在Linux服务器运维工作中,磁盘I/O瓶颈是导致系统性能下降的常见原因之一。当服务器出现响应缓慢、应用卡顿等问题时,及时定位并解决高I/O占用进程就显得尤为重要。本文将从核心思路出发,通过“确认问题-定位磁盘-锁定进程-深入分析”四个步骤,详细介绍Linux下磁盘I/O高占用进程的排查方法,帮助运维人员高效解决磁盘I/O相关问题。
一、排查核心思路
磁盘I/O排查需遵循“由全局到局部、由表面到深层”的逻辑,避免盲目定位。核心流程可分为四步:
- 确认问题:先判断性能瓶颈是否真的在磁盘I/O,而非CPU或内存。
- 全局视角:找到压力过大的磁盘或分区,缩小排查范围。
- 进程视角:定位对目标磁盘进行大量读写操作的具体进程。
- 深入分析:挖掘高I/O进程的具体行为(如读写文件、系统调用等),为后续优化提供依据。
二、第1步:确认全局磁盘I/O状况
首先需要通过工具确认是否存在磁盘I/O瓶颈,并定位压力最高的磁盘。这里首选iostat工具(来自sysstat包),它能直观展示磁盘的读写速率、利用率等关键指标。
1.1 安装sysstat(含iostat工具)
不同Linux发行版的安装命令略有差异:
- Ubuntu/Debian系统:
sudo apt update && sudo apt install sysstat - CentOS/RHEL/Fedora系统:
sudo yum install sysstat # 或 sudo dnf install sysstat(Fedora新版本)
1.2 运行iostat查看磁盘状态
使用以下命令实时监控磁盘I/O,每2秒刷新一次(间隔可自定义):
iostat -dx 2
-d:仅显示磁盘相关统计信息,排除CPU信息。-x:显示扩展统计信息(如等待时间、利用率),比默认输出更详细。
1.3 关键指标解读
iostat输出结果中,以下指标是判断磁盘I/O瓶颈的核心:
| 指标 | 含义 | 参考标准 |
|---|---|---|
Device |
磁盘设备名(如sda、vda、nvme0n1,NVMe硬盘通常以nvme开头) |
- |
r/s/w/s |
每秒读/写请求数量(IOPS) | 无固定标准,需结合业务判断 |
rkB/s/wkB/s |
每秒读/写数据量(吞吐量,单位KB) | 无固定标准,需结合业务判断 |
await |
每个I/O请求的平均等待时间(毫秒),包含队列等待时间和设备处理时间 | 正常应<10ms,>50ms说明排队严重 |
%util |
磁盘设备利用率(百分比),表示磁盘忙时占比 | 持续>80%说明磁盘饱和,存在瓶颈 |
1.4 示例分析
假设iostat输出如下:
Device r/s w/s rkB/s wkB/s await %util
sda 0.00 485.00 0.00 59420.00 120.33 98.20
vda 2.00 10.00 16.00 80.00 2.10 3.50
从结果可见:
sda磁盘的%util高达98.2%(接近饱和),await达120.33ms(排队严重),wkB/s为59420KB/s(约58MB/s),说明sda是高压力磁盘,且主要压力来自写入操作。vda磁盘各项指标正常,无I/O瓶颈。
三、第2步:定位高I/O占用进程
确认高压力磁盘(如上文的sda)后,下一步需锁定对该磁盘进行大量读写的进程。常用工具包括iotop(直观实时)和pidstat(详细统计)。
方法1:使用iotop(首选,实时监控)
iotop类似top工具,但专门针对磁盘I/O,能按进程/线程显示实时读写速率,且支持交互操作。
1.1 安装iotop
- Ubuntu/Debian系统:
sudo apt install iotop - CentOS/RHEL/Fedora系统:
sudo yum install iotop # 或 sudo dnf install iotop
1.2 运行iotop(需root权限)
sudo iotop
1.3 实用操作技巧
- 只显示有I/O活动的进程:按下键盘
o键(或启动时加--only参数,如sudo iotop --only),避免无关进程干扰。 - 自定义刷新间隔:通过
-d参数设置,如sudo iotop -d 3表示每3秒刷新一次。 - 按列排序:按左右箭头键切换排序列(如按“DISK WRITE”排序,快速找到写入量最大的进程)。
- 查看累计I/O:加
-a参数显示进程累计读写量,而非实时速率(适合长期监控)。
1.4 输出解读
假设iotop输出如下:
Total DISK READ: 0.00 B/s | Total DISK WRITE: 59.42 M/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
4560 be/4 mysql 0.00 B/s 59.42 M/s 0.00 % 99.99 % mysqld
1230 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % bash
关键信息:
COMMAND列显示进程名,此处mysqld(MySQL服务进程)是主要 culprit。DISK WRITE列显示mysqld每秒写入59.42MB,与前文sda磁盘的写入量匹配。IO>列显示mysqld的I/O占用时间达99.99%,说明该进程几乎完全占用磁盘I/O资源。
方法2:使用pidstat(详细统计,支持历史记录)
pidstat是sysstat套件的一部分,不仅能显示进程的实时I/O统计,还能记录历史数据,适合需要长期跟踪的场景。
2.1 运行pidstat监控I/O
- 监控所有进程的I/O(每2秒刷新):
sudo pidstat -d 2 - 监控特定进程(已知PID后):若已通过
iotop找到可疑进程PID(如4560),可针对性监控:sudo pidstat -d -p 4560 2
2.2 输出解读
假设pidstat输出如下:
Linux 5.4.0-xxx-generic 2024-05-20 _x86_64_ (4 CPU)
03:15:20 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:15:22 PM 112 4560 0.00 59420.00 0.00 mysqld
03:15:24 PM 112 4560 0.00 58980.00 0.00 mysqld
关键指标:
kB_rd/s:进程每秒从磁盘读取的字节数(KB),此处mysqld无读取操作(0.00)。kB_wr/s:进程每秒向磁盘写入的字节数(KB),mysqld稳定在约59000KB/s(58MB/s),与iotop结果一致。kB_ccwr/s:进程每秒取消写入的字节数(KB,如文件删除后的回写),此处为0,无异常。
四、第3步:深入分析高I/O进程
找到高I/O进程(如mysqld,PID=4560)后,需进一步分析其具体行为,例如“读写哪些文件”“发起哪些系统调用”,为优化提供方向。常用工具包括lsof、strace和/proc文件系统。
方法1:用lsof查看进程打开的文件
lsof(List Open Files)可列出进程当前打开的所有文件(包括普通文件、设备文件、日志文件等),帮助定位进程读写的具体文件。
1.1 基础用法(列出进程打开的所有文件)
sudo lsof -p 4560
-p 4560:指定进程PID为4560(mysqld)。
1.2 过滤关键文件(重点关注写入/删除的文件)
实际场景中,进程打开的文件可能很多,可通过grep过滤核心文件(如正在写入的文件、已删除但仍被占用的日志文件):
# 过滤“可写入的普通文件”(REG类型+W权限)和“已删除的文件”(DEL状态)
sudo lsof -p 4560 | grep -E "REG.*W|DEL"
1.3 示例输出与解读
mysqld 4560 mysql 4u REG 8,1 10485760 123456 /var/lib/mysql/ib_logfile0 (deleted)
mysqld 4560 mysql 5u REG 8,1 10485760 123457 /var/lib/mysql/ib_logfile1
mysqld 4560 mysql 6u REG 8,1 524288000 123458 /var/lib/mysql/testdb.ibd
关键信息:
ib_logfile0(已删除,DEL状态)和ib_logfile1是MySQL的redo日志文件,用于崩溃恢复,mysqld正在写入这些文件。testdb.ibd是MySQL的表空间文件,可能因大量写入操作(如批量插入)导致高I/O。
方法2:用strace跟踪进程的系统调用(高级调试)
strace可实时跟踪进程发起的系统调用(如read、write、open、sync等),能精确到“进程向哪个文件写入了多少数据”,但开销较大,不建议在生产环境长时间运行。
2.1 基础用法(跟踪文件读写相关调用)
sudo strace -ff -p 4560 -e trace=file,write,read -s 1024 -o /tmp/mysqld_strace.txt
参数解读:
-ff:跟踪进程的所有子线程(如mysqld的工作线程),并为每个线程生成独立日志文件。-p 4560:指定目标进程PID。-e trace=file,write,read:只跟踪与“文件操作”(file)、“写入”(write)、“读取”(read)相关的系统调用,减少冗余日志。-s 1024:显示字符串(如文件名)的前1024个字符,避免文件名被截断。-o /tmp/mysqld_strace.txt:将日志输出到指定文件(子线程日志会以mysqld_strace.txt.123形式命名)。
2.2 日志解读示例
查看/tmp/mysqld_strace.txt,可找到类似记录:
write(4, "\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00", 16) = 16
open("/var/lib/mysql/testdb.ibd", O_RDWR|O_DIRECT|O_DSYNC) = 7
write(7, "\x08\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00", 16384) = 16384
write(4, ...):向文件描述符4(对应ib_logfile1)写入数据。open(...):打开testdb.ibd文件,权限为“读写”(O_RDWR)+“直接I/O”(O_DIRECT)。write(7, ...):向testdb.ibd(文件描述符7)写入16384字节(16KB)数据,验证了mysqld对该表空间文件的写入操作。
方法3:用/proc文件系统查看进程累计I/O
Linux的/proc文件系统是内核与用户空间的接口,其中/proc/<PID>/io文件存储了进程的累计I/O统计信息,适合手动计算进程的实时I/O速率。
3.1 查看累计I/O
sudo cat /proc/4560/io
3.2 输出解读与速率计算
示例输出:
rchar: 12345678 # 进程从内核读取的总字节数(含缓存,非物理磁盘)
wchar: 987654321 # 进程向内核写入的总字节数(含缓存,非物理磁盘)
syscr: 120 # 进程发起的读系统调用次数
syscw: 450 # 进程发起的写系统调用次数
read_bytes: 4096000 # 进程从物理磁盘读取的总字节数(KB)
write_bytes: 20480000 # 进程向物理磁盘写入的总字节数(KB)
cancelled_write_bytes: 0 # 取消写入的总字节数
- 实时速率计算:间隔10秒读取两次
write_bytes,计算差值除以时间:- 第一次读取:
write_bytes=20480000 - 10秒后第二次读取:
write_bytes=26480000 - 写入速率 = (26480000 - 20480000) / 10 = 600000 KB/s = 600 MB/s(此处为示例,实际需根据真实数据计算)。
- 第一次读取:
五、常见高I/O进程场景与优化方向
排查出高I/O进程后,需结合业务场景制定优化方案。以下是常见高I/O进程及对应的优化思路:
| 进程类型 | 常见场景 | 优化方向 |
|---|---|---|
| 数据库(MySQL/PostgreSQL) | 1. 大量写入(如批量插入、日志刷盘);2. 全表扫描导致的大量读取;3. 脏页频繁刷新。 | 1. 调整数据库参数(如MySQL的innodb_flush_log_at_trx_commit);2. 优化SQL(加索引避免全表扫描);3. 升级磁盘(如机械硬盘换SSD)。 |
| 日志服务(rsyslog/journald) | 应用日志输出过多(如 debug 级别日志未关闭),导致日志文件频繁写入。 | 1. 调整日志级别(如改为 info/warn);2. 配置日志轮转(logrotate),避免单个日志文件过大;3. 日志归档到远程存储(如ELK)。 |
| 备份工具(rsync/tar/cp) | 全量备份时大量读取源文件,写入目标存储,占用磁盘I/O。 | 1. 改为增量备份(如rsync --link-dest);2. 在业务低峰期执行备份;3. 使用多线程工具(如pigz替代gzip压缩)。 |
| 包管理器(apt/yum) | 批量安装/更新软件时,大量下载包并解压写入磁盘。 | 1. 选择业务低峰期执行更新;2. 配置本地yum/apt源(如阿里云镜像),减少下载耗时。 |
| 虚拟机/容器(KVM/Docker) | 虚拟机磁盘镜像(qcow2/raw)或容器数据卷的频繁读写。 | 1. 使用SSD存储镜像/数据卷;2. 配置磁盘缓存策略(如KVM的cache=writeback);3. 限制容器I/O速率(如Docker的–device-read-bps)。 |
六、排查流程总结(附流程图)
Linux 磁盘 I/O 高占用进程的排查需遵循“从全局到局部、从现象到本质”的逻辑,通过标准化流程可高效定位问题并落地解决方案。以下为完整排查流程拆解及可视化流程图。
1. 排查流程分步拆解
步骤 1:全局诊断 - 确认磁盘 I/O 瓶颈
- 核心目标:判断性能问题是否源于磁盘 I/O(排除 CPU、内存瓶颈干扰),定位高压力磁盘。
- 执行工具:
iostat(需提前安装sysstat套件)。 - 关键操作:
- 运行命令
sudo iostat -dx 2(每 2 秒刷新一次,-d仅显磁盘、-x显扩展指标)。 - 重点关注指标:
%util(磁盘利用率,持续 >80% 为饱和)、await(I/O 等待时间,>50ms 为排队严重)、wkB/s/rkB/s(读写吞吐量)。 - 输出结果中,筛选出
%util和await异常的磁盘(如sda),作为后续排查焦点。
- 运行命令
步骤 2:进程定位 - 锁定高 I/O 进程
- 核心目标:找到对“高压力磁盘”进行大量读写的具体进程(获取 PID 和进程名)。
- 执行工具:优先用
iotop(实时直观),备选pidstat(统计详细)。 - 关键操作(以
iotop为例):- 运行命令
sudo iotop --only(--only仅显有 I/O 活动的进程,减少干扰)。 - 按“DISK WRITE”或“DISK READ”列排序(左右箭头键切换),定位读写量最大的进程。
- 记录目标进程的 PID(如 4560)和 进程名(如
mysqld),用于下一步分析。
- 运行命令
步骤 3:深度分析 - 挖掘进程 I/O 行为
- 核心目标:明确高 I/O 进程的具体操作(如读写哪些文件、发起哪些系统调用),为优化提供依据。
- 执行工具:
lsof(查打开的文件)、/proc/<PID>/io(查累计 I/O 统计)、strace(查系统调用,谨慎使用)。 - 关键操作:
- 查读写文件:运行
sudo lsof -p 4560 | grep -E "REG.*W|DEL",筛选进程写入的普通文件(REG.*W)或已删除但仍占用的文件(DEL,如未释放的日志),定位核心读写文件(如/var/lib/mysql/testdb.ibd)。 - 查累计 I/O:运行
sudo cat /proc/4560/io,通过对比不同时间的write_bytes/read_bytes,计算进程实时 I/O 速率(如间隔 10 秒差值 ÷10 得每秒写入量)。 - 查系统调用(可选):若需精准跟踪操作,运行
sudo strace -ff -p 4560 -e trace=file,write -o /tmp/strace.log(-ff跟踪子线程,-e过滤关键调用),但需注意:strace性能开销较大,生产环境避免长时间运行。
- 查读写文件:运行
步骤 4:优化落地 - 解决 I/O 瓶颈
- 核心目标:结合进程类型和业务场景,制定针对性优化方案,降低磁盘 I/O 压力。
- 优化方向(按进程类型匹配):
- 数据库进程(如
mysqld):调整参数(如 MySQL 的innodb_flush_log_at_trx_commit降低刷盘频率)、优化 SQL(加索引避免全表扫描)、升级磁盘(机械硬盘换 SSD)。 - 日志进程(如
rsyslog):降低日志级别(debug → info)、配置logrotate日志轮转、将日志归档至远程存储(如 ELK 集群)。 - 备份进程(如
rsync):改为增量备份(rsync --link-dest)、在业务低峰期执行、用多线程工具(如pigz替代gzip压缩)。
- 数据库进程(如
- 验证效果:优化后重新运行
iostat和iotop,确认磁盘%util、await恢复正常,高 I/O 进程读写量下降。
2. 排查流程可视化流程图
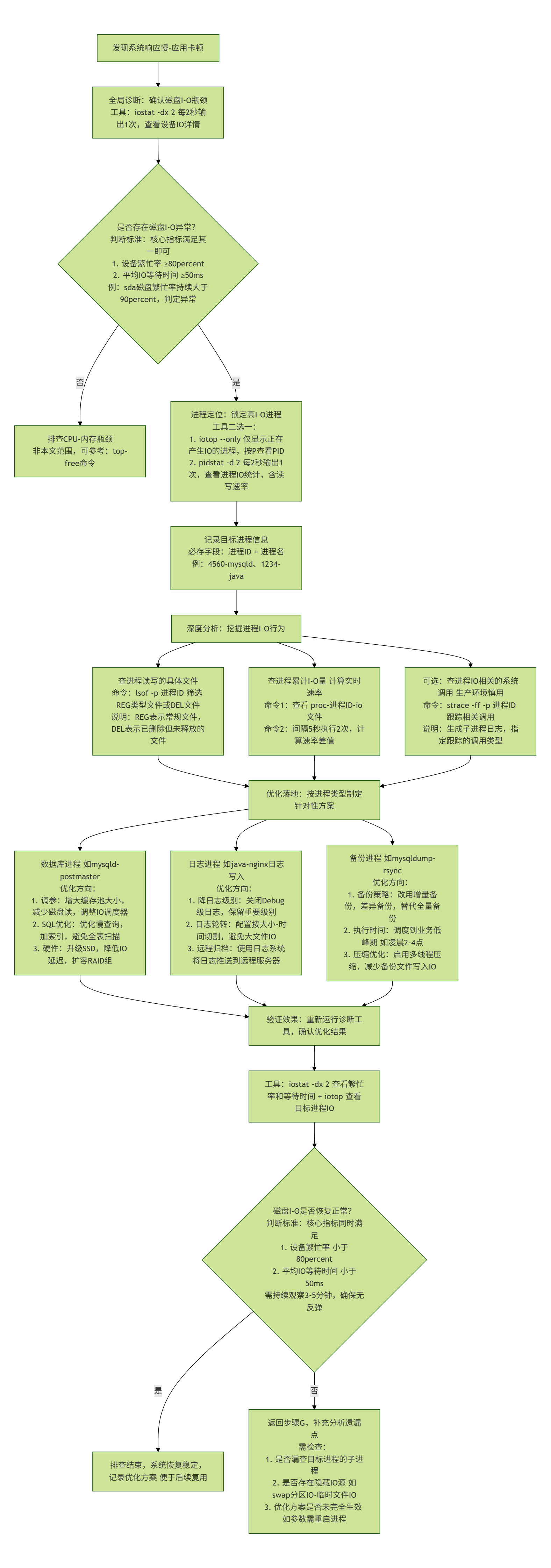
通过上述流程,可标准化解决 Linux 磁盘 I/O 高占用问题。实际运维中需注意:优先使用 iostat、iotop 等低开销工具,避免在生产环境滥用 strace;优化方案需结合业务特性(如数据库不可中断,需选择低风险参数调整),确保稳定性优先。