项目代码:
Paddledetection-picodet: https://github.com/PaddlePaddle/PaddleDetection
一、环境配置
- 下载anaconda,安装,win10左下角查找anaconda prompt 打开
- 输入 conda create –n picodet python==3.8.13 回车创建新环境 picodet
(conda会列出所有相关的包,问你是否下载,输入y 后回车开始下载)
- conda activate picodet 激活并进入新虚拟环境
- 输入conda install paddlepaddle-gpu==2.3.2 cudatoolkit=10.2 --channel Index of /anaconda/cloud/Paddle/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
- 验证安装,输入Python回车,进入python解释器,输入import
- 下载项目https://github.com/PaddlePaddle/PaddleDetection 并解压
- cd 到源码项目路径,复制路径到 你anaconda终端窗口中 (如果你的anaconda此刻在C盘,请输入F: +回车先切换磁盘位置 ,在粘贴路径切换到项目所在的路径中 )
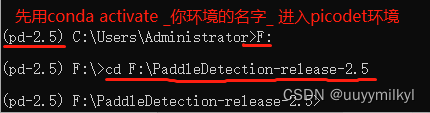
- 输入 pip install –r requirements.txt 安装需要的库
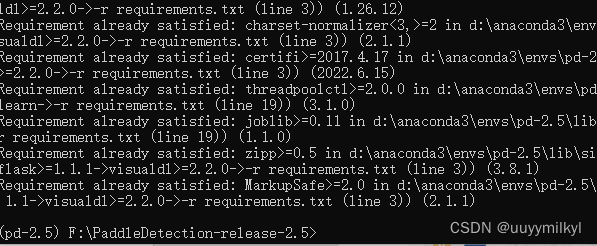
完成后是这个样子
- 输入 python setup.py install 安装项目
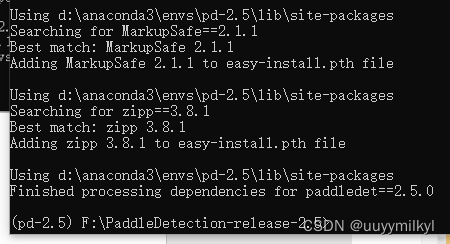
完成后是这个样子
二、数据准备
先对项目的文件进行一些了解
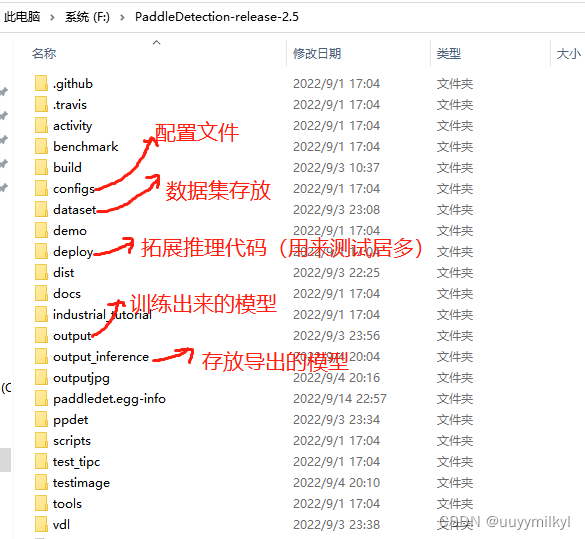
1.VOC数据集制作成coco数据集
2. VOC数据集文件夹中包含 Annotations (存放格式为xml的标签文件) Images (存放图像) train.txt , val.txt , test.txt (用脚本一键生成的数据集划分文件)label_list.txt (标签设置)
3. 执行VOC转COCO 脚本
指令:
python xml2coco.py --dataset_type voc --voc_anno_dir E:/Make_data/data_for_sentry/VOC/Annotations --voc_anno_list E:/Make_data/data_for_sentry/VOC/trainval.txt(这里是trainval.txt,依次改成train.txt, test.txt --voc_label_list label_list.txt --voc_out_name coco_val.json (用的文件改了之后,生成的文件名也要依次改成 coco_train.json , coco_test.json)
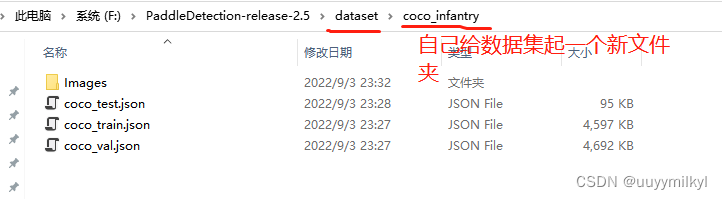
- 将生成的 coco_trainval.json coco_train.json coco_test.json 及图像文件 Images文件夹复制进 dataset/(自己取名)/ 之下
三、模型训练
1.修改配置文件 (标红的都是路径、文件名、值得留意的地方)
① 数据集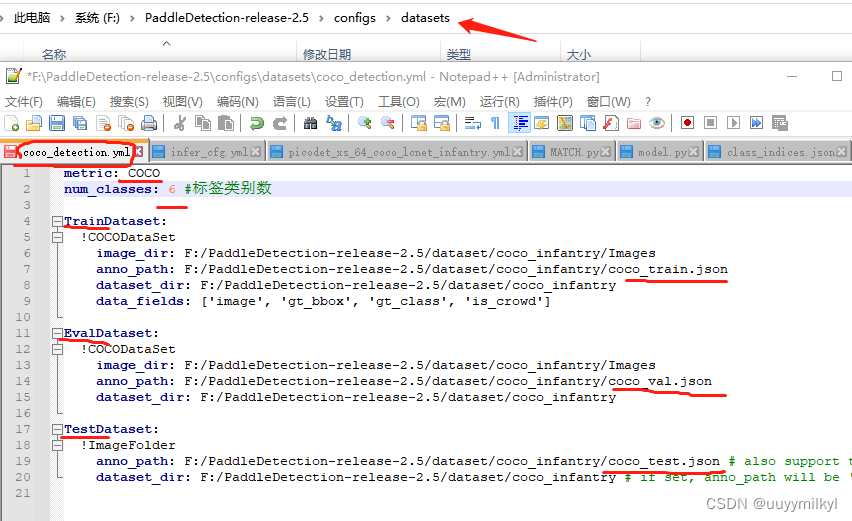
② 网络结构
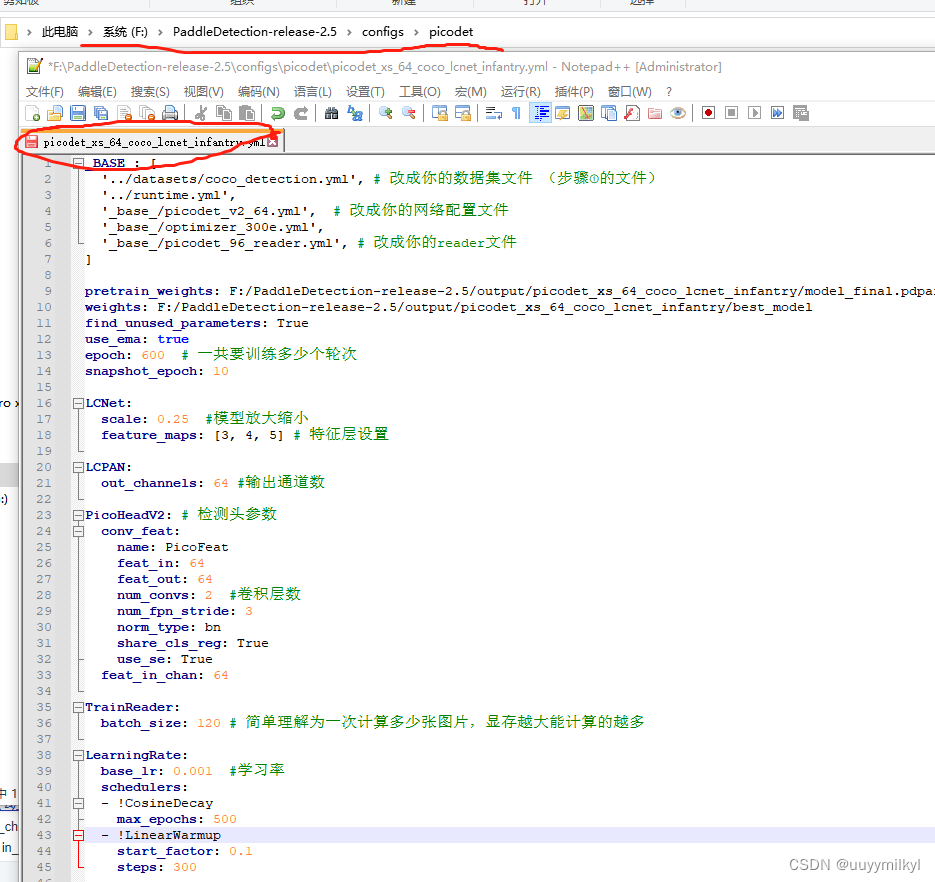
要理解这些参数的作用,需要有深度学习+神经网络的基础知识铺底,而且调整模型的参数以提升性能本来就是一项研究,有进阶学习需求的(想要帮我发挥出这个模型的上限的)以后可以回看picodet的论文和网络结构图来理解&改善它们
③ reader文件
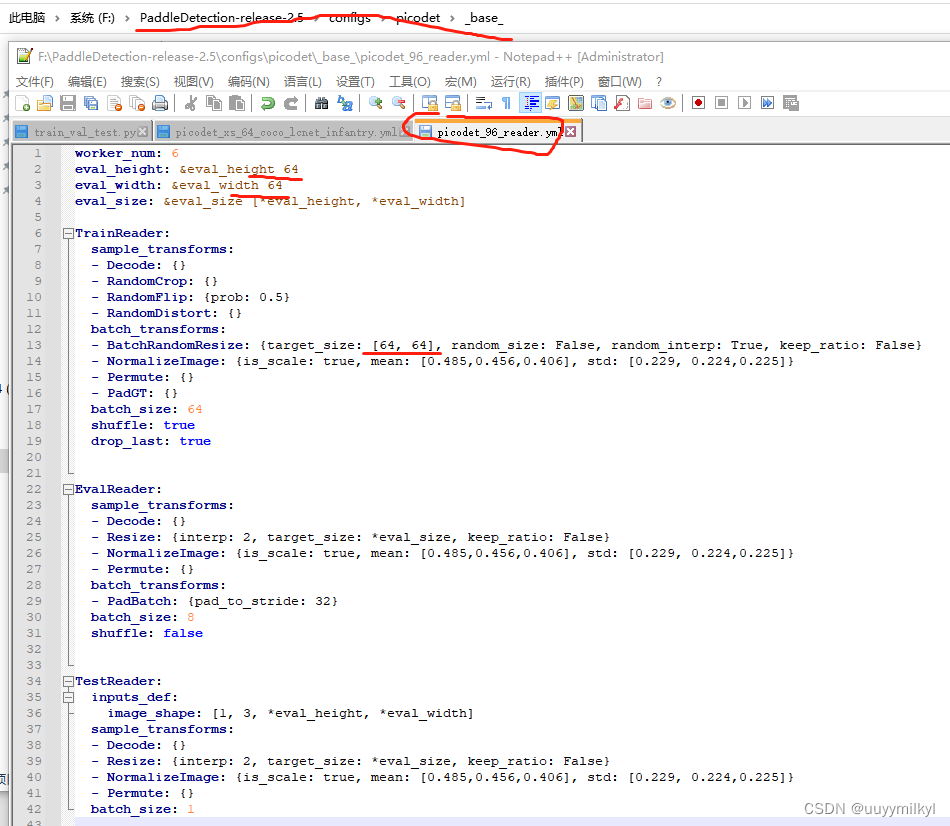
2.开始训练 python tools/train.py -c configs/picodet/picodet_xs_64_coco_lcnet_lastforsentry.yml -o use_gpu=True
四、模型检测
(这里的绝对路径/相对路径很多都是乱的,请自己对着改,不要直接复制进去就回车)
1. 模型导出
python tools/export_model.py -c configs/picodet/ picodet_xs_64_coco_lcnet_lastforsentry.yml(我的配置文件路径) -o weights=output/ picodet_xs_64_coco_lcnet_lastforsentry /model_final.pdparams TestReader.inputs_def.image_shape=[1,3,64,64] (设置输入图像的大小,要和训练配置文件一致
)
2. 用测试图像测试置信度,如果这里都没有90置信度那基本是废了
python deploy/python/infer.py --model_dir output_inference/picodet_xs_64_coco_lcnet_lastforsentry2(我的模型路径) --batch_size 1 --image_dir E:/Make_data/data_for_sentry/VOC_thredshould/test(我存放图像的路径) --output_dir E:/PaddleDetection-release-2.3/outputjpg/(我设定的图像导出路径) --device gpu --threshold=0.7 --save_mot_txts --save_images
3. paddle模型转onnx 模型
先 pip install paddle2onnx (下载包)
paddle2onnx --model_dir F:\PaddleDetection-release-2.5\output_inference\picodet_xs_64_coco_lcnet_infantry --model_filename model.pdmodel --params_filename model.pdiparams --save_file pico96_infantry.onnx --opset_version 11 --enable_onnx_checker True --input_shape_dict "{'image':[1,3,64,64]}"
4. 模型轻量级化
python -m onnxsim pico64_sentry_718.onnx(输入的模型) pico64_sentry_717_sim.onnx(输出的模型)
最后onnx模型就是放在这一行代码的路径里测试实际效果了
![]()