算法原理及流程
关于RBF神经网络的细节详见:RBF神经网络学习及实践。
关于PSO算法的细节详见:粒子群优化算法(PSO)python实践。
PSO算法优化RBF神经网络训练流程图如下所示。

代码实现
代码直接使用文章RBF神经网络学习及实践和粒子群优化算法(PSO)python实践中的代码框架。
为了能在PSO类内部计算fitness,我们给PSO类初始化方法添加rbfn参数,方便调用rbfn进行训练和计算适应度(适应度直接采用均方误差)。
self.rbfn = rbfN
修改RBFN类中的训练测试函数,使之返回适应度。
def test(self):
G = self._calcAct(self.X)
Y_pre = np.dot(G, self.W)
# 计算整体均方误差
E = 0.5 * (np.linalg.norm(Y_pre - self.Y)) ** 2
return E
def predict(self, x):
G = self._calcAct(x)
Y_pre = np.dot(G, self.W)
return Y_pre
测试主函数
num_sample, num_center, sample_dim = 30, 3, 1
# 数据生成
x_train = np.linspace(-4, 4, num_sample).reshape(-1, 1)
y_train = np.multiply(1.1 * (1 - x_train + 2 * x_train ** 2), np.exp(-0.5 * x_train ** 2))
x_test = np.linspace(-4, 4, 500).reshape(-1, 1)
y_test = np.multiply(1.1 * (1 - x_test + 2 * x_test ** 2), np.exp(-0.5 * x_test ** 2))
# PSO-RBF
rbfn = RBFN(1, num_center, 1, x_train, y_train)
pso = PSO_RBFN(num_center * sample_dim, 30, 400, rbfN = rbfn)
pso.pso()
# print(pso.g_best)
rbfn.train(pso.g_best)
y_pre = rbfn.predict(x_test)
# 绘图
plt.figure(1)
plt.plot(x_test, y_pre, 'k')
plt.plot(x_test, y_test, 'r:')
plt.ylabel('y')
plt.xlabel('x')
for i in range(len(x_train)):
plt.plot(x_train[i], y_train[i], 'go', markerfacecolor = 'none')
plt.legend(labels = ['reconstruction', 'original', 'sample point'], loc = 'lower left')
plt.show()
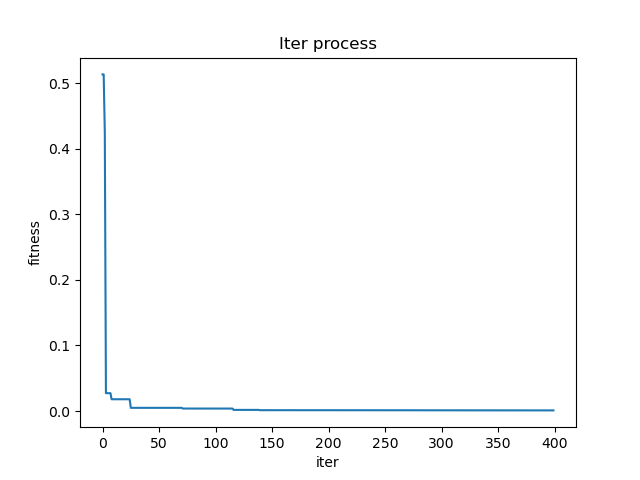
测试PSO适应度收敛曲线如下图所示。
PSO-RBFN毕竟结果如下。
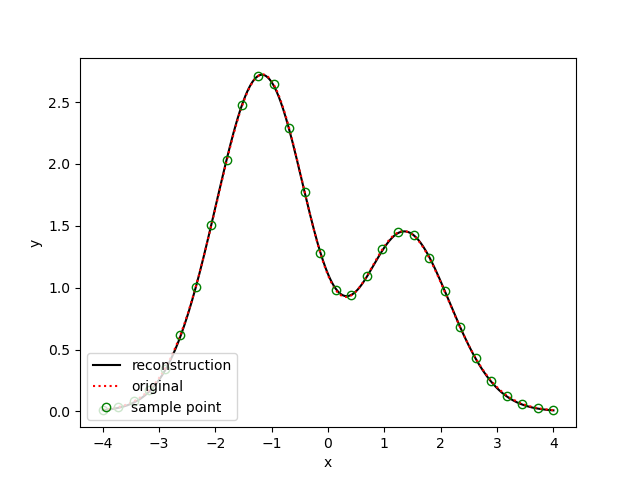
其中绿色空心圆点为样本数据,红色虚线为期望数据,黑色实线为预测数据。
结果分析与总结
PSO粒子与RBFN中心点
这两个概念我曾混淆,认为:PSO优化RBFN时,每个中心点都编码成一个粒子。但是随后又想,既然在PSO中需要频繁计算每个粒子的适应度,而RBFN的预测结果是由所有中心点共同线性加权决定的,所以这个想法不成立。实际上,我们引入PSO算法的目的在于更好地优化RBFN,使其找到最优的网络构建参数:隐层中心点、方差、输出层到结果的权值。只要隐层中心点确定,方差可以由如下公式计算得到:
σ = d max 2 n \sigma=\frac{d_{\max }}{\sqrt{2 n}} σ=2ndmax
这里 d max \mathrm{d}_{\max } dmax 是选取中心的之间的最大距离。权值也可以通过伪逆法求解得到。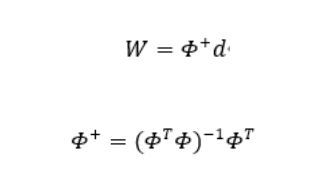
因此,我们只需找到构建RBFN的最优中心点即可,即粒子编码中包括基函数中心值。设有 m m m 个中心点,每个中心点为 k k k 维(中心点维度等于输入样本数据维度),那么,每个粒子的位置和速度均为 m × k m\times{k} m×k 维。
粒子位置限制和速度限制
对于粒子的位置限制,取决于输入样本的各个维度的取值域,如果是取值无约束,可注释掉位置限制相关代码。对于速度限制,一般取最大速度取维度位置变化范围的10%~20%,在测试代码中粒子速度范围限制在[-1,1]之间。
RBFN中心点个数确定和初始化
在测试代码中,对于RBFN中心点个数取3,且在 [ X m i n , X m a x ] [X_{min},X_{max}] [Xmin,Xmax] 中均匀随机初始化,这属于比较简单粗暴的了。正常来说,一般是使用聚类进行初始化。如指定中心点个数进行K-Means聚类得到聚类中心初始化中心点位置。但是K-Means算法的缺点是需要指定聚类中心个数,所以可以考虑采用减法聚类
Subtrative Clustering迭代得到一定数量的聚类中心点位置。样本数据归一化
对于样本数据的不同维度,其数据量纲、量纲单位、数量级存在差别,为防止计算饱和,需要对其进行归一化处理,以建立各类数据的可比性。
min-max标准化
min-max标准化最终将样本数据限定在[0,1]范围内,其转化函数为:
X = X − X m i n X m a x − X m i n X=\frac{X-X_{min}}{X_{max}-X_{min}} X=Xmax−XminX−Xmin
式中 X X X 为样本数据, X m a x X_{max} Xmax 为样本数据最大值, X m i n X_{min} Xmin 为最小值。z-score标准化
经过 z-score标准化处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
z = x − μ σ z=\frac{x-\mu}{\sigma} z=σx−μ
其中 μ \mu μ 为样本数据的均值, σ \sigma σ 为样本数据的标准差, x x x 为样本数据。
参考
[1] 庹婧艺,徐冰峰,徐悦,等. 基于PSO算法优化的RBF神经网络水厂混凝投药控制[J]. 工业安全与环保,2022,48(9):83-86. DOI:10.3969/j.issn.1001-425X.2022.09.020.