文章目录
本笔记为DataWhale 9月GitModel课程的学习内容,链接为:https://github.com/Git-Model/Modeling-Universe/tree/main/Data%20Analysis%20and%20Statistical%20Modeling
Task01 主要介绍了可视化相关知识,涵盖下面两方面内容:
- 从分析目标出发,不同数据类型所对应的可视化图表;
- 常用的可视化框架:matplotlib、plotnine、seaborn。
所有的可视化技术、可视化图表,都要围绕一个核心进行展开,这个核心就是——分析目标。
一、 图表类型
1. 类别型图表
针对类别型数据(Categorical Data),可以生成的图表如下:
(1)柱状图:
- 柱状图一般分为单系列柱状图、多系列柱状图、堆叠柱状图和百分比柱状图。
(2)火柴图:(棒棒糖图)
- 由于柱状图在表达数据的数值大小时使用的是不等高的长方形柱子,柱子会占据大量的绘图面积,因此当类别较多时,会出现画不下的情况。
- 再者,柱子的宽度并没有表达什么信息,因此可以省略柱子或者将柱子替换为直线就可以节省大量的绘图空间,这样的图就是火柴图。
(3)哑铃图:
- 由于火柴杆图只能展示一个纬度的数值对比情况,如果想像多系列柱状图一样对比两个或多个因素的数值变化情况,又不想像柱状图一样浪费许多绘图空间,那么哑铃图是个不错的选择。
(4)坡度图:
- 坡度图可以看做折线图的推广。
- 坡度图可以很好的比较各个类别在两个不同时间点或者两种不同状态下的数值数据的变化,表现的内容与哑铃图大同小异。
(5)雷达图:
- 雷达图可以展示多个变量在不同属性上的数值对比,如:十个员工在职场中五种能力的分数对比、英雄联盟每个英雄在每个属性的数值分数对比等等。
目前常用的绘图框架中,只有Matplotlib可以绘制雷达图。
2. 关系型图表
(1)散点图:
散点图常用于两个变量的关系表征,特别是数值变量与数值变量之间的关系。
- 变量之间是否存在关联关系;
- 如果存在关联关系,那么变量之间的关联关系是正向关联还是负向关联;
- 如果存在变量关系,那么是线性关联还是非线性关联;
- 是否存在趋势之外的点:离群点;
(2)带趋势线的散点图:
在前一种散点图的基础上,还可以运用统计学上的回归分析方法,拟合一条数据趋势线。
常用回归方法如下图所示:
(3)Q-Q图和P-P图:
当我们需要确定现有数据的分布特征时,可以借助Q-Q图与P-P图。
- Q-Q图:Q-Q图的横纵坐标分别是理论的分位数和样本的分位数,如果Q-Q图接近 𝑦=𝑥 直线,则认为样本符合某个分布;
- P-P图:P-P图的横纵坐标是理论的累积分布函数和样本的累积分布,如果P-P图接近于 𝑦=𝑥 那么认为样本符合某个分布。而当P-P图不是一条直线,有一定的规律,那么可以考虑对变量做一定的变换使得变换后的数据服从该分布。
(4)聚类散点图:
当我们想要探索不同类型的 x 1 x_1 x1 和 x 2 x_2 x2 之间是什么关系时,可以在第一类散点图的基础上,对类别进行标识。
如教程中的案例:
# 使用Matplotlib绘制聚类散点图
from sklearn.datasets import load_iris #家在鸢尾花数据集
iris = load_iris()
X = iris.data
label = iris.target
feature = iris.feature_names
df = pd.DataFrame(X, columns=feature)
df['label'] = label
label_unique = np.unique(df['label']).tolist()
plt.figure(figsize=(10, 6))
for i in label_unique:
df_label = df.loc[df['label'] == i, :]
plt.scatter(x=df_label['sepal length (cm)'], y=df_label['sepal width (cm)'], s=20, label=i)
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.title('sepal width (cm)~sepal length (cm)')
plt.legend()
plt.show()
运行结果如下:

更生动的用法可以像下面这样:
conormclaughlin 网站上的 " Checking in on the Start of the 2019-2020 NBA Season " 这篇文章,对 2019-2020 赛季,联盟中所有球队的 进攻(Offensive) 和 防守(defensive) 评分进行了可视化:

(5)相关系数矩阵图:
无论是在机器学习中,还是统计分析中,相关系数矩阵都是使用比较广泛的、查看多变量相关性的一种方法。
相关系数矩阵可视化后的结果——相关系数矩阵图:

3. 数据分布型图表
在进行探索性分析(EDA) 时,经常性的需要生成描述性统计数据,但更直观的方式可以借助数据分布图:
(1)统计直方分布图:(统计直方图)
- In statistics, a histogram is a graphical representation of the distribution of data.
- The histogram is represented by a set of rectangles, adjacent to each other, where each bar represent a kind of data.
直观上看,直方图是以离散区间的方式,展示数据的分布密度。
(2)核密度图
核密度图,则是通过连续曲线的形式(数学上的积分形式),对数据分布密度进行可视化。
(3)箱线图:
如果就是想看目标数据的纯数字特征,比如 百分位(percetile),四分位(quartile) 以及中位数(medians),可以使用箱线图。
这里有一篇讲述 boxplot 40年演变的文章:40 years of boxplots PDF,作者是 Hadley Wickham, Lisa Stryjewski 。
(4)提琴图:
之前的直方图只能反映数据的密度信息,箱线图只能反映数据的位置信息,有没有一种图可以将数据的密度信息和位置信息结合起来呢?有,这个图叫做:提琴图!
(5)饼状图/环状图:
饼状图也是一种非常常见的展示数据分布的图表:
4. 时间序列型图表
(1)时间序列线图:
折线图可以反映某个时间段内数值变量的趋势和关系,当只有一个线图时则可以反映趋势,而当有多个线图时,可以反映趋势的同时对比两者的关系。
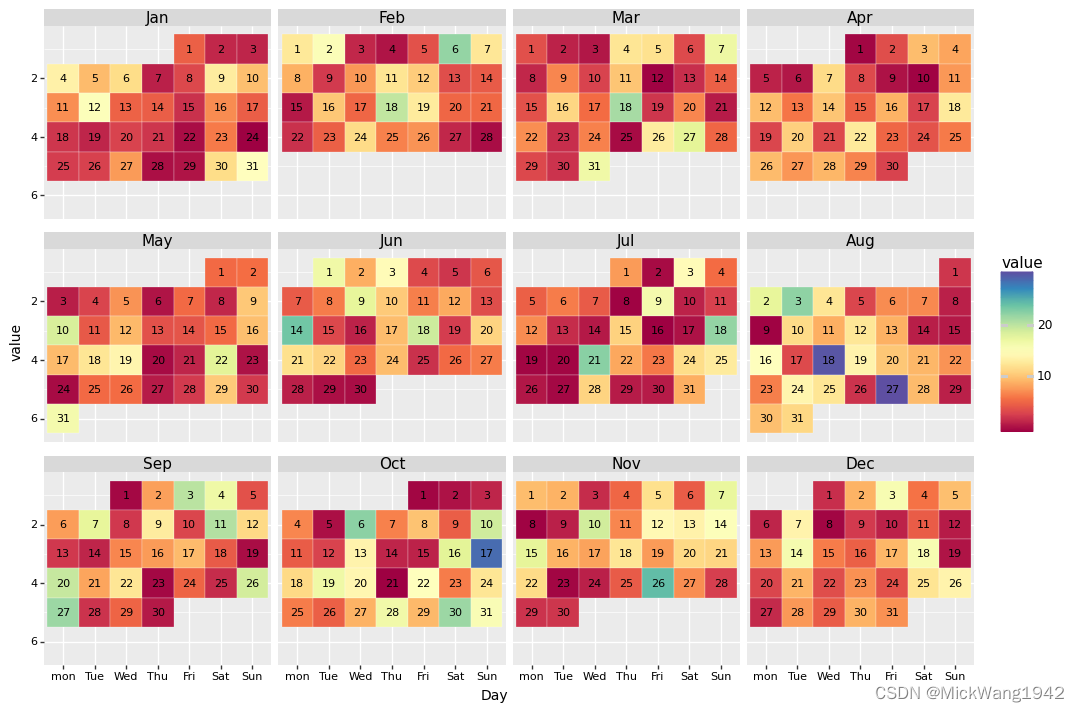
(2)日历图:
说到时间,不可不说日历,我们刚刚使用的是线图表达每天的数值变化大小,但是这个并不利于发现周期性的信息,如:每周五晚上火车站客流量也许是个高峰,每个月月初的进货达到高峰等等。这时候,我们可以使用日历图:
p1 = (
ggplot(df, aes(x='Weekday_label', y='month_week', fill='value'))+
geom_tile(colour='white', size=0.1)+ # 画出日历的方框
scale_fill_cmap(cmap_name='Spectral')+
geom_text(aes(label='Day'), size=8)+
facet_wrap('~Month_label', nrow=3)+ # 按照月份分面
scale_y_reverse()+ #将y周转向,因为越往下周数越大
xlab('Day')+ylab('value')+
theme(
strip_text = element_text(size=11,face="plain",color="black"),
axis_title =element_text(size=10,face="plain",color="black"),
axis_text = element_text(size=8,face="plain",color="black"),
legend_position = 'right',
legend_background = element_blank(),
aspect_ratio=0.85,
figure_size=(12,12),
dpi=100)
)
print(p1)
5. 空间分布图表
- 绘制地理图表,首先得有空间位置数据,地图常见的数据格式有:SHP格式与Json格式。
- 一般来说,在国家地理信息统计局提供的地图数据大多数以SHP格式,而大多数空间分析软件都能打开SHP格式的数据集并进行可视化;Json格式表示空间信息越来越常用,但是这种形式的数据体积更大。
- 在Python中,我们可以使用GeoPandas包可以轻松读取这两种数据形式的地图数据。在geopandas中,有两种基本的数据格式:GeoSeries与GeoDataFrame两种基础数据结构,对应pandas的两种基本数据结构:Series和DataFrame。
二、可视化框架
Matplotlib: https://matplotlib.org/
Seaborn: https://seaborn.pydata.org/
Plotnine: https://plotnine.readthedocs.io/en/stable/ ,是 Python 中的 ggplot2, 可以参考 ggplot2 的语法。
最后,来自导航员的建议:
在这里,我给大家在数据可视化task学习的几点建议:
1、世界上有很多种作图工具,如:matplotlib、plotnine、seaborn、plotly等等,这些不是最重要的,重要的是知道什么情况下使用哪个工具,即:知道工具之间的侧重点与差异点。
2、作图的语法不是最重要的,不同的工具语法是不一样的,数据可视化的重点是表达,即:什么业务场景下怎么表达,如研究不同类别的国家之间的GDP情况,那么就应该抽象出来是不同类别(携带地理信息)下的数值对比,可以使用分类散点图(表达在地图上最好)。
3、作图的语法不是最重要的,不同的工具语法是不一样的,但是要知道不同工具的绘制框架,如:matplotlib与plotnine之间的框架明显是不一样的。
4、很多同学初次接触plotnine,这个工具跟常规的matplotlib绘制很不一样,资料也很少,建议直接搜索ggplot2的同名语法,会很详细。