前言:本人为C语言初学者,学识尚浅,研究程度存在很大的局限性,眼界很窄。以下所有观点仅代表个人见解和思路,各位游刃有余的前辈可以给予批评和指正!各位与鄙人同路的学子可相互探讨、发表看法,交换观点!
这是关于上一篇:初学C语言:sizeof 和 strlen 你真的了解吗?的拓展,关于二维数组和 sizeof 的深度解析,如果你能够理解上一篇的内容,这一篇的内容会对你有很大帮助。当然,并不是说你不能直接看这一篇,如果你有深厚的基础且真正了解它们,这一篇也应该不在话下。
目录
数组如下:
int arr[3][4] = {0};1.sizeof(arr);
int ret = sizeof(arr);首先,我想关于数组名的两点需要被再次强调:(1)sizeof 中,单独存在的数组名将会计算的是整个数组的大小 (2)&数组名,取出的是整个数组的地址
所以这里单独存在的数组名被计算了整个数组的大小,即为:3行 * 4列 * 4byte = 48byte
2.sizeof(arr[0][0]);
int ret = sizeof(arr[0][0]);arr[0][0] 即取出第一行第一列的值,为0,即为int类型,所以其大小为:4byte
3.sizeof(arr[0]);
int ret = sizeof(arr[0]);arr[0] 实则是二维数组中一维数组的数组名,所以计算的应该是整个一维数组的大小,即: 4个 * 4byte = 16byte
或许有人说,arr[0] 不是等价于 *(arr + 0) 吗?故想把以上代码转换成:sizeof(*(arr + 0)); 但是这里能转换吗?很简单的道理,我们都知道 arr 数组名在除特殊两种情况外,等价于 &arr[0] 但是 sizeof(arr); 确实是其特殊情况之一,那么 sizeof(arr); 并不等价于 sizeof(&arr[0]); 吧!所以 sizeof(arr[0]); 肯定也不能等价于 sizeof(*(arr + 0)); 啊!这里不要过度思考了!(这里其实是我自己的胡思乱想...)
4.sizeof(arr[0] + 1);
int ret = sizeof(arr[0] + 1);这里刚好与上一点对应,这里涉及到了运算,所以 arr[0] 本是表示整个一维数组,但现在作为一维数组的首元素地址使用,即表示:&arr[0][0],加上 1 即表示第一行第二列的元素的地址嘛!所以它最终得到的是一个地址,即第一行第一列元素的地址,为:8byte
5.sizeof(*(arr[0] + 1));
int ret = sizeof(*(a[0] + 1));首先,我们要明白先算的应该是:arr[0] + 1; 而因为 a[0] 参与了运算,所以变成了第一行第一列的地址,即变成了:&arr[0][0] + 1; 加 1 即表示第一行第二列的地址:&arr[0][1],又对其进行解引用:*&arr[0][1],所以最终获得的是:arr[0][1],即取出了第一行第二列的值,为int类型,所以其大小为4byte
6.sizeof(arr + 1);
int ret = sizeof(arr + 1);arr 本来作为数组名,但参与了运算,则表示数组首元素地址,又因为其是二维数组,所以 arr 这里表示的是一位数组的地址,即:&arr[0]; 这里的加 1 即让地址指向了第二行,变为了:&arr[1] 而已,但说到底还是地址,所以为:8byte
7.sizeof(*(arr + 1));
int ret = sizeof(*(arr + 1));分析同6,只是多了一步解引用,到最后便变成了:*&arr[1]; * 和 & 抵消,神奇的事情发生了,最后剩下了:arr[1]; 这是神马,这是数组名啊,所以到头来,它还是变成了数组名,变成了那个特例,计算了整个一维数组的大小,为:4个 * 4byte = 16byte
8.sizeof(&a[0] + 1);
int ret = sizeof(&a[0] + 1);a[0] 本来作为一维数组的数组名,但 &a[0] 涉及到一种特殊情况,即取出的是整个一维数组的地址,整个数组的地址加 1,最终得到的是第二行的一维数组的地址,即:&a[1]; 所以,无论怎样,它都是一个地址,占:8byte
9.sizeof(*(&a[0] + 1));
int ret = sizeof(*(&a[0] + 1));分析同8,只是多了一步解引用,到最后便变成了:*&arr[1]; 同理,* 和 & 会抵消掉,所以最后成了:arr[1]; 又是数组名,所以计算的自然又是一维数组的大小,即:4个 * 4byte = 16byte
10.sizeof(*arr);
int ret = sizeof(*arr);arr 本来是二维数组数组名,和解引用结合即参与了运算,所以这里的 arr 被视为首元素地址,即第一行,一维数组的地址,所以可以整个转换为:*(&arr[0]); 即:arr[0]; 又是一维数组数组名,所以又是:4个 * 4byte = 16byte
11.sizeof(a[3]);
int ret = sizeof(a[3]);好,好!傻了吧。这里执意对数组越界访问会怎样?
我们都知道,这里应该是计算第四行的一维数组大小,但是这个数组就三行,哪来的第四行!这里又不得不说一说这个 sizeof 的独到之处,不妨先用以下代码来见证一下:
short a = 2;
printf("%d\n", sizeof(a = 5 + 2));
printf("%d\n", a);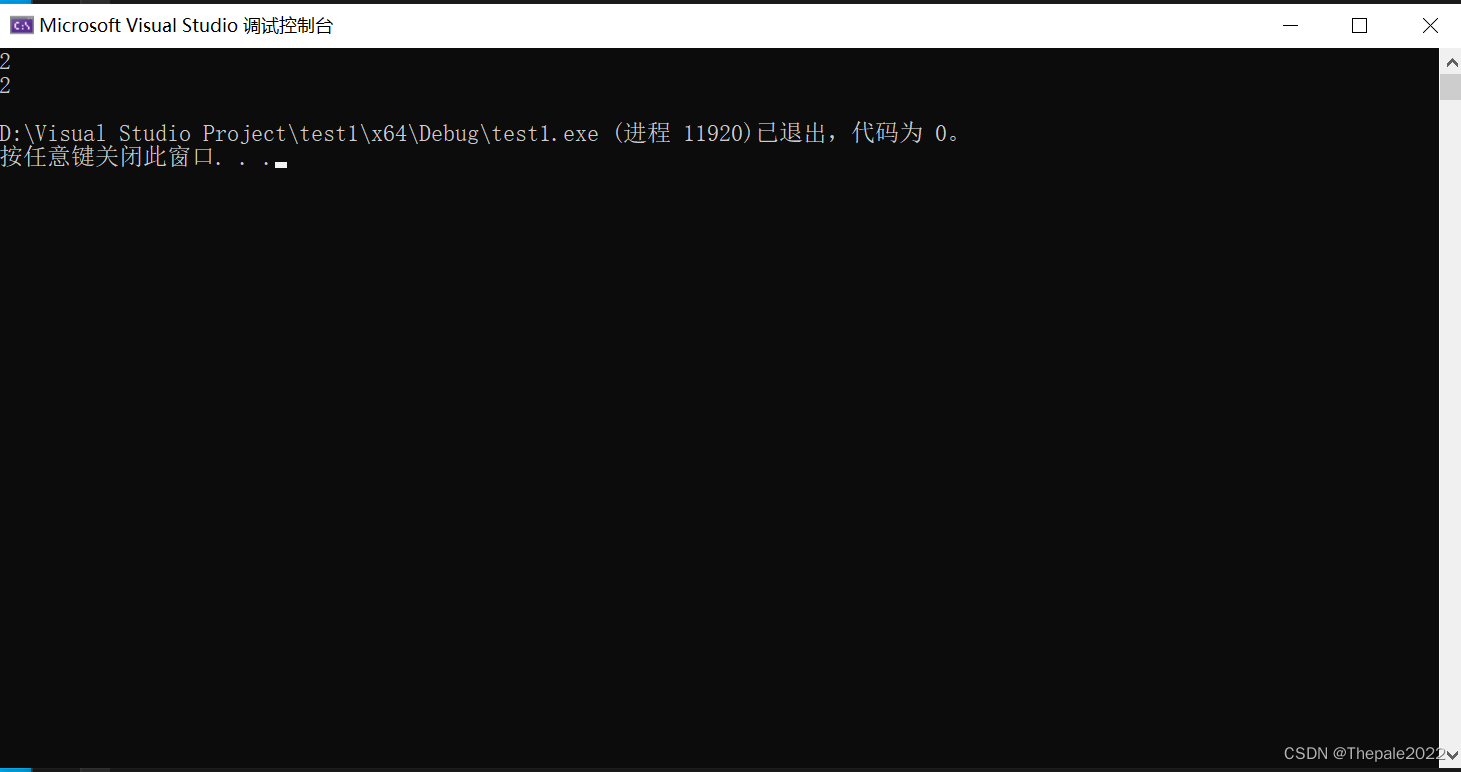
可以看到,sizeof 的输出结果取决于a,而a的值又没有被改变。
说明 sizeof 内部表达式并没有参与运算,只是推算了运算后的类型属性应该是 short 类型。同理,对于 arr[3],也只是推算出其类型属性是 int[4],所以可以计算出其大小为:16byte,而并没有真正的去运算,即并没有越界访问。
END