最近跟着学长一起做项目,需要用到yolo实现蜜蜂图像检测,网上找资料,最先在b站看到炮哥的yolov5,非常详细,成功实现yolov5目标检测。但是yolov5在蜜蜂(小目标)检测上并没有达到我们的预期,于是我们打算用yolov7实现蜜蜂图像检测。
网上找了很多yolov7教程,发现yolov7跟yolov5差别不大,我就跟着炮哥yolov5的教程自学了yolov7,并成功实现了密封图像检测,目前是299张数据集按照82比例划分正确率达到60%。
本文记录我自学yolov7的全过程,找数据集->筛选照片并重命名->labelimg打标签->voc转txt并按比例划分数据集->github下载yolov7模型和yolov7.pt参数文件->配置模型、数据yaml文件->修改train文件运行并通过tensorboard查看
一、前言
我用的学长的电脑,他的电脑已经配好了环境。
Anaconda3(虚拟环境pytorch37)+cuda11.1+torch1.8.1+torchvision0.9.1+python3.7.15
考虑到部分没有配置经验的朋友,下面简单说一下环境配置的步骤。
步骤主要是:查看cuda版本
(1)win+R,输入cmd,输入ncvv --version,查看cuda版本
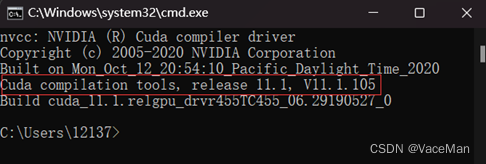
如上图,学长电脑的cuda是11.1
上网百度查找与cuda相匹配的pytorch版本,网页地址:PyTorch和CUDA版本对应关系 - 墨莲玦 - 博客园
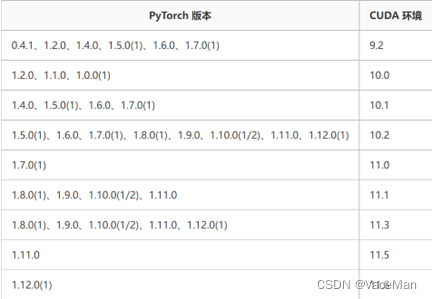
(2)这里选择与cuda11.1对应的pytorch1.8.1,然后再去找python、torch之间的对应关系。
地址:torch、torchvision、python、cuda 版本对应关系_来一碗锅巴洋芋的博客-CSDN博客_torch和cuda版本对应
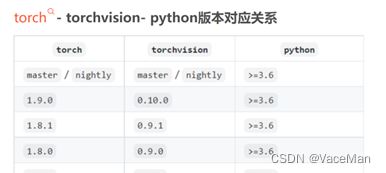
(3)最终确定配置torch1.8.1+torchvision0.9.1+python3.7的环境。
安装就很简单了,去pytorch官网找下载命令就可以了,然后到anaconda中指定python版本创建新的虚拟环境,激活虚拟环境然后下载pytorch就可以啦。(如果有需要,后面再单独补一期配置环境的博客)
二、找数据集+下载解压+创建项目文件夹+筛选所需图片并重命名
我都是在ai studio平台寻找公开的数据集,搜索关键字“蜜蜂”找到如下数据集,哪一个都可以。
点击上图箭头标出的进入到数据集详细界面,下拉点击“下载查看更多”就开始下载了。
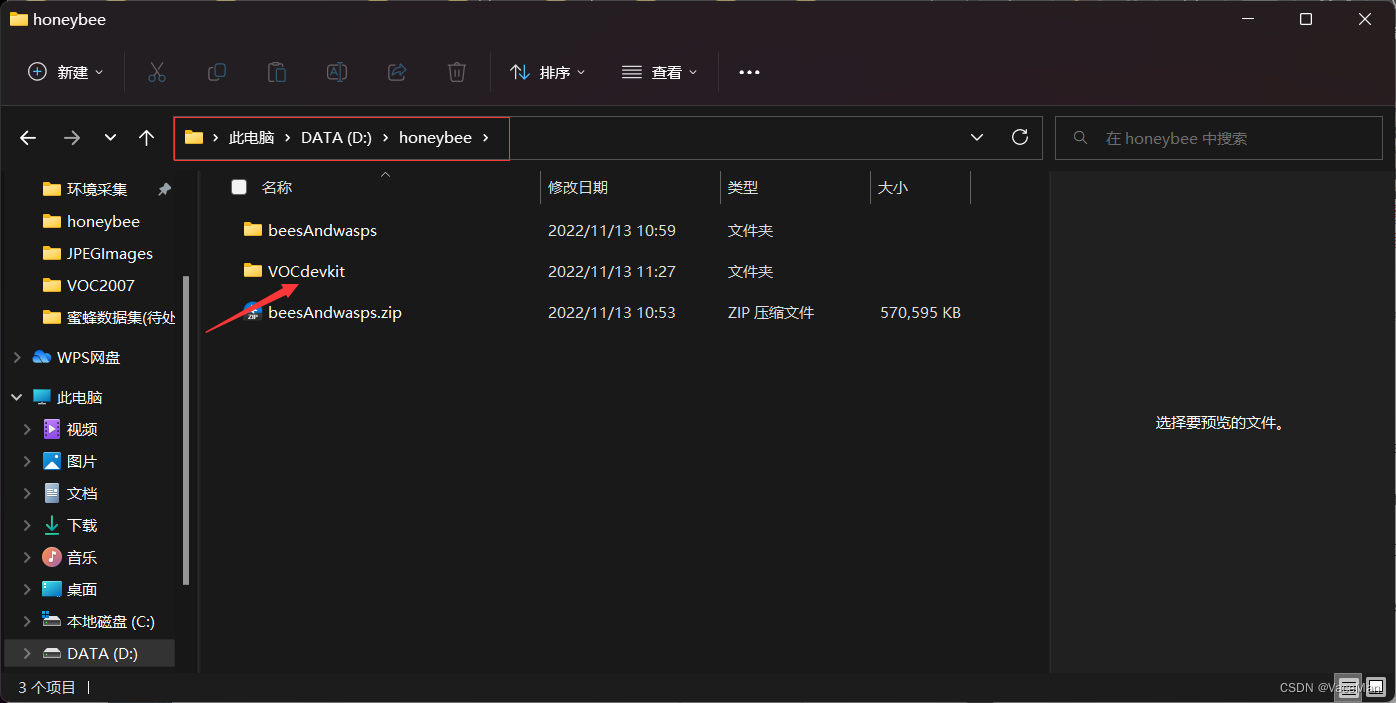
下载好后,我在D盘建了一个空文件夹,名为honeybee,存放我们要用到的数据集、yolov5等等。把下载好的压缩包放入到项目文件夹中,并解压。文件结构如下图所示。
我们查看解压后的数据集文件结构,如下图所示。
我们点击去看一看,选择我们需要的就可以啦。
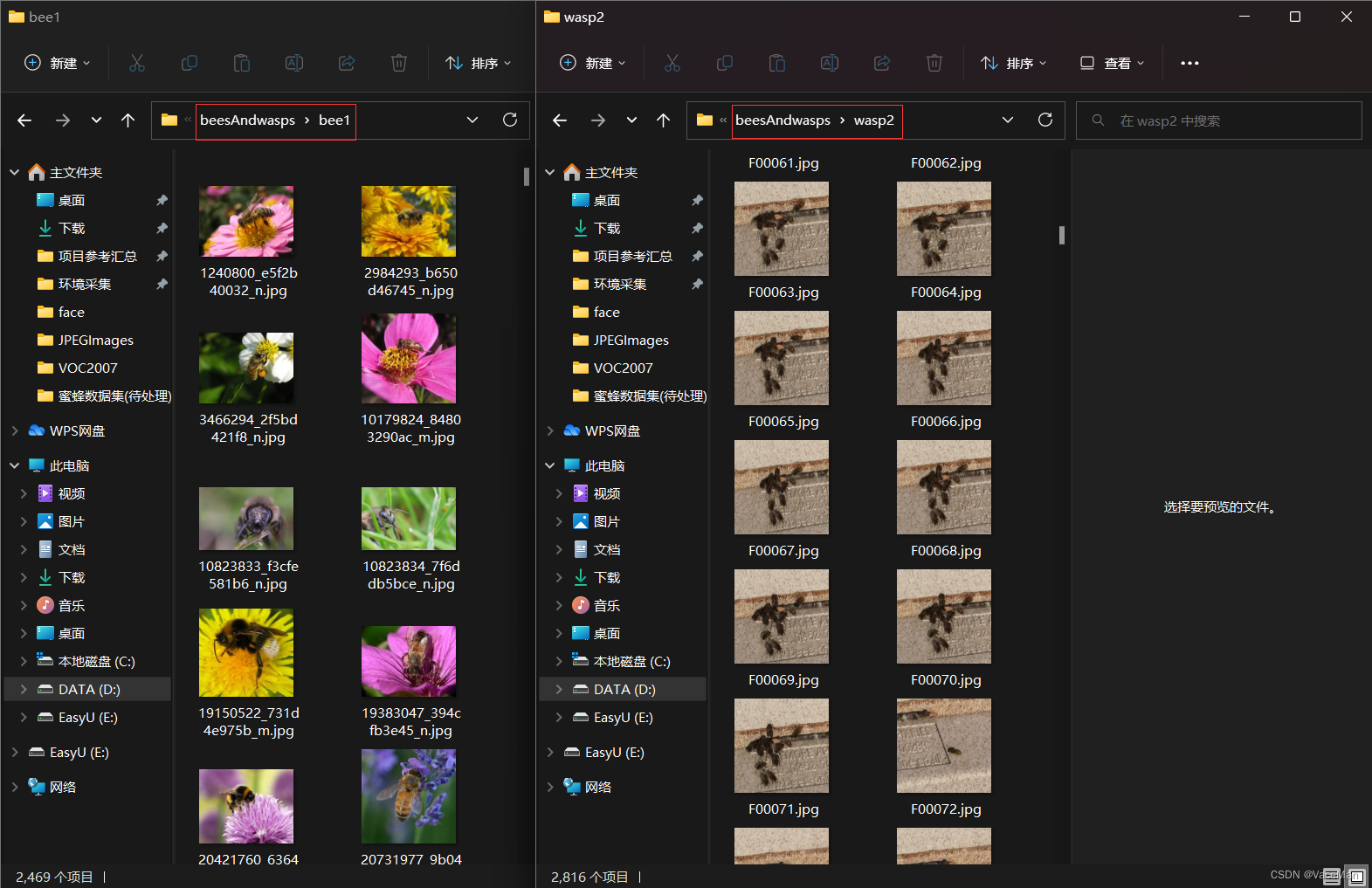
这里我最终选择的是bee1和wasp2。
简单说一下为什么选择这两个文件夹,bee1不同地方不同环境不同状态下的蜜蜂图片多,但是bee1只有单个蜜蜂;wasp2中有多个蜜蜂的照片。
然后在项目根文件夹创建如下结构的文件目录:
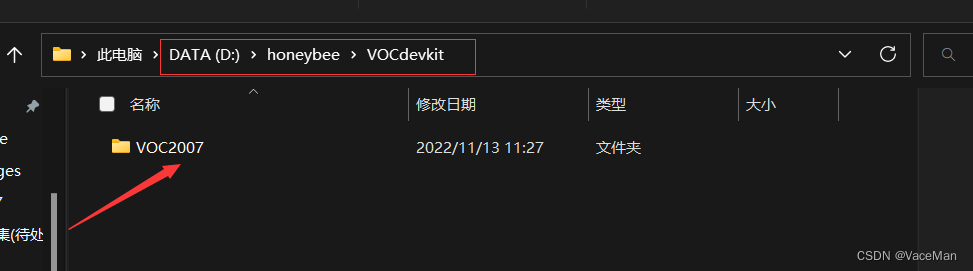
——VOCdevkit
————VOC2007
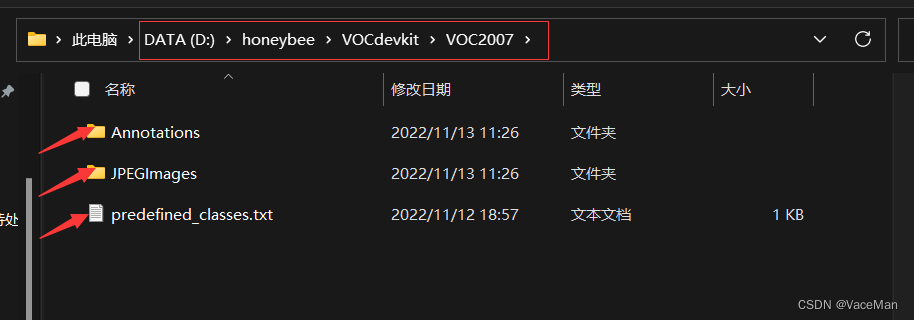
————————Annotations
————————JPEGImages
————————predefined_classes.txt
创建好后,我们把需要的图片放到JPEGImages文件夹中。
这里我没有选择太多,500张照片,其中包含几十张多蜜蜂的图片。
(左边是JPEGImages文件夹,右边是我们从网上下载解压后的数据集文件,把网上的剪切到我们的JPEGImages文件夹)
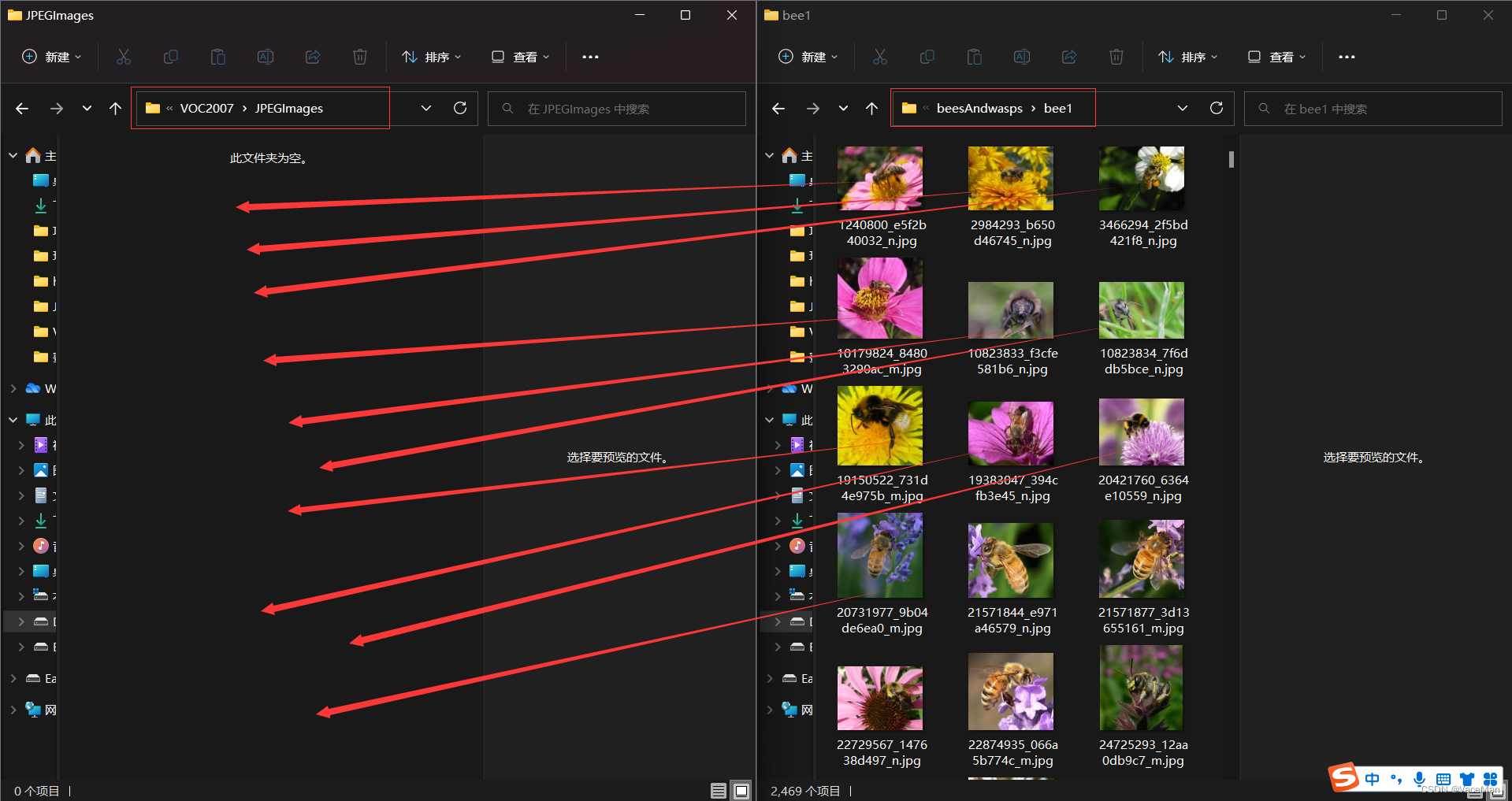
从bee1剪切了490张,然后再去swap2里面找10张包含多个蜜蜂的图片

最终,500张图片
然后,我们给它排序,从1到500
执行rename.py文件夹,修改好路径,执行就可以了。
rename.py是我写好的,文件重命名,我把rename.py放在项目根目录下。
rename.py代码如下:
import os
oldpath = os.listdir(r"D:\honeybee\VOCdevkit\VOC2007\JPEGImages")
path = r"D:\\honeybee\\VOCdevkit\\VOC2007\\JPEGImages\\"
for i in range(len(oldpath)):
oldimg = path + oldpath[i]
newimg = path + str(i+1)+".jpg"
os.rename(oldimg,newimg)
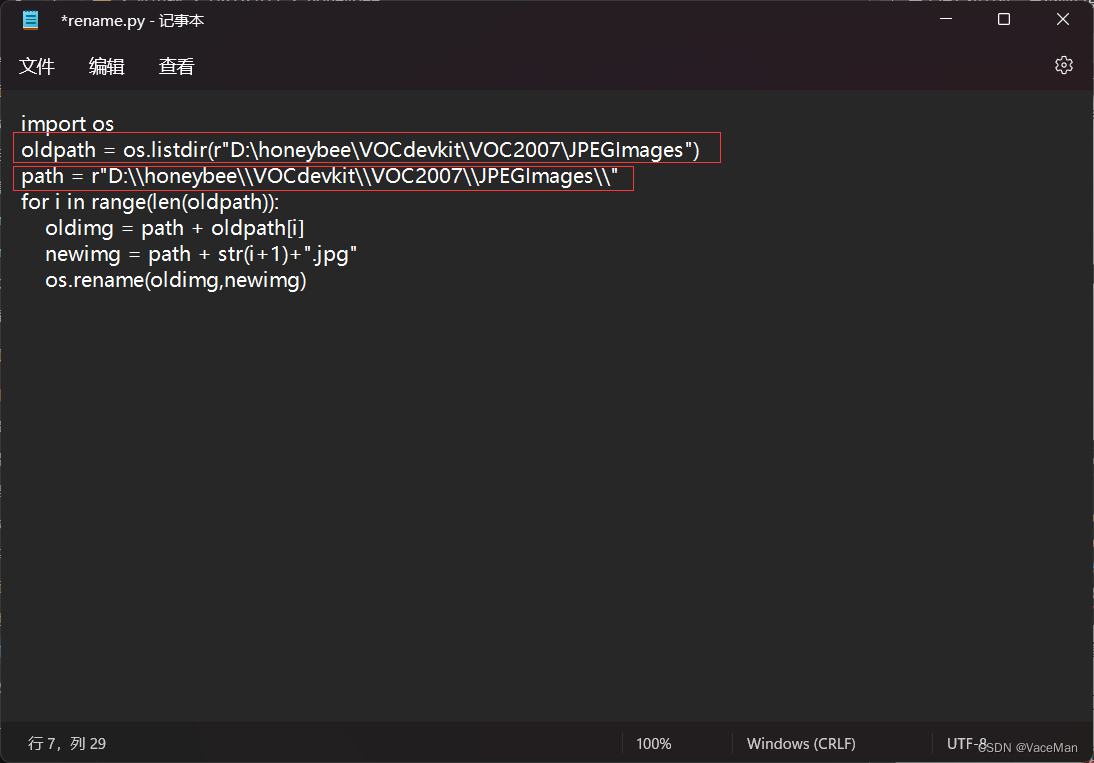
右键通过记事本打开文件,修改几处地方
修改oldpath、path
oldpath:我们JPEGimages绝对路径
path:oldpath把后面的JPEGimages去掉,并把\改成\\就可以啦
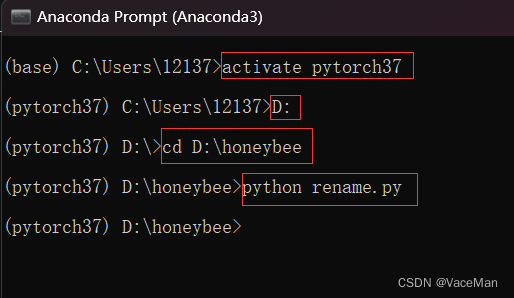
使用anaconda,激活进入虚拟环境,然后进入项目根目录,执行rename.py文件
查看重命名后的JPEGimages文件夹:
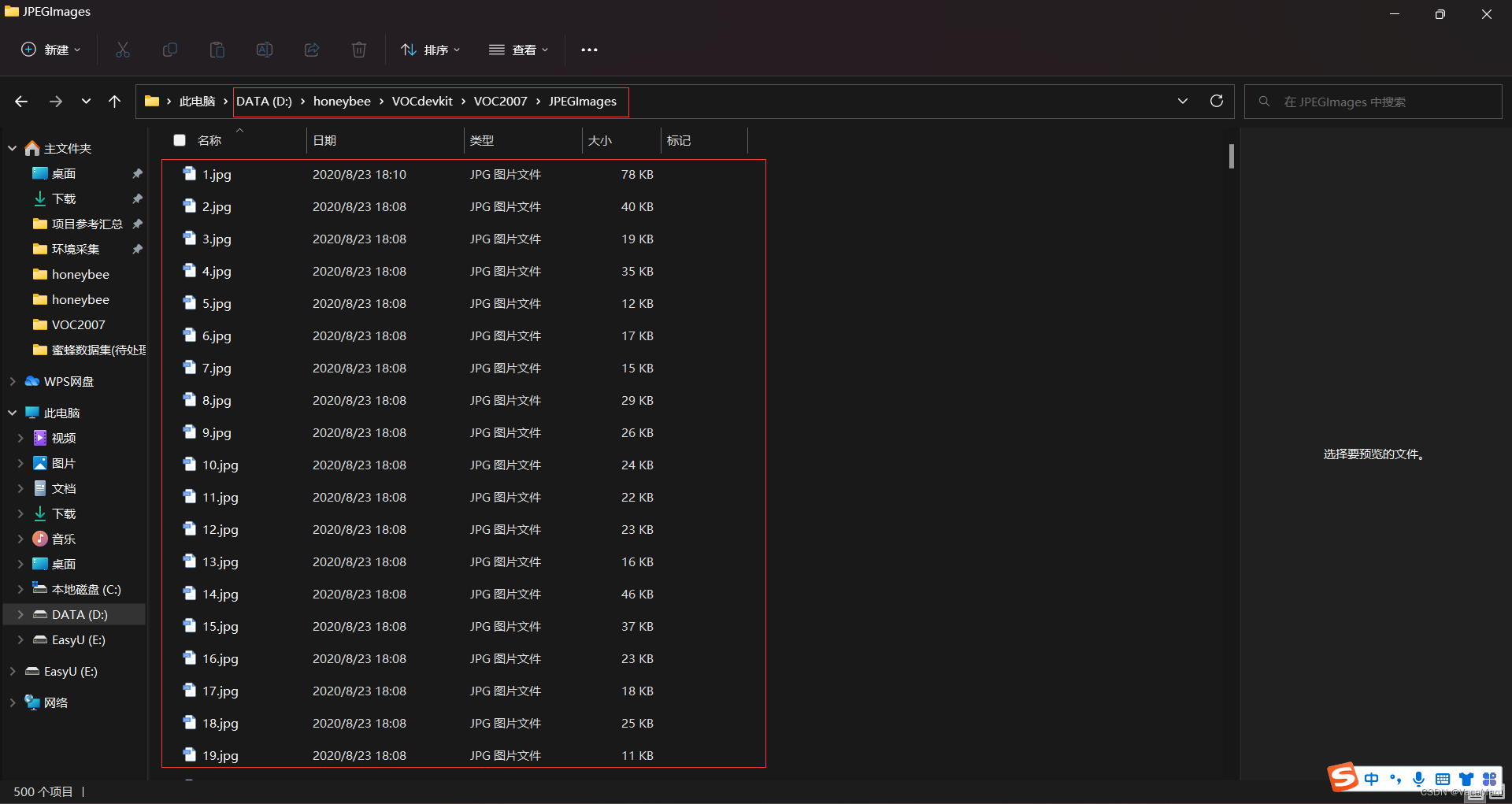
三、打voc(xml)标签,转为yolo(txt)格式并按照比例划分训练集和测试集
把我们的图像检测类别名称写进去
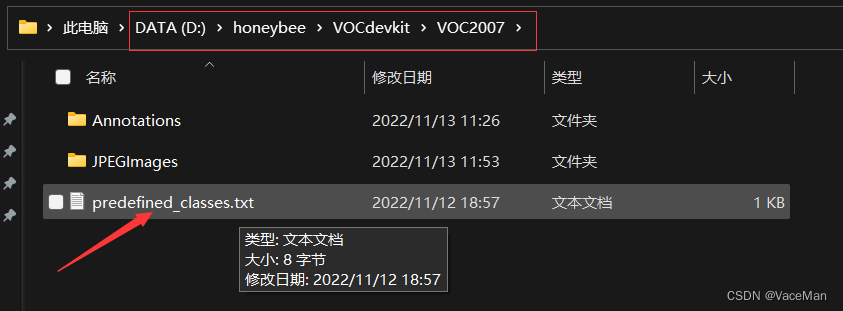
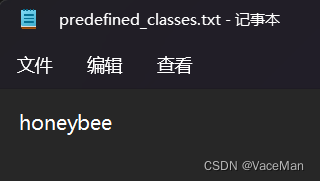
有多个名称就换行写

这里我们只有一个honeeybee,就按照下图写
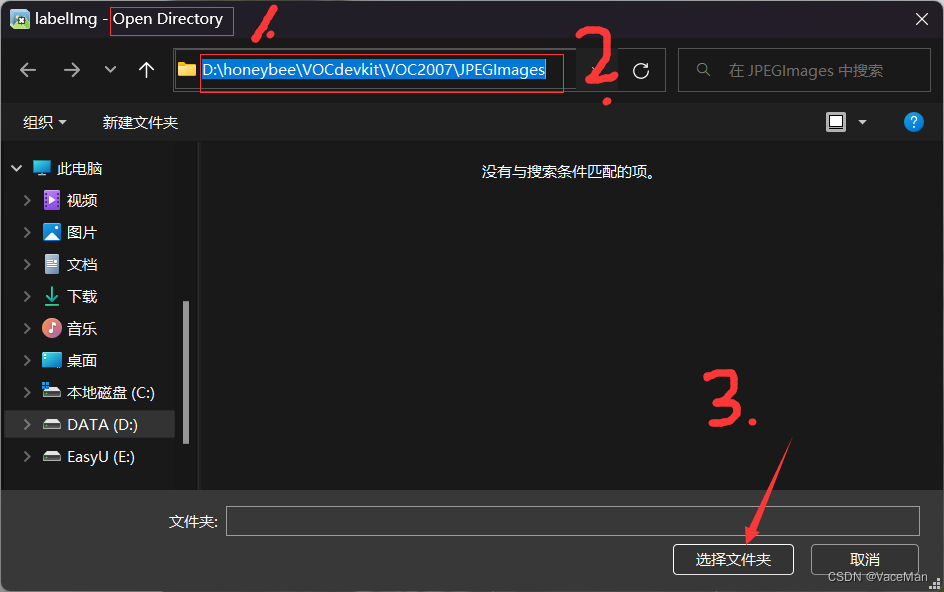
然后进入虚拟环境,再进入到我们的JPEGImages文件夹,执行下面的命令:
labelimg JPEGImages predefined_classes.txt
就打开labelimg标注软件了
打开后第一次见的话,不要慌,我们在左侧边栏检查源文件路径和更改目标文件路径就可以了。
源文件路径就是我们存放照片的JPEGImages文件夹,标签信息存放文件就是我们的Annotations文件夹。(下图左确认源文件夹对不对,下图右选择标签保存文件夹)
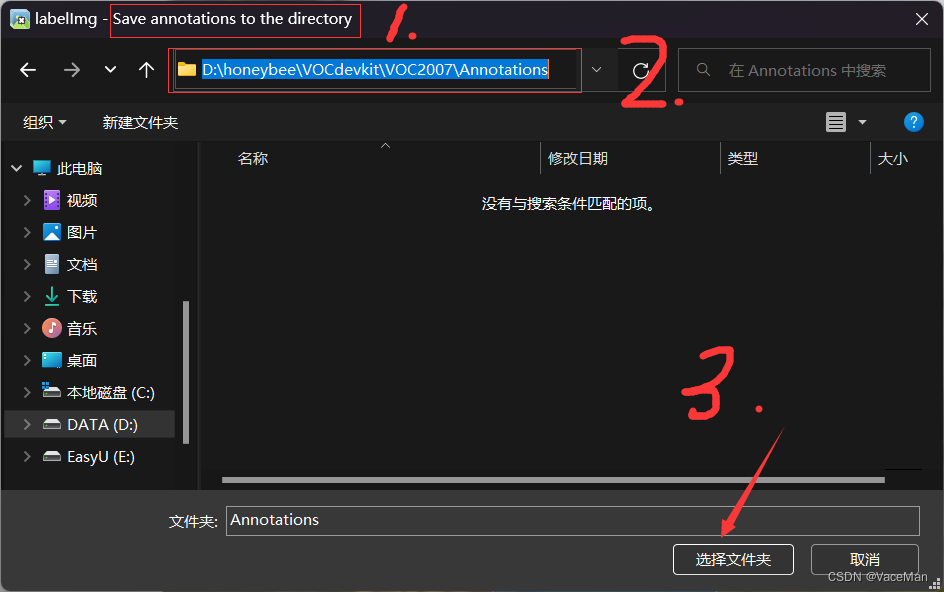
选择完后,就会显示我们的第一张图片,然后我们按下W键标注信息,标注完后按下D键再标注下一张照片,同理,按住A键返回上一张照片。
(有几个蜜蜂就打几个标签,下图有两个那就打两个)
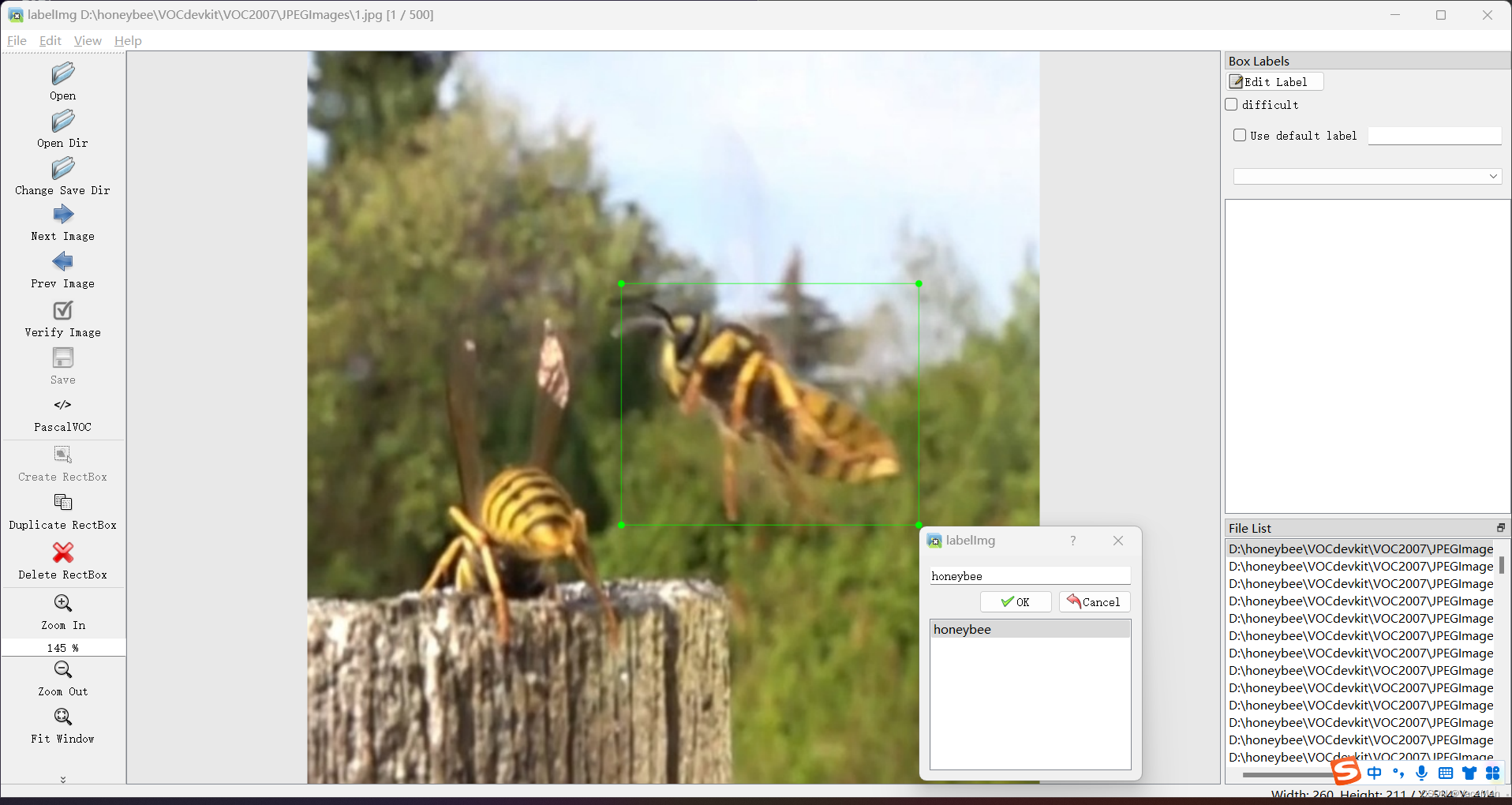
打完后,右边侧边栏会显示打了多少标签
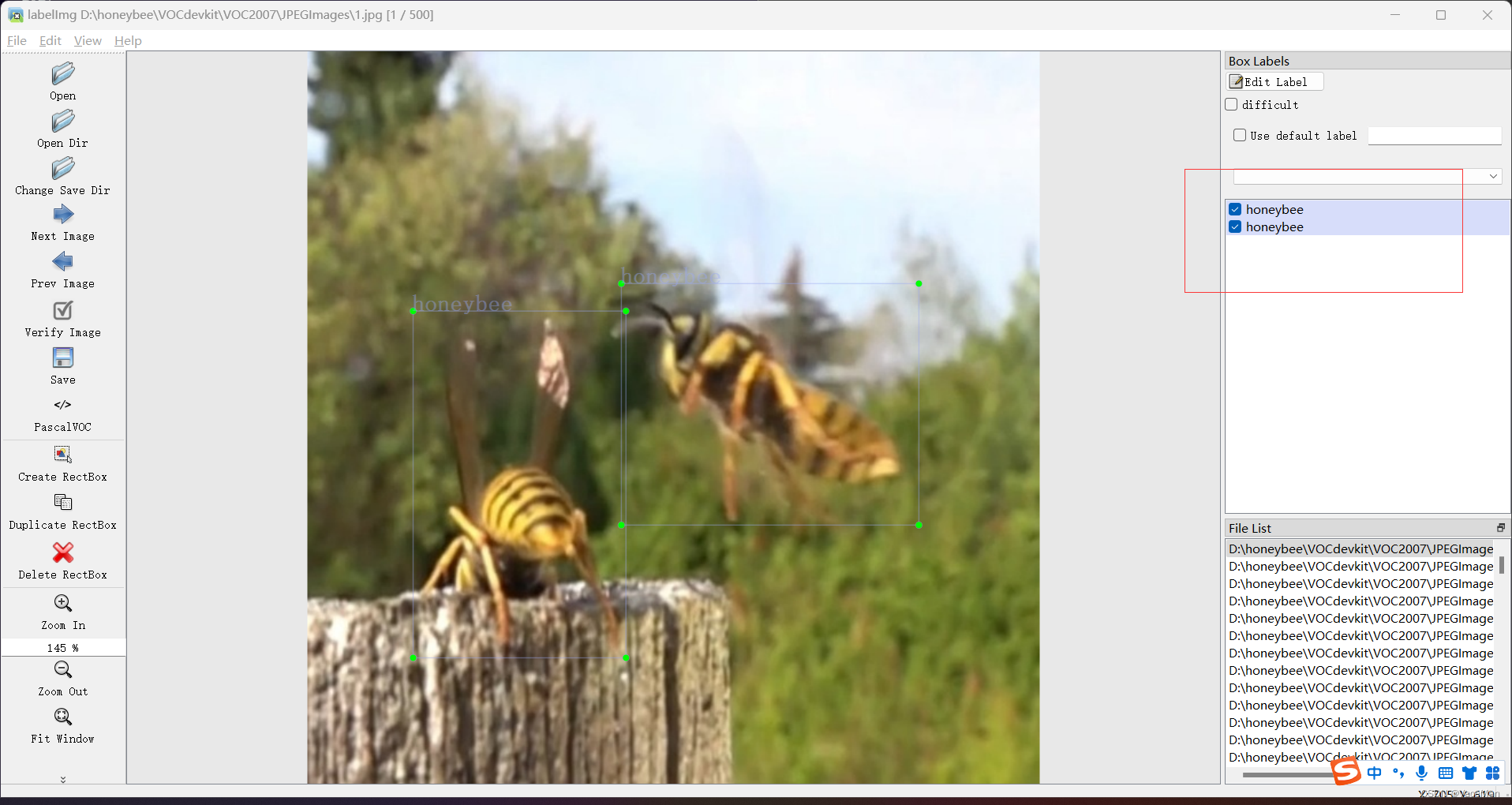
按下D键跳转到下一张图片,如果提示是否保存,点击确认就可以了。
如果不想每次都提示,可以设置默认保存。
每次保存的文件都放在了我们的标签存储文件夹下。
然后就可以开心的打标签了,打完最后一张,点击右上角关闭推出就可以了。
最后是466张图片和466张标签文件,标注过程中有一些图片不是很好就给删除掉了,如果删除图片的话,标签和原图片都删掉。
把voc文件转成yolo并划分训练集和测试集
这里用的是炮哥的源代码,把源代码文件2.py放在项目根目录下运行就可以啦:
炮哥数据集划分文章链接:
目标检测---数据集格式转化及训练集和验证集划分_炮哥带你学的博客-CSDN博客_xmlbuilder.writexml(f, indent='\t', newl='\n', add
2.py源代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["honeybee"]
#classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()2.py放在项目根目录,执行2.py,不用修改。
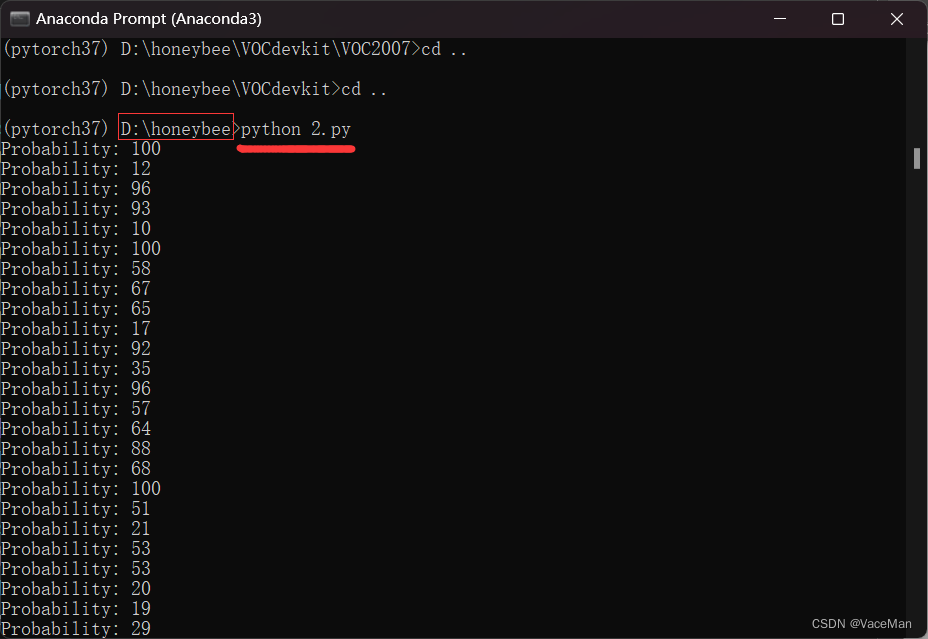
运行完后,再来看我们的项目文件,发现多了一些文件
根目录多了两个:yolov5_train.txt和yolov5_val.txt,里面放的是图片的绝对路径
这两个没有什么用,想删就删
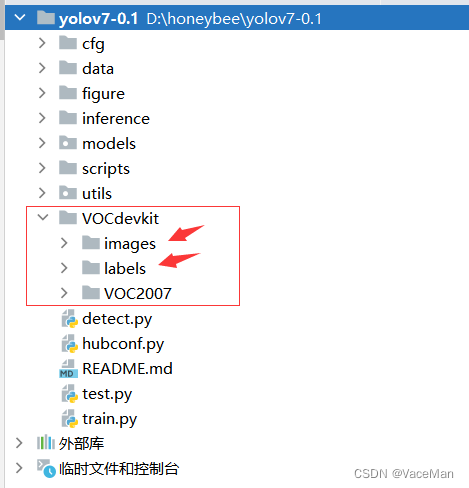
进入VOCdevkit文件夹,多了两个文件夹,images和labels文件夹,这两个是我们要用到的。
再进入到VOC2007文件夹,发现多了1个文件夹,YOLOLabels文件夹,里面放的是未分成训练和测试的yolo(txt)文件。
我们一般不用这个文件, 我们用分成训练和测试的yolo(txt)文件,这两个文件就是上面图片中的images和labels文件夹。
四、github下载yolov7 0.1模型和yolov7.pt参数文件,并把数据集导入到yolov7项目中
把从github上下载的yolov7 0.1和yolov7.pt参数文件放在项目根目录下。如下图所示:
将模型文件解压到当前文件目录:
用pycgarm将解压后的yolov7 文件夹打开
打开后,在右下角选择解释器,根据自己的情况选择就可以啦。
然后,我们把项目根目录的数据集文件 复制-粘贴 到项目根目录中。
数据集粘贴过程中的截图:
粘贴完后yolov7项目结构如下图所示:
五、 修改两个数据配置文件(yaml)
大白话就是,cfg/deploy/第一个模型配置文件.yaml 和 data/第二个数据集配置文件.yaml
如下图:
到这步了,不要慌,配置文件不要我们写,只要复制粘贴改名简单修改就好了。
修改模型配置文件:复制并粘贴yolov7.yaml,重命名(想取啥名取啥名)hb,如下图所示:
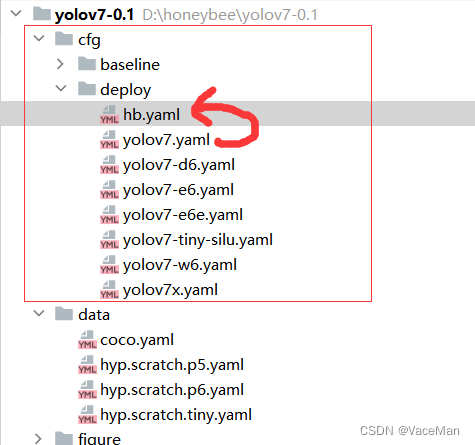
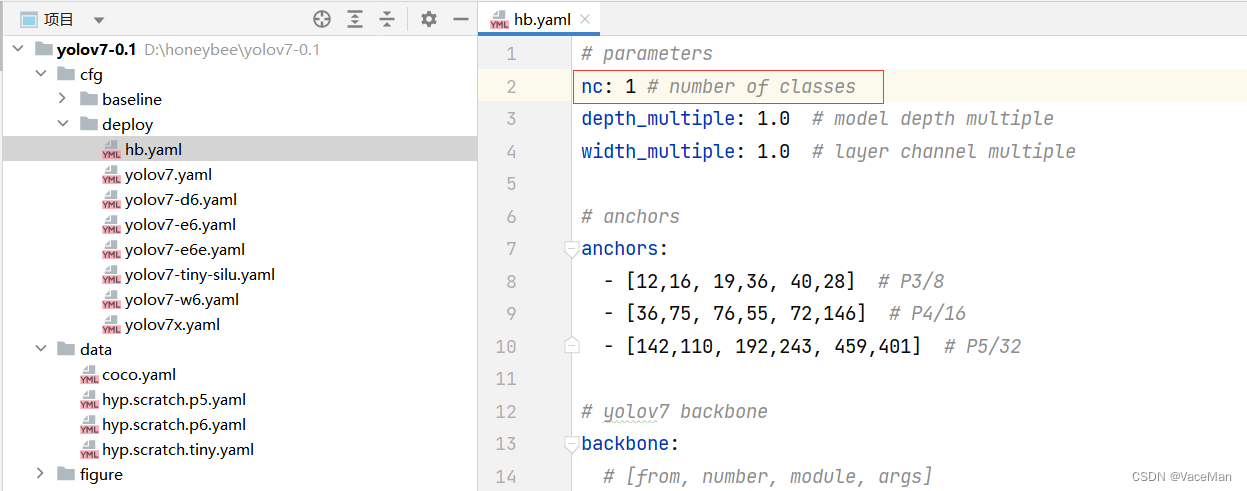
修改hb文件,只修改nc就可以,目标检测有几类就写几类,我只识别蜜蜂,所以nc写1。
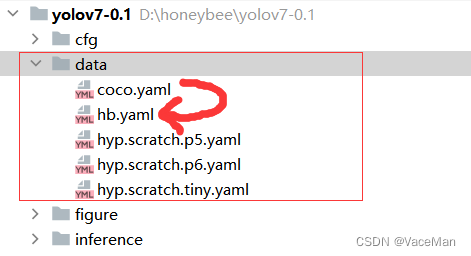
再修改数据配置文件,复制粘贴coco.yaml,重命名(想怎么取怎么取)hb.yaml
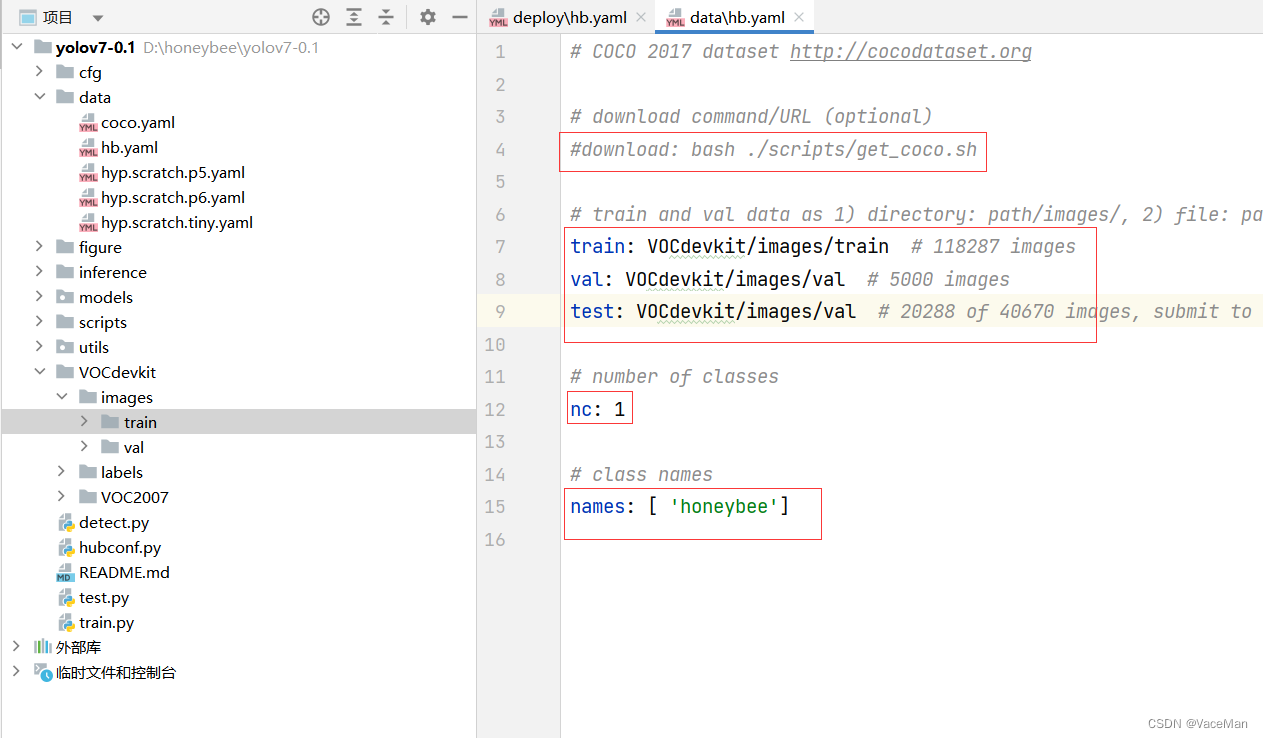
修改hb.yaml数据配置文件:
修改4部分:
(1)第4行注释掉
(2)7-9行修改数据集图片引用路径,只引用images下的train和val,如果数据集分类时只分了train和val,没有test,可以选择注释掉test或者把test路径修改成val路径。(另外,最重要的是,这里只引用了images,没有引用labels,yolo会自动根据images寻找相对应的labels文件,所以我们只告诉yolo images下的train和val就可以了)
(3)修改图像检测类别数nc
(4)修改图像检测类别名称,最好是英文,中文会乱码(乱码也可以解决,这里先不提了)
六、 修改train文件,运行并通过tensorboard查看
先把yolov7.pt参数文件导入到我们的模型根目录里(复制粘贴就可以)
进入trian文件,直接往下拉就可以了
依次修改default :
--weights default 修改成我们项目根路径刚刚导入的yolov7.pt
--cfg default 修改成我们的模型配置文件
--data default 修改成我们数据配置文件
--epochs 就是训练轮数 这里default我写成50,先跑50轮看一看
--batch-size 就是每一次加载多少张照片,这台电脑的显卡是1650ti,我设置了4
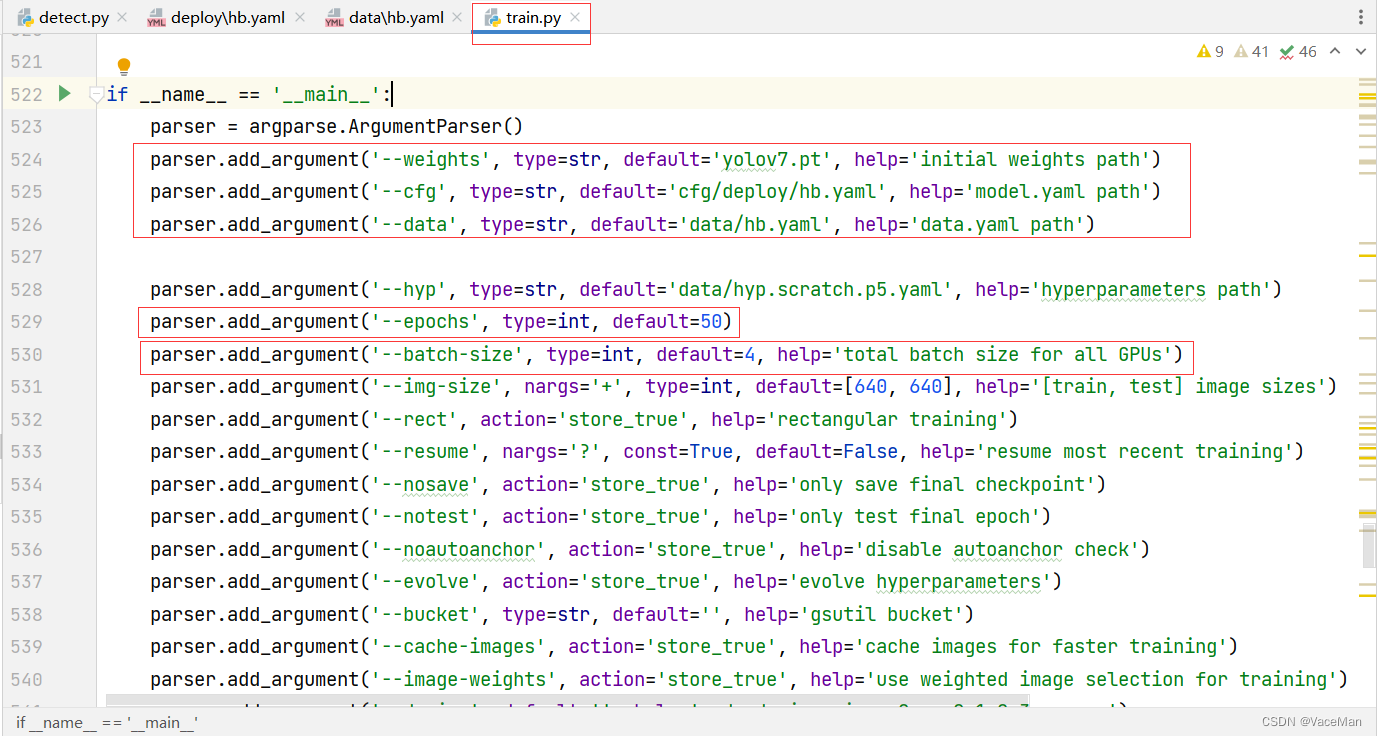
修改完后,如果你的电脑操作系统是windows,需要再设置num_workers为0,如下图
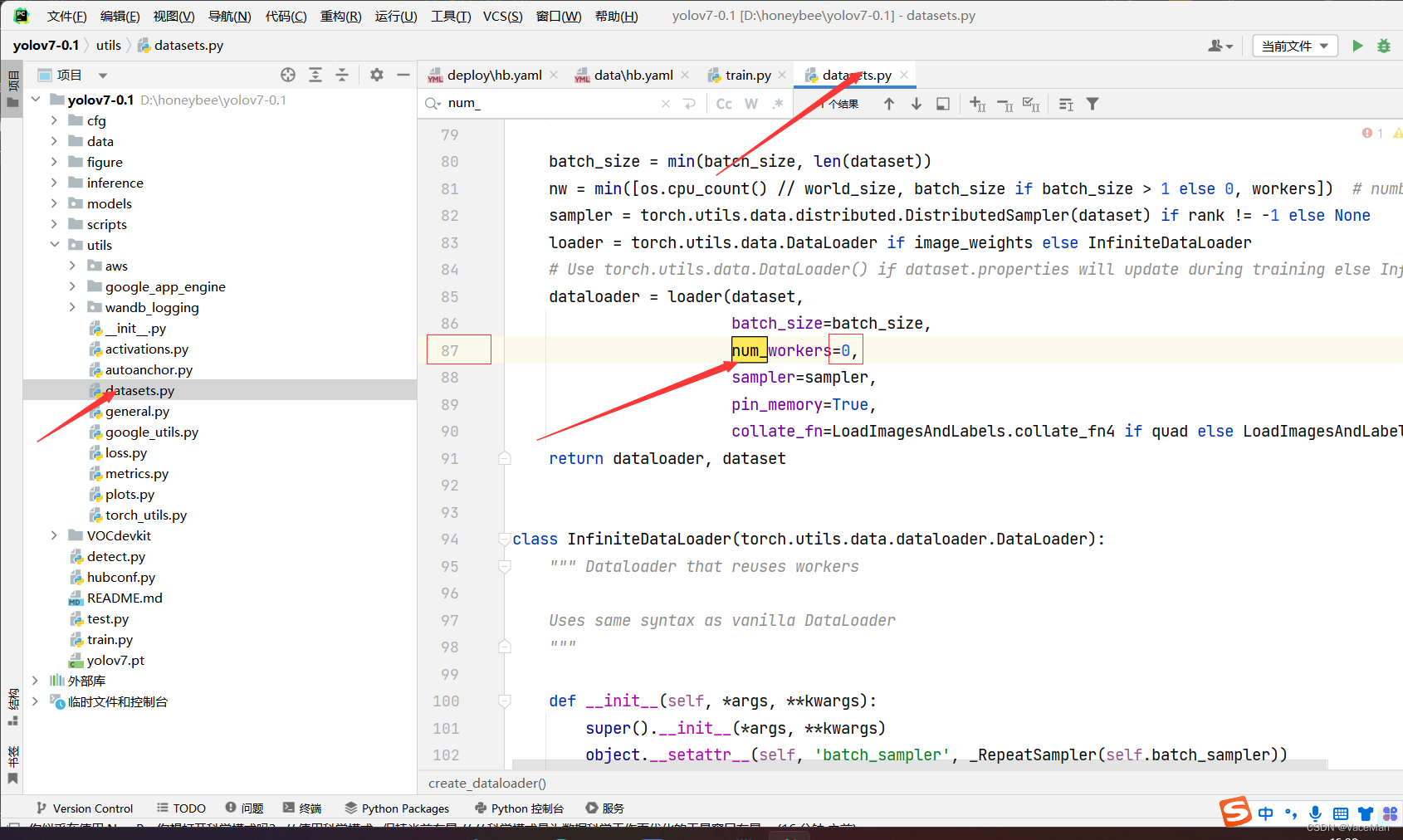
修改完后,在train.py中右键单击运行就可以啦
运行一段时间后,截图如下所示(1轮差不多15分钟,一小时能跑4轮)
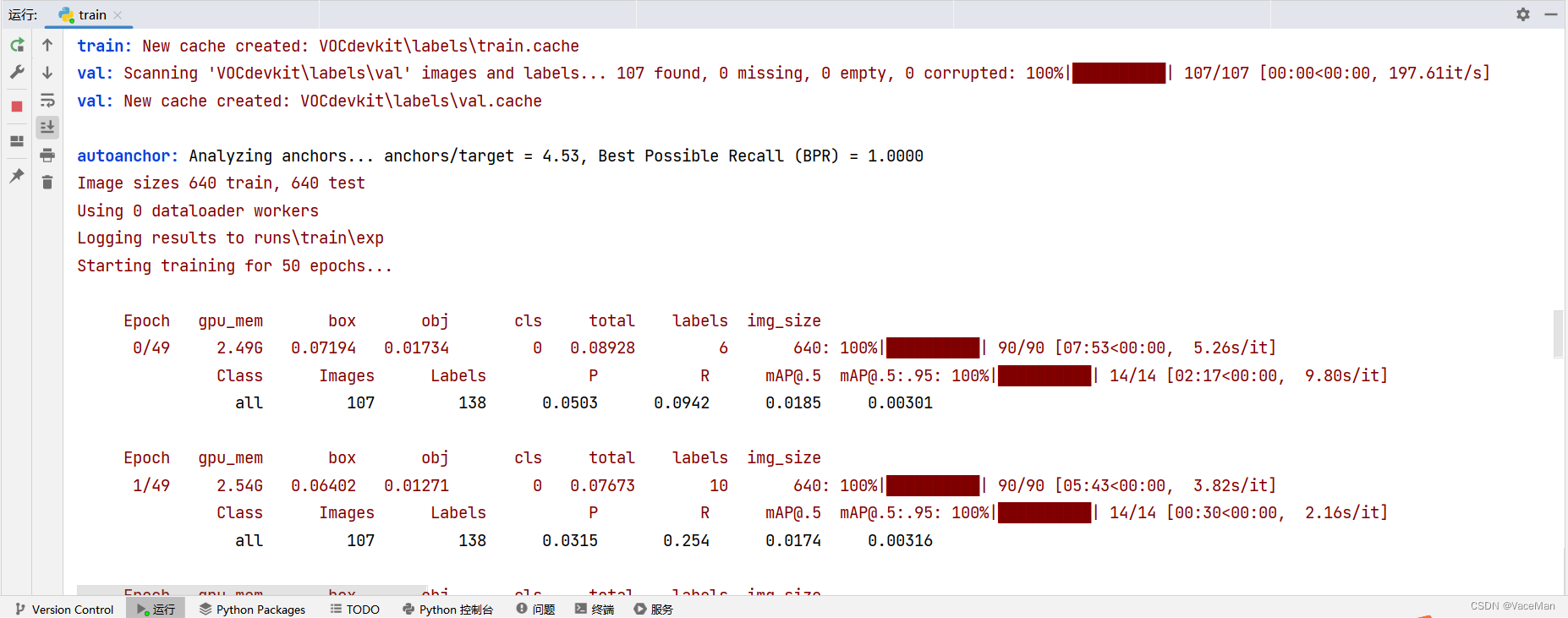
光看这个看不出啥东西,我们进入tensorboard看看如何。
pycharm底部选择终端,激活并进入虚拟环境,执行下面语句:
tensorboard --logdir=runs/train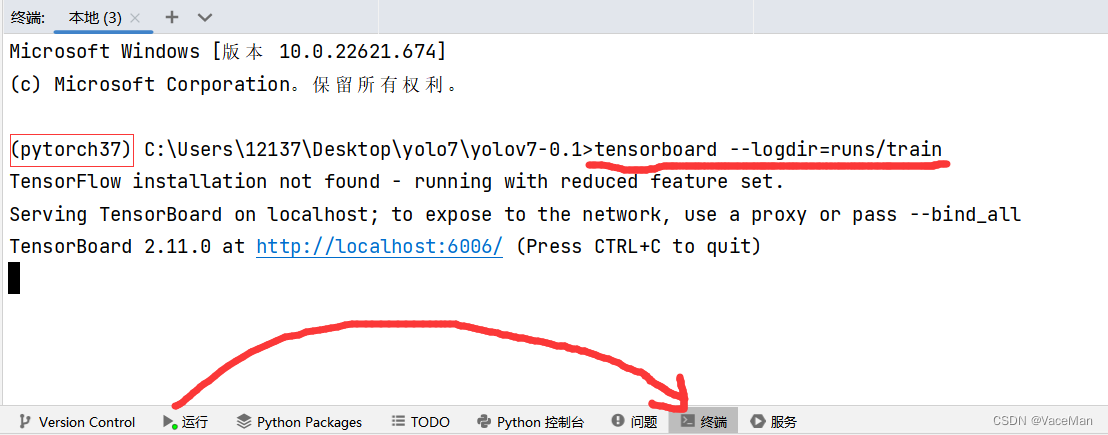
弹出网址后,按住ctrl点击跳转就可以看到啦
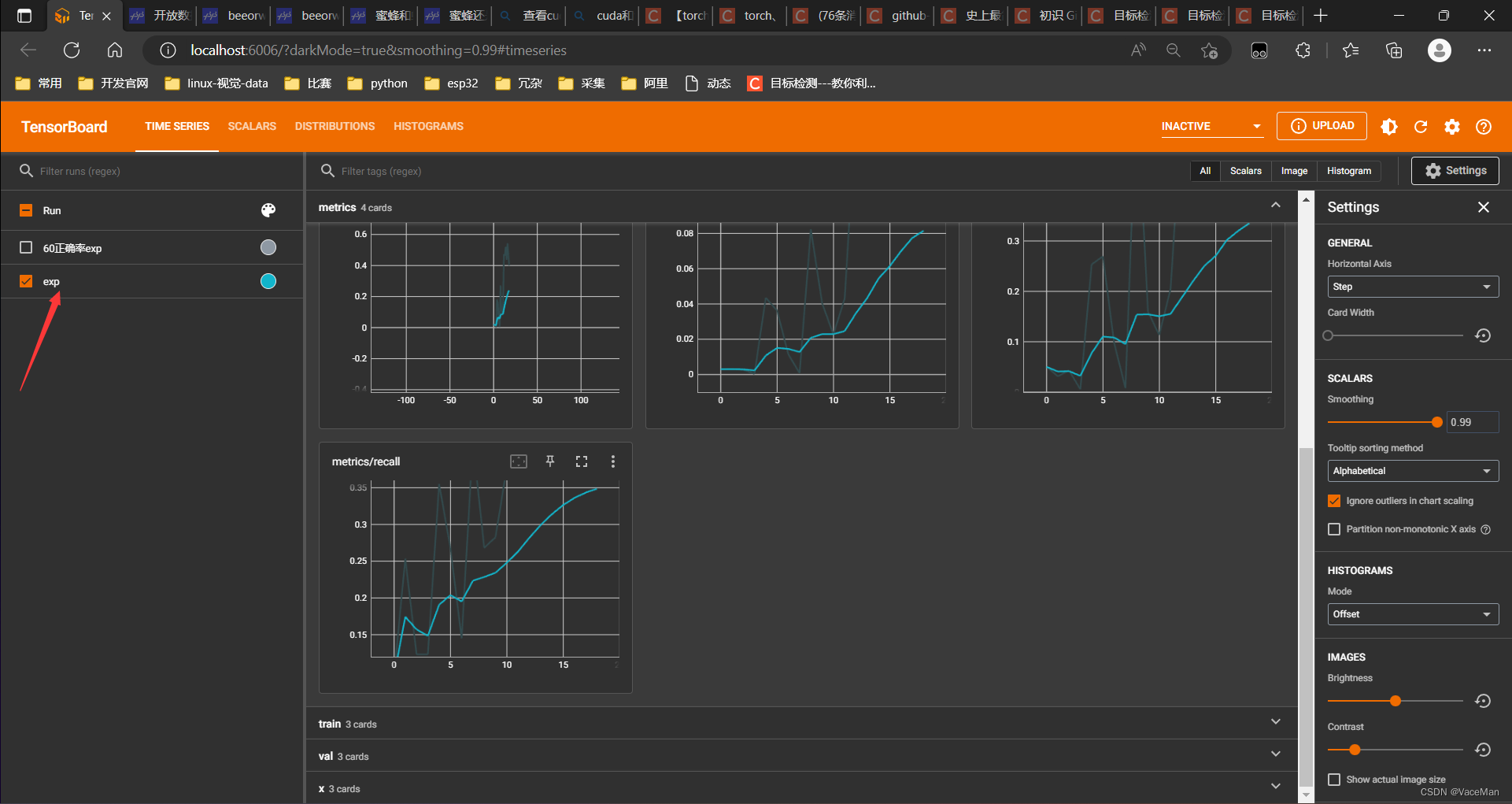
到此,训练就没有问题啦!
七、结尾
以上就是我从收集数据集到训练成功的全过程
现在模型还在跑
下个文档我们再说如何使用训练好的参数去图像检测(detect)