1、namenode 与datanode 启动
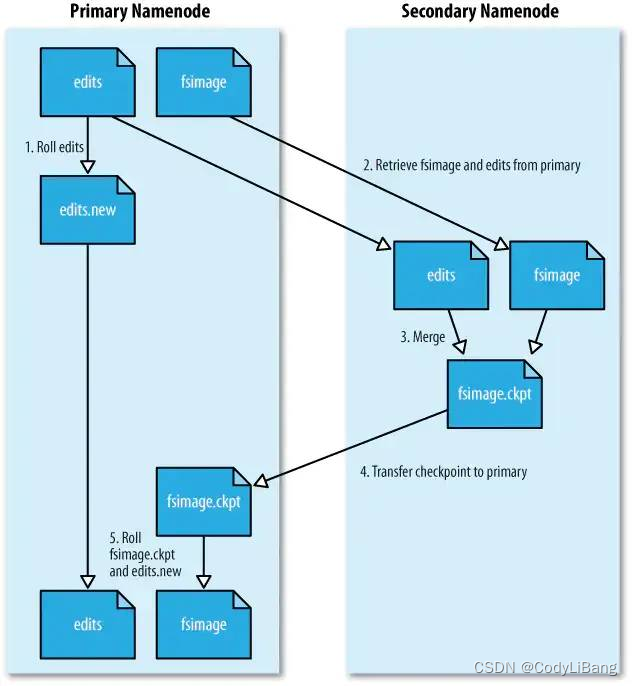
namenode工作机制
1.第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存中。
2.客户端对元数据进行增删改的请求
3.namenode记录操作日志,更新滚动日志。
4.namenode在内存中对数据进行增删改查
secondary namenode 角色
1.secondary namenode 询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
2.secondary namenode 请求执行checkpoint
3.namenode 滚动正在写的edits日志。
4.将滚动前的编辑日志和镜像文件拷贝到secondary namenode。
5.secondary namenode 加载编辑日志和镜像文件到内存,并且进行合并。
6.生成新的镜像文件fsimage.checkpoint。
7.拷贝fsimage.checkpoint 到namenode
8.namenode 将fsimage.checkpoint重新命名为fsimage.
过程示意图如下:
fsimage 与edits文件详解
所有的元数据信息都保存在了fsimage 和edits文件当中,这两个文件非常重要,元数据信息的保存目录配置在hdsf-site.xml配置文件当中。
在CDH中配置如下:

目录文件如下:
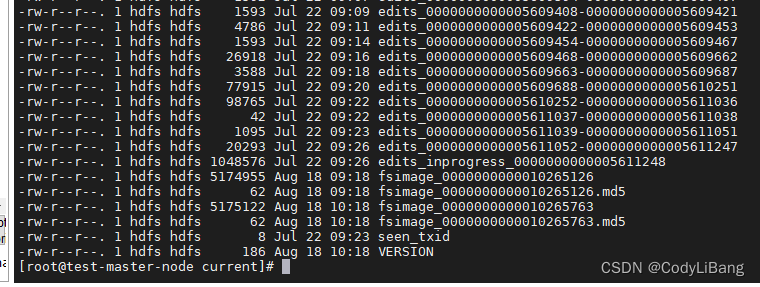
当前正在写入的edits文件名会有inprogress的标识,而seen_txid文件中保存的是当前正在写入的edits文件的id。
客户端对hdfs进行读写文件时都会先被记录在edits文件中。
edits修改时元数据也会更新,每次hdfs更新时edits先更新后客户端才会看到最新的信息。
fsimage: 是namenode中关于元数据的镜像,一般称为检查点。
一般开始时对namenode的操作都是放在edits中进行,为什么不放在fsimage
因为fsimage是namenode 的元数据的完整镜像文件 内容非常大,如果每次都加载到内存中生成树的拓扑结构是非常消耗cpu和内存的
fsiamge内容包含了namenode管理下的所有datanode中文件block,及block所在的
datanode的元数据信息。随着edits内容增大,就需要在一定的时间点进行fsimage合并。
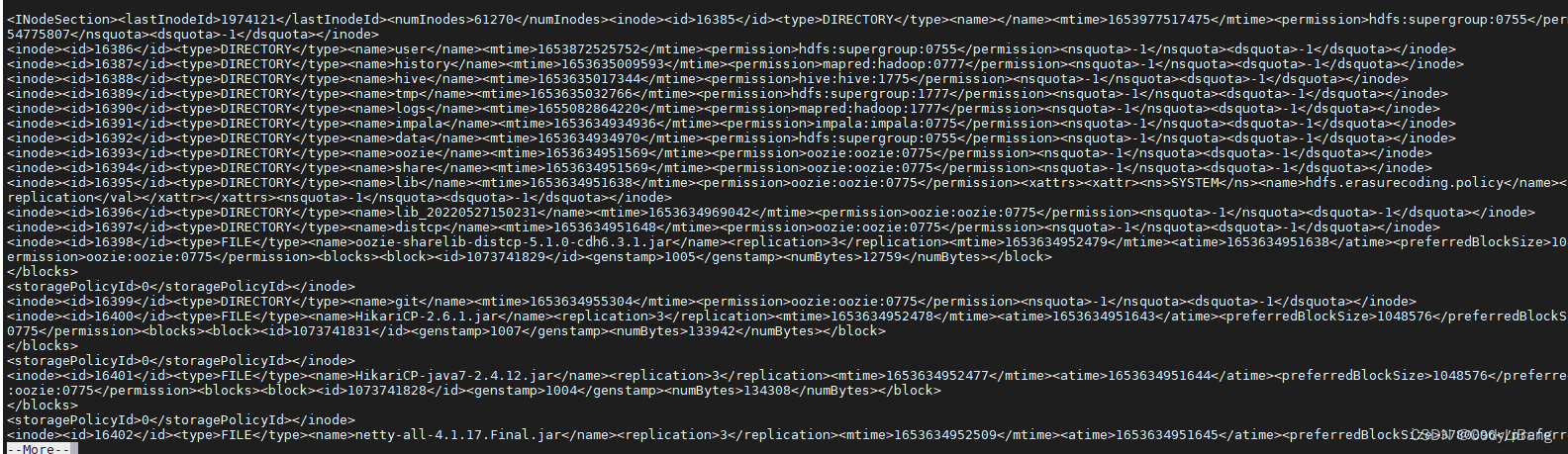
fsimage文件当中的文件信息查看
使用命令 hdfs oiv
cd /opt/hadoop-xxx/hadoopDatas/namenodeDatas/current
hdfs oiv -i fsimage_00000000112 -p XML -o hello.xml
文件内容如下:
edits文件信息查看
查看命令 hdsf oev
cd /opt/hadoop-xxxx/hadoopDatas/dfs/nn/edits
hdfs oev -i edits_0000000000112-111 -o edit.xml -p XML
文件内容如下:
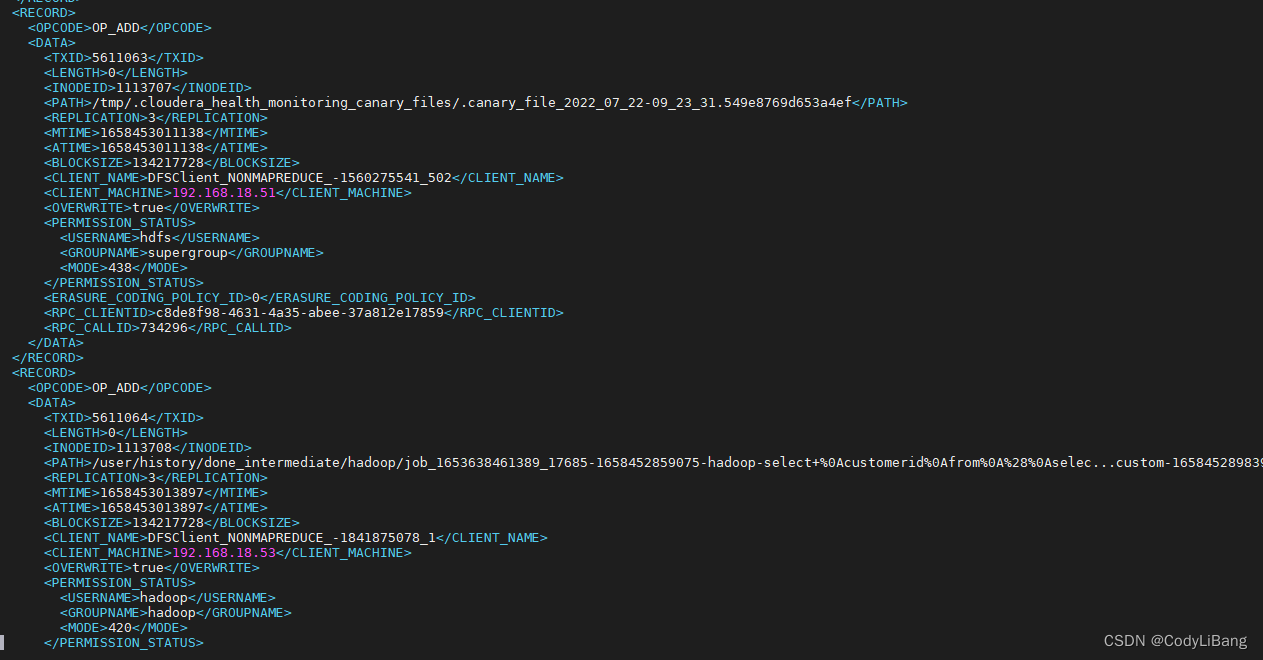
为什么不在namenode中完成上述的fsimage edits文件的融合操作?
namenode 需要处理大量的客户端元数据操作请求io频繁,此时再做该操作增加namenode的负担。
secondary namenode 不会有宕机的风险?
作为namenode节点的热备,secondary namenode 与 namenode 同样都是单节点
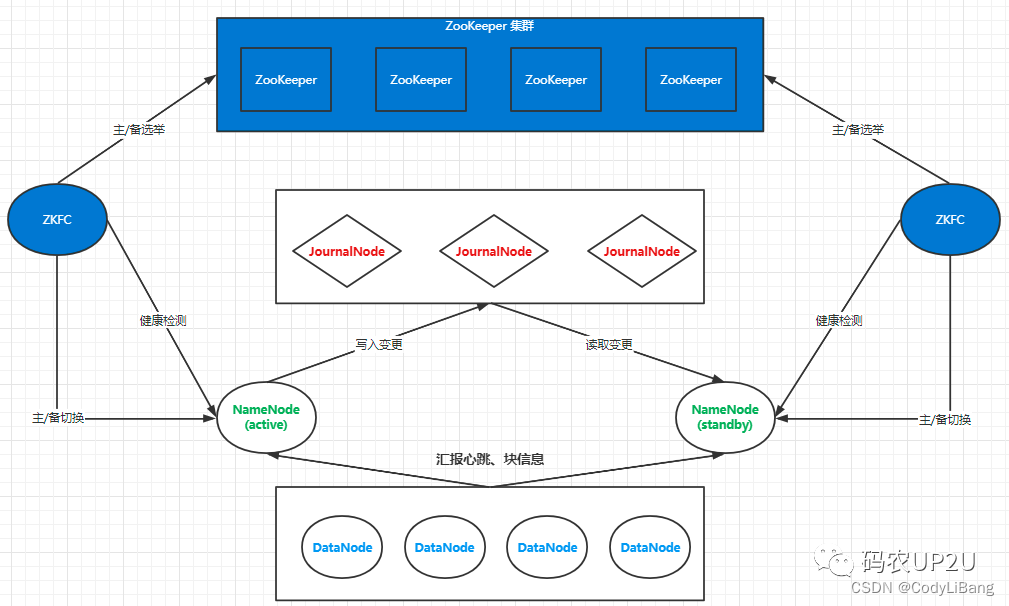
HDFS 的HA 模式
实际的应用中为了避免namonode 的单节点故障问题,往往需要引入故障转移,高可用模式。
这时可以采取多namenode方式,一个处于active服务状态,一个处于standby备用状态。但是这两个namenode角色的沟通成了问题;由于namenode 需要在内存中保存edits元数据信息
不可能在主备切换时备用namenode才从fsimage文件中获取元数据信息,所以这时就增加了JournalNode 节点。
journalNode节点扮演的角色则是在 active namenode与 standby namenode之间进行edits元数据信息的同步。
与单节点时的secondary name node 节点的功能时一样的。
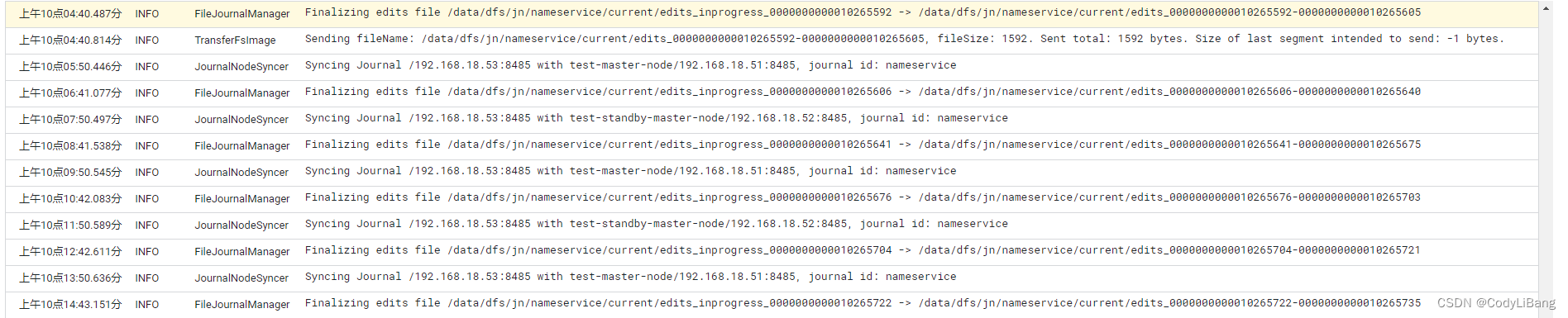
journalNode 工作日志如下:
HA高可用工作示意图: