前言:
随着企业数字化转型的深入,系统稳定性已成为业务连续性的重要保障。传统监控工具往往存在配置复杂、扩展性差等问题。Prometheus作为云原生时代的主流监控解决方案,以其强大的数据采集能力和灵活的查询语言获得广泛认可。结合Grafana的优秀可视化功能,可以构建出一套功能完善、易于维护的监控体系。本文将从实战角度出发,系统讲解监控系统各组件的部署配置流程,帮助读者快速掌握企业级监控系统的搭建技能。
目录
1.1 监控系统组件概述
Prometheus核心功能:负责采集和存储时序数据,通过exporter监控Linux、MySQL等目标。
Node Exporter作用:暴露主机级硬件和操作系统指标(如CPU、内存、磁盘),默认端口9100。
Grafana定位:可视化平台,通过导入仪表板模板展示Prometheus收集的数据,默认端口3000。
组件关系:Node Exporter采集数据 → Prometheus拉取数据 → Grafana可视化展示。
1.2 Prometheus部署流程
安装步骤:
解压安装包:
tar xf prometheus-*.tar.gz移动至系统目录:
mv prometheus-* /usr/local/prom创建软链接:
ln -s /usr/local/prom/prometheus /usr/bin/启动服务(指定配置文件):
nohup /usr/local/prom/prometheus --config.file=/usr/local/prom/prometheus.yml &
关键配置文件解析:
默认监控目标:
prometheus.yml中定义job监控自身9090端口配置项说明:
scrape_configs: - job_name: 'prometheus' # 任务名称 static_configs: - targets: ['localhost:9090'] # 监控目标地址
1.3 Node Exporter配置
部署流程:
启动Node Exporter:
nohup ./node_exporter --web.listen-address :9100 &修改Prometheus配置,添加监控任务:
- job_name: 'node' static_configs: - targets: ['localhost:9100'] # Node Exporter地址重启Prometheus服务使配置生效。
指标验证方法:
访问Prometheus UI(9090端口)http://192.168.72.176:9090,查询
node_cpu_seconds_total验证数据采集
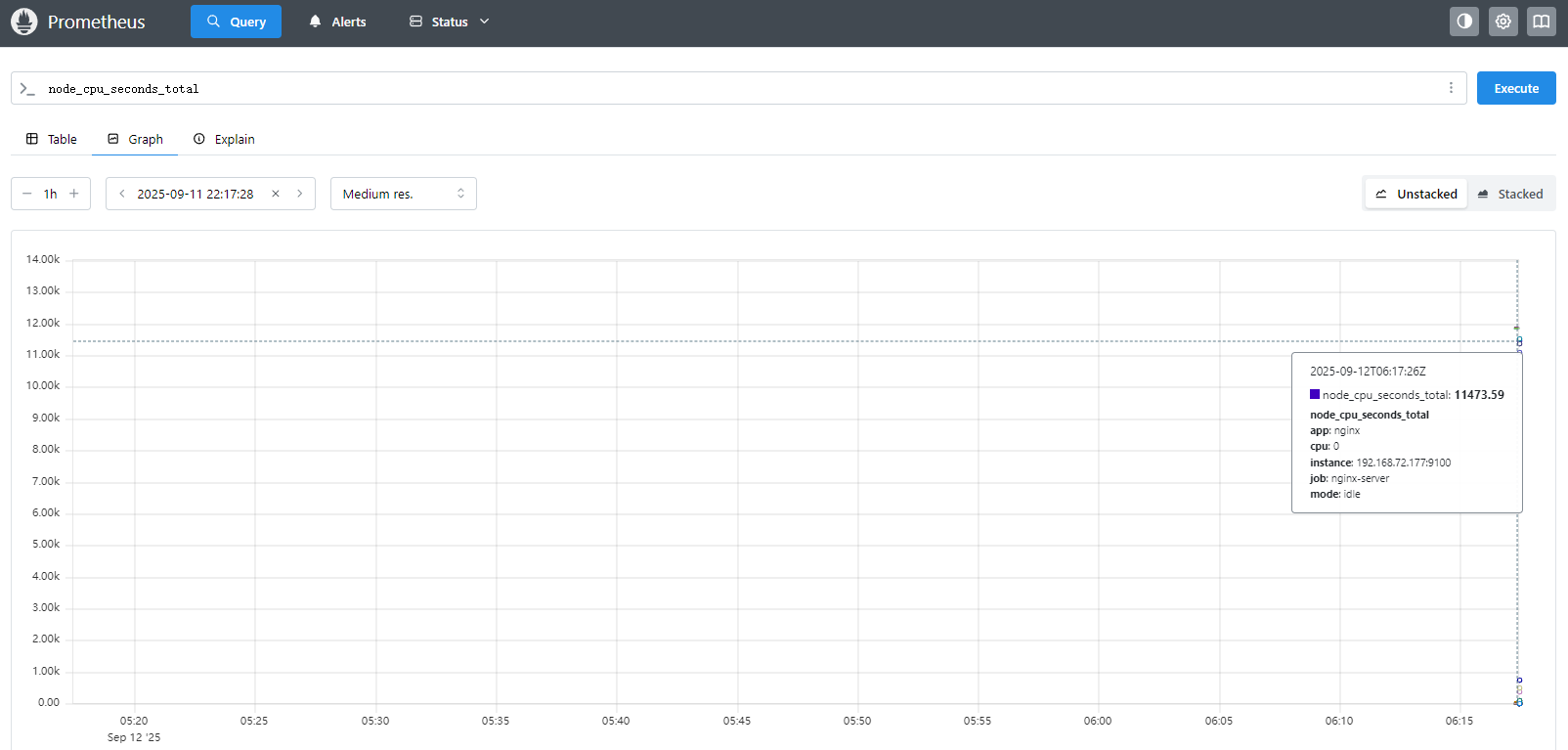
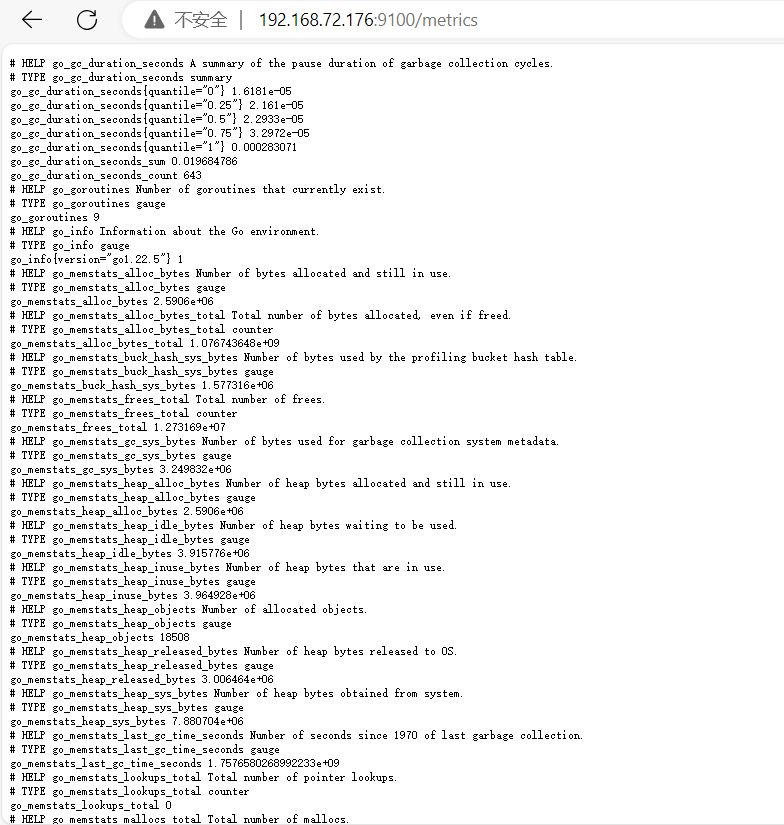
直接访问Node Exporter(9100端口)http://192.168.72.176:9100/metrics获取原始指标数据
1.4 Grafana安装与数据源配置
安装方式:
RPM包安装:
rpm -ivh grafana-*.rpm服务管理:
systemctl start grafana-server # 启动服务 systemctl enable grafana-server # 设置开机启动
初始化操作:
访问
http://<IP>:3000,初始账号密码admin/admin
汉化设置:
管理 → 通用 → 语言 → 选择中文
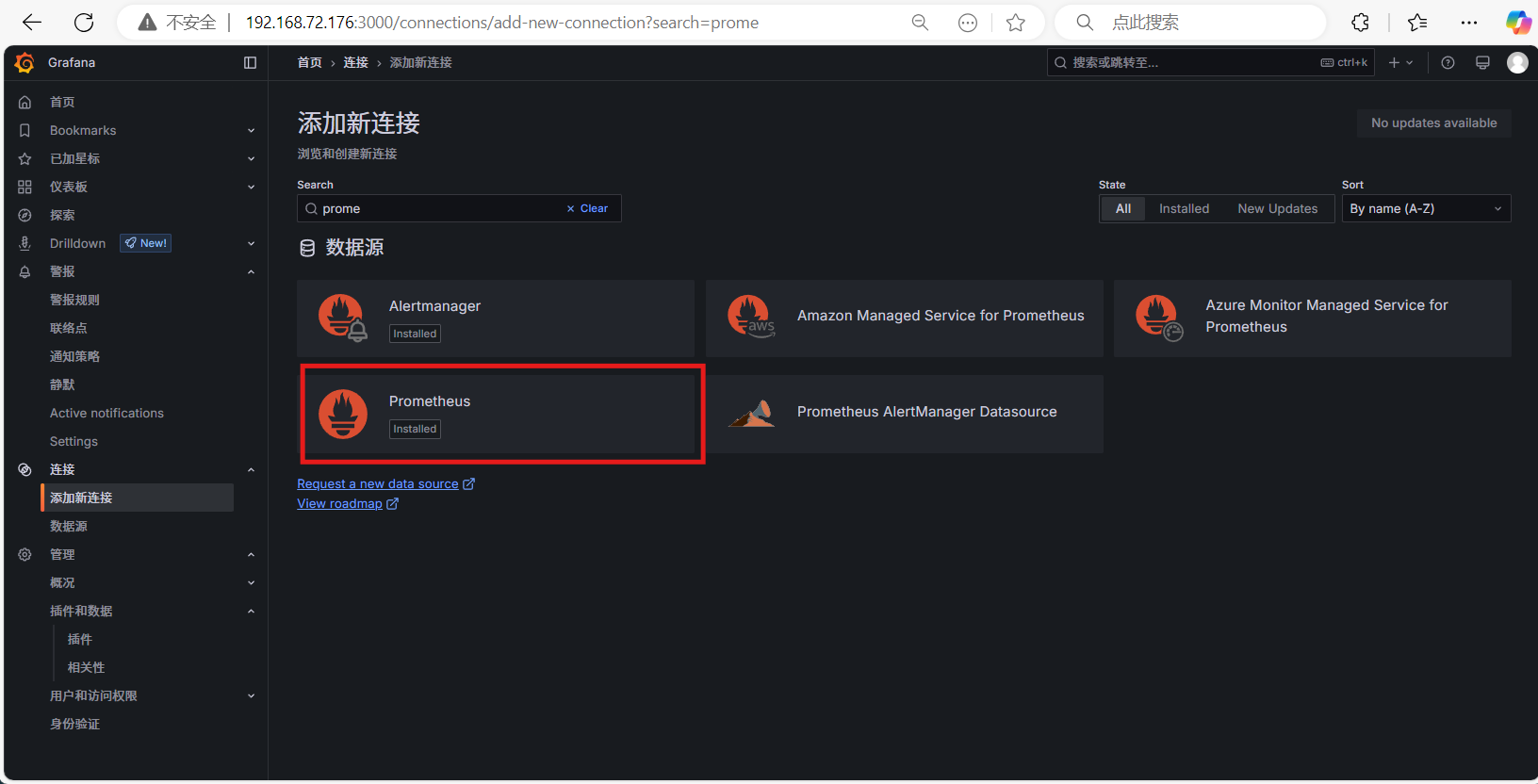
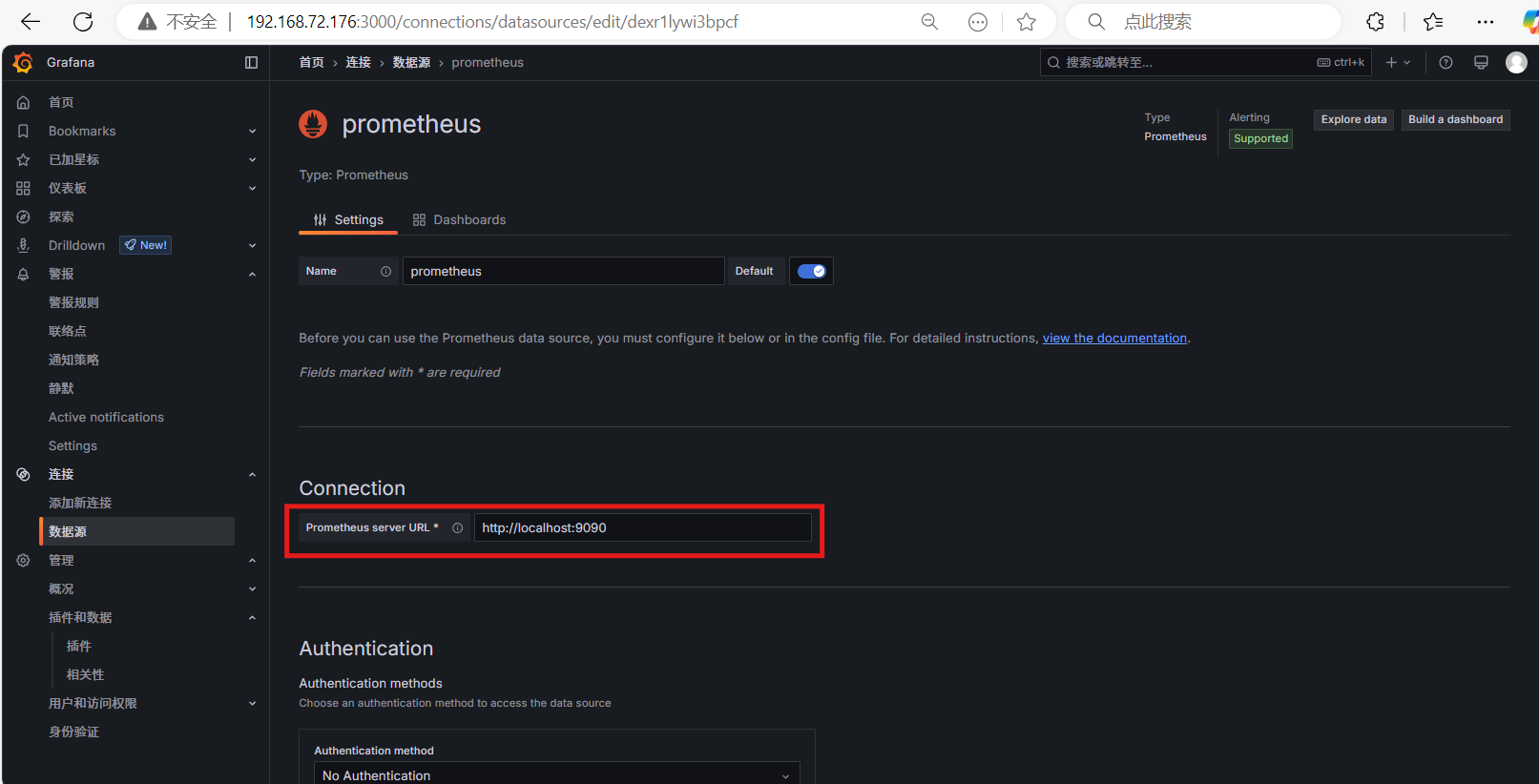
添加Prometheus数据源:
名称:
PrometheusURL:
http://localhost:9090保存并测试连通性
1.5 仪表板模板导入与管理
模板来源:
常用模板ID:
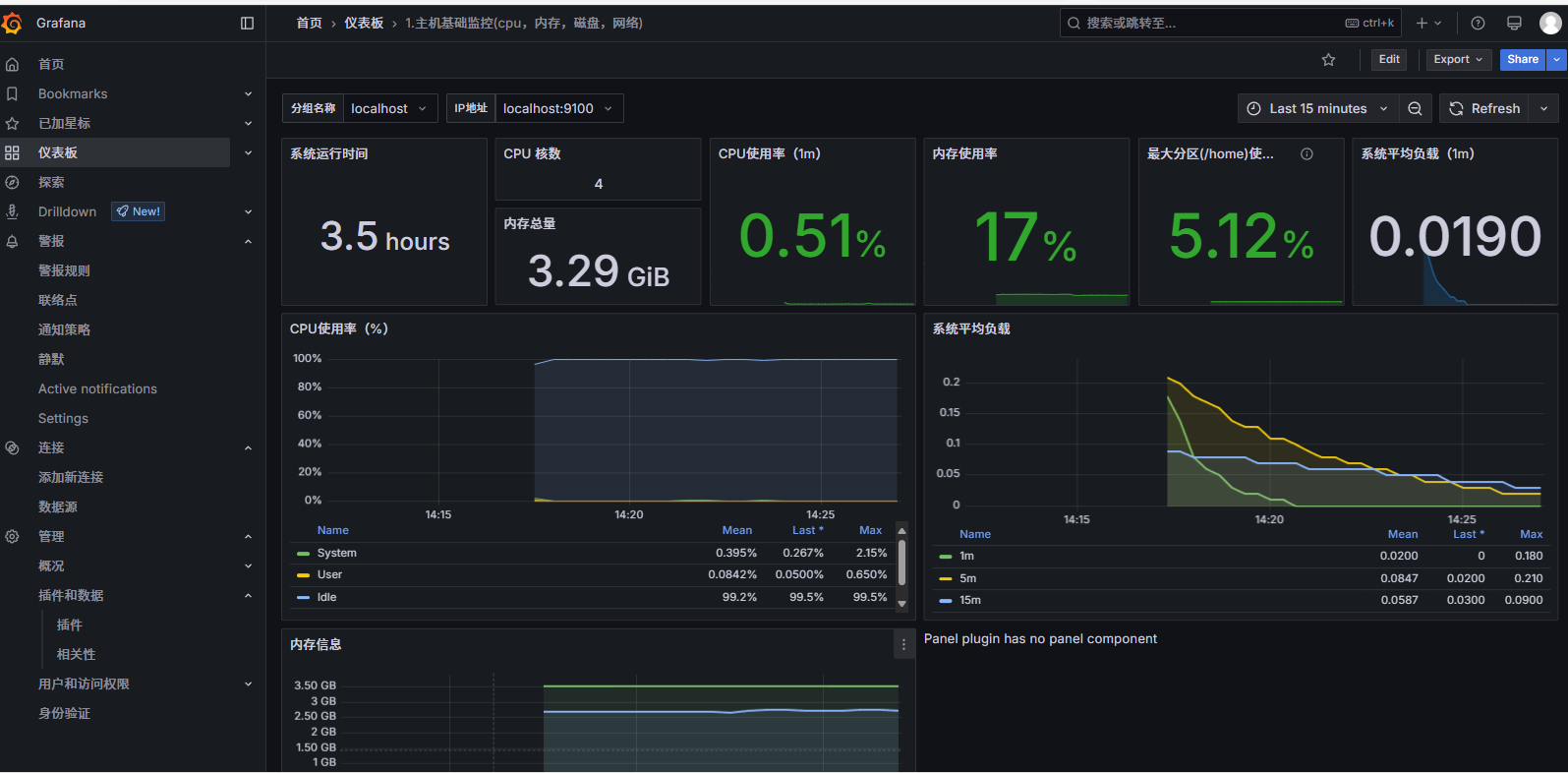
Linux主机监控:
1860MySQL监控:
7362
导入流程:
导航至"仪表板" → "导入" → 输入模板ID
选择数据源为已配置的Prometheus
命名仪表板并保存
模板问题处理:
数据未显示:检查数据源是否匹配,指标采集是否正常
面板报错:"Panel plugin not found":需安装对应插件如
grafana-piechart-panel
1.6 MySQL监控专项配置
部署mysql_exporter:
启动exporter:
./mysqld_exporter --config.my-cnf=./.my.cnf配置文件 .my.cnf内容:
[client] user=root password=your_password
Grafana配置要点:
导入MySQL专用仪表板(如ID
7362)验证指标:
查询
mysql_global_status_uptime确认运行时间检查
mysql_version_info获取版本信息
1.7 告警系统配置
Prometheus告警规则:
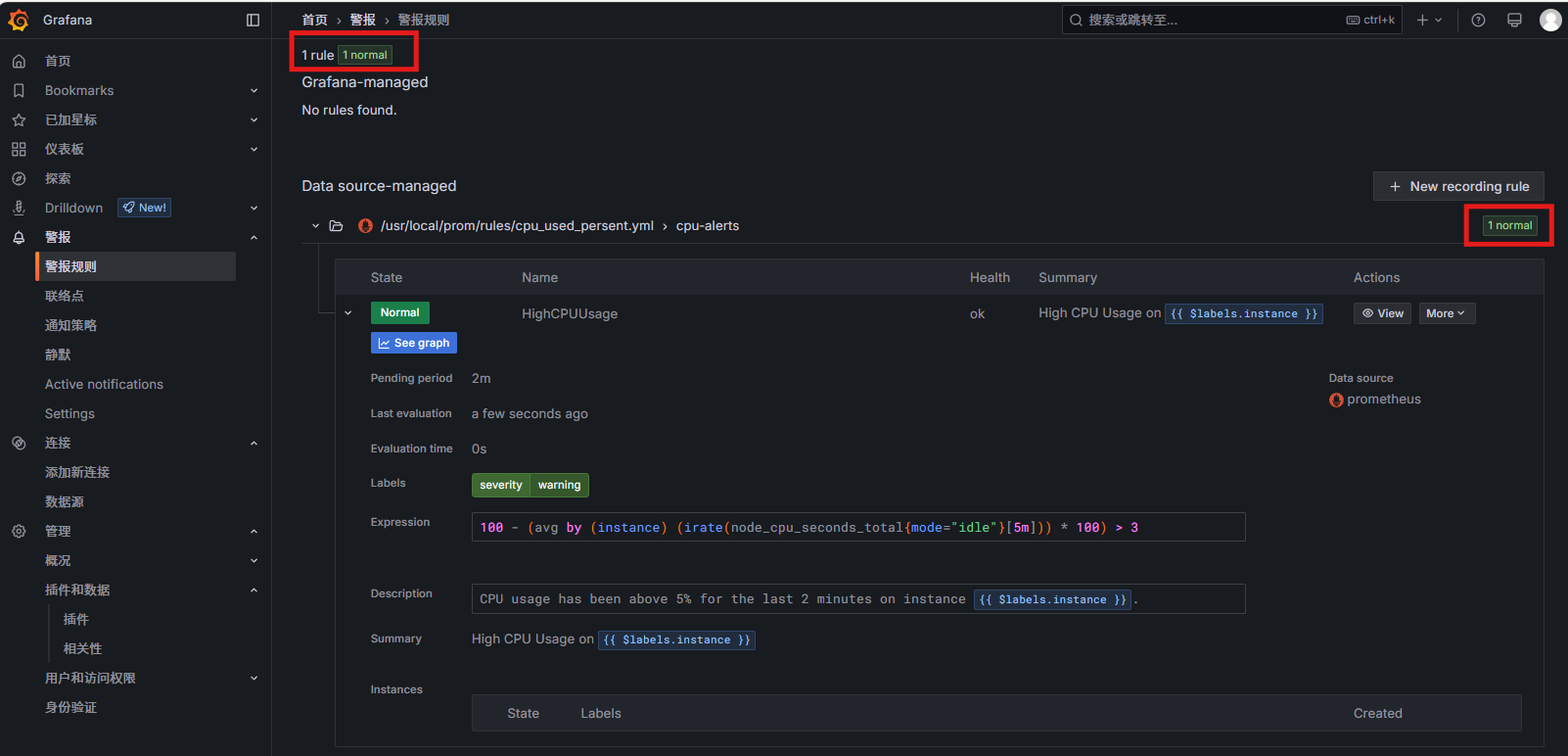
配置示例(CPU使用率告警):
groups: - name: cpu-alerts rules: - alert: HighCPUUsage expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 3 for: 2m labels: severity: warning annotations: summary: "High CPU Usage on {{ $labels.instance }}" description: "CPU usage has been above 5% for the last 2 minutes on instance {{ $labels.instance }}."
告警通道配置:
邮件告警修改prometheus.yml:
# Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - localhost:9093 # Alertmanager地址 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" - "/usr/local/prom/rules/*.yml" # 告警规则文件修改alertmanager.yml配置文件
[root@prometheus alert]# cat alertmanager.yml global: smtp_smarthost: 'smtp.gmail.com:587' smtp_from: 'your-alertmanager-email@gmail.com' smtp_auth_username: 'your-alertmanager-email@gmail.com' smtp_auth_password: 'your-email-password' smtp_require_tls: false route: group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 1h receiver: 'default' receivers: - name: 'default' email_configs: - to: 'user1@example.com,user2@example.com' send_resolved: true inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']启动Alertmanager:
nohup ./alertmanager --config.file=alertmanager.yml &
告警测试方法:
触发CPU负载:
while true; do echo test; done在Prometheus UI的"Alerts"页验证状态变为"Pending"→"Firing"
检查邮件接收情况(配置延迟约1-5分钟)
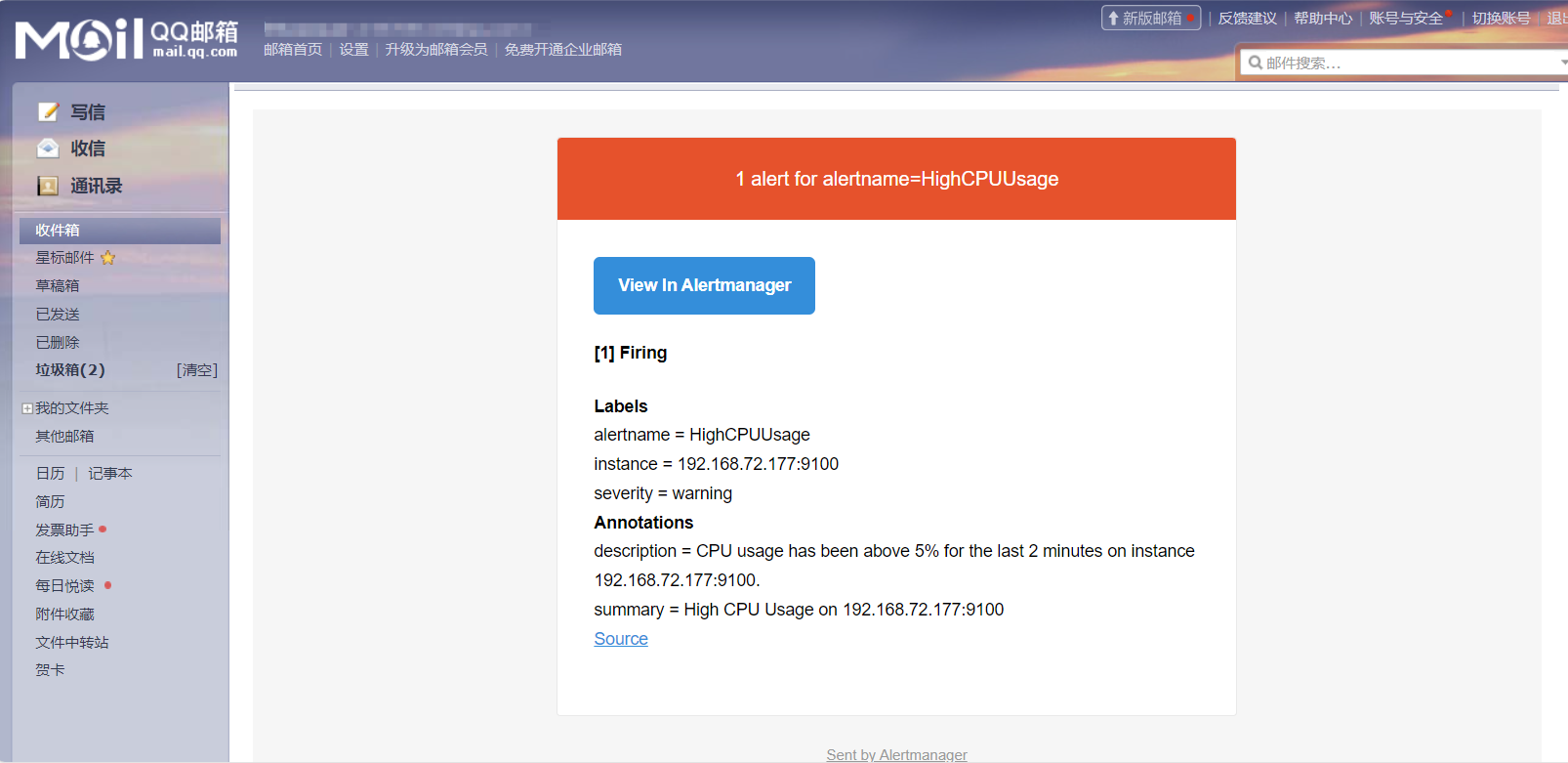
当CPU负载恢复正常后,会再发一封邮件(配置延迟5分钟左右)
1.8 故障排查与优化
常见问题处理:
| 现象 | 原因 | 解决方案 |
|---|---|---|
| Grafana面板无数据 | 数据源配置错误 | 检查Prometheus URL及端口 |
| "Panel plugin not found" | 缺少可视化插件 | 安装对应插件(如grafana-piechart-panel) |
| 告警邮件未发送 | SMTP配置错误 | 验证alertmanager.yml中邮箱参数 |
| 指标采集失败 | exporter未运行 | 检查Node/mysql_exporter进程状态 |
性能优化建议:
大规模集群部署独立Alertmanager,避免Grafana内置告警性能瓶颈
使用
irate()替代rate()处理高动态指标,避免峰值平滑模板开发规范:
指标命名遵循
exporter名_指标类型_单位(例:node_cpu_seconds_total)避免单仪表板加载过多面板(超过20个影响性能)
总结:
通过本文的完整实践指南,我们可以构建出一套涵盖数据采集、存储、展示和告警的完整监控体系。该方案具有以下优势:组件轻量易部署,支持多种数据源采集;Grafana提供丰富的可视化能力,支持模板化快速部署;Alertmanager实现灵活的告警路由和多种通知方式。在实际应用中,建议根据业务特点调整监控指标和告警阈值,并定期进行系统优化和故障演练。这套监控系统不仅能够及时发现系统异常,更能为性能优化和容量规划提供数据支撑,是企业运维体系中不可或缺的重要组成部分。