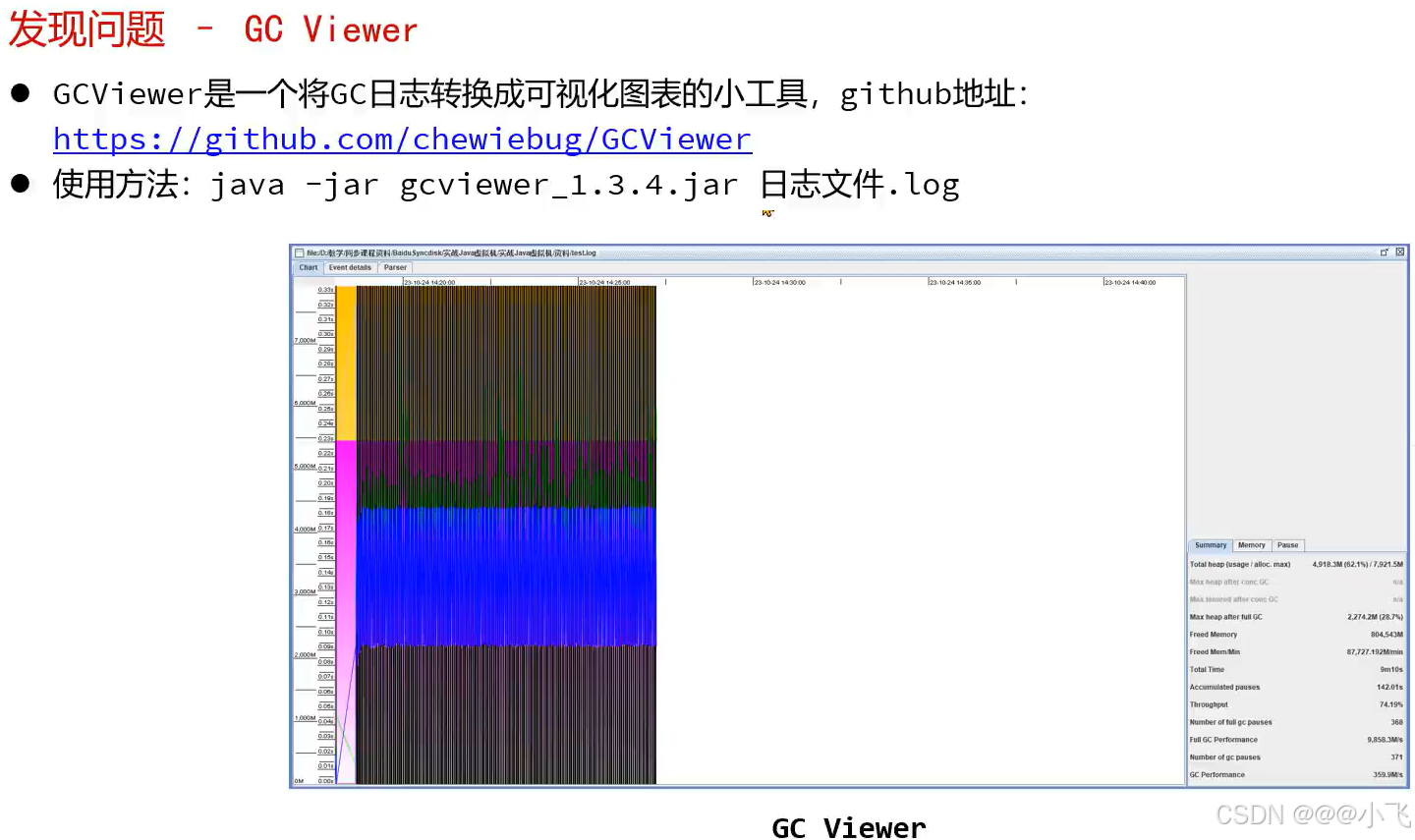
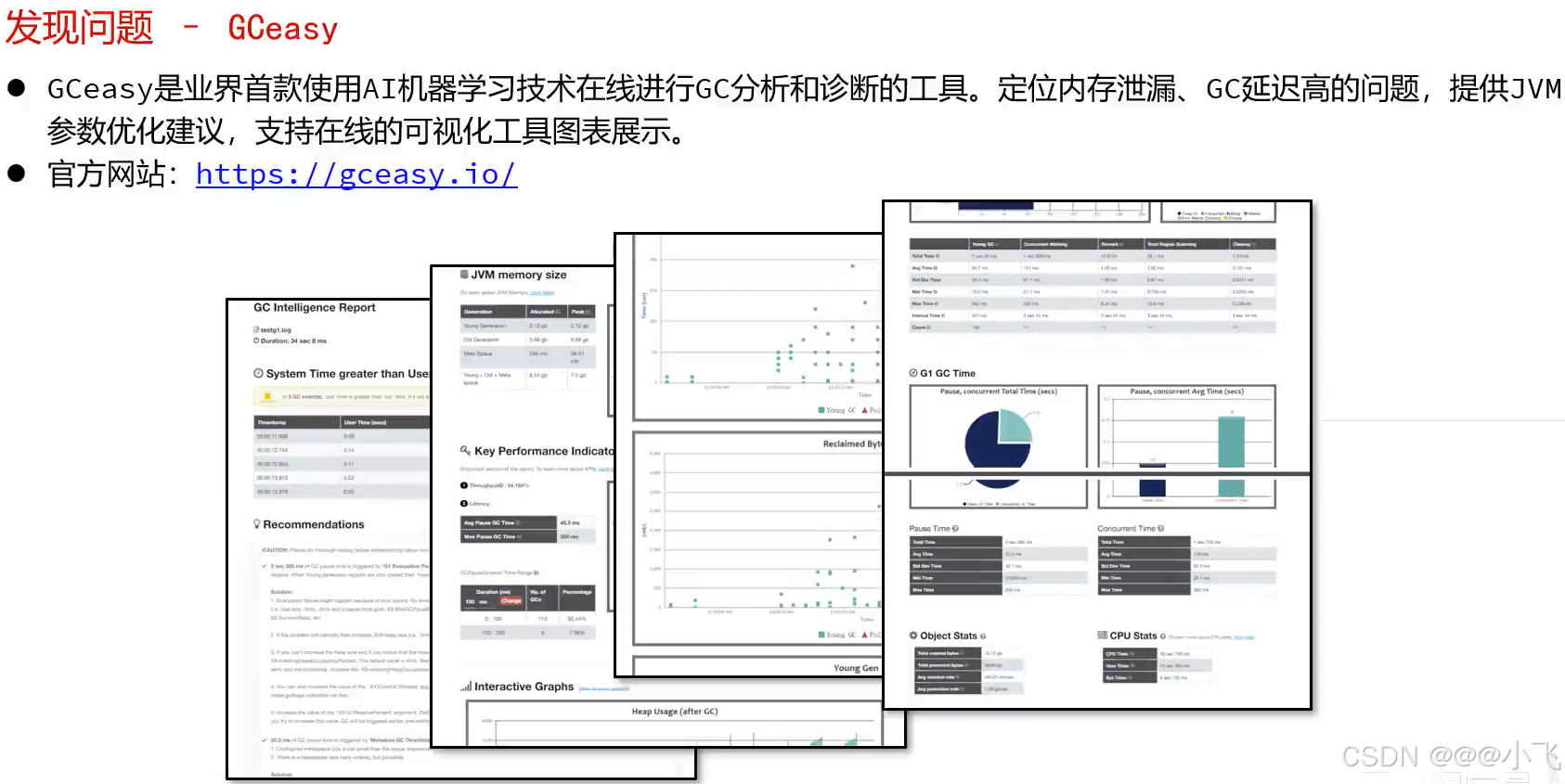
https://gceasy.io/ 这是一个收费的一个在线诊断GC日志的网站
常见的GC模式
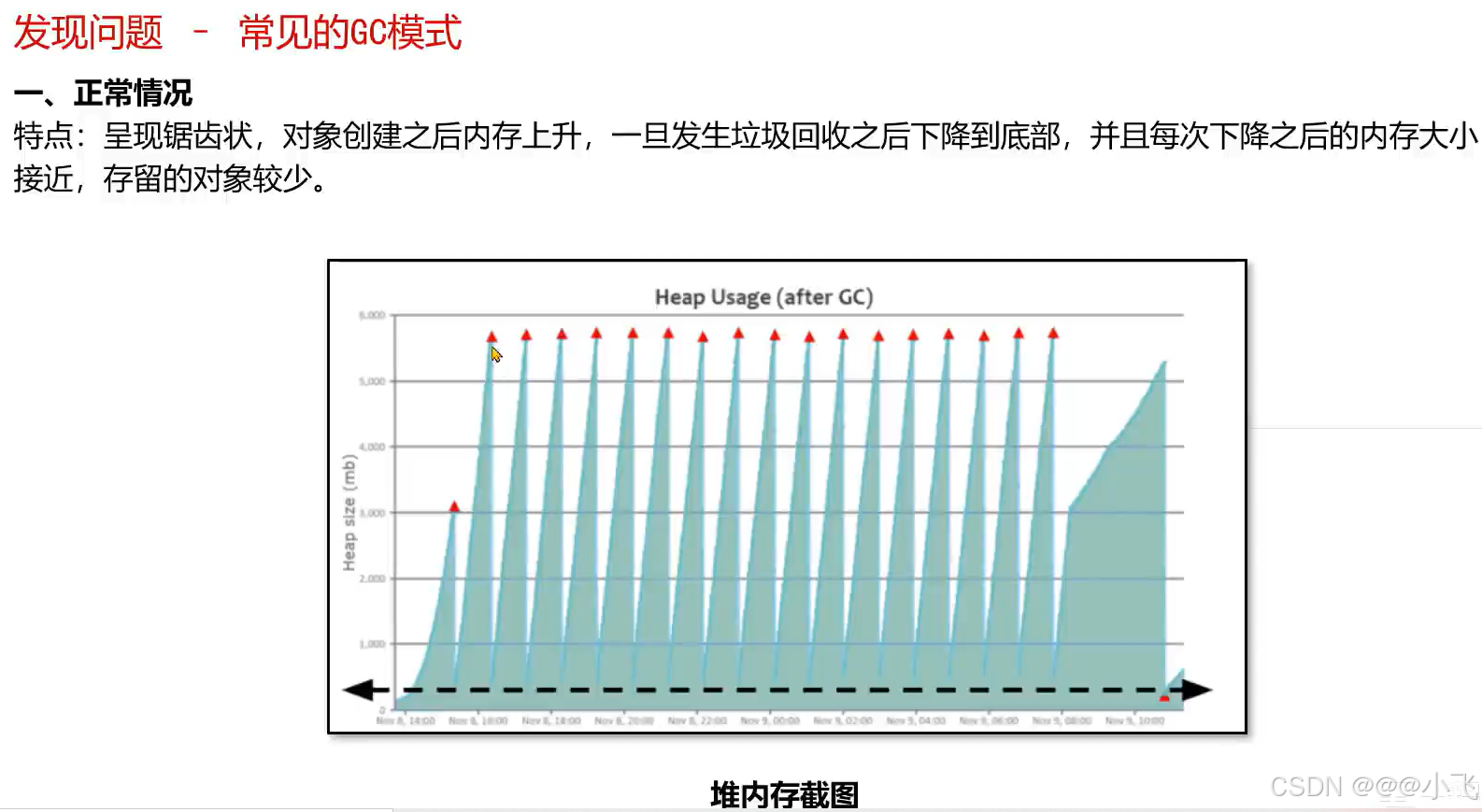
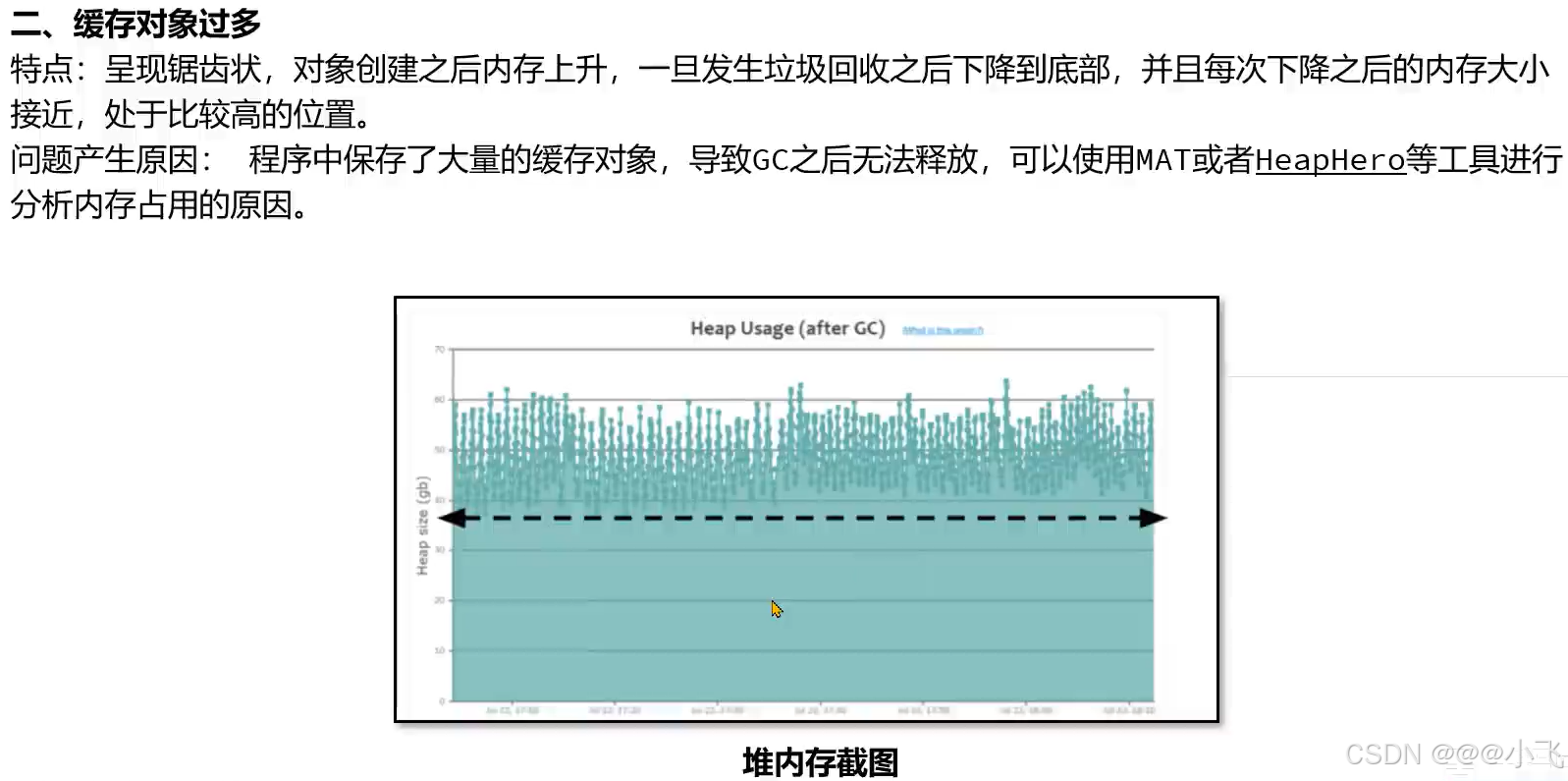
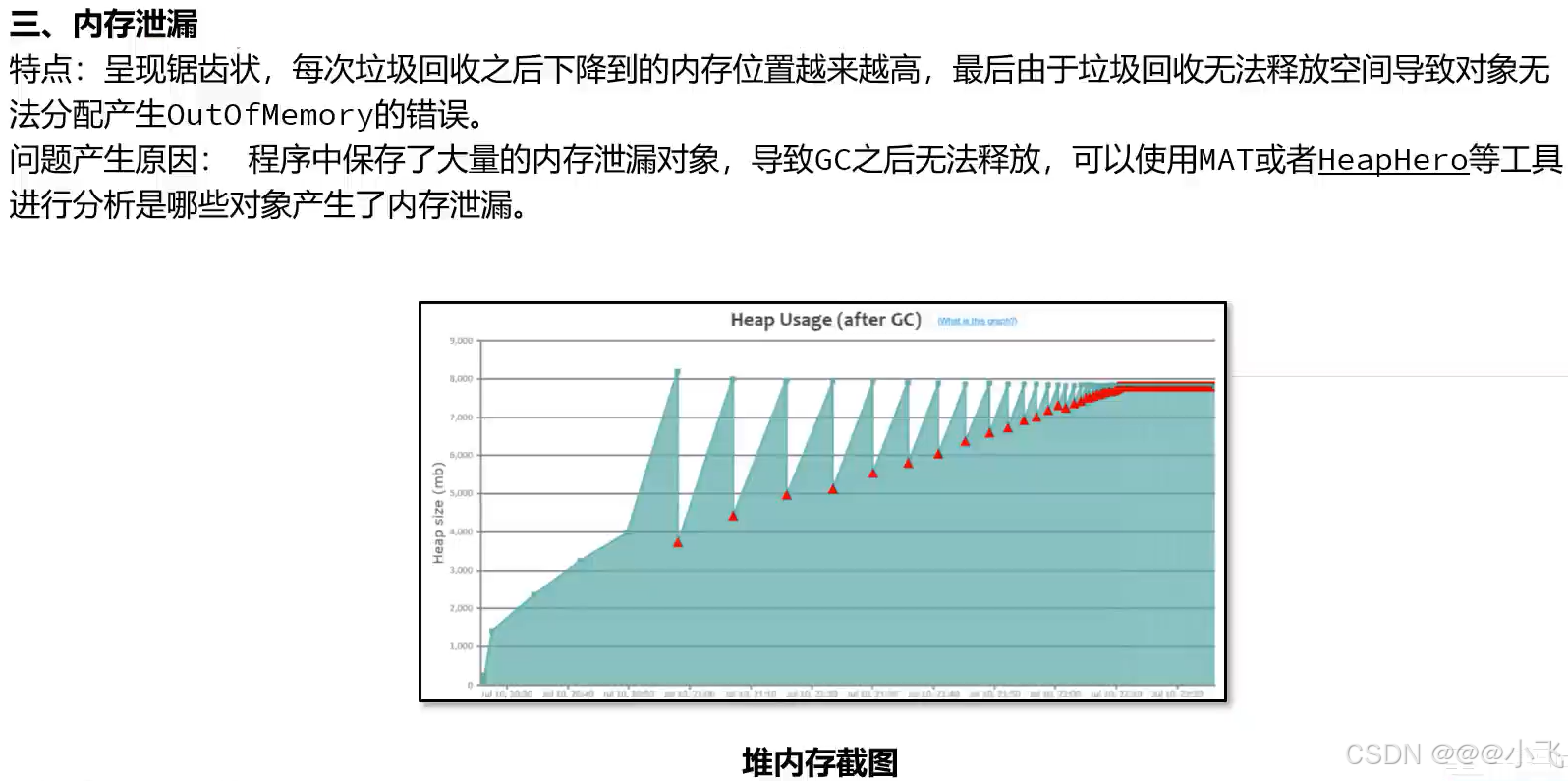
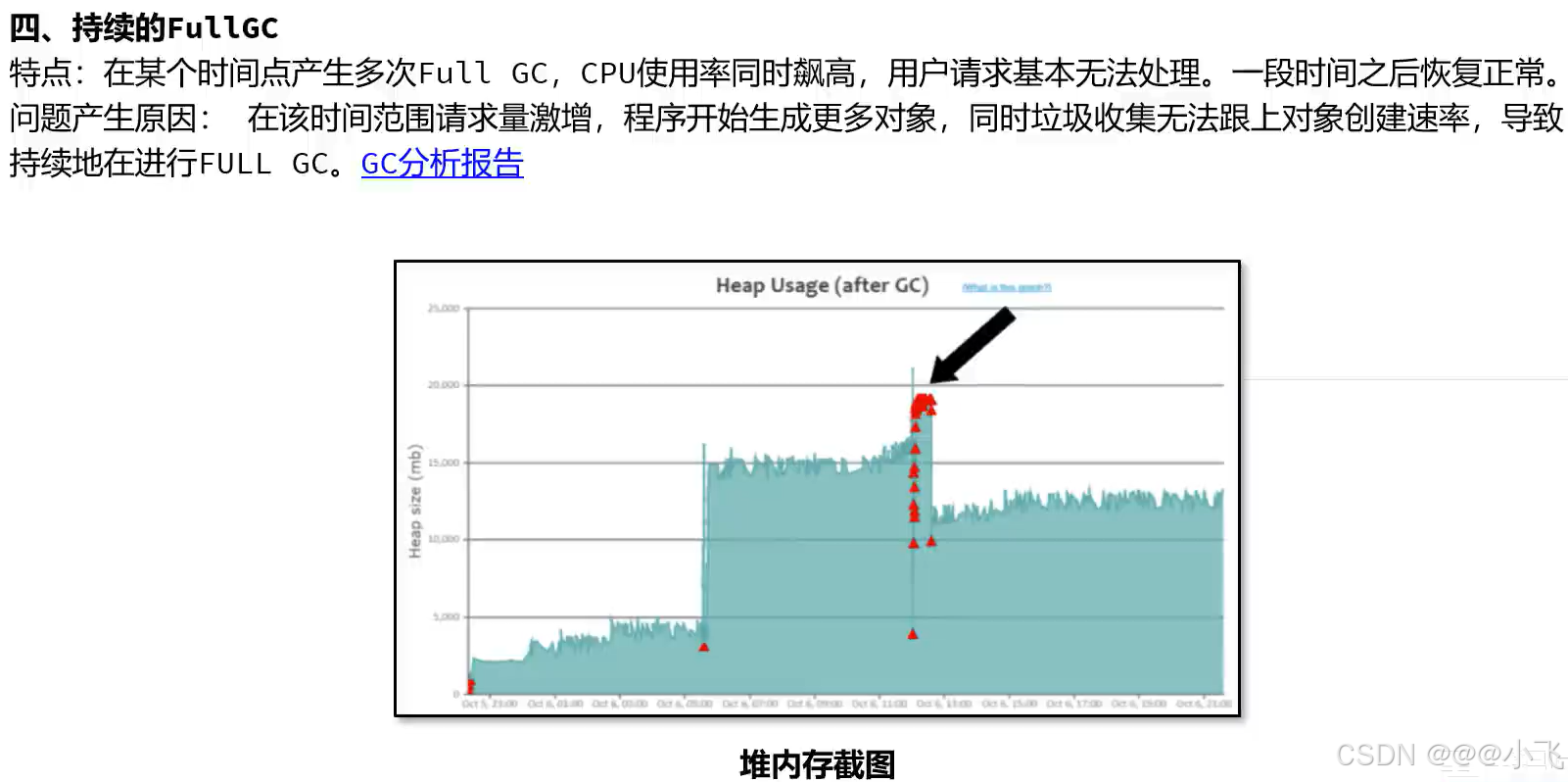
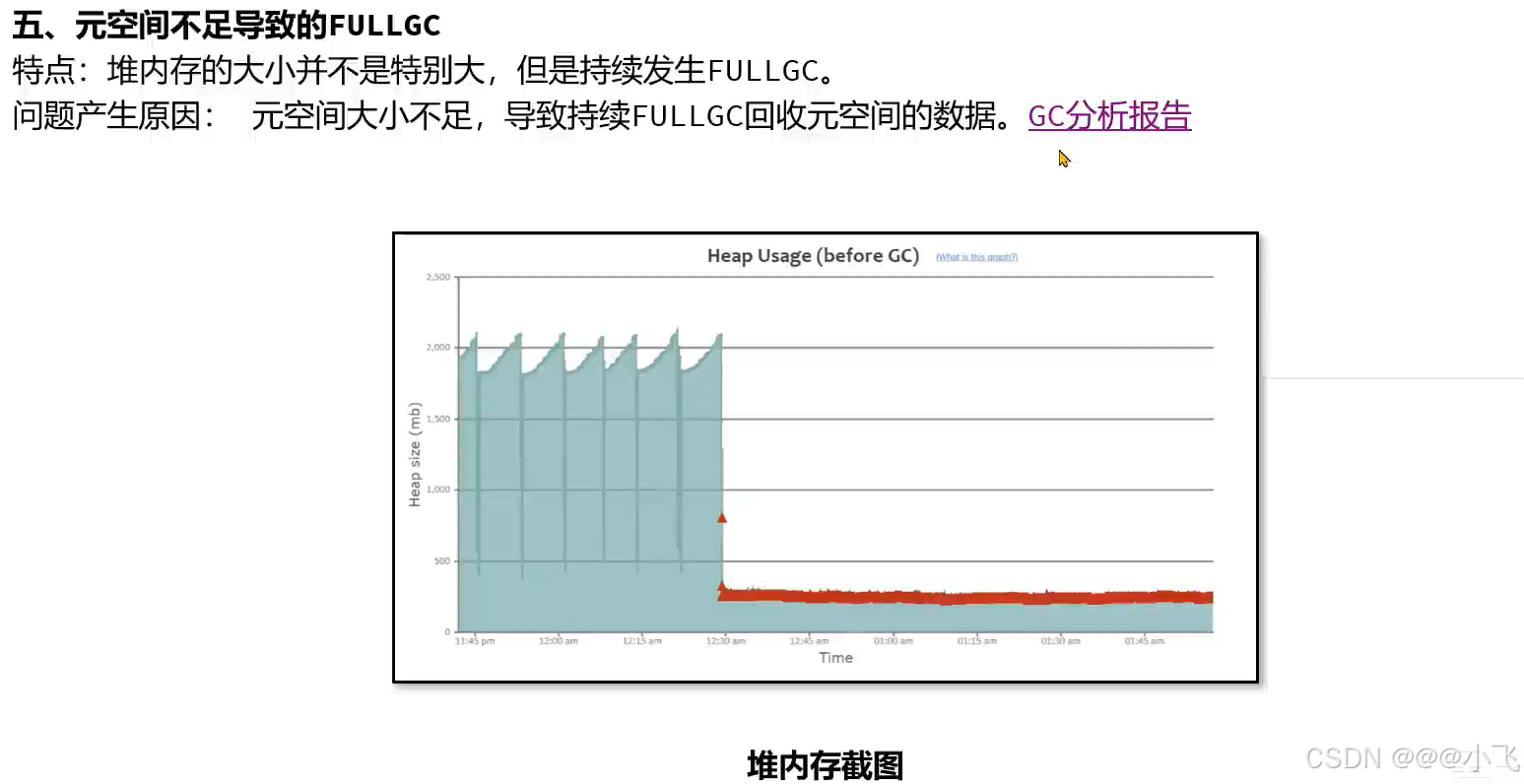
解决GC调优的手段
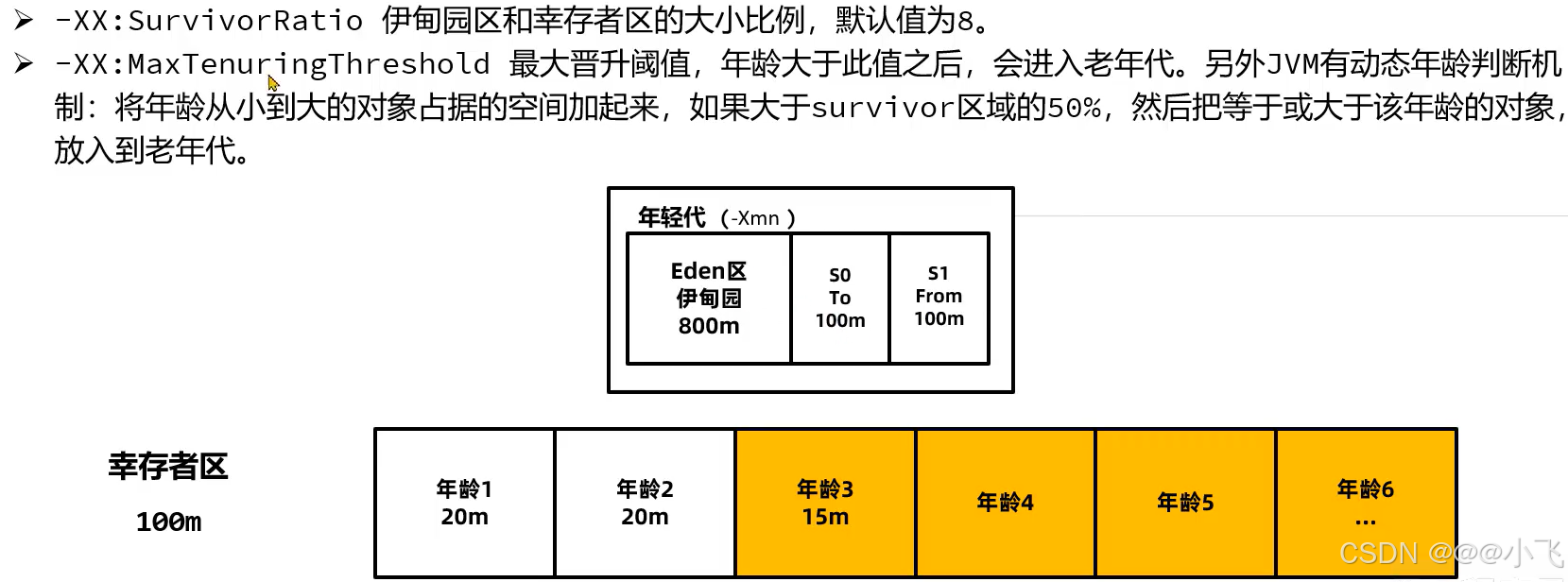
优化JVM参数


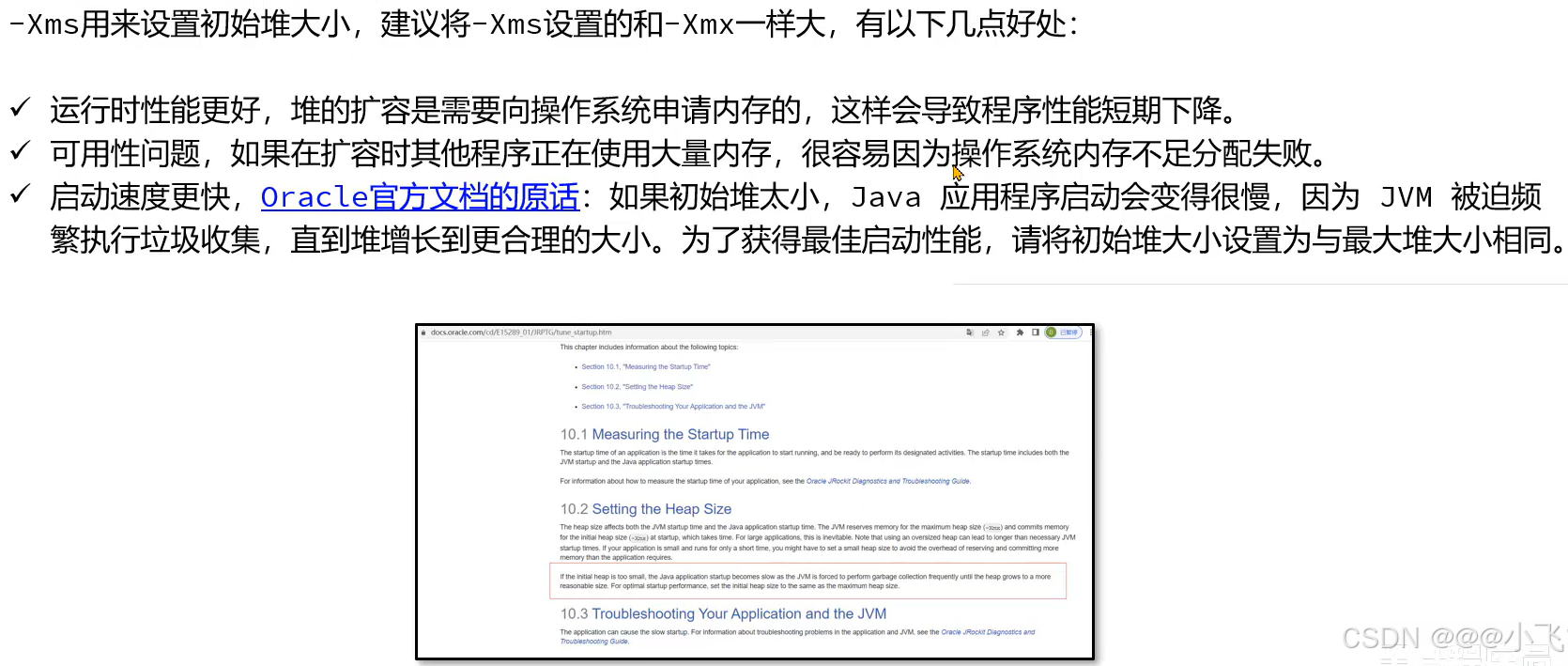
预留500MB内存给突发情况

如果不知道设置多少,可以不设置(设置有更好)


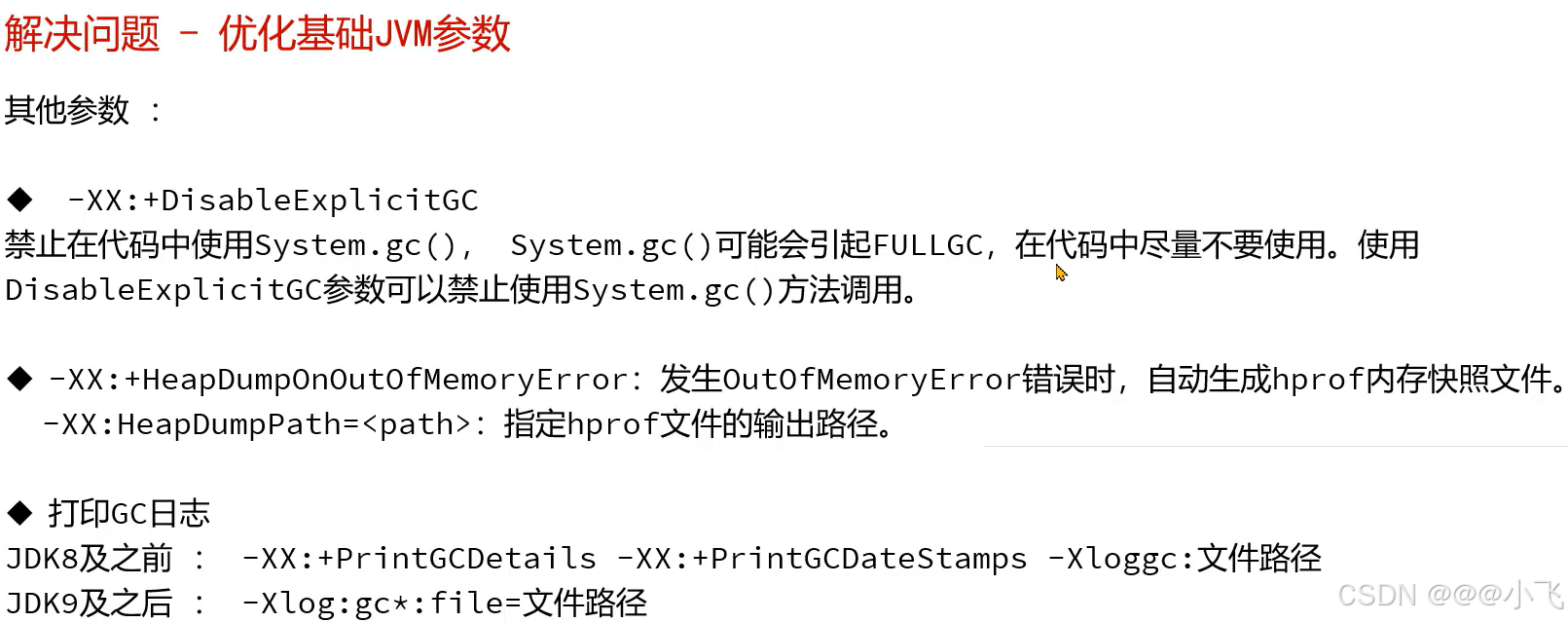
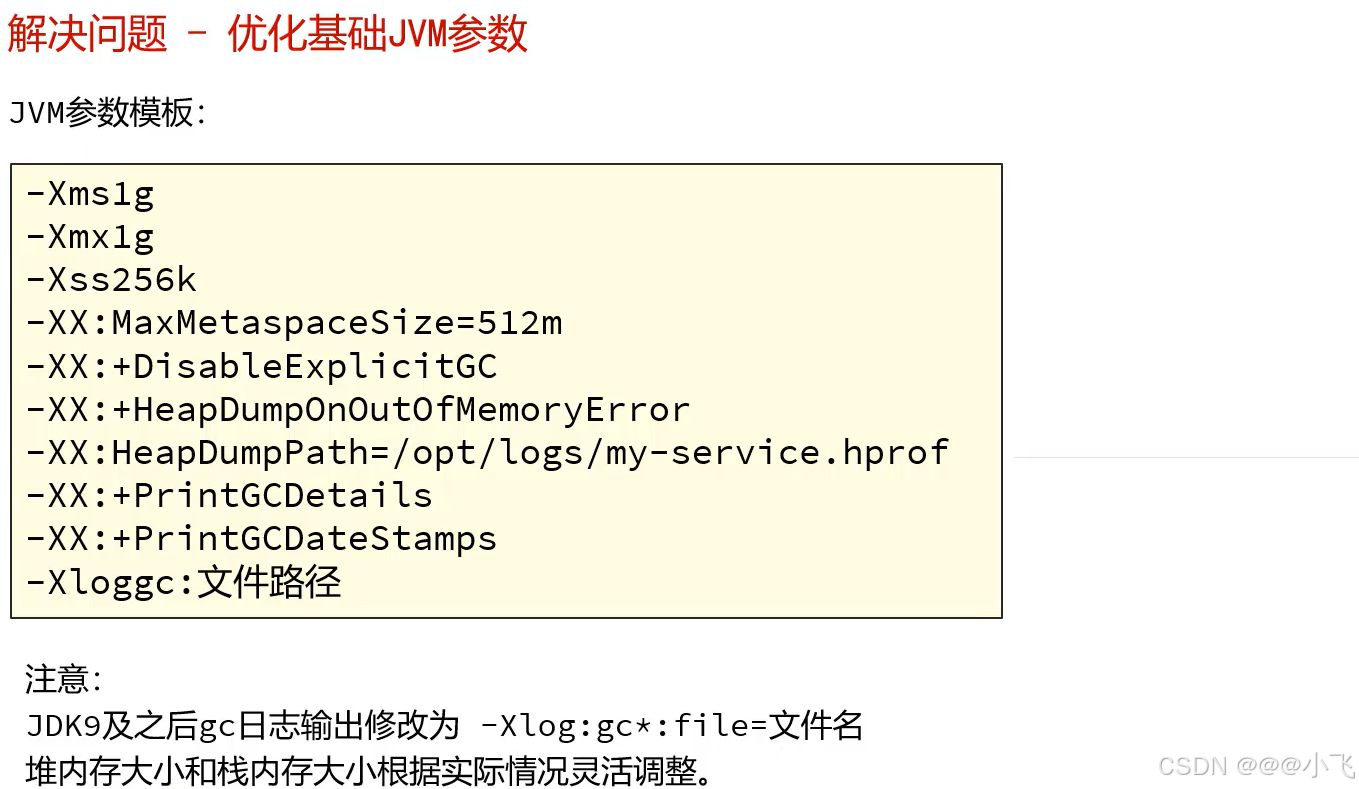
JDK9之后可以直接将后3行的日志输出替换为一行
更换垃圾回收器



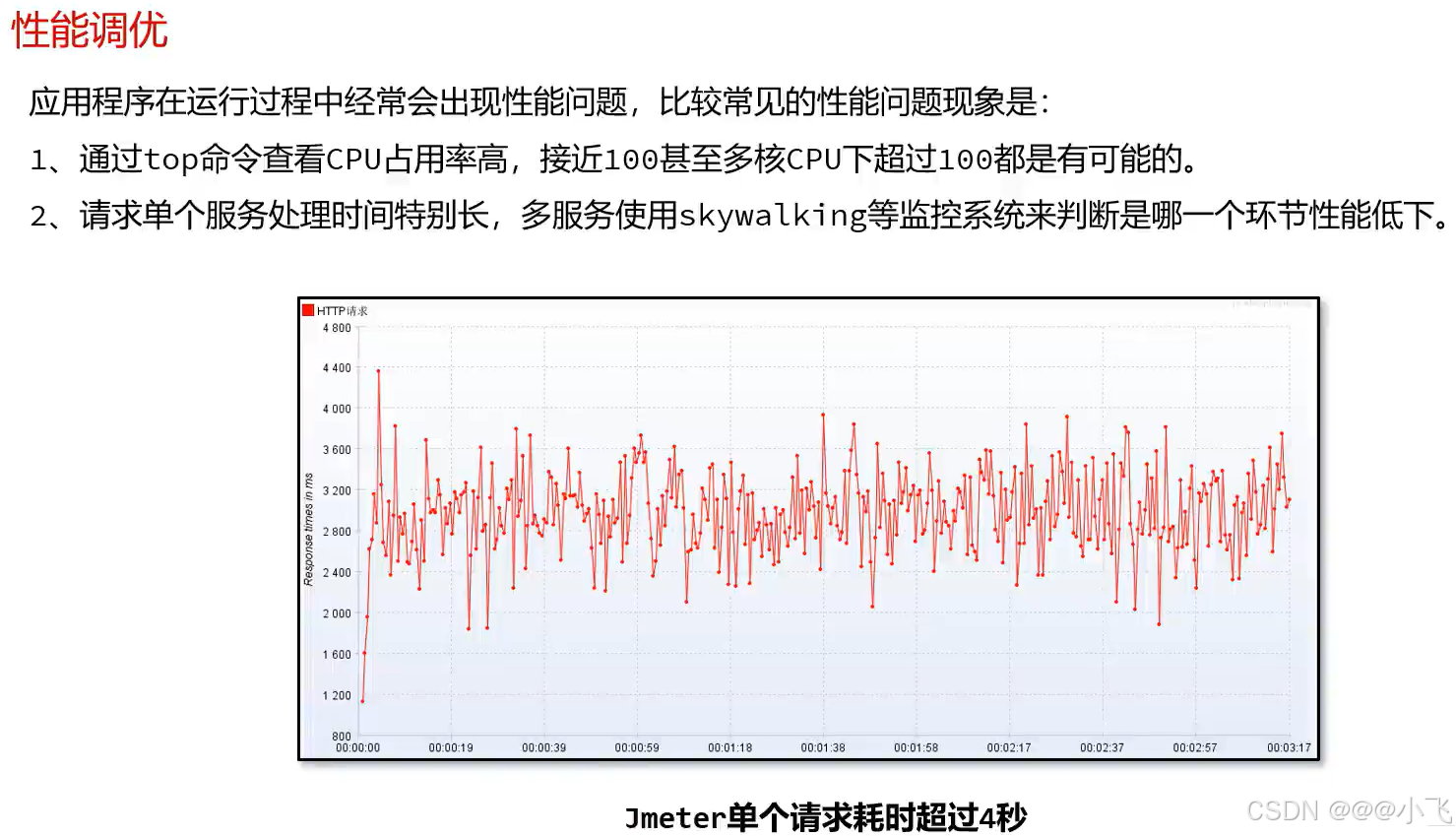
性能调优
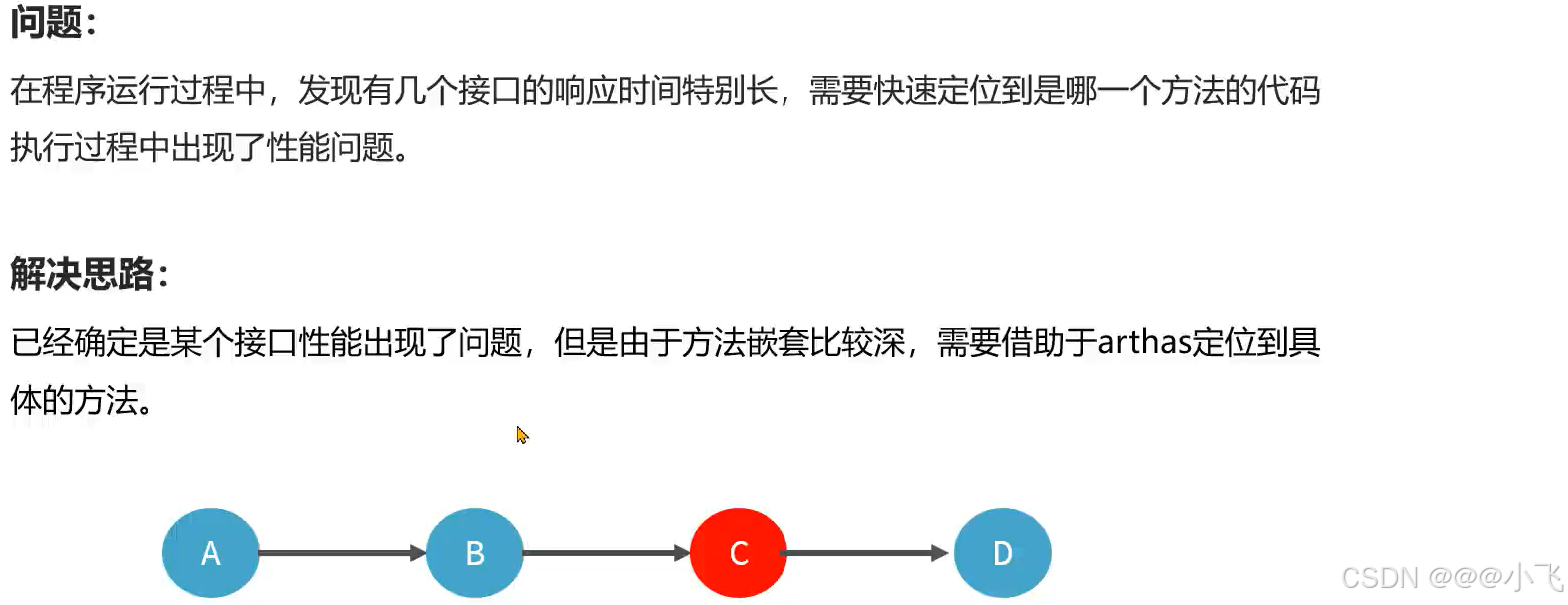
性能问题的现象和解决思路

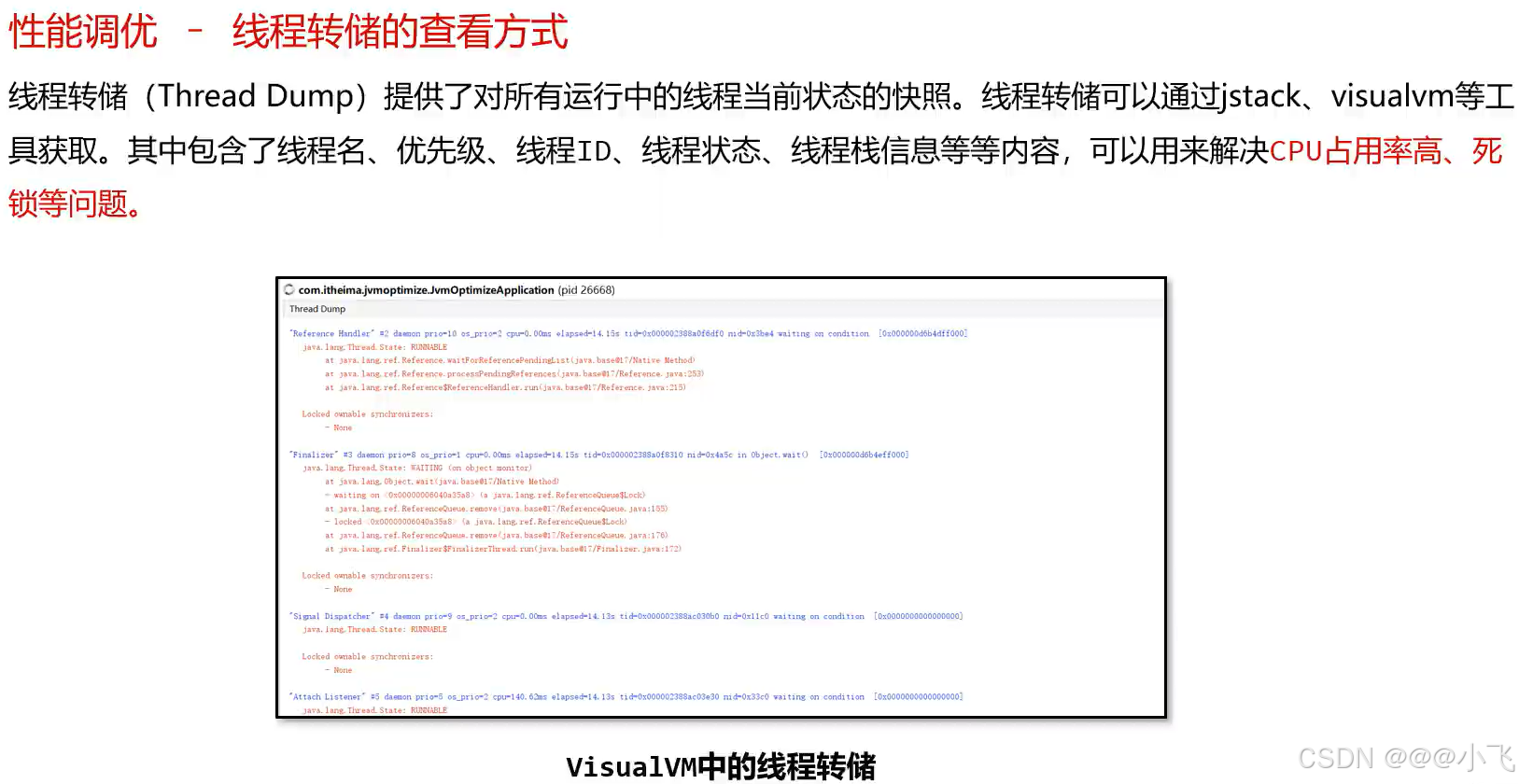
jstack命令和visualvm界面都可以生成线程转储文件
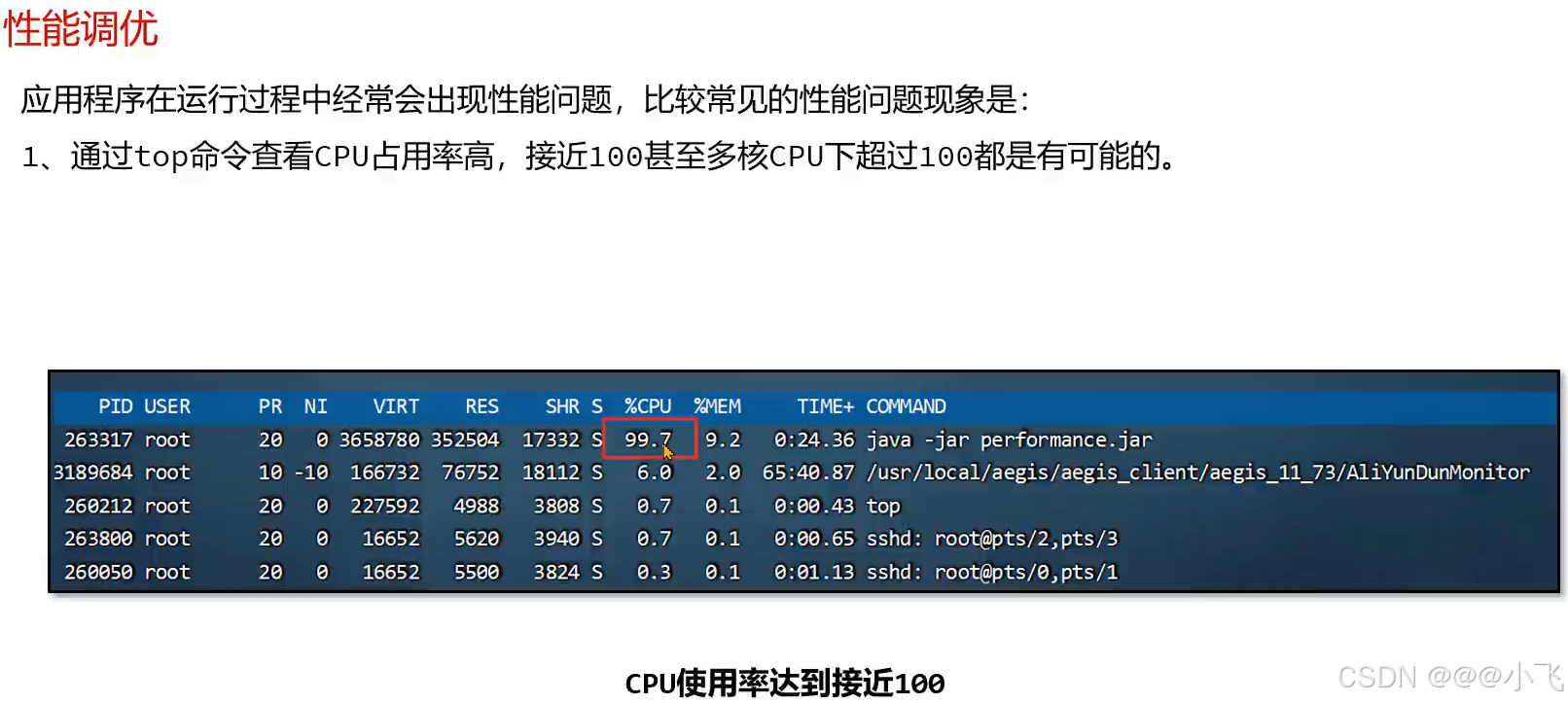
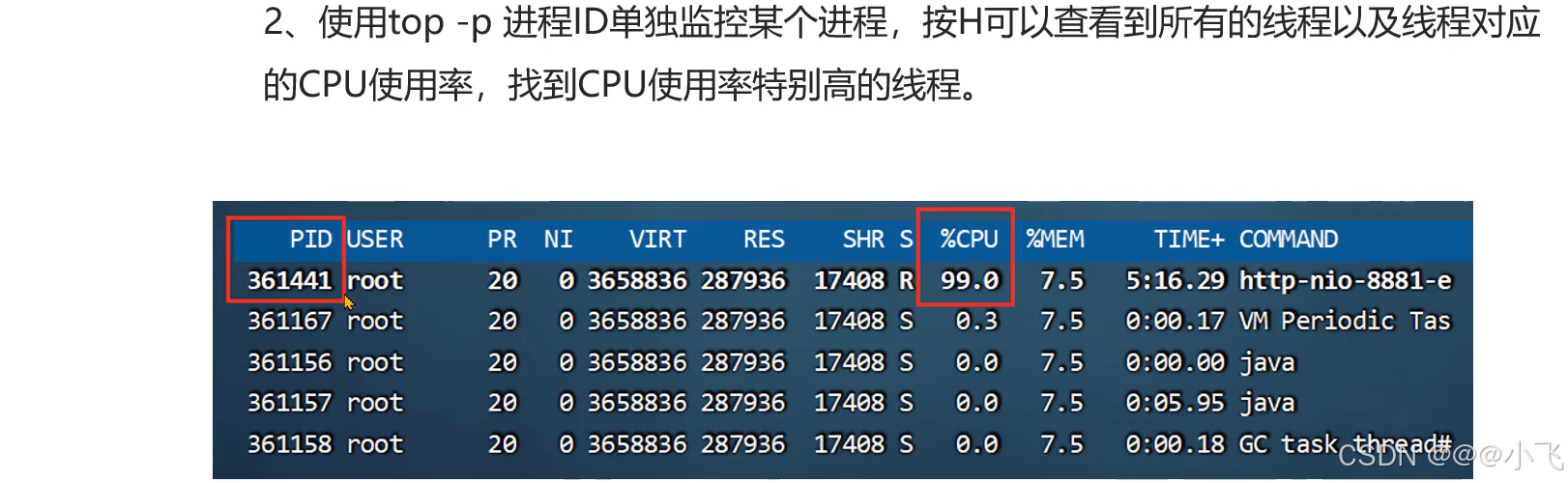
定位进程CPU占有率高问题


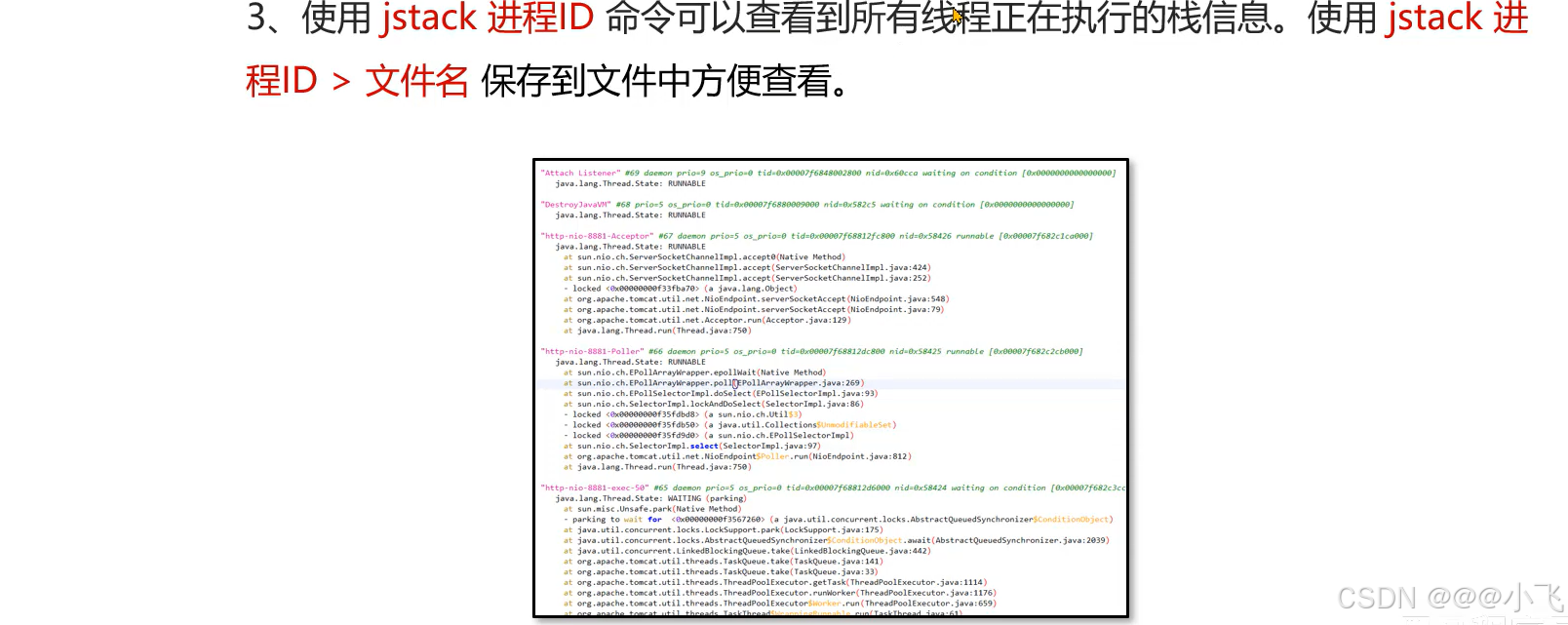
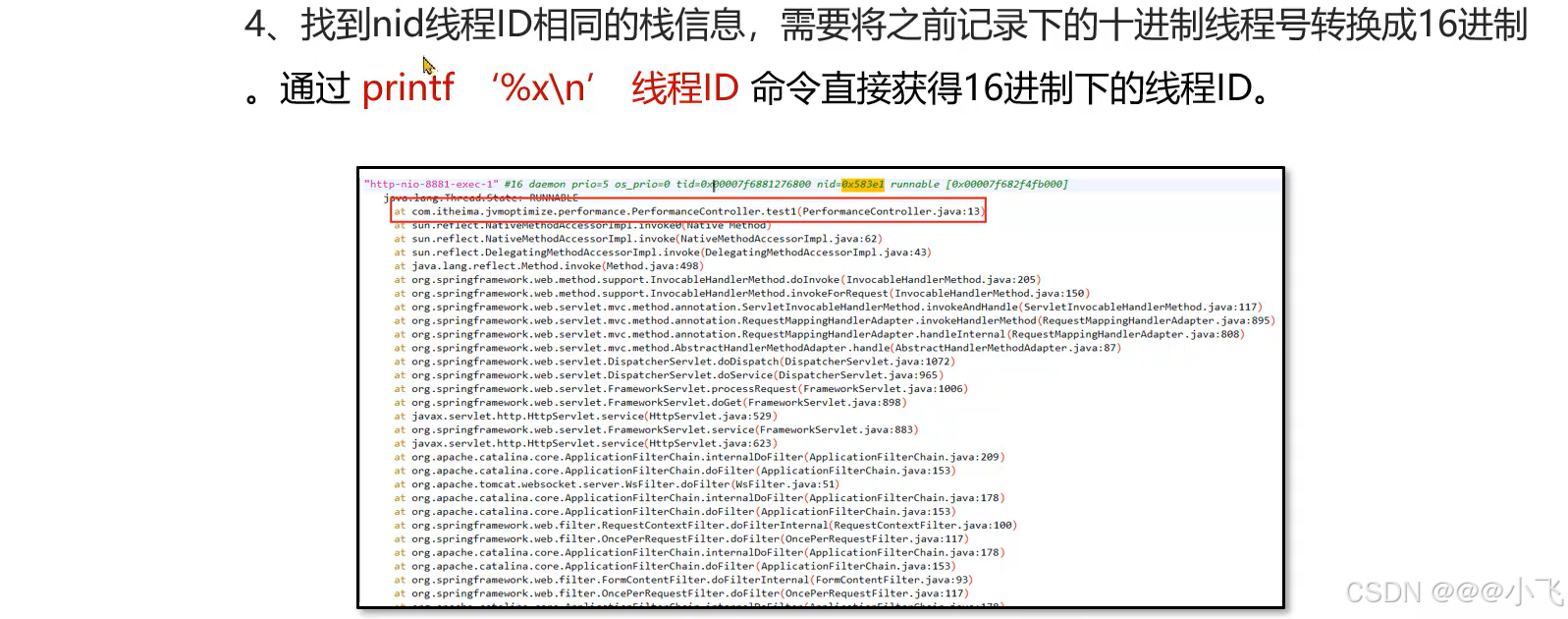


定位接口响应慢问题
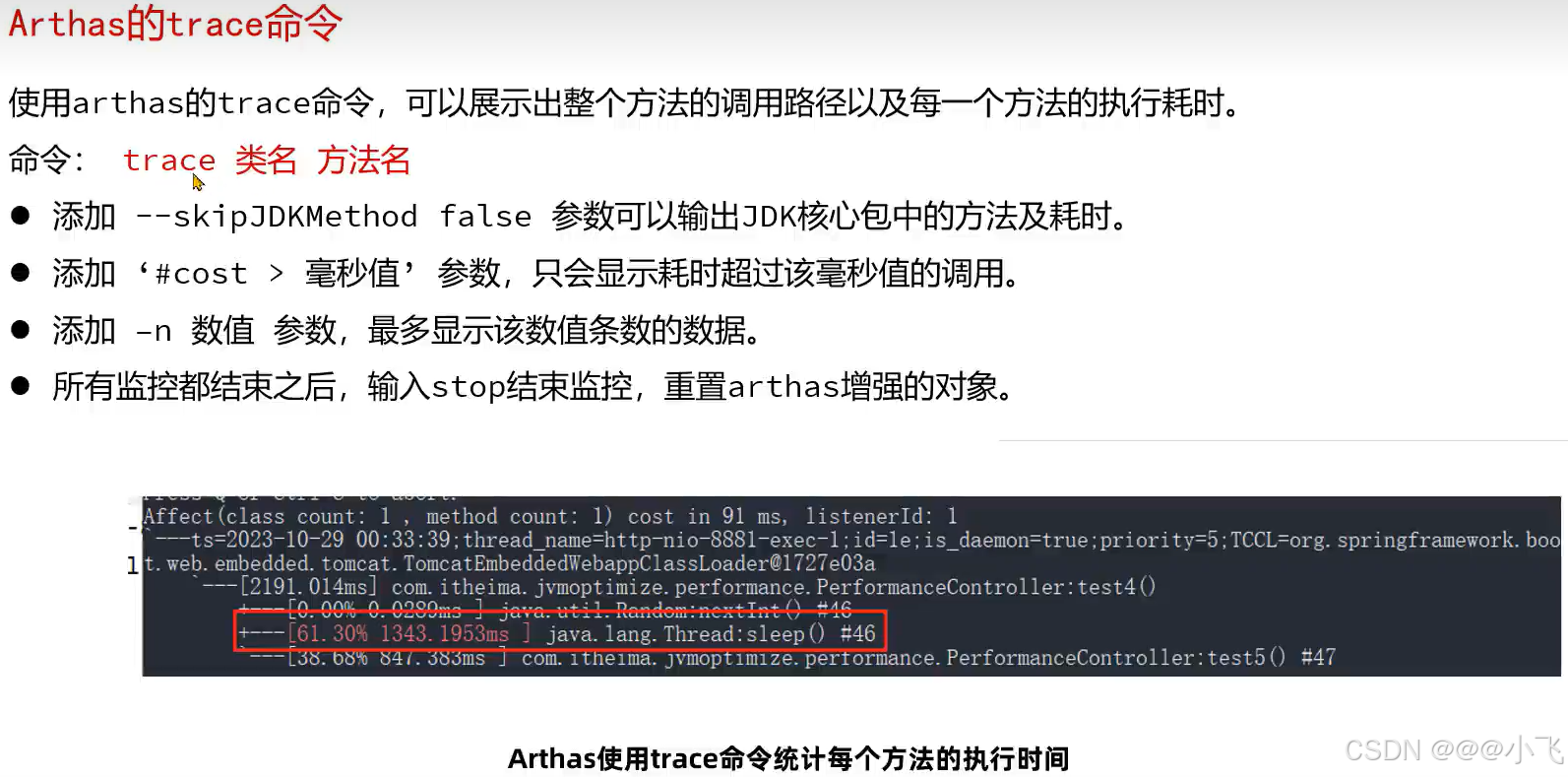
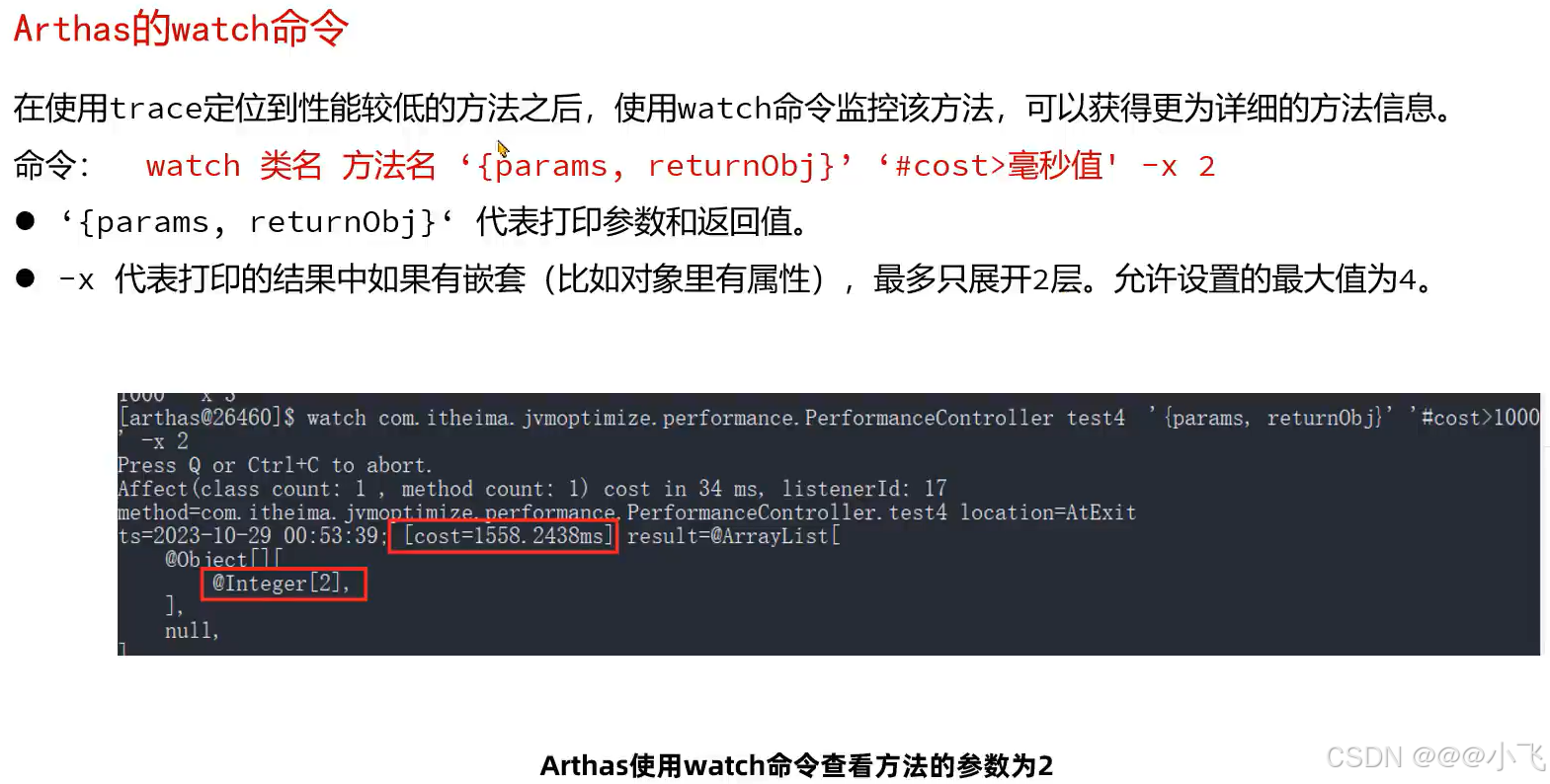
arthas底层通过动态代理方式增强,使用完后一定要stop结束监控,不然会损耗性能
火焰图定位接口响应慢问题



死锁的检查


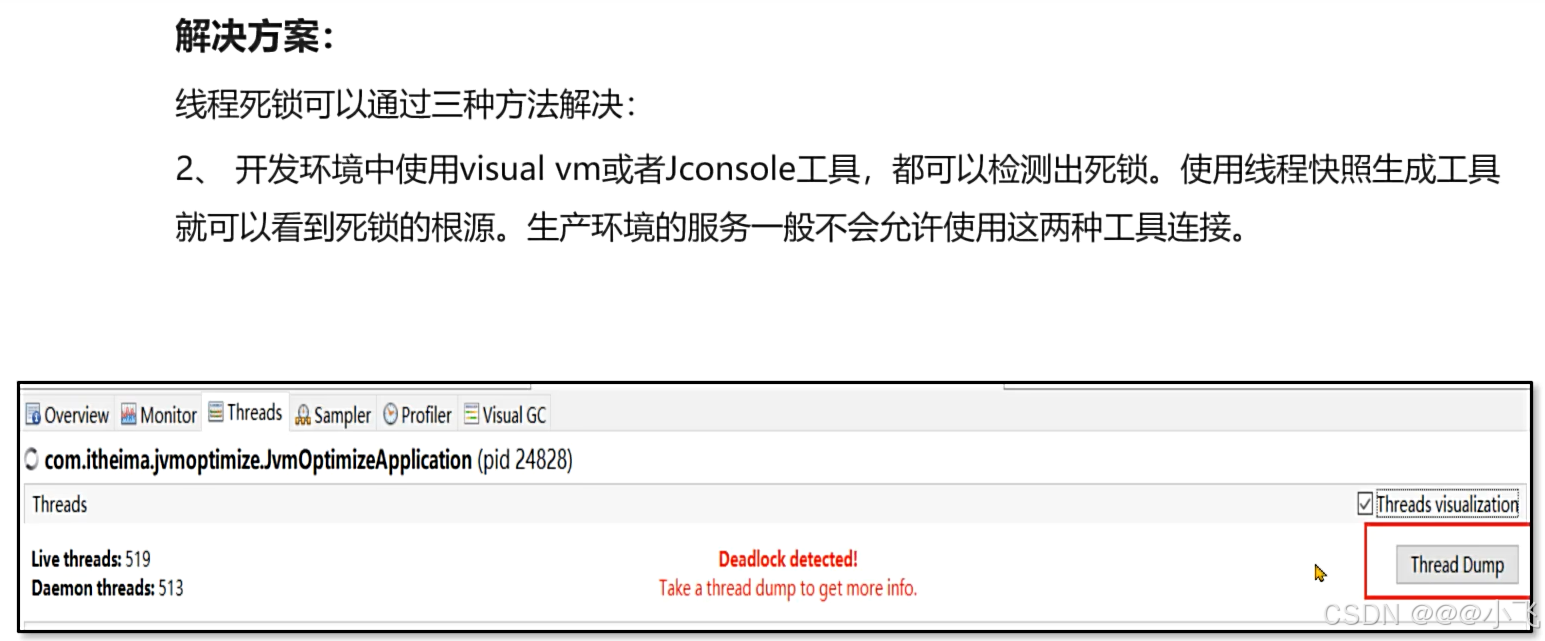
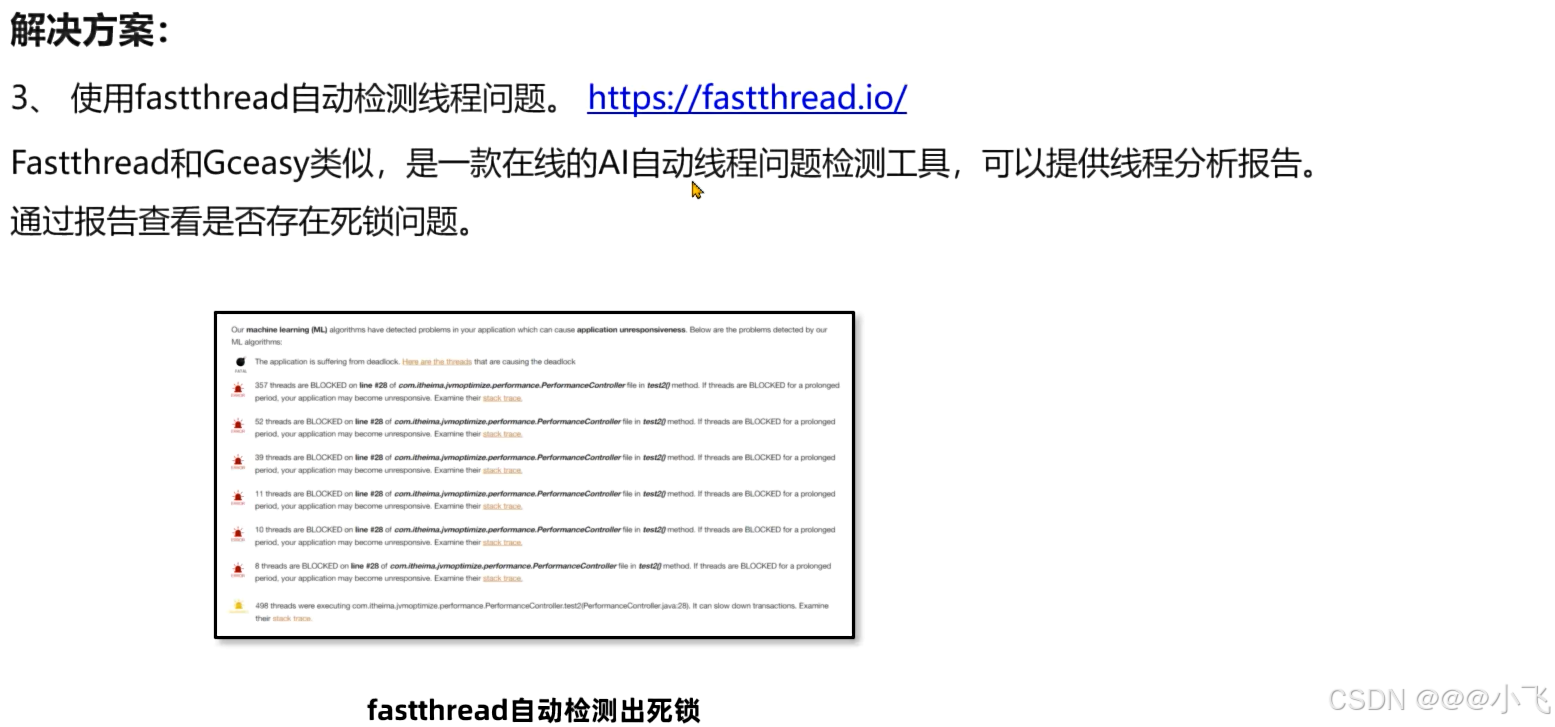
推荐使用解决方案3
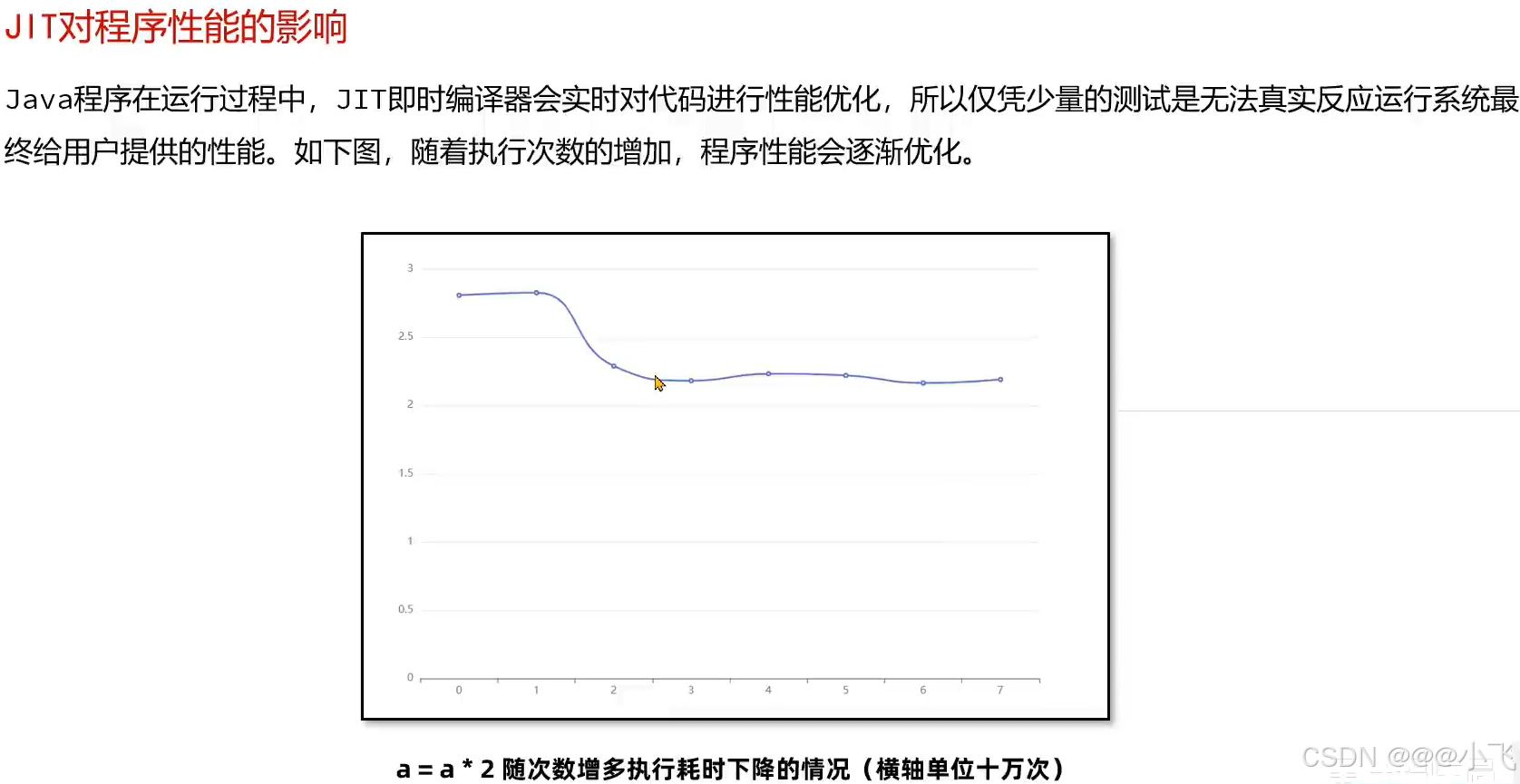
基准测试框架JMH

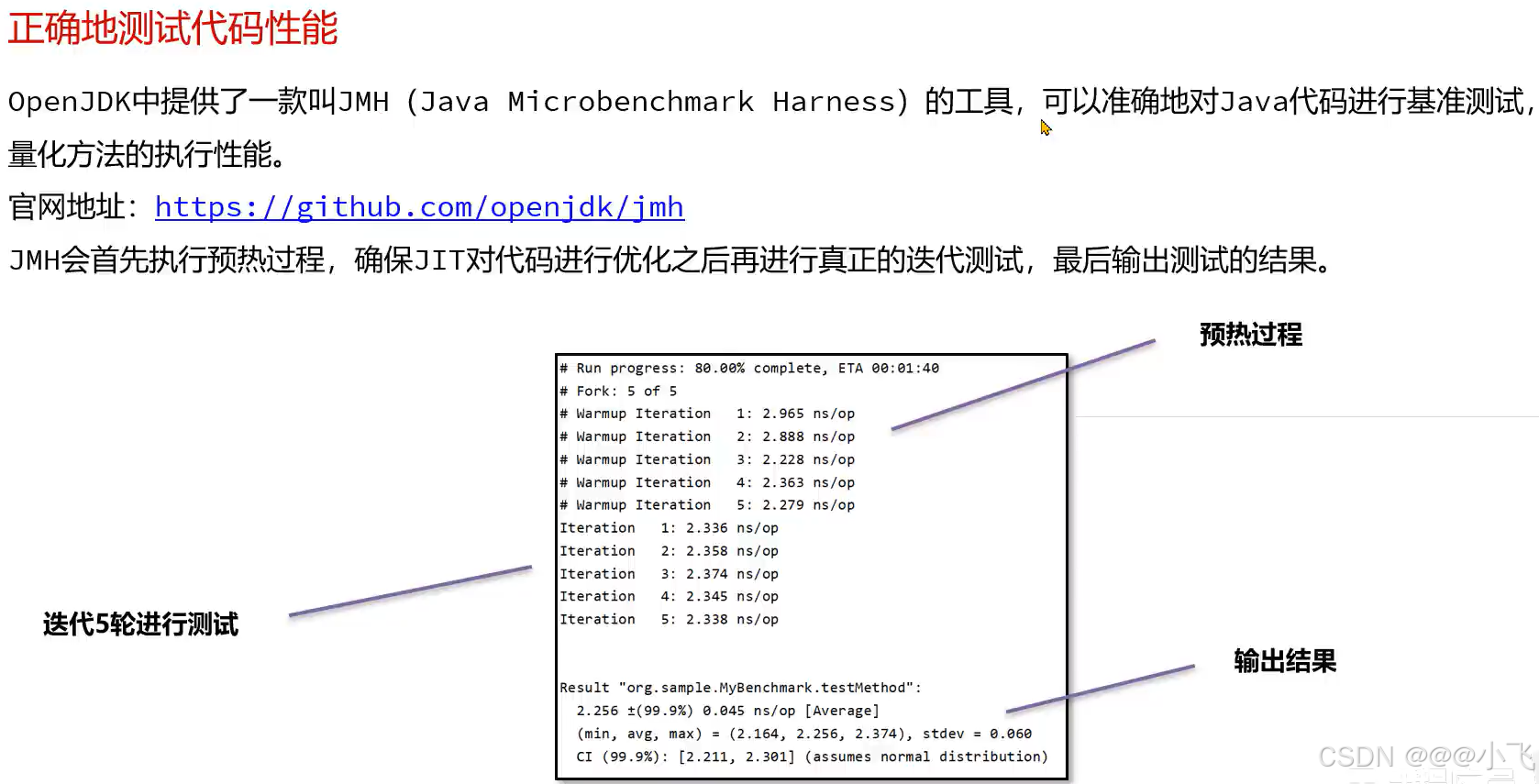
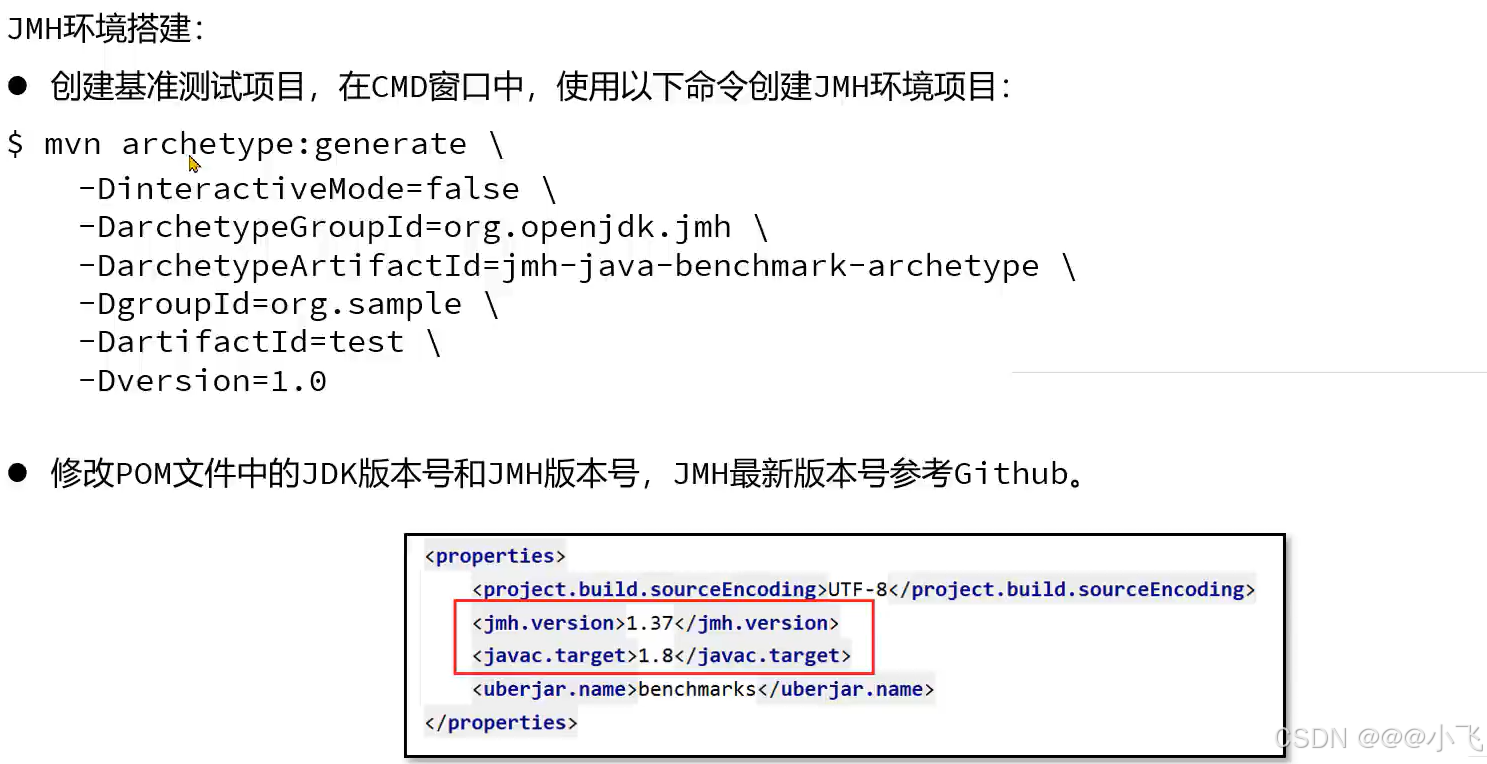
mvn archetype:generate ^
-DinteractiveMode=false ^
-DarchetypeGroupId="org.openjdk.jmh" ^
-DarchetypeArtifactId="jmh-java-benchmark-archetype" ^
-DgroupId="org.sample" ^
-DartifactId="test" ^
-Dversion="1.0"
使用maven 拉取JMH项目代码脚手架,然后修改pom文件的中依赖版本
编写 MyBenchmark.java
// 预热5次,每次1秒
@Warmup(iterations = 5, time = 1)
// 启动线程数
@Fork(value = 2)
// 显示平均时间
@BenchmarkMode(Mode.AverageTime)
// 输出时间单位为纳秒
@OutputTimeUnit(TimeUnit.NANOSECONDS)
// 变量共享范围
@State(Scope.Benchmark) // 在测试环境中全部共享
public class MyBenchmark {
@Benchmark
public int testMethod() {
int i = 0;
i++;
return i;
}
}然后执行maven生命周期中的verify,对集成测试的结果进行检查并生成 benchmarks.jar包
然后执行 java -jar benchmarks.jar 就能对 testMethod 方法预热测试了
也可以直接在 MyBenchmark.java 中使用 main 方法启动来对方法进行预热测试:但是这样idea对结果造成轻微的误差
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(MyBenchmark.class.getSimpleName())
.forks(1)
// .resultFormat(ResultFormatType.JSON) // 输出结果JSON文件
.build();
new Runner(options).run();
}然后将文件放到网站: JMH 结果文件可视化平台
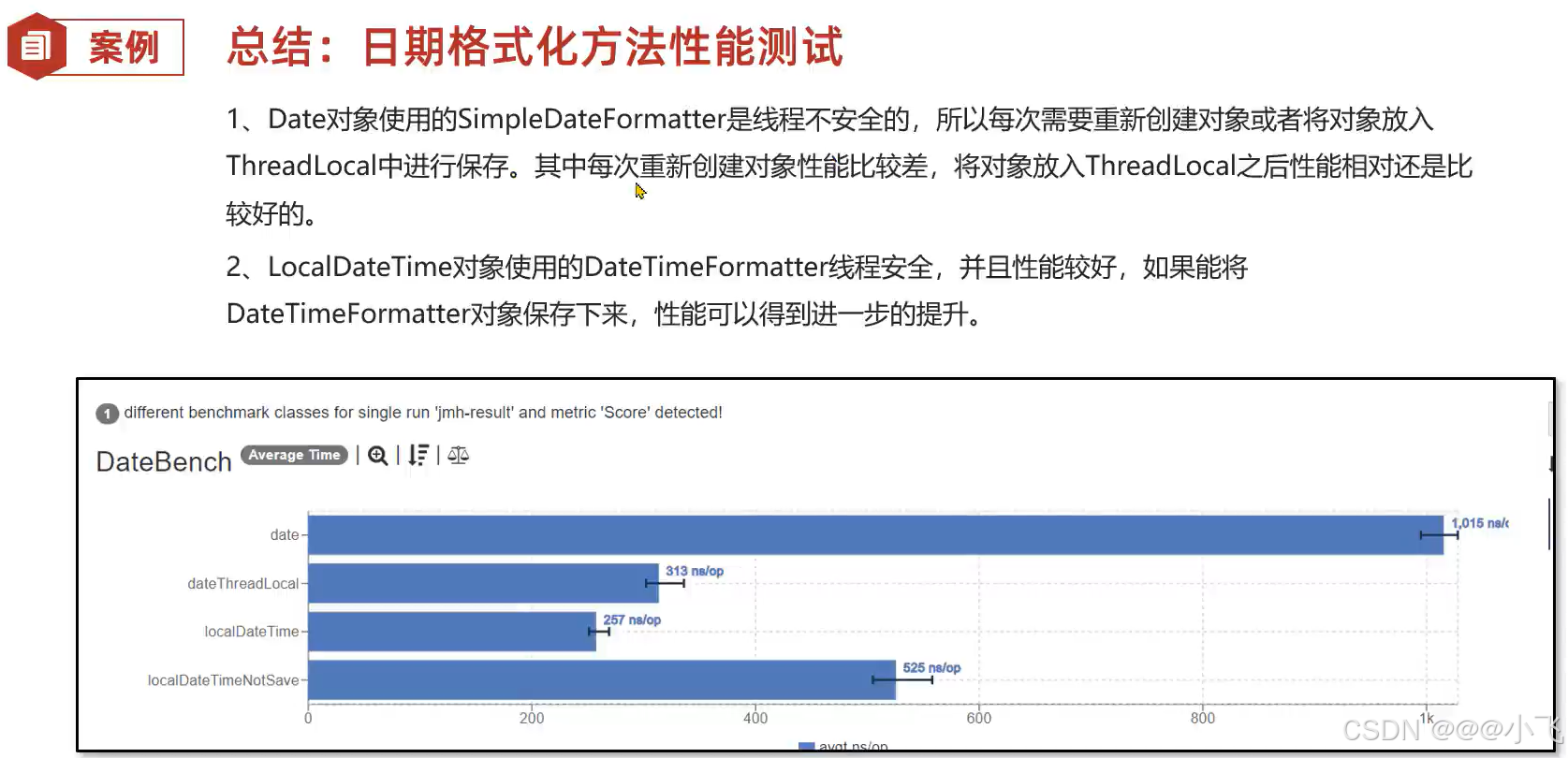
发现使用 LocalDateTime + 共享对象 来格式化时间是性能最高的
