Redis线程模型
1 redis是单线程还是多线程
总的来说:redis是客户端多线程,服务端要分版本,redis4.X以前:单线程,之后的版本核心线程是单线程,其他也使用的多线程。
客户端
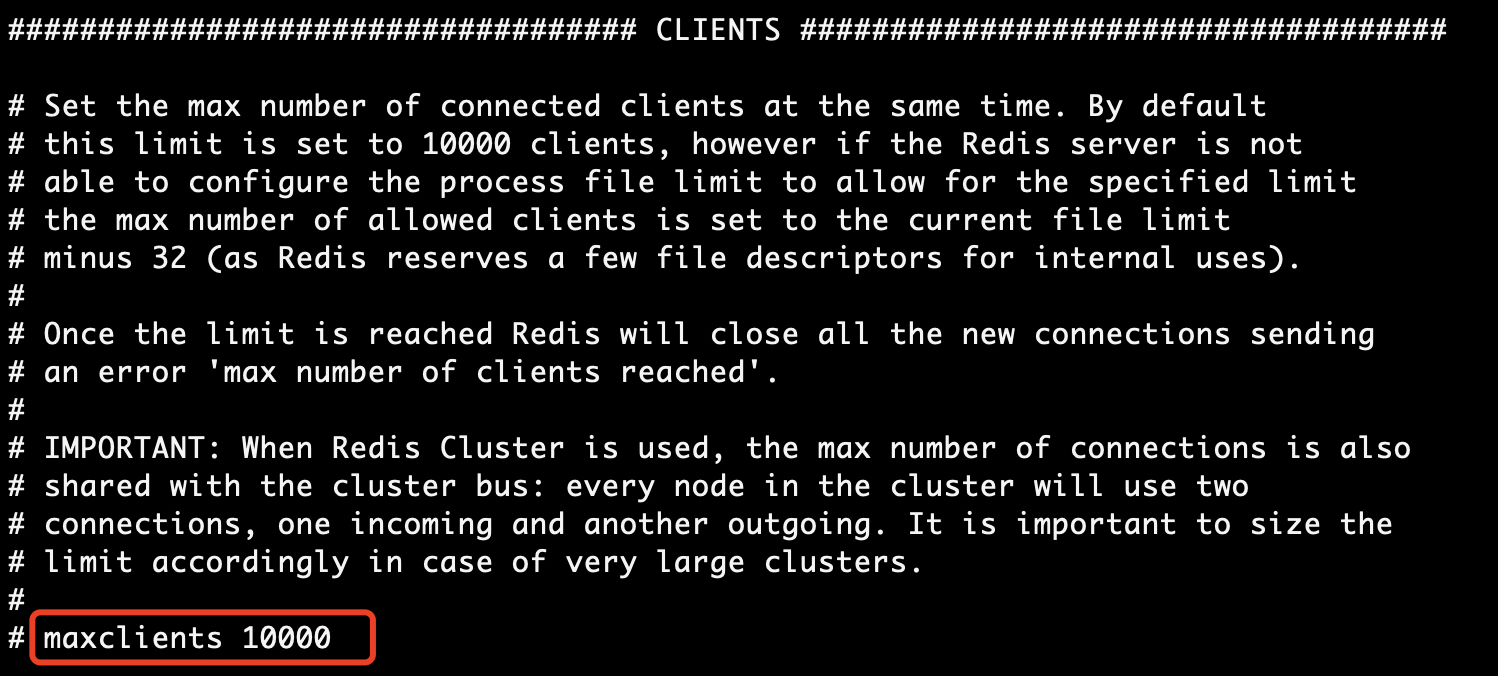
Redis为了实现服务端与更多的客户端进行连接,使用多线程来维护与客户端的socket连接。在redis.conf中的参数“maxclients” 就是设置最大连接客户端连接数的
服务端
在服务端,redis响应网络I/O和键值对读写的请求,是由一个单独的主线程来完成,Redis基于epoll实现了IO多路复用,用来满足一个主线程可以同时响应多个客户端的socket连接的请求。
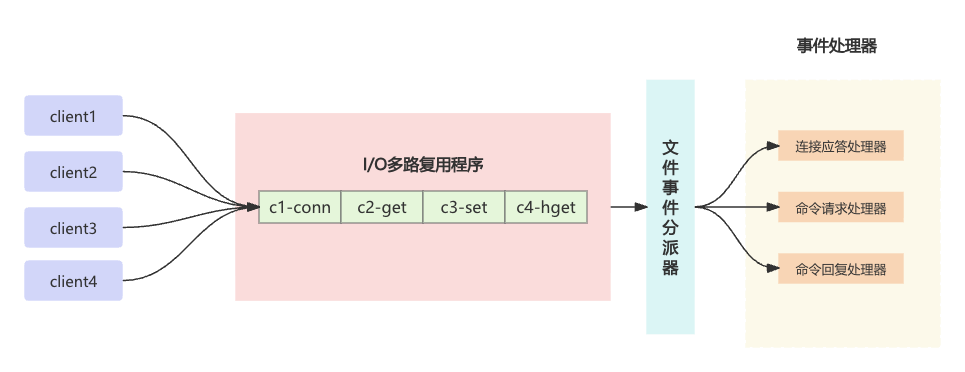
Redis将客户端多个并发的请求转成了串行的执行方式,这种串行化的线程模型,不仅规避了MySQL的脏读、幻读、不可重复读之类的并发问题, 而且加上Redis基于内存工作的极高性能,也让Redis成为很多并发问题的解决工具。
Redis4.X以前的版本,都是采用的纯单线程。之后的版本,加入了多线程,做了优化,核心的任务还是单线程执行,对于一些费时的,比如持久化RDB,AOF文件、unlink异步删除、集群数据同步等,都是由额外的线程执行的。对于 FLUSHALL操作,也提供了异步的方式。

问:为什么CPU早就多核了,Redis的核心线程模型却用单线呢?
答:Redis一直保持核心线程的单线程模型,其实是因为对于现代的Redis来说,CPU通常不会成为Redis的性能瓶颈。影响Redis的性能瓶颈大部分是内存和网络。因此,核心线程改为多线程的要求并不急切。另外,Redis的这种单线程为主的工作机制还可以减少线程上下文切换的性能消耗。而且,如果Redis将核心线程改为多线程并发执行,那么就必然带来资源竞争,反而会极大增加Redis的业务复杂性,影响Redis的业务执行效率。
2 Redis如何保证指令原子性
问题:
Redis是支持同时连接多个客户端,如果多个客户端同时进行读写请求,由于核心的读写键值的操作,Redis是单线程处理的,那多个请求同时过来就会排队,排队的顺序就可能会乱,针对单个客户端,Redis并没有类似MySQL的事务那样保证同一个客户端的操作原子性。那redis是如何保证指令原子性的呢?
2.1 Redis指令原子性的实现机制
2.1.1 复合指令
Redis内部提供了很多复合指令,一个指令可以执行多个操作, 比如 MSET(HMSET)、GETSET、SETNX、SETEX。这些复合指令都能很好的保持原子性。
2.1.2 Redis事务
Redis事务通过MULTI、EXEC、DISCARD和WATCH命令实现,允许将多个操作打包为一个原子单元执行。事务中的所有命令会按顺序执行,且不会被其他客户端命令打断。
# 丢弃事务
DISCARD (null)
# 执行事务中的所有命令。
EXEC (null)
# 开启事务
MULTI (null)
# 去掉监听
UNWATCH (null)
# 监听某一个key的变化。key有变化后,就执行当前事务
WATCH key [key ...]
事务的执行流程
- 开启事务:使用
MULTI命令标记事务开始,后续命令会进入队列而非立即执行。 - 命令入队:输入操作命令(如
SET、GET、INCR等),这些命令会按顺序存入队列。 - 执行或放弃:
EXEC:执行队列中的所有命令,返回各命令的结果。DISCARD:取消事务,清空命令队列。
事务的原子性特点
- 非严格原子性:Redis事务仅保证命令顺序执行,但单条命令失败不会回滚(与关系型数据库不同)。例如语法错误会导致整个事务失败,而运行时错误(如对字符串执行
INCR)仅影响当前命令。 - 无隔离级别:事务执行期间,其他客户端命令不会插入,但事务内操作的结果在
EXEC前不可见。
WATCH命令与乐观锁
WATCH用于监控一个或多个键,若这些键在EXEC前被其他客户端修改,则事务会失败(返回nil)。适用于需要检测数据变化的场景。
示例代码:
WATCH balance
MULTI
DECRBY balance 50
EXEC # 若balance被其他客户端修改,此处返回nil
2.1.3 Pipeline
Redis Pipeline 是一种客户端技术,用于将多个命令一次性发送到服务器并批量接收响应,减少网络往返时间(RTT),显著提升批量操作的性能。适用于需要执行大量命令的场景(如批量写入、读取)。
RTT: 当客户端执行一个指令,数据包需要通过网络从Client传到Server,然后再从Server返回到Client。这个中间的时间消耗,就称为RTT(Round Trip Time)。
Pipeline 的核心原理
- 传统模式:客户端发送一个命令后需等待服务器响应,再发送下一个命令,每次命令消耗一个 RTT。
- Pipeline 模式:客户端将多个命令打包一次性发送,服务器按顺序执行后批量返回结果,仅消耗一次 RTT。
非原子性:Pipeline 中的命令会被分批发送到服务器,但服务器可能在其他客户端命令间插入执行(需用
MULTI/EXEC实现原子性)。
错误处理:某条命令失败不会影响后续命令执行,需检查返回结果中的错误信息。
合理批量大小:避免单次 Pipeline 数据量过大导致网络阻塞或超时(建议分批发送)。
与事务(Transaction)的区别
- Pipeline:批量发送命令,无原子性保证。
- 事务(MULTI/EXEC):命令按顺序原子性执行,但会消耗更多 RTT(需配合 Pipeline 优化)。
适用场景
- 批量写入数据(如日志入库)。
- 批量读取多个键值(减少网络延迟)。
- 高频命令需低延迟(如计数器递增)。
2.1.4 lua脚本
Lua是一种轻量级、高效的脚本语言,比如参数类型、作用域、函数等,设计初衷为嵌入其他应用程序中扩展功能。
Redis中Lua脚本的作用
Redis从2.6版本开始支持Lua脚本,主要解决以下问题:
- 原子性操作:脚本内的多条Redis命令作为一个整体执行,避免竞态条件。
- 减少网络开销:合并多个操作为单个脚本,降低客户端与Redis的通信次数。
- 复杂逻辑封装:实现如分布式锁、限流等需多命令组合的功能。
Lua脚本在Redis中的基本用法
- 脚本执行命令
通过EVAL直接执行脚本,或使用SCRIPT LOAD预加载后以EVALSHA调用:
-- 直接执行示例
EVAL "return redis.call('GET', KEYS[1])" 1 mykey
-- 预加载脚本
SCRIPT LOAD "return redis.call('SET', KEYS[1], ARGV[1])"
EVALSHA "sha1哈希值" 1 key value
参数传递规则
- KEYS:键名列表,用于标识Redis中操作的数据。
- ARGV:额外参数列表,传递非键名数据。
- 必须明确指定KEYS的数量(如
EVAL script 2 key1 key2 arg1)。
脚本特性
- 原子性:脚本执行期间其他命令会被阻塞。
- 缓存机制:Redis缓存脚本的SHA1哈希,避免重复传输。
- 调试支持:通过
redis-cli --ldb可进行脚本调试。
应用场景
分布式锁 ,以下脚本实现锁的获取与释放:
-- 获取锁(SET if Not eXists)
local ok = redis.call('SETNX', KEYS[1], ARGV[1])
if ok == 1 then
redis.call('EXPIRE', KEYS[1], ARGV[2])
end
return ok
-- 释放锁(验证值匹配)
if redis.call('GET', KEYS[1]) == ARGV[1] then
return redis.call('DEL', KEYS[1])
else
return 0
end