1、什么是卷积神经网络?
卷积神经网络(CNN)作为多层感知机(MLP)的变体,其理论基础源于生物学家休博尔和维瑟尔对猫视觉皮层的研究。他们发现视觉皮层细胞具有复杂结构,对视觉输入空间的特定子区域表现出高度敏感性,这些子区域被定义为感受野。
1998年,纽约大学的Yann Lecun提出了CNN架构(LeNet-5),其本质属于多层感知机范畴。该网络取得突破性成功的关键在于采用了局部连接和权值共享机制:一方面大幅削减了权重参数数量,使网络优化过程更为高效;另一方面显著降低了模型复杂度,有效控制了过拟合风险。当处理图像类输入数据时,这些优势表现得尤为突出。
2006年,Hinton开创了深度学习领域,其核心观点认为:包含多个隐藏层的人工神经网络具备卓越的特征提取能力,所学习到的特征能更准确地反映数据内在本质,为可视化和分类任务提供有力支持。随着大数据时代的到来和计算机硬件技术的飞速进步,深度学习得到了广泛推广和实际应用。
2012年,AlexNet在ImageNet图像分类竞赛中夺冠,标志着卷积神经网络进入爆发式发展阶段。现代CNN已成为一种具备卷积结构的深度神经网络模型,其卷积设计显著降低了深层网络的内存消耗。通过局部感受野、权值共享和池化层三大核心操作,CNN有效减少了网络参数总量,显著缓解了模型的过拟合问题,为深度学习在计算机视觉等领域的应用奠定了坚实基础。
2、CNN与常规神经网络(全连接网络)的关键区别
| 特性 | 常规神经网络 | 卷积神经网络(CNN) |
|---|---|---|
| 连接方式 | 全连接:每个神经元与前一层的所有神经元连接 | 局部连接:神经元仅连接输入的局部区域 |
| 参数共享 | 无参数共享:每个连接有独立权重 | 权值共享:同一卷积核在输入上共享权重 |
| 参数数量 | 巨大:随输入维度指数增长 | 稀疏:与输入大小无关,仅取决于卷积核尺寸和数量 |
| 空间信息处理 | 需展平输入:破坏空间结构 | 直接处理:保留空间关系 |
| 特征提取能力 | 全局特征:难以捕捉局部模式 | 局部到全局:层次化特征学习 |
| 平移不变性 | 无:输入平移导致输出完全变化 | 有:通过卷积和池化实现 |
| 计算效率 | 低:高维输入时计算量巨大 | 高:局部连接和权值共享大幅减少计算量 |
| 适用数据类型 | 结构化数据(表格、向量) | 网格结构数据(图像、视频、音频) |
3、CNN的组件结构
3.1 通过局部感受野进行特征提取
以图像识别为例,说明为什么CNN相较于传统神经网络效果更好。
如果采用经典的神经网络模型,则需要读取整幅图像作为神经网络模型的输入(即全连接的方式),当图像的尺寸越大时,其连接的参数将变得很多,从而导致计算量非常大。 而我们人类对外界的认知一般是从局部到全局,先对局部有感知的认识,再逐步对全体有认知,这是人类的认识模式。在图像中的空间联系也是类似,局部范围内的像素之间联系较为紧密,而距离较远的像素则相关性较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。这种模式就是卷积神经网络中降低参数数目的重要神器:局部感受野。
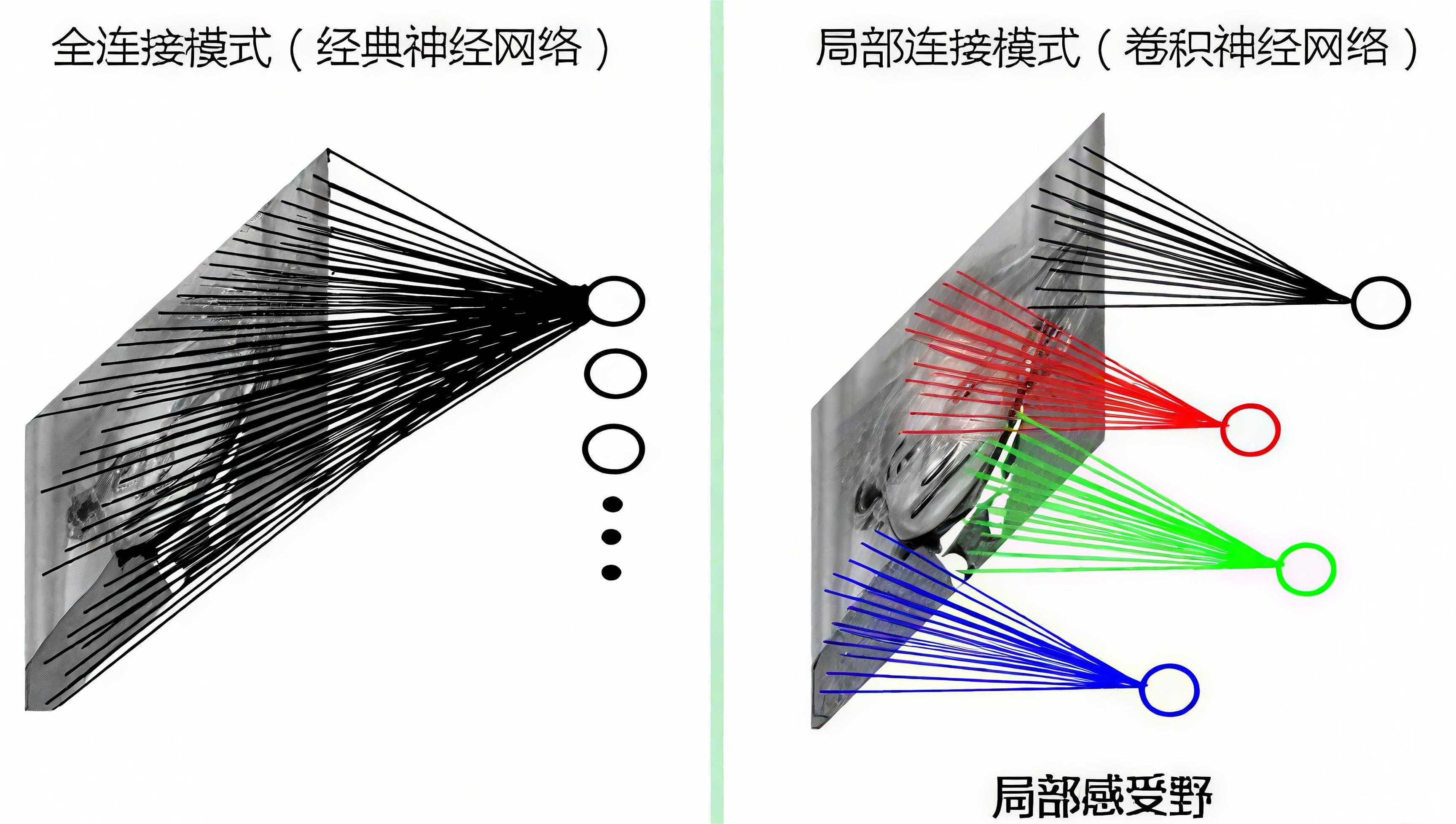
如果字母 X、字母 O 是固定不变的,那么最简单的方式就是图像之间的像素一一比对就行,但在现实生活中,字体都有着各个形态上的变化(例如手写文字识别),例如平移(translation)、缩放(scaling)、旋转(rotation)、微变形(weight)等等,如下图所示:
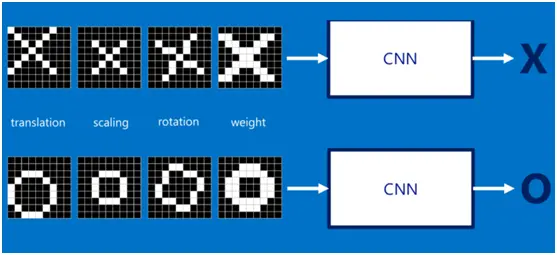
我们的目标是对于各种形态变化的 X 和 O,都能通过 CNN 准确地识别出来,这就涉及到应该如何有效地提取特征,作为识别的关键因子。 回想前面讲到的 “局部感受野” 模式,对于 CNN 来说,它是一小块一小块地来进行比对,在两幅图像中大致相同的位置找到一些粗糙的特征(小块图像)进行匹配,相比起传统的整幅图逐一比对的方式,CNN 的这种小块匹配方式能够更好的比较两幅图像之间的相似性。如下图:
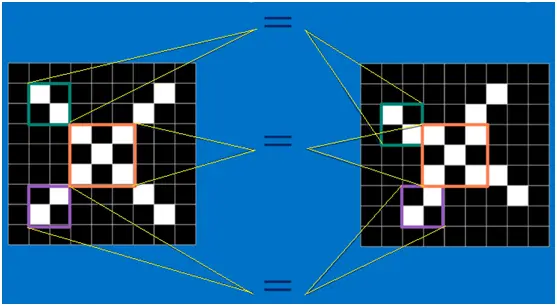
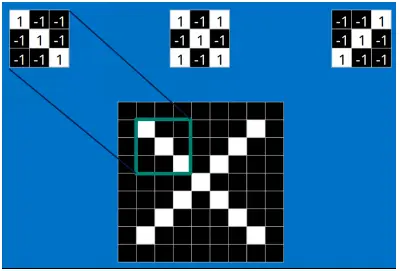
以字母 X 为例,可以提取出三个重要特征(两个交叉线、一个对角线),如下图所示:
| 图1 | 图2 | 图3 |
|---|---|---|
 |
 |
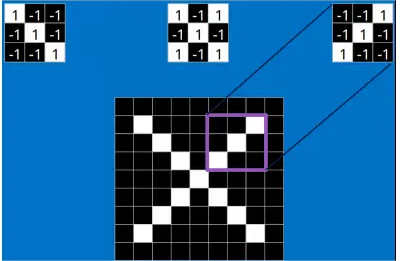 |
假如以像素值 "1" 代表白色,像素值 "-1" 代表黑色,则字母 X 的三个重要特征如下:

3.2 通过卷积计算进行特征提取后的匹配
当给定一张新图时,CNN 并不能准确地知道这些特征到底要匹配原图的哪些部分,所以它会在原图中把每一个可能的位置都进行尝试,相当于把这个 feature(特征)变成了一个过滤器。这个用来匹配的过程就被称为卷积操作,这也是卷积神经网络名字的由来。
如果读者还不了解卷积计算,可以参考以下文章:【卷积神经网络详解与实例】2——卷积计算详解_卷积神经网络的卷积怎么计算的-CSDN博客![]() https://blog.csdn.net/colus_SEU/article/details/150657893?spm=1001.2014.3001.5501
https://blog.csdn.net/colus_SEU/article/details/150657893?spm=1001.2014.3001.5501
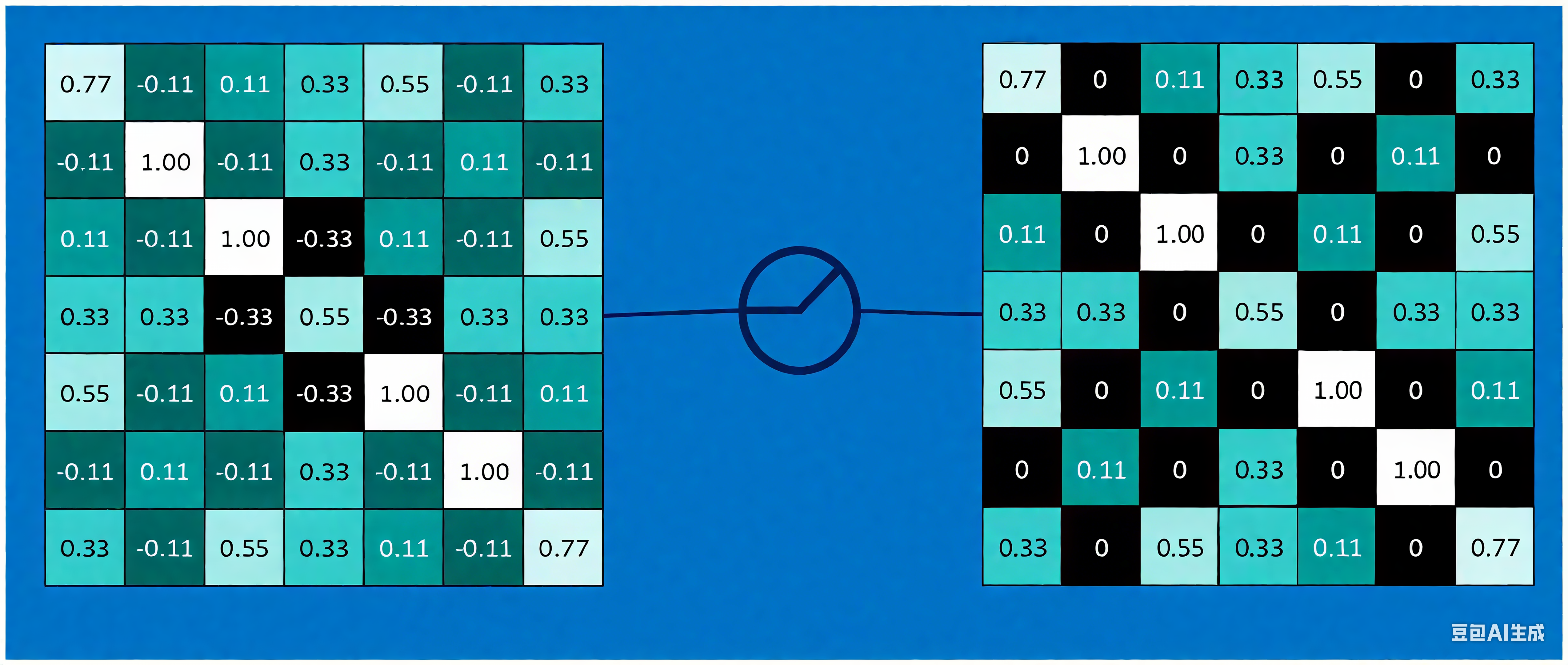
使用上三个特征(卷积核)对原图进行卷积(这里每个结果最后都除以小块内像素点总个数,即进行归一化,当然也可不除以总个数的),第一个特征的卷积结果如下:

通过每一个 feature(特征)的卷积操作,会得到一个新的二维数组,称之为 feature map。其中的值,越接近 1 表示对应位置和 feature 的匹配越完整,越是接近 - 1,表示对应位置和 feature 的反面匹配越完整,而值接近 0 的表示对应位置没有任何匹配或者说没有什么关联。
3.3 通过激活函数引入非线性因素
在卷积神经网络中,激活函数一般使用 ReLU (The Rectified Linear Unit,修正线性单元),它的特点是收敛快,求梯度简单。计算公式也很简单,,即对于输入的负值,输出全为 0,对于正值,则原样输出。第一个特征卷积计算后经激活函数:
3.4 通过池化进行信息压缩,减少参数
为了有效地减少计算量,CNN 使用的另一个有效的工具被称为 “池化 (Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化方法详细介绍:
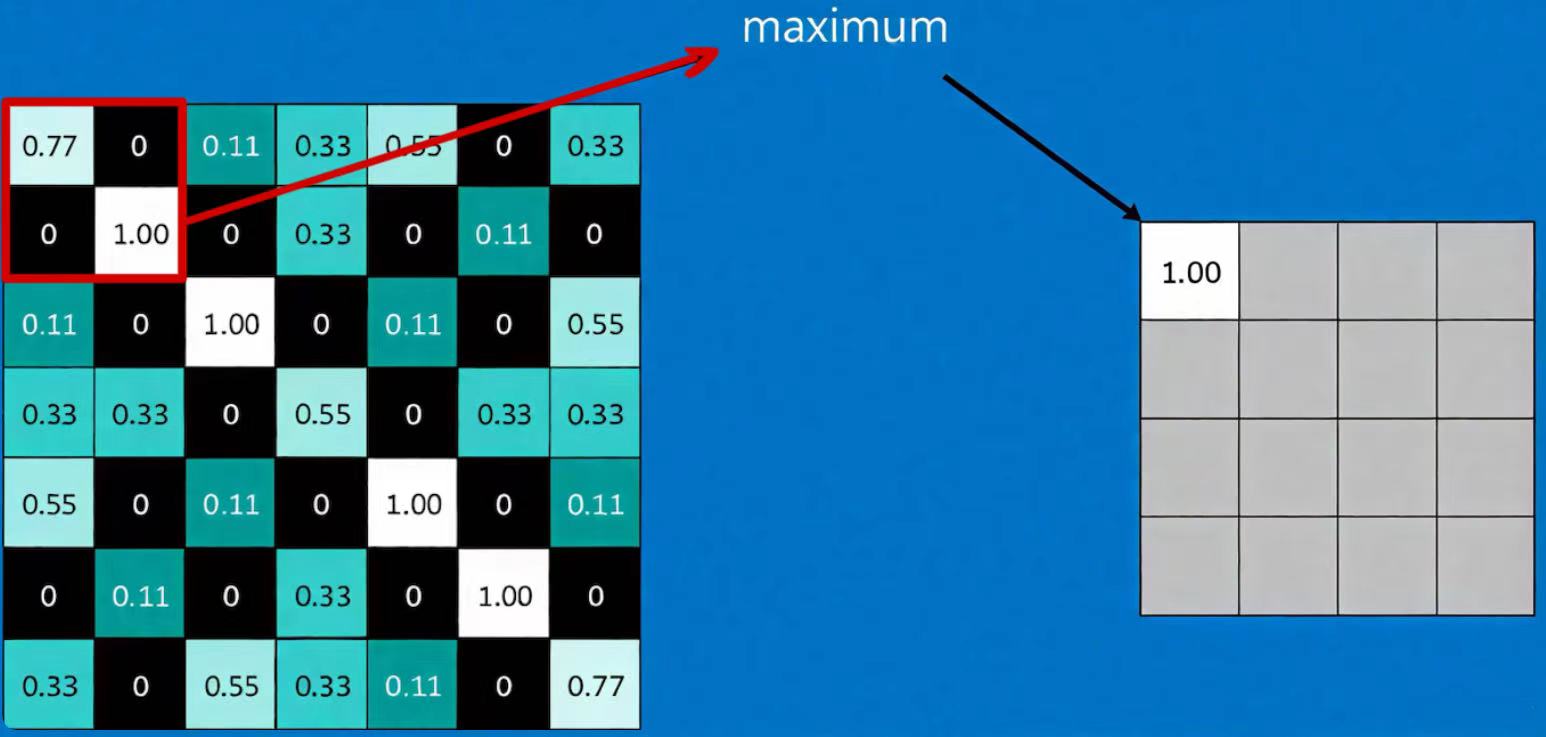
【卷积神经网络详解与实例】3——池化与反池化操作-CSDN博客![]() https://blog.csdn.net/colus_SEU/article/details/151370006?spm=1001.2014.3001.5501最大值池化的计算方法如下(取池化区域为 2*2 大小):
https://blog.csdn.net/colus_SEU/article/details/151370006?spm=1001.2014.3001.5501最大值池化的计算方法如下(取池化区域为 2*2 大小):
则第一个特征的整个池化结果为:

最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近 1 表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。 通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
3.5 深度神经网络
通过将上面所提到的卷积、激活函数、池化组合在一起,再通过加大网络的深度,增加更多的层,就得到了深度神经网络,如下图:

(图中结果不一定对,网络架构并不是经典LeNet或AlexNet架构,只是作为一个例子用于解释)
3.6 全连接层
全连接层在整个卷积神经网络中起 “分类器” 的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示:
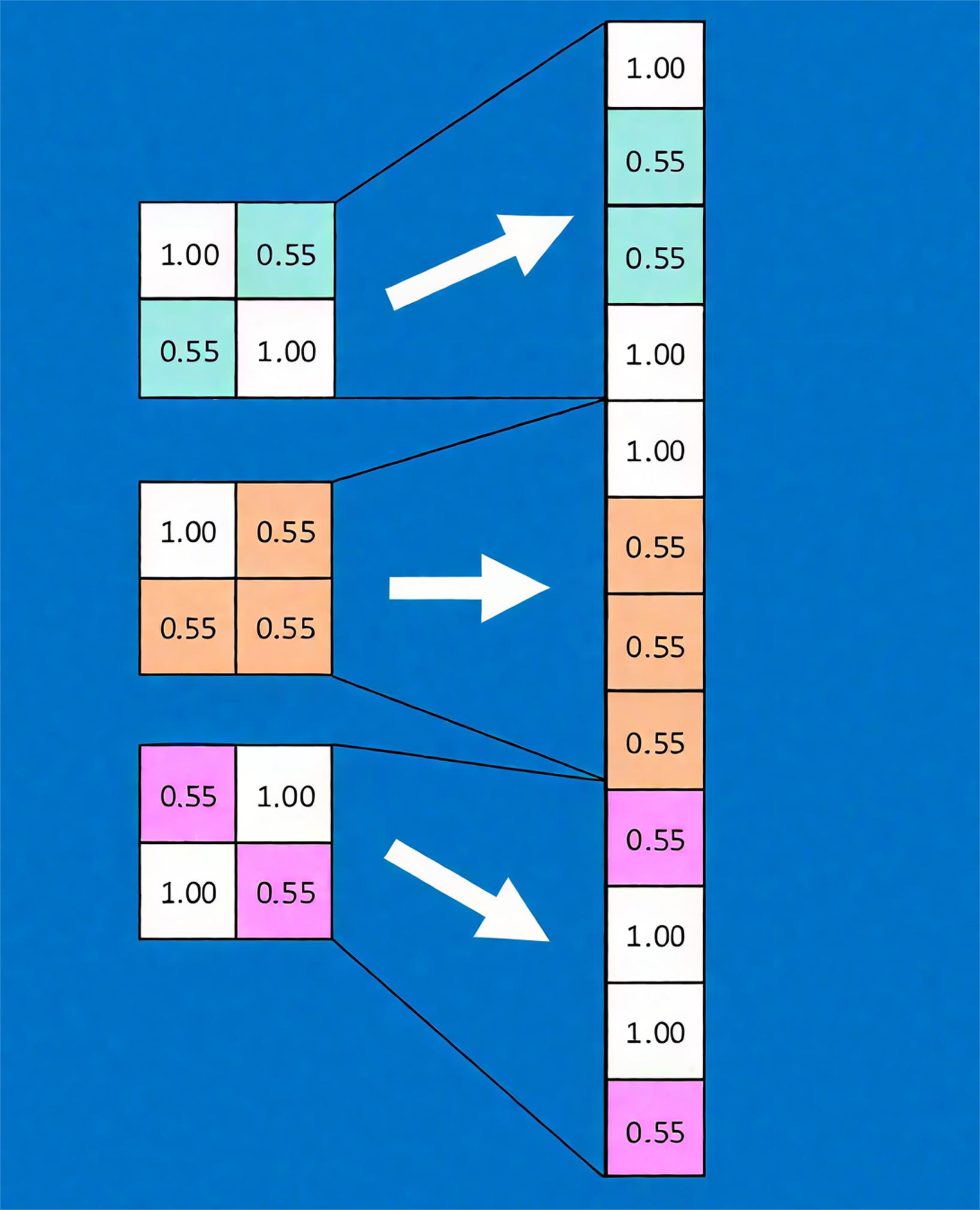
神经网络属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(如预测字母 X 的所有连接的权重)
在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果。
上述这个过程定义的操作为” 全连接层 “(Fully connected layers),全连接层也可以有多个。
将以上所有结果串起来后,就形成了一个 “卷积神经网络”(CNN)结构,如下图所示:
