文章目录
Leetcode codebook: https://books.halfrost.com/leetcode/ChapterOne/Algorithm/
鱼皮编程导航:https://www.code-nav.cn/
稀土掘金:https://juejin.cn/post/6948598508362399752
leetcode高刷题:代码随想录https://www.algomooc.com/1659.html
![[图片]](https://img-blog.csdnimg.cn/d08428c1fd3e4558ae75e7a56207b98b.png)
**字节(基础架构)易考:**链表合并、删除链表倒数第k个节点,反转链表,接雨水,深/广度优先,快排,二叉树中序遍历(利用栈)
二分查找
- 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1
func search(nums []int, target int) int {
var low,high,mid int
low = 0
high = len(nums) -1
for low <= high { // 不要省略这里判断条件的=号,没有这个=对于偶数组数据输出结果是不正确的
mid = low + (high - low)/2 //防止溢出
if(target < nums[mid]){
high = mid-1
}else if(target == nums[mid]){
return mid
}else{
low = mid+1
}
}
return -1
}
复杂度分析
- 时间复杂度:O(logn),其中 n 是数组的长度。
- 空间复杂度:O(1)。一维数组
- 你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, …, n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
/**
* Forward declaration of isBadVersion API.
* @param version your guess about first bad version
* @return true if current version is bad
* false if current version is good
* func isBadVersion(version int) bool;
*/
func firstBadVersion(n int) int {
low := 1
high := n
for low <= high{
mid := low + (high - low)/2
if isBadVersion(mid){
if isBadVersion(mid -1){
high = mid-1
}else{ //注意这里的return放在else里面,想好逻辑顺序
return mid
}
}else {
low = mid +1
}
}
return -1
}
// 官方解答
return sort.Search(n,func(version int) bool {
return isBadVersion(version)
})
- 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
示例 4:
输入: nums = [1,3,5,6], target = 0
输出: 0
示例 5:
输入: nums = [1], target = 0
输出: 0
func searchInsert(nums []int, target int) int {
low := 0
high := len(nums)-1
var mid int
for low <= high {
mid = low + (high - low)/2
if target == nums[mid] {
return mid
}else if(target > nums[mid]){
low = mid+1
}else {
high = mid-1
}
}
//注意下面的处理方式,不用在上面一顿瞎处理
if(nums[mid] > target){
return mid
}
return mid +1
}
双指针
双指针一:
- 返回 每个数字的平方 组成的新数组(结果按 非递减顺序 排序)
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
输入:nums = [-4,-1,0,3,10]
输出:[0,1,9,16,100]
解释:平方后,数组变为 [16,1,0,9,100]
排序后,数组变为 [0,1,9,16,100]
示例 2:
输入:nums = [-7,-3,2,3,11]
输出:[4,9,9,49,121]
**思想:**用两个指针分别从两头开始移动来判断谁大(这样做的前提是数组已按非递减顺序排好序了),之后谁大就将谁放到新数组的最后为之后一次往前方(这里要单独再定义个值缩放位置的变量pos):
func sortedSquares(nums []int) []int {
left, right := 0, len(nums)-1
array := make([]int, len(nums)) // 注意创建数组的时候,数组长度为len[nums]而不是len[nums]-1
for pos := len(nums) - 1; pos >= 0; pos-- {
if v, w := nums[left]*nums[left], nums[right]*nums[right]; v > w {
array[pos] = v //继续比较左边第二个数与最右边的数的大小
left++
} else {
array[pos] = w //继续比较左边的数与右边的数的大小
right--
}
}
return array
}
// 法二(这个思想比较简单)
func sortedSquares(nums []int) []int {
res := make([]int, len(nums))
head, tail := 0, len(nums)-1
count := len(nums)-1
for head <= tail{
n1 := nums[head] * nums[head]
n2 := nums[tail] * nums[tail]
if n1 > n2{
res[count] = n1
count--
head++
}else{
res[count] = n2
count--
tail--
}
}
return res
}
- 给定一个已按照 非递减顺序排列 的整数数组 numbers ,请你从数组中找出两个数满足相加之和等于目标数 target 。
函数应该以长度为 2 的整数数组的形式返回这两个数的下标值。numbers 的下标 从 1 开始计数 ,所以答案数组应当满足 1 <= answer[0] < answer[1] <= numbers.length 。
你可以假设每个输入 只对应唯一的答案 ,而且你 不可以 重复使用相同的元素。
示例 1:
输入:numbers = [2,7,11,15], target = 9
输出:[1,2]
解释:2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
示例 2:
输入:numbers = [2,3,4], target = 6
输出:[1,3]
示例 3:
输入:numbers = [-1,0], target = -1
输出:[1,2]
提示:
2 <= numbers.length <= 3 * 104
-1000 <= numbers[i] <= 1000
numbers 按 非递减顺序 排列
-1000 <= target <= 1000
仅存在一个有效答案
**思路:**进字节面的第一道算法题,学长给出的😂
func twoSum(numbers []int, target int) []int {
sort.Ints(numbers)
left, right := 0, len(numbers)-1
array := []int{-1, -1}
for left <= right {
if numbers[left]+numbers[right] == target {
array[0] = left + 1
array[1] = right + 1
return array //这个结束条件必须写,要不他不会自动执行结束,因为找到结果后下面的语句他就不执行了,所以left与right的值就不会变了
} else if numbers[left]+numbers[right] > target {
right--
} else {
left++
}
}
return array
}
双指针二:
- 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
输入: [0,1,0,3,12]
输出: [1,3,12,0,0]
思路:是指两个指针均从最左侧开始一前一后前面的指针指向最前面的0元素后面的指针开始找最左非0元素,当后面的元素找到非零元素后与左指针的0互换,之后left++ , right++
func moveZeroes(nums []int) {
left, right := 0, 0
for right < len(nums){
if nums[right] != 0 {
nums[left], nums[right] = nums[right], nums[left]
left++
}
right++
}
}
- 给你一个数组,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
示例 1:
输入: nums = [1,2,3,4,5,6,7], k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右轮转 1 步: [7,1,2,3,4,5,6]
向右轮转 2 步: [6,7,1,2,3,4,5]
向右轮转 3 步: [5,6,7,1,2,3,4]
示例 2:
输入:nums = [-1,-100,3,99], k = 2
输出:[3,99,-1,-100]
解释:
向右轮转 1 步: [99,-1,-100,3]
向右轮转 2 步: [3,99,-1,-100]
提示:
1 <= nums.length <= 105
-231 <= nums[i] <= 231 - 1
0 <= k <= 105
进阶:
尽可能想出更多的解决方案,至少有 三种 不同的方法可以解决这个问题。
你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
方法一:(取余,记住取余条件)
func rotate(nums []int, k int) {
n := len(nums)
array := make([]int, n)
for i := 0; i < n; i++{
array[(i + k)%n] = nums[i] // 取余条件
}
for i := 0; i < n; i++{
nums[i] = array[i]
}
}
方法二:翻转,从k个元素处分割再翻转----这个是原地解决的,空间复杂度为O(n)
思路: 1、先将整个数组翻转一遍
2、从k处将数组分割,在两节分别翻转
func rotate(nums []int, k int) {
k %= len(nums) // 这是必要的:一是防止k太大切片的时候发生错误,二是,循环几次数组影响效率
reverse(nums)
reverse(nums[:k])
reverse(nums[k:])
}
func reverse(a []int){
for i, n := 0, len(a); i < n/2; i++{
a[i], a[n-1-i] = a[n-1-i], a[i]
}
}
双指针三:
- 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
示例 1:
输入:s = [“h”,“e”,“l”,“l”,“o”]
输出:[“o”,“l”,“l”,“e”,“h”]
示例 2:
输入:s = [“H”,“a”,“n”,“n”,“a”,“h”]
输出:[“h”,“a”,“n”,“n”,“a”,“H”]
提示:
1 <= s.length <= 105
s[i] 都是 ASCII 码表中的可打印字符
**思路:**典型两头双指针问题
func reverseString(s []byte) {
left, right := 0, len(s)-1
for left < right {
s[left], s[right] = s[right], s[left]
left++
right--
}
}
- 给定一个字符串,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
示例:
输入:“Let’s take LeetCode contest”
输出:“s’teL ekat edoCteeL tsetnoc”
思路:
开辟一个新字符串。然后从头到尾遍历原字符串,直到找到空格为止,此时找到了一个单词,并能得到单词的起止位置。随后,根据单词的起止位置,可以将该单词逆序放到新字符串当中。如此循环多次,直到遍历完原字符串,就能得到翻转后的结果,重点是原地解法:在原地按空格找出单词之后将单词立即翻转
func reverseWords(s string) string {
str_int := []rune(s)//这的rune也可以为byte,关于rune的解释及用法:https://studygolang.com/articles/26235
i := 0
//原地翻转
for i < len(s) {
start := i
//这几处总要加上i < len(s)是为了处理计数到字符串末尾时,数组索引越界的问题,且当计数到字符串末尾时没有空格
//符不知道怎样结束,此时这个就派上用场了,i到最后为27超过了len,结束循环,否则会因为没遇到' '而造成数组越界
for i < len(s) && str_int[i] != ' ' {
i++
}
//用到双指针处
left, right := start, i-1
for left < right {
str_int[left], str_int[right] = str_int[right], str_int[left]
left++
right--
}
//i到最后为27超过了len(27),结束循环,没必要再走判断这步了
if i < len(s) && str_int[i] == ' '{
i++
}
}
return string(str_int) //最后再将rune切片转换为字符串类型
}
链表(+双指针)
- 给定一个头结点为 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
示例 1:
输入:[1,2,3,4,5]
输出:此列表中的结点 3 (序列化形式:[3,4,5])
返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。
注意,我们返回了一个 ListNode 类型的对象 ans,这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
示例 2:
输入:[1,2,3,4,5,6]
输出:此列表中的结点 4 (序列化形式:[4,5,6])
由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点。
思路,因为求取的是一个链表的中间的节点,所以想到可以用快慢指针解法(之后考虑边界), 且链表长度可能为奇数也可能为偶数且此题要求当有偶数个节点时返回后面的那个中间节点,所以此时想是将快慢指针从head节点开始呢,还是将快慢指针从head.Next节点开始呢,经过考虑发现应该从head.Next节点开始
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func middleNode(head *ListNode) *ListNode {
// 快慢指针法解法
if head.Next == nil {
return head
}
fast, slow := head.Next, head.Next
// 这里让快慢指针都指向head.Next是为了满足当有偶数个节点时返回的是中间后面的节点-----
//--当要返回中间前面的节点时,应将快慢指针都指向head节点
for fast.Next != nil && fast.Next.Next != nil {
slow = slow.Next
fast = fast.Next.Next
}
return slow
}
'
- 题目:给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例1:
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
链表中结点的数目为 sz
1 <= sz <= 30
0 <= Node.val <= 100
1 <= n <= sz
![[图片]](https://img-blog.csdnimg.cn/f31a47fb31bb49a6a9c6471c9d37c266.png)
思路: 方法一,快慢指针解法+哑结点,思想是看下面的代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func removeNthFromEnd(head *ListNode, n int) *ListNode {
// 在head节点前设置虚拟头结点,(哑结点)解法
dummy := &ListNode{0,head}
slow, fast := dummy, head //注意:一开始slow节点指向哑结点, fast节点指向head节点
for i:=0; i < n; i++{
fast = fast.Next
//使fast所指节点与slow所指节点间隔n个节点,
//这样当要删除倒数第n个节点的时候slow指向的就是倒数第n个节点的前驱节点
}
for fast != nil {
fast = fast.Next
slow = slow.Next
}
slow.Next = slow.Next.Next
return dummy.Next //返回头结点
}
时间复杂度为O(L) L为链表长度,空间复杂度为O(1)
方法二:求出链表长度,之后设置哑结点,之后找出倒数第n个节点之后将其删除,返回dummy.Next节点
func removeNthFromEnd(head *ListNode, n int) *ListNode {
// 在head节点前设置虚拟头结点,(哑结点)解法
dummy := &ListNode{0,head}
cur := dummy // 这里注意!!!
length := length(head)
for i := 0; i < length-n; i++ {
cur = cur.Next
}
cur.Next = cur.Next.Next
return dummy.Next //返回头结点
}
func length(head *ListNode) int{
length := 1 // 这里注意!!!
for head != nil && head.Next != nil {
length++
head = head.Next
}
return length
}
时间复杂度为O(L) L为链表长度,空间复杂度为O(1)
第三种方法还可用栈来删除倒数第n个元素,利用的是栈演进后出的特点,golang中栈可以哟经链表节点的动态数组来模拟,用append给加进去
滑动窗口
- 无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: s = “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: s = “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
示例 4:
输入: s = “”
输出: 0
提示:
0 <= s.length <= 5 * 104
s 由英文字母、数字、符号和空格组成
思路:设置左右两个指针ans和rk,一开始ans=0,rk=-1,之后开始以字符串的第一个字符依次为开始字符来找最长的无重复字符的字符串,ans来记录最长的字符串为多大,返回ans
假设我们选择字符串中的第 k 个字符作为起始位置,并且得到了不包含重复字符的最长子串的结束位置为 rk。那么当我们选择第 k+1 个字符作为起始位置时,首先从 k+1 到 rk的字符显然是不重复的,并且由于少了原本的第 k 个字符,我们可以尝试继续增大 rk,直到右侧出现了重复字符为止。
这样一来,我们就可以使用「滑动窗口」来解决这个问题了:
- 我们使用两个指针表示字符串中的某个子串(或窗口)的左右边界,其中左指针代表着上文中「枚举子串的起始位置」,而右指针即为上文中的 rk
- 在每一步的操作中,我们会将左指针向右移动一格,表示 我们开始枚举下一个字符作为起始位置,然后我们可以不断地向右移动右指针,但需要保证这两个指针对应的子串中没有重复的字符。在移动结束后,这个子串就对应着 以左指针开始的,不包含重复字符的最长子串。我们记录下这个子串的长度;
- 在枚举结束后,我们找到的最长的子串的长度即为答案。
func lengthOfLongestSubstring(s string) int {
m := map[byte]int{} // 哈希map记录每个字符是否出现过
n := len(s)
// 右指针初始值为-1表示一开始不知道字符串长度,在左指针ans左侧,还没指向字符串
rk, ans := -1, 0
for i := 0; i < n; i++ {
if i != 0 {
delete(m, s[i-1]) //左指针想移动一格,移除一个字符
}
for rk+1 < n && m[s[rk+1]] == 0 {
m[s[rk+1]]++ //不断地右移右指针
rk++
}
// 第i个到第rk个字符是一个最大无重复字符的串
ans = max(ans, rk-i+1)
}
return ans
}
func max(x, y int) int { // 找最大不含重复字符的字符串
if x < y {
return y
}
return x
}
- 给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的排列。如果是,返回 true ;否则,返回 false 。
换句话说,s1 的排列之一是 s2 的 子串 。
示例 1:
输入:s1 = “ab” s2 = “eidbaooo”
输出:true
解释:s2 包含 s1 的排列之一 (“ba”).
示例 2:
输入:s1= “ab” s2 = “eidboaoo”
输出:false
提示:
1 <= s1.length, s2.length <= 104
s1 和 s2 仅包含小写字母
思路:先用len()函数求出s1,s2两字符串的长度分别记为n,m;之后如果n大于m则s2中不可能存在s1的排列,声明两个26长度的数字cnt1,cnt2(26为26个英文字母,因为在存字符的个数的时候要将字符与a做相对位置的计算)将s1字符串中的每个字符的种类的个数存在数组cnt1中,之后求s2字符串的前n个字符种类的数目,若相等返回true,若不相等,滑动窗口为n,开始向右移1位,之后将最左边的字符数量减1,新进来的字符数量加1,之后再判断时候相等(cnt1与cnt2),不相等滑动窗口继续右移1位,直到不最后,若都没有返回false
func checkInclusion(s1 string, s2 string) bool {
n, m := len(s1), len(s2)
if n > m {
return false
}
var cnt1, cnt2 [26]int // 因为26个英文字母
// 先统计s1的字符和次数,另外初始化s2的滑动窗口的字符和次数
for i := 0; i < n; i++ {
cnt1[s1[i]-'a']++
cnt2[s2[i]-'a']++
}
if cnt2 == cnt1 {
return true
}
// 滑动窗口遍历,滑动窗口的大小始终保持len(s1)
for i := n; i < m; i++ {
// 窗口左边界右移,缩减窗口
cnt2[s2[i-n]-'a']--
// 窗口右边界+1,左边界-1,保持固定
// 窗口右边界加入s2[i]
cnt2[s2[i]-'a']++
if cnt1 == cnt2 {
return true
}
}
return false
}
广度优先深度优先搜索
1. 图像渲染
有一幅以二维整数数组表示的图画,每一个整数表示该图画的像素值大小,数值在 0 到 65535 之间。
给你一个坐标 (sr, sc) 表示图像渲染开始的像素值(行 ,列)和一个新的颜色值 newColor,让你重新上色这幅图像。
为了完成上色工作,从初始坐标开始,记录初始坐标的上下左右四个方向上像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应四个方向上像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为新的颜色值。
最后返回经过上色渲染后的图像。
示例 1:
输入:
image = [[1,1,1],[1,1,0],[1,0,1]]
sr = 1, sc = 1, newColor = 2
输出: [[2,2,2],[2,2,0],[2,0,1]]
解析:
在图像的正中间,(坐标(sr,sc)=(1,1)),
在路径上所有符合条件的像素点的颜色都被更改成2。
注意,右下角的像素没有更改为2,
因为它不是在上下左右四个方向上与初始点相连的像素点。
注意:
image 和 image[0] 的长度在范围 [1, 50] 内。
给出的初始点将满足 0 <= sr < image.length 和 0 <= sc < image[0].length。
image[i][j] 和 newColor 表示的颜色值在范围 [0, 65535]内。
深度优先解法(递归):递归顺序为:上下左右
深度优先,递归解法
func floodFill(image [][]int, sr int, sc int, newColor int) [][]int {
R, C := len(image), len(image[0])
color := image[sr][sc]
//当目标颜色和初始颜色相同时,我们无需对原数组进行修改。
if image[sr][sc] == newColor {
return image
}
dfs(sr, sc, newColor, R, C, color, image)
return image
}
func dfs(r int, c int, newColor int, R int, C int, color int, image [][]int) {
if image[r][c] == color {
image[r][c] = newColor
if r >= 1 {
// 自己执行自己的,对r的加减影响,函数结束完毕了也就消失了,这个地方写的有点冗杂
dfs(r-1, c, newColor,R , C, color, image)
}
if r+1 < R {
dfs(r+1, c, newColor,R , C, color, image)
}
if c >= 1 {
dfs(r, c-1, newColor,R , C, color, image)
}
if c+1 < C {
dfs(r, c+1, newColor,R , C, color, image)
}
}
}
广度优先解法(与队列 || 栈,是好兄弟!!一般情况~):放入队列的顺序是上下左右
type QueueNode struct {
x int
y int
}
func floodFill(image [][]int, sr int, sc int, newColor int) [][]int {
r, c := len(image), len(image[0])
color := image[sr][sc]
queue := make([]QueueNode, 0) //创建QueueNode类型的切片,长度为0,这里用他来构造队列
if image[sr][sc] == newColor {
return image
}
queue = append(queue, QueueNode{sr, sc})
for len(queue) > 0 {
vaule := queue[0]
queue = queue[1:]
// 注意这行代码放置的位置很有讲究,且影响下面的判断条件
image[vaule.x][vaule.y] = newColor
// vaule.x-1 >= 0 注意!!
if vaule.x-1 >= 0 && image[vaule.x-1][vaule.y] == color {
queue = append(queue, QueueNode{vaule.x-1, vaule.y})
}
if vaule.x+1 < r && image[vaule.x+1][vaule.y] == color {
queue = append(queue, QueueNode{vaule.x+1, vaule.y})
}
// vaule.y-1 >= 0 注意!!
if vaule.y-1 >= 0 && image[vaule.x][vaule.y-1] == color {
queue = append(queue, QueueNode{vaule.x, vaule.y-1})
}
if vaule.y+1 < c && image[vaule.x][vaule.y+1] == color {
queue = append(queue, QueueNode{vaule.x, vaule.y+1})
}
}
return image
}
2. 岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例1:
[图片]
输入:grid = [
[0,0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,1,1,0,1,0,0,0,0,0,0,0,0],
[0,1,0,0,1,1,0,0,1,0,1,0,0],
[0,1,0,0,1,1,0,0,1,1,1,0,0],
[0,0,0,0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,0,1,1,0,0,0,0] ]
输出:6
解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1 。
示例 2:
输入:grid = [[0,0,0,0,0,0,0,0]]
输出:0
思路:利用深度优先遍历递归方法,首先设置俩层循环目的是将原始的二维数组的每一个元素进行遍历,之后遍历到值为1的元素的时候开始采用深度优先遍历其上下左右的元素是否为1如果是加1如果不是跳过去,将查找的为1的元素在累加之后置为0以防止重复计算(已经计算过的岛屿面积)之后将找到的岛屿面积与下一个计算出的岛屿面积一直进行大小比较,最后比较出最大的岛屿面积并返回结果
var ( //这块就是为了下面搜索到某一块时,控制上下左右四个方向搜索的,且应该用括号括起来
dx = []int{1, 0, 0, -1}
dy = []int{0, 1, -1, 0}
)
func maxAreaOfIsland(grid [][]int) int {
island := 0
for i := 0; i < len(grid); i++ {
for j := 0; j < len(grid[0]); j++ {
if grid[i][j] == 1 {
island = max(dfs(i, j, grid), island)
}
}
}
return island
}
func dfs(x int, y int, grid [][]int) (res int) { // 注意:返回值带参数名的要括起来!!!
if grid[x][y] == 1 {
//此处判断一定要写因为递归调用的时候grid[x][y]可能就不是1了,这也是个终止条件
res++ // 注意此处res可以直接用!!!
grid[x][y] = 0 // 将遍历过的岛屿面积置为0,以防后面继续在重复遍历
for k := 0; k < 4; k++ {
mx, my := x + dx[k], y + dy[k]
// 这里千万注意不要用x += dx[k]; y += dy[k]
//因为这样用会将原始的x,y给改变掉当递归结束下一轮循环的时候
//还要用原始的x,y再进行其他方向的遍历
if mx >= 0 && mx < len(grid) && my >= 0 && my < len(grid[0]) {
res += dfs(mx, my, grid) //累加岛屿面积
}
}
}
return // 因为上面用到了res所以此处return res 与 return 都可以!
}
func max(x int, y int) (res int) {
if x < y {
return y
}
return x
}
广度优先搜索:(队列)所占内存所用时间比上面的深度优先,递归解法都要长
思路:还是从头开始遍历原来的二维数组,之后遇到元素值为1的先存入一个长不确定宽为2的一个动态数组构造的队列中之后从头拿出队列里的元素将island+1并看上下左右是否还有为1的元素有的话加入队列继续这个过程,没有的话开始与之前存入res里的上个岛屿面积island进行对比,比较出大的一个存入res最后返回res
var ( //这块就是为了下面搜索到某一块时,控制上下左右四个方向搜索的
dx = []int{1, 0, 0, -1}
dy = []int{0, 1, -1, 0}
)
// 广度优先搜索(利用队列)
func maxAreaOfIsland(grid [][]int) int {
res := 0
for i := 0; i < len(grid); i++ {
for j := 0; j < len(grid[0]); j++ {
island := 0
if grid[i][j] == 1 {
var queue [][2]int
queue = append(queue, [2]int{i, j})
for k := 0; k < len(queue); k++ {
if grid[queue[k][0]][queue[k][1]] == 1 {
island++
grid[queue[k][0]][queue[k][1]] = 0
for s := 0; s < 4; s++ {
mx, my := queue[k][0] + dx[s], queue[k][1] + dy[s]
if mx >= 0 && mx < len(grid) && my >= 0 && my < len(grid[0]) {
queue = append(queue, [2]int{mx, my})
}
}
}
}
}
res = max(res, island)
}
}
return res
}
func max(x int, y int) (res int) {
if x < y {
return y
}
return x
}
方法三是:深度优先+栈,思路就是找到元素值为1的,加入到栈中之后从栈中取出遍历其上下左右的元素
复杂度分析(深 / 广度优先均是)
时间复杂度:O(R×C)。其中 R 是给定网格中的行数,C 是列数。我们访问每个网格最多一次。
空间复杂度:O(R×C),递归的深度最大可能是整个网格的大小,因此最大可能使用 O(R×C) 的栈空间。
合并二叉树
- 给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
示例 1:
![[图片]](https://img-blog.csdnimg.cn/618cf50d74074ae1a835c3c5e5e4fb55.png)
思路:深度优先遍历(递归)从两棵树的根节点出发(先序遍历),看两棵树是否为空,如果是有一个为空则合并后的结果为有值的那个节点(注意此时返回得这个有值的节点连带他的左右指针指向的下面的接地那一起返回,所以不用担心有的节点合并不到),如果俩个都是空那就返回空,如何两个都不是空则将两个节点的值相加。再继续看这两个节点的左右节点,递归的进行下去,直到满足结束条件
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func mergeTrees(root1 *TreeNode, root2 *TreeNode) *TreeNode {
// go语言是值传递只有传递节点指针才会将原来的树的节点的信息进行改变
if root1 == nil {
return root2
}
if root2 == nil {
return root1
}
root1.Val += root2.Val
root1.Left = mergeTrees(root1.Left , root2.Left)
root1.Right = mergeTrees(root1.Right,root2.Right)
return root1
}
时间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。对两个二叉树同时进行深度优先搜索,只有当两个二叉树中的对应节点都不为空时才会对该节点进行显性合并操作,因此被访问到的节点数不会超过较小的二叉树的节点数。
空间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。空间复杂度取决于递归调用的层数,递归调用的层数不会超过较小的二叉树的最大高度,最坏情况下,二叉树的高度等于节点数。
方法二;利用广度优先遍历+三个队列,分别存放原始的两个树的节点,以及合并后的树的节点
二叉树的镜像
![递归解法,之后可能会补充非递归解法
题目:
请完成一个函数,输入一个二叉树,该函数输出它的镜像。
例如输入:
4
/ 2 7
/ \ / 1 3 6 9
镜像输出:
4
/ 7 2
/ \ / 9 6 3 1
示例 :
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
思路:将各个子树的左右节点都颠倒](https://img-blog.csdnimg.cn/50cf596992bb4b2cbc78042f3110187a.png)
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func mirrorTree(root *TreeNode) *TreeNode {
if root == nil {
return root
}
left := mirrorTree(root.Left) //想不过来可以画个最简单的3节点的二叉树来看看
right := mirrorTree(root.Right)
root.Left = right
root.Right = left
return root
}
二叉树的遍历
非递归:(栈来实现)
先序
二叉树先序遍历,自己方法,有些地方比较冗余。下面有改进版
题解挺不错的:https://leetcode.cn/problems/binary-tree-inorder-traversal/solution/dai-ma-sui-xiang-lu-che-di-chi-tou-qian-xjof1/
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func preorderTraversal(root *TreeNode) []int {
res := []int{}
if root == nil {
return res
}
stack := list.New()
// stack.PushBack(root.Right) // 先压栈的顺序考虑好,先进后出
// stack.PushBack(root.Left)
nodeLeft := root.Left
nodeRight := root.Right
if nodeRight != nil{
stack.PushBack(root.Right)
}
if nodeLeft != nil{
stack.PushBack(root.Left)
}
res = append(res, root.Val) // 先序遍历嘛,所以第一个访问的就是根节点及各个子树的根节点
for stack.Len() > 0 {
e := stack.Back()
node := e.Value.(*TreeNode)
stack.Remove(e) // 更新栈的值
res = append(res, node.Val)
nodeLeft := node.Left
nodeRight := node.Right
if nodeRight != nil{
stack.PushBack(node.Right)
}
if nodeLeft != nil{
stack.PushBack(node.Left)
}
}
return res
}
改进版:
func preorderTraversal(root *TreeNode) []int {
res := []int{}
if root == nil {
return res
}
stack := list.New()
stack.PushBack(root.Right) // 先压栈的顺序考虑好,先进后出
stack.PushBack(root.Left)
res = append(res, root.Val) // 先序遍历嘛,所以第一个访问的就是根节点及各个子树的根节点
for stack.Len() > 0 {
e := stack.Back()
node := e.Value.(*TreeNode)
stack.Remove(e) // 更新栈里面的值
if node == nil{
continue
}
res = append(res, node.Val)
stack.PushBack(node.Right)
stack.PushBack(node.Left)
}
return res
}
中序
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func inorderTraversal(root *TreeNode) []int {
res := []int{}
if root == nil {
return res
}
node := root
stack := []*TreeNode{} // 自己构造个节点切片当做
// 先把左节点放入栈中
for node != nil {
stack = append(stack, node)
node = node.Left
}
for len(stack) > 0 {
node = stack[len(stack)-1]
stack = stack[:len(stack)-1] //将最后的一个数据弹出,更新新的栈内容
res = append(res, node.Val)
node = node.Right
for node != nil {
stack = append(stack, node)
node = node.Left
}
}
return res
}
// 调用go的栈,来实现
// func inorderTraversal(root *TreeNode) []int {
// res := []int{}
// for root == nil {
// return res
// }
// node := root
// stack := list.New()
// // 先把树的左节点压入栈中
// for node != nil {
// stack.PushBack(node)
// node = node.Left
// }
// for stack.Len() > 0 {
// e := stack.Back()
// node = e.Value.(*TreeNode)
// stack.Remove(e)
// res = append(res, node.Val)
// node = node.Right
// for node != nil {
// stack.PushBack(node)
// node = node.Left
// }
// }
// return res
// }**加粗样式**
后序
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func postorderTraversal(root *TreeNode) []int {
res := []int{}
if root == nil {
return res
}
stack := list.New()
// 这里按照前序遍历的思想,将存入栈中的节点改变,此处和前序遍历亚展的顺序刚好相反
stack.PushBack(root.Left) // 先进后出
stack.PushBack(root.Right)
res = append(res, root.Val) // res中存的值为中,右, 左,最后整体翻转,便成了,左右中--》正好后序遍历
for stack.Len() > 0 {
e := stack.Back()
node := e.Value.(*TreeNode)
stack.Remove(e)
if node == nil { // 这里注意判断节点是否为nil
continue
}
res = append(res, node.Val)
stack.PushBack(node.Left)
stack.PushBack(node.Right)
}
for i := 0; i < len(res)/2; i++ {
res[i], res[len(res)-1-i] = res[len(res)-1-i], res[i]
}
return res
}
递归 :(深度优先遍历)
中序
func inorderTraversal(root *TreeNode) []int {
// 中序遍历递归
res := []int{}
inorder(root, &res)
return res
}
func inorder(root *TreeNode, res *[]int){
if root == nil {
return
}
inorder(root.Left, res)
*res = append(*res, root.Val)
inorder(root.Right, res)
}
先序
func inorderTraversal(root *TreeNode) []int {
// 中序遍历递归
res := []int{}
inorder(root, &res)
return res
}
func inorder(root *TreeNode, res *[]int){
if root == nil {
return
}
*res = append(*res, root.Val)
inorder(root.Left, res)
inorder(root.Right, res)
}
后序
func inorderTraversal(root *TreeNode) []int {
// 中序遍历递归
res := []int{}
inorder(root, &res)
return res
}
func inorder(root *TreeNode, res *[]int){
if root == nil {
return
}
inorder(root.Left, res)
inorder(root.Right, res)
*res = append(*res, root.Val)
}
二叉树将每一层右节点连接起来
- 填充每个节点的下一个右侧节点指针
层次遍历输出
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例 1:
![[图片]](https://img-blog.csdnimg.cn/35626ee2ccb048eea77e6f5062562584.png)
解法一:
思路:用的是next指针将每一层的左右节点连接起来,虽然看起来简单但是两层循环的条件要好好考虑。
从根节点开始,由于第 0 层只有一个节点,所以不需要连接,直接为第 1 层节点建立 next 指针即可。该算法中需要注意的一点是,当我们为第 N 层节点建立next 指针时,处于第 N−1 层。当第 N 层节点的next 指针全部建立完成后,移至第 N 层,建立第 N+1 层节点的 next 指针。
遍历某一层的节点时,这层节点的 next 指针已经建立。因此我们只需要知道这一层的最左节点,就可以按照链表方式遍历,不需要使用队列。
![[图片]](https://img-blog.csdnimg.cn/80cea1fe56f842ffbfb8ac69db29cb1f.png)
/**
* Definition for a Node.
* type Node struct {
* Val int
* Left *Node
* Right *Node
* Next *Node
* }
*/
func connect(root *Node) *Node {
//横向遍历完全二叉树,利用next之指针
if root == nil {
return nil
}
// 最外面循环管理遍历到的二叉树的层次----这两层循环出的条件特别需要注意
for leftMost := root; leftMost.Left != nil; leftMost = leftMost.Left { // 注意这里是leftMost.Left != nil
// 通过next遍历这一层节点,为下一层节点更新next,里面这层循环管理将这一层节点遍历完
for node := leftMost; node != nil; node = node.Next { //因为横向遍历而每一层 node = node.Next
node.Left.Next = node.Right //同一父节点的两个子节点,通过next连接起来
// 右节点指向下一个左节点(父节点同级的相邻节点的左节点)
if node.Next != nil {
node.Right.Next = node.Next.Left
}
}
}
return root //将每一层的节点都连接起来了,就返回了
}
时间复杂度为:O(n),每个节点只访问一次。
空间复杂度为:O(1),不需要存储额外的节点。
解法二:层序遍历(基于广度优先&队列)
思路:
链表(两数相加)
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
[图片]
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
示例 2:
输入:l1 = [0], l2 = [0]
输出:[0]
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
思路:逐位相加,考虑进位,别被下住!!
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
var tail,head *ListNode
carry := 0
for l1 != nil || l2 != nil {
n1, n2 := 0, 0
if l1 != nil{
n1 = l1.Val
l1 = l1.Next
}
if l2 != nil {
n2 = l2.Val
l2 = l2.Next
}
sum := n1 + n2 + carry
sum ,carry = sum%10, sum/10
if head == nil{
head = &ListNode{Val:sum}
tail = head
}else {
tail.Next = &ListNode{Val:sum}
tail = tail.Next
}
}
if carry > 0 {
tail.Next = &ListNode{Val: carry}
}
return head
}
dp,最长公共子序列(动态规划)
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如: “ace” 是 “abcde” 的子序列,但 “aec” 不是 “abcde” 的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = “abcde”, text2 = “ace”
输出:3
解释:最长公共子序列是 “ace” ,它的长度为 3 。
示例 2:
输入:text1 = “abc”, text2 = “abc”
输出:3
解释:最长公共子序列是 “abc” ,它的长度为 3 。
示例 3:
输入:text1 = “abc”, text2 = “def”
输出:0
go创建动态二维数组:
func main() {
n := 2
m := 3
//动态创建二维数组 2行3列
grid := make([][]int, n)
for i := 0; i < n; i++ {
grid[i] = make([]int, m)
}
/*
000
000
*/
}
思路:
bilibili最长公共子序列求解教程
**![[图片]](https://img-blog.csdnimg.cn/ece4870126a4481da680d496438c550f.png)
**
题解:
func longestCommonSubsequence(text1 string, text2 string) int {
m, n := len(text1), len(text2)
dp := make([][]int, m+1)// 构造m+1行n+1列数组
for i := 0; i <= m; i++ {
dp[i] = make([]int, n+1)
}
for i, c1 := range text1 {
for j, c2 := range text2 {
if c1 == c2 {
dp[i+1][j+1] = dp[i][j] + 1 // 若相等 取 左上角的值+1
}else{
dp[i+1][j+1] = max(dp[i+1][j], dp[i][j+1]) // 若不相等,取左边和上边值的最大值
}
}
}
return dp[m][n]
}
func max(a, b int) int{
if a <= b {
return b
}
return a
}
二叉树的层序遍历(广度优先??)
![[图片]](https://img-blog.csdnimg.cn/2eb105064c974441a6cdb9492bd0faa4.png)
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func levelOrder(root *TreeNode) [][]int {
var res [][]int
arr := []*TreeNode{root}
if root == nil{ //这步不能丢,因为这个丢了,吧nil放在arr切片中len > 0
return res
}
for len(arr) > 0 {
size := len(arr)
currRes := []int{}
for i := 0; i < size; i++{
node := arr[i]
currRes = append(currRes, node.Val)
// 将下一层的所有节点都放到节点切片中(相当于自己够早的队列)
if node.Left != nil {
arr = append(arr, node.Left)
}
if node.Right != nil{
arr = append(arr, node.Right)
}
}
//新的一层的节点个数
arr = arr[size: ]
res = append(res, currRes)
}
return res
}
二叉树的锯齿形遍历
![[图片]](https://img-blog.csdnimg.cn/0829791a46204054bd7a948b209a99a6.png)
**思路:**就是层序遍历之后设置一个 level 变量来记录层序遍历,第几层的节点加入队列,0,1,2,3,4…
将奇数层的节点值翻转。
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func zigzagLevelOrder(root *TreeNode) [][]int {
var ans [][]int
queue := []*TreeNode{root}
level := 0
if root == nil {
return ans
}
for len(queue) > 0 {
size := len(queue)
var currAns []int
for i := 0; i < size; i++ {
node := queue[i]
currAns = append(currAns, node.Val)
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
if level%2 == 1 {
for i := 0; i < size/2; i++ {
currAns[i], currAns[size-1-i] = currAns[size-1-i], currAns[i]
}
}
queue = queue[size:]
level++
ans = append(ans, currAns)
}
return ans
}
二叉树每层的最大值
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
![[图片]](https://img-blog.csdnimg.cn/0a47d1973b374edbb89317ee41aa5cda.png)
![[图片]](https://img-blog.csdnimg.cn/6b86b7f50abe4642850426f38053902b.png)
题解:https://leetcode.cn/problems/hPov7L/solution/er-cha-shu-mei-ceng-de-zui-da-zhi-by-lee-q4y2/
思路: 用的层序遍历(广度优先),构造个树node的列表queue存放树的每一层节点,之后将queue给tmp,同时给queue清空存放下面一层的节点,遍历tmp找最大值,返回ans[]
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func largestValues(root *TreeNode) []int { // 广度优先遍历
var queue []*TreeNode
var ans []int
if root != nil {
queue = append(queue, root)
}
for len(queue) > 0 {
tmp := queue
queue = nil
maxValue := math.MinInt32
for _, node := range tmp {
maxValue = max(maxValue, node.Val)
if node.Left != nil{
queue = append(queue, node.Left)
}
if node.Right != nil{
queue = append(queue, node.Right)
}
}
ans = append(ans, maxValue)
}
return ans
}
func max(a, b int) int{
if a > b {
return a
}
return b
}
快排
![[图片]](https://img-blog.csdnimg.cn/4ad976e43d0249489cc53526b55a0918.png)
快速排序 关于起始方向的选择问题 为什么一定要从右边开始,详细解释见下面:
https://cloud.tencent.com/developer/article/1672267
func quickSort(nums []int, left, right int) {
if left > right {
return
}
i, j, base := left, right, nums[left]
for i < j {
for nums[j] >= base && i < j {
j--
}
for nums[i] <= base && i < j {
i++
}
nums[i], nums[j] = nums[j], nums[i]
}
nums[i], nums[left] = nums[left], nums[i]
quickSort(nums, left, i - 1)
quickSort(nums, i + 1, right)
}
自己仿照写法:
func sortArray(nums []int) []int {
ans := quickSort(nums, 0, len(nums)-1)
return ans
}
func quickSort(nums []int, left int, right int) []int{
if left > right{
return nil
}
i, j, base := left, right, nums[left]
for i < j {
// 这里需要注意当基准值选择最左边的值时,要从右指针开始茶轴,所以先nums[j] >= base
for nums[j] >= base && i < j{
j--
}
for nums[i] <= base && i < j{
i++
}
nums[i], nums[j] = nums[j], nums[i]
}
nums[i], nums[left] = nums[left], nums[i]
quickSort(nums, left, i-1)
quickSort(nums, i+1, right)
return nums
}
反转链表
![[图片]](https://img-blog.csdnimg.cn/84f426493a694770a957547ce3e379e7.png)
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func reverseList(head *ListNode) *ListNode {
var prev *ListNode
curr := head
for curr != nil {
next := curr.Next
curr.Next = prev
prev = curr
curr = next
}
return prev
}
```go
在这里插入代码片
合并两个排序链表
![[图片]](https://img-blog.csdnimg.cn/1b113885f6da43c1bd76ad5fff1c59af.png)
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func mergeTwoLists(l1 *ListNode, l2 *ListNode) *ListNode {
dummp := &ListNode{}
curr := dummp
for l1 != nil && l2 != nil {
if l1.Val < l2.Val {
curr.Next = l1
l1 = l1.Next
}else {
curr.Next =l2
l2 = l2.Next
}
curr = curr.Next
}
if l1 == nil {
curr.Next = l2
}
if l2 == nil {
curr.Next = l1
}
return dummp.Next
}
整数转罗马数字
法一: 模拟计算过程
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给你一个整数,将其转为罗马数字。
示例 1:
输入: num = 3
输出: “III”
type valueSymbol struct {
value int
symbol string
}
func intToRoman(num int) string {
valueSymbols := []valueSymbol{ // 先用构造的结构体将13个特殊罗马符号与数字进行映射, 注意由大到小顺序
{1000, "M"},
{900, "CM"},
{500, "D"},
{400, "CD"},
{100, "C"},
{90, "XC"},
{50, "L"},
{40, "XL"},
{10, "X"},
{9, "IX"},
{5, "V"},
{4, "IV"},
{1, "I"},
}
res := []byte{}
for _, vs := range valueSymbols { // 先找到与num最接近的13个映射中的最大值,之后依次将找到的字符加在之前找到的字符后面
for num >= vs.value {
res = append(res, vs.symbol...)
num -= vs.value
}
if num == 0 { // 注意加上找到与num对应的罗马字符后循环的结束条件,加快速度
break
}
}
return string(res)
}
法二:
硬编码:
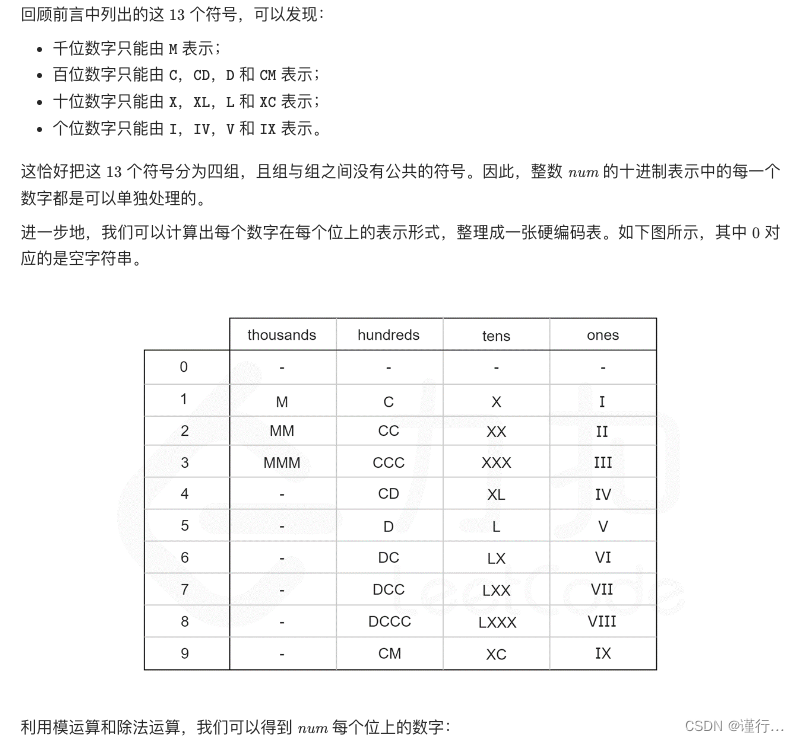
var (
thousands = []string{"", "M", "MM", "MMM"}
hundreds = []string{"", "C", "CC", "CCC", "CD", "D", "DC", "DCC", "DCCC", "CM"}
tens = []string{"", "X", "XX", "XXX", "XL", "L", "LX", "LXX", "LXXX", "XC"}
ones = []string{"", "I", "II", "III", "IV", "V", "VI", "VII", "VIII", "IX"}
)
func intToRoman(num int) string {
return thousands[num/1000] + hundreds[num%1000/100] + tens[num%100/10] + ones[num%10]
}
罗马数字转整数
 思路:模拟,将数字与罗马字符的映射存放在map中,之后按照罗马字符–》数字的规律(小数在大数的左边为减,小数在大数的右边则为加),同时注意判断条件限制
思路:模拟,将数字与罗马字符的映射存放在map中,之后按照罗马字符–》数字的规律(小数在大数的左边为减,小数在大数的右边则为加),同时注意判断条件限制
var symbolValues = map[byte]int{'I':1, 'V':5, 'X':10, 'L':50, 'C':100, 'D':500, 'M':1000}
func romanToInt(s string) int {
var ans int
for i := range s {
n := len(s)
value := symbolValues[s[i]]
if i < n-1 && value < symbolValues[s[i+1]] {
// i < n-1 此条件不可省略,因为少了这个条件 symbolValues[s[i+1]]遍历到最后一位字符会造成数组越界
ans -= value
}else {
ans += value
}
}
return ans
}
把数字翻译成字符串
// 待更新
两数之和(无序数组)
这题注意是无序数组,之前用双指针搞的是有序数组
题目:
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
此题用的是HashSet,因为hashSet中的元素查找很快,一个hash值对应一个元素,但是hashSet有要解决冲突等问题
func twoSum(nums []int, target int) []int {
res := []int{}
hashSet := map[int]int{}
for i, value := range nums {
if point, ok := hashSet[target-value]; ok {
res = append(res, point) //这两个append顺序不能颠倒,因为point 的值(索引肯定是在数组前面的,之前村存入hashSet中的)
res = append(res, i)
return res
}
hashSet[value] = i
}
return res
}
- 时间复杂度:O(N),其中 N 是数组中的元素数量。对于每一个元素 x,我们可以 O(1) 地寻找 target - x。
- 空间复杂度:O(N),其中 N 是数组中的元素数量。主要为哈希表的开销。
三数之和(双指针解法)
题目: 给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
思路:排序数组,固定一个数a,用双指针(left、right)找数b、c;找到a+b+c=0的三个数放入数组,最重要的是 a,b,c 去重,num[i-1] == num[i] (一定要用这个因为用num[i] == num[i+1]会影响left指针的值,num[i+1]==left ) => continue
func threeSum(nums []int) [][]int {
sort.Ints(nums)
ans := [][]int{}
for i := 0; i < len(nums)-1; i++{
n1 := nums[i]
if n1 > 0 { // 如果排序完的第一个数就大于0则不可能有三数之和为0
break
}
// n1去重;即a去重
if i > 0 && nums[i-1] == nums[i]{
continue
}
//用双指针找n1, n2 (即b、c)
left, right := i+1, len(nums)-1
for left < right{
n2, n3 := nums[left], nums[right]
if n1+n2+n3 == 0 {
ans = append(ans, []int{n1, n2, n3})
// b、c 去重
for left < right && nums[left] == n2{
left++ // 如果left左边的值和n2一直相等则left一直移到与n2不等的元素,且left < right
}
for left < right && nums[right] == n3{
right-- // 同理进行n3去重
}
}else if n1+n2+n3 > 0{
right--
}else {
left ++
}
}
}
return ans
}
- 时间复杂度:O(N^2),其中 N 是数组 nums 的长度。
- 空间复杂度:O(logN)。我们忽略存储答案的空间,额外的排序的空间复杂度为 O(logN)。然而我们修改了输入的数组nums(给排序了变成有序数组了),在实际情况下不一定允许,因此也可以看成使用了一个额外的数组存储了 nums 的副本并进行排序,空间复杂度为 O(N)。
翻转链表第k个节点
// 待更新
dp: 岛屿数量、接雨水、股票。。