一.介绍
单机模式
这是 Hadoop 的默认部署模式,所有组件(如 HDFS、MapReduce 等)都运行在单个 JVM 进程里,直接读写本地文件系统,不涉及分布式通信。它部署简单,无需额外配置,适合新手入门学习 Hadoop 基本命令和进行简单的代码调试、轻量测试,但无法模拟分布式特性,不支持海量数据处理,无实际生产价值。
伪分布式模式
该模式是在单机上模拟分布式架构,所有 Hadoop 组件(如 NameNode、DataNode 等)以独立的 JVM 进程运行在同一台机器,且遵循分布式通信协议。需要进行 SSH 免密登录等配置,能模拟数据副本、节点通信等分布式特性,可用于开发测试分布式程序、熟悉 Hadoop 分布式流程,但仍受单机硬件资源限制,不能用于生产环境处理真实海量数据。
完全分布式模式
此模式是真正的分布式部署,Hadoop 各组件(如 NameNode、DataNode、ResourceManager 等)分别运行在多台不同的机器上,通过网络进行通信协作。需要对多台机器进行规划配置,如设置主从节点、配置节点间的通信和资源调度等。它能充分利用多台机器的硬件资源,支持海量数据的分布式存储与计算,具备高可靠性、可扩展性,是生产环境中处理大规模数据的标准部署方式。
二.单机模式
环境准备
操作系统:推荐 Linux(如 Ubuntu/CentOS)或 macOS(Windows 需通过 WSL 或虚拟机)
Java 环境:
安装 JDK 1.8+(Hadoop 3.x 需 Java 8 或 11)
卸载以前的包

# 查询已安装的 JDK 包
rpm -qa | grep 'java\|jdk\|gcj\|jre'# 卸载指定包(替换为实际查询结果)
yum -y remove java*
安装jdk
jdk-8u181-linux-x64.tar.gzhttps://www.oracle.com/cn/java/technologies/downloads/#license-lightbox
配置环境变量
sudo vi /etc/profile export JAVA_HOME=/opt/jdk1.8
#填写自己的jdk路径 export
PATH=$JAVA_HOME/bin:$PATH
环境生效
source /etc/profile
Hadoop 版本:选择稳定版本(如 Hadoop 3.3.6)
从 Apache 官网下载二进制包(以 Hadoop 3.3.6 为例):
wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
安装
# 解压到指定目录(例如 /opt/hadoop)
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/ mv /opt/hadoop-3.3.6 /opt/hadoop
# 配置环境变量(编辑 ~/.bashrc 或 ~/.zshrc)
export HADOOP_HOME=/opt/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使配置生效
source ~/.bashrc
查看
hadoop version

测试
准备输入文件
# 创建输入目录
mkdir -p ~/hadoop-input
# 写入测试文本
echo "Hello World Hello Hadoop" > ~/hadoop-input/test.txt
执行 WordCount
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar \ wordcount ~/hadoop-input ~/hadoop-output
查看结果
cat ~/hadoop-output/part-r-00000

二. 伪分布式模式
以下是 Hadoop 伪分布式模式(Pseudo-Distributed Mode)的环境搭建步骤。伪分布式模式下,Hadoop 的各个组件(如 HDFS、YARN、MapReduce)以独立进程运行,但所有服务均部署在单台机器上,模拟多节点集群的行为。这是学习和开发中最常用的模式。
环境准备
操作系统:Linux(如 Ubuntu/CentOS)或 macOS(Windows 需通过 WSL 或虚拟机)。
前置条件:
完成 Hadoop 单机模式 的安装(JDK 和 Hadoop 解压配置)。
配置 SSH 免密登录(用于启动 Hadoop 服务)。
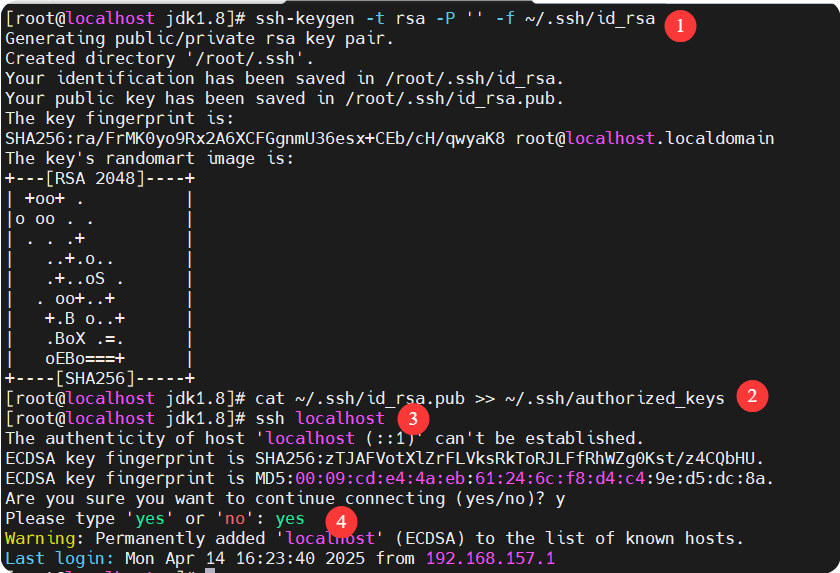
配置 SSH 免密登录
Hadoop 需要通过 SSH 启动本地进程
<
# 生成 SSH 密钥(如果已有密钥可跳过)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 将公钥添加到授权列表
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 测试免密登录本机
ssh localhost
# 输入 exit 退出