MapReduce经典案例—倒排索引
案例分析
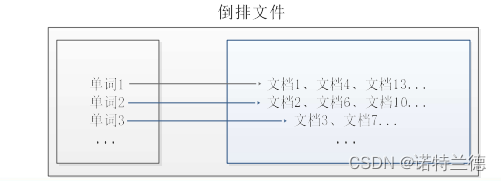
1. 倒排索引介绍 倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排 索引主要用来存储某个单词(或词组)在一组文档中的存储位置的映射,提供了可以根据 内容来查找文档的方式,而不是根据文档来确定内容,因此称为倒排索引(Inverted Index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(Inverted File)。
MapReduce经典案例
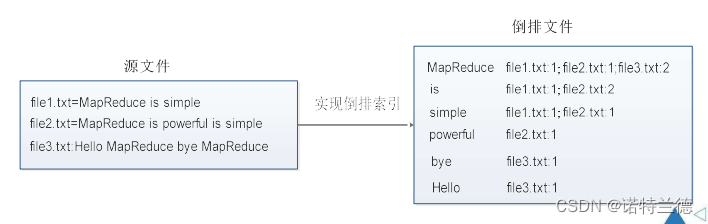
2. 案例需求及分析 现假设有三个源文件file1.txt、file2.txt和file3.txt,需要使用倒排索引的方式 对这三个源文件内容实现倒排索引,并将最后的倒排索引文件输出。
MapReduce经典案例—倒排索引
案例分析
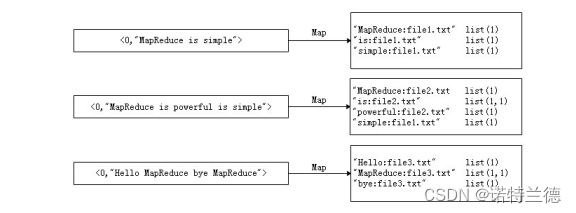
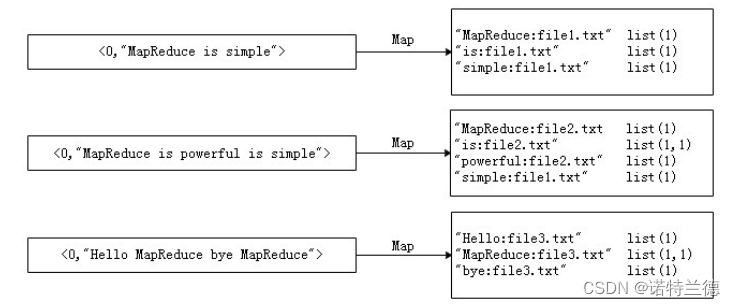
2. 案例需求及分析 首先,使用默认的TextInputFormat类对每个输入文件进行处理,得到文本 中每行的偏移量及其内容。Map过程首先分析输入的键值对,经 过处理可以得到倒排索引中需要的三个信息:单词、文档名称和词频。
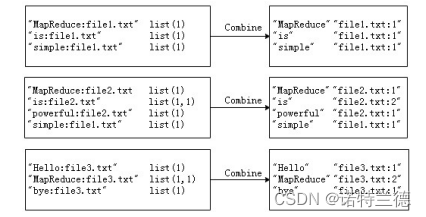
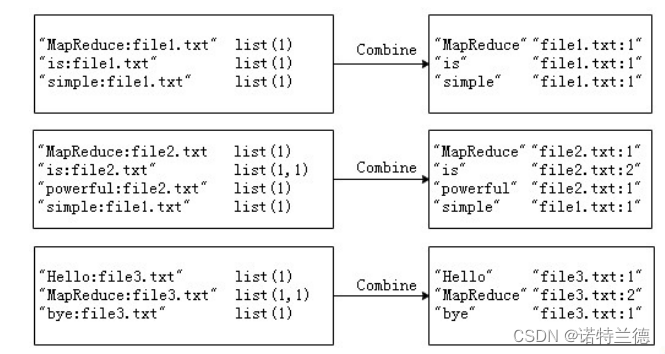
2. 案例需求及分析 经过Map阶段数据转换后,同一个文档中相同的单词会出现多个的情况,而 单纯依靠后续Reduce阶段无法同时完成词频统计和生成文档列表,所以必须增加 一个Combine阶段,先完成每一个文档的词频统计。
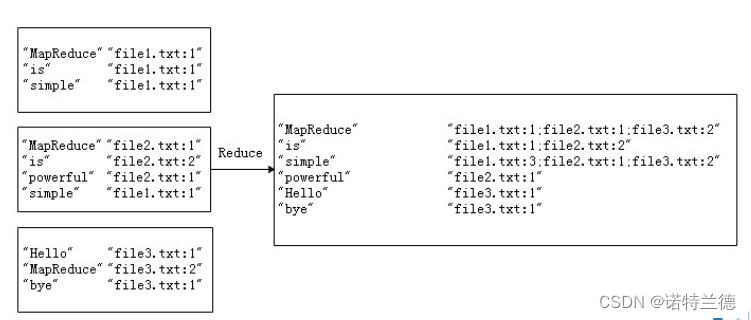
MapReduce经典案例—倒排索引 案例分析 2. 案例需求及分析 经过上述两个阶段的处理后,Reduce阶段只需将所有文件中相同key值的 value值进行统计,并组合成倒排索引文件所需的格式即可。

MapReduce经典案例—倒排索引 案例实现
1. Map阶段实现
首先,使用Eclipse开发工具打开之前创建的Maven项目HadoopDemo, 并且新创建cn.itcast.mr.invertedIndex包,在该路径下编写自定义Mapper类 InvertedIndexMapper,主要用于将文本中的单词按照空格进行切割,并以冒 号拼接,“单词:文档名称”作为key,单词次数作为value,都以文本方式输 出至Combine阶段。 ✎ 4.6MapReduce经典案例—倒排索引 案例实现
1. Map阶段实现
2. Combine阶段实现
根据Map阶段的输出结果形式,在cn.itcast.mr.InvertedIndex包下,自 定义实现Combine阶段的类InvertedIndexCombiner,对每个文档的单词进 行词频统计。
2. Combine阶段实现
3. Reduce阶段实现
根据Combine阶段的输出结果形式,同样在cn.itcast.mr.InvertedIndex 包下,自定义Reducer类InvertedIndexReducer,主要用于接收Combine阶 段输出的数据,并最终案例倒排索引文件需求的样式,将单词作为key,多个 文档名称和词频连接作为value,输出到目标目录。
3. Reduce阶段实现
MapReduce经典案例—倒排索引 案例实现
4. Driver程序主类实现
编写MapReduce程序运行主类 InvertedIndexDriver,主要用于设置 MapReduce工作任务的相关参数,由于本次演示的数据量较小,为了方便、快 速 进 行 案 例 演 示 , 本 案 例 采 用 了 本 地 运 行 模 式 , 指 定 的 本 地 D:\\InvertedIndex\\input目录下的源文件(需要提前准备)实现倒排索引,并 将结果输入到本地D:\\InvertedIndex\\output目录下。
5. 效果测试 为 了 保 证 MapReduce 程 序 正 常 执 行 , 需 要 先 在 本 地 D:\\InvertedIndex\\input目录下创建file1.txt、file2.txt和file3.txt;然后执行 MapReduce程序的程序入口InvertedIndexDriver类,正常执行完成后,会在 指定的D:\\InvertedIndex\\output下生成结果文件