参考链接:https://mp.weixin.qq.com/s/EjT05Fl0gvuUwVhYaqx6QQ
MIT计算机与人工智能实验室和丰田汽车研究院的研究人员提出了一种基于自监督学习的3D神经渲染方法,该方法在训练阶段会观察大量的未标记的多视图视频,并从中提取时序特征,学习将复杂的场景(例如街道上有很多行驶的汽车)的单个静态图像映射到3D神经空间中,随后将整体特征表示分解为静态背景对象和动态前景目标,同时合理的完成整体3D结构的表述。在测试阶段,该方法只需要输入单张图像,网络便可将图像中所包含的3D场景和实例级的前景目标解析出来,下图是本文方法整体操作流程的动画。

此外,作者还进一步通过实验证明了本文方法可以作为很多下游任务的3D场景理解backbone,例如三维场景中对象的3D表示,新颖的3D视图合成,3D实例分割以及3D场景编辑等等。这都得益于本文引入了静态-动态分解机制(Static-Dynamic Disentanglement),为更加精细多维度的3D场景分析任务打下了基础。
01动机
本文作者提出了一种自监督方法,通过学习3D场景重建的方式来获得更精细的3D场景表示。同时受人类视觉感知流程的启发,作者也意识到运动视角是完整描述3D场景中静态背景和动态前景的关键线索,因此本文方法利用运动信息作为对象线索并在多视图视频上进行训练,在测试阶段就可以仅通过单张静态图像来重建出分解后的3D表示。
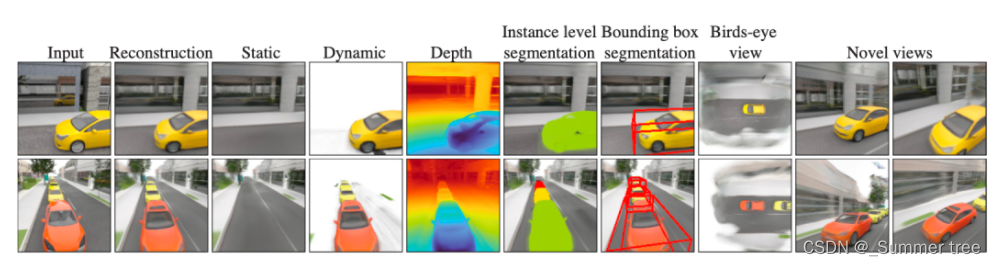
本文方法也可以被认为是一种专注于三维场景的多任务学习框架,如上图所示,模型首先对输入图像进行3D特征分解,随后完成包括三维场景重建、前景目标深度估计、3D实例分割、3D目标检测、3D场景编辑、鸟瞰视角合成和新颖3D视图合成等多个任务。
02 方法
两个步骤
第一步是将输入的单个静态图像映射到三维空间中,并转换为3D神经表示。
第二步才是将上一步得到的整体三维表示分解为静态背景和动态前景对象的三维表示。
给定单个图像,本文模型需要推断出一个神经平面图(Neural Ground Plans),即与实际地面对齐的2D网格,在该平面上提供了密集并且内存高效的神经场景表示。(与之前使用体素网格作为3D表示的方法相比,神经平面图具有更高的内存效率。因为传统体素网格的设计是内存密集型的,因而其很难将得到的三维表示扩展到高分辨率的情况。)
条件神经平面图
- 作者引入了条件神经平面图作为3D场景理解的紧凑场景表示
- 神经平面图的呈现形式是与场景地平面对齐的2D特征网格
- 本文将其定义为 xz-平面
对于每个3D点,首先将其进行投影到神经平面图中,并使用双线性插值方法来检索与其最接近的特征向量,随后将该特征送入到一个全连接网络中解码得到三维空间中的辐射度和密度值,供后续的神经渲染器使用以实现新颖的3D视角合成。
从单张或多张图像推理得到神经平面图可以分为三个步骤,如下图所示:
- 2D CNN 特征提取
- 特征投影
- 支柱融合
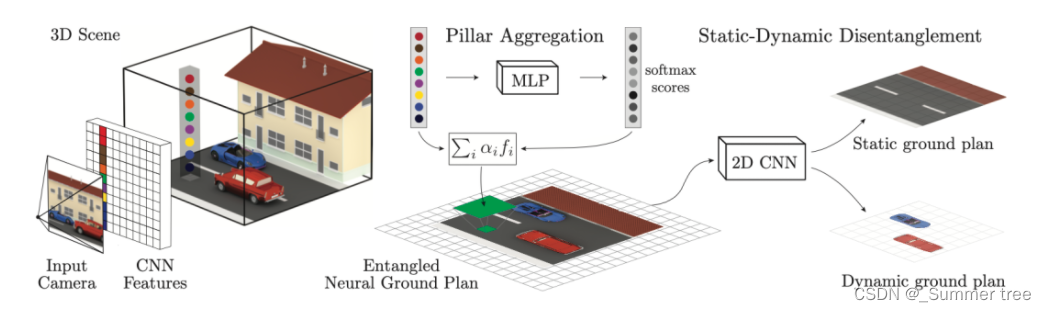
具体流程如下:
- 给定单张图像 I ,首先通过CNN编码器密集提取每个像素的特征得到特征张量 F
- 将相机定义为三维世界原点,并相应的将神经平面图居中放置,与地面对齐
- 将图像各点的特征沿各自的光线方向进行投影,并通过相机的固定参数和外在参数进行参数化(参数化过程对每个2D位置估计体积,其中v(x)=F(π(x)) 表示其在3D网格点上的体积。 π(·)是投影操作。
- 对平面图所有顶点的体积估计后会形成一个“支柱”,如上图左侧用彩色点标出的长柱。
- 将每个支柱通过一个MLP进行整合形成一个点送入到2D平面图中(支柱的整合过程可以理解为聚合当前2D网格在三维垂直空间上所有目标的场景特征表示)
静态-动态分解机制
作者利用运动信息作为对象线索来对整体的三维表示进行操作,同时引入了一种简单的启发式算法来对场景中的3D目标进行自监督形式的检测和实例分割。
Steps:
- 将多视图的视频序列帧作为模型的输入和训练信号,首先根据时间顺序选取视频的两帧 t=0 和t=1.
- 对于每一帧,模型首先推理得到两帧的神经平面图
- 该神经平面图中的特征对整体场景的静态和动态特征进行了参数化
- 将平面图输入到一个全卷积的2D网络中,该网络将其分解为两个独立的平面图,分别包含静态和动态特征
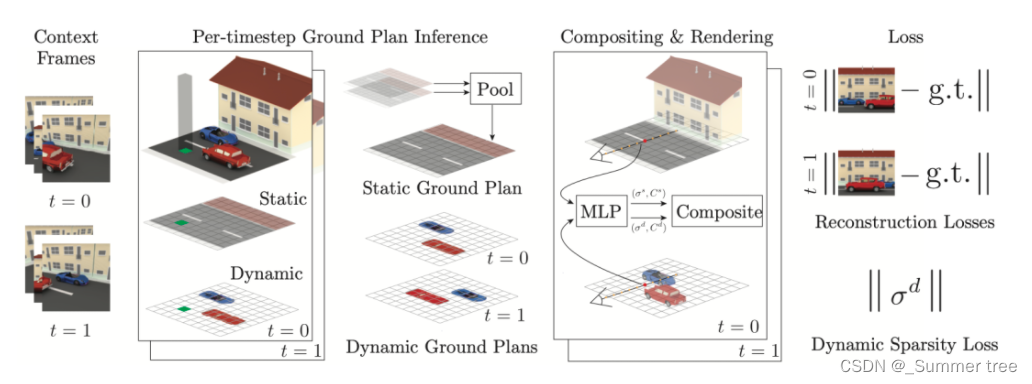
作者使用了一种可微分的体渲染方法来对每帧动态和静态平面图进行渲染,由于在训练时输入模型的是同一场景的多视图数据,其中一些视图作为网络的输入,另外一部分则用于计算损失函数,这里的损失函数由三部分构成,分别是图像重建损失,表面约束损失和稀疏损失:
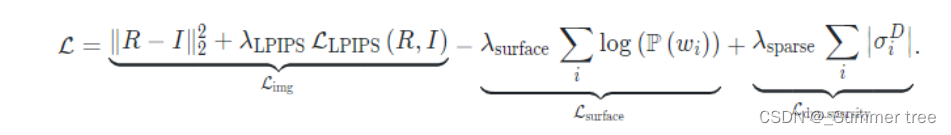
- 其中L_img是L2损失和LPIPS感知损失的组合,分别用来计算渲染图像和ground-truth图像之间的像素和感知距离
- L_surface 用来约束3D目标的渲染质量,分别鼓励沿着渲染光线的所有样本的静态和动态权重为0或1 (要求要么是动态的,要么是静态的)
- 稀疏项L_dyn_sparsity 从所有渲染光线在静态和动态神经平面图中的场景密度入手,使得模型在整体空间中尽可能的渲染非空3D结构,从而提升静态-动态解耦能力,同时提高渲染质量。
03 实验效果
相关实验情况介绍:
- 使用了一种街景数据程序生成器cosy[1]获取场景数据,其中包含了15个城市背景和95个汽车模型,最终通过组合得到了8000个场景样本。场景和背景并非自然一体
- 使用了CLEVR数据集来进行自监督目标分析任务的基准数据集
- Pixel-NeRF[2]方法进行对比,验证本文方法可以仅根据单张图像重建出大规模的三维场景
结果展示

- 本文方法可以可靠的将场景分割成静态和动态部分,同时合理的根据上下文信息补全了其中的遮挡部分。
- PixelNeRF虽然也可以在CLEVR上进行新颖视图合成,但其在更加复杂的cosy生成数据集的渲染结果展示出了明显的伪影,作者分析这可能由于PixelNeRF采用了线性采样导致的。(文章采用了什么采样呢)
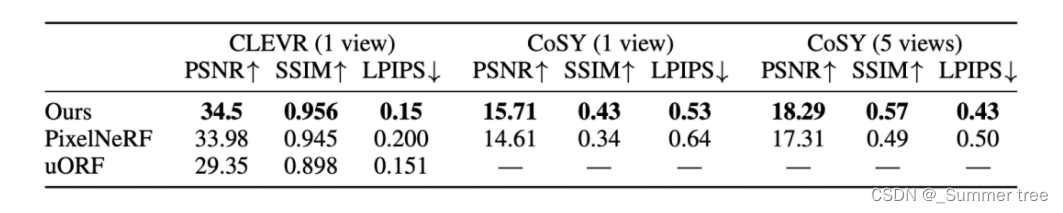
- 在CLEVR数据集上,uORF方法通常会产生高质量的渲染结果,但是其缺乏高频细节
- 本文方法可以在两个数据集上都合成具有高频细节的新视图,同时还可以将场景进行前后分解,具有更多优势。
04 总结
本文作者提出了一种基于自监督学习的3D场景表示学习方法,并将得到的3D表示分解为静态和动态的场景元素。虽然本文方法是在多视图数据集上进行训练,但是在测试阶段,模型可以从单个静态图像出发对整体场景进行三维重建。此外,作者结合神经平面图和本文推出的静态-动态分解机制,可以得到更加丰富的3D场景表示,其为很多下游以对象为中心的3D分析任务提供了一种数据高效的解决方案,例如3D实例分割、3D目标检测和3D场景编辑。作者也希望能够通过本文工作激发更多的工作将自监督静态-动态神经场景表示学习应用于更加泛化的场景理解任务上。